
C’est un point important à comprendre. Non seulement l’utilisation de la mauvaise méthode entraînera parfois la suppression de pages de l’index comme prévu, mais elle peut également avoir un effet négatif sur le référencement.
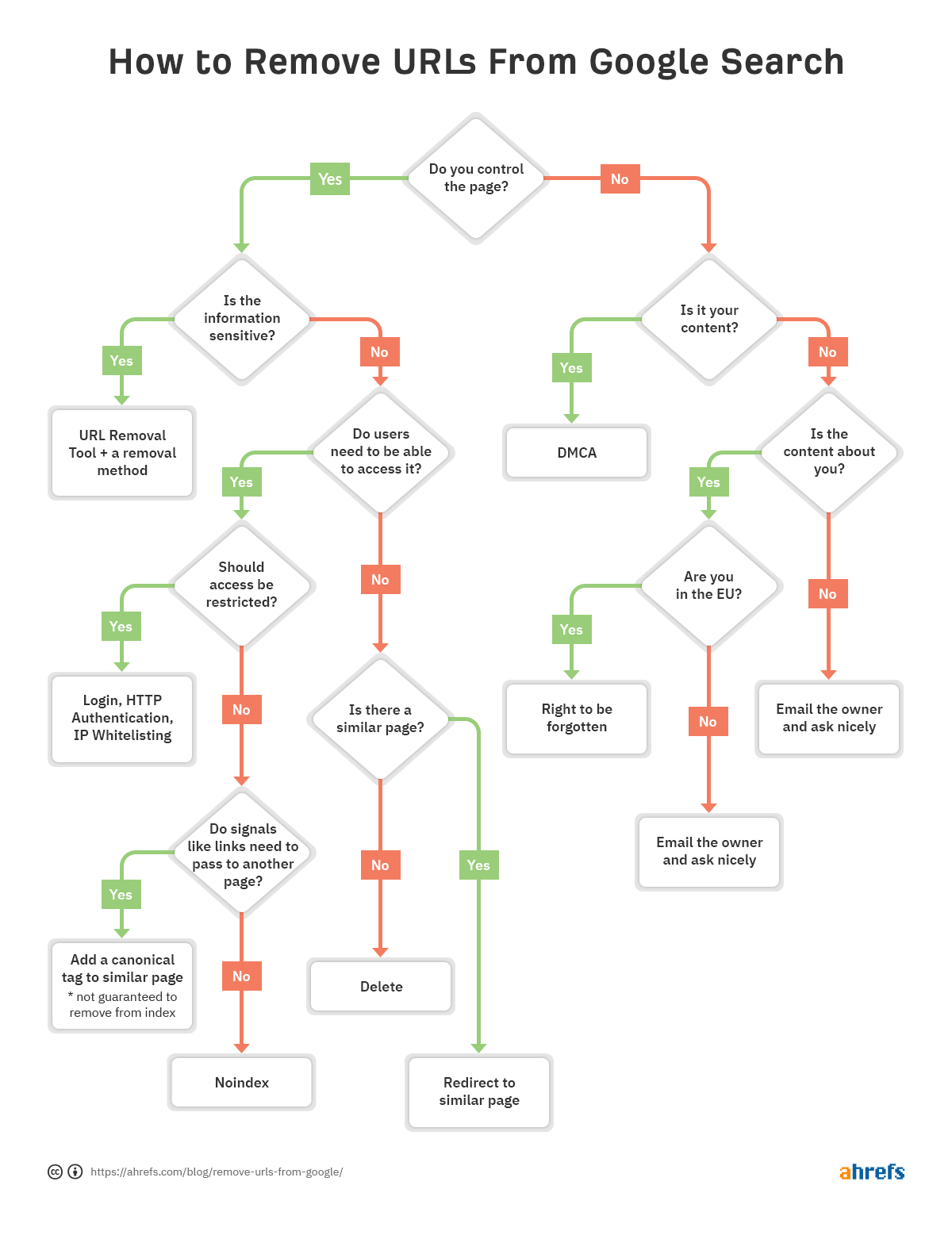
Pour vous aider à décider rapidement quelle méthode de suppression vous convient le mieux, nous avons créé un organigramme afin que vous puissiez passer à la section pertinente de l’article.
Dans cet article, vous apprendrez:
- Comment vérifier si une URL est indexée
- Cinq façons de supprimer des URL de Google
- Comment prioriser les suppressions
- Erreurs de suppression courantes à éviter
- Comment supprimer du contenu qui ne se trouve pas sur votre site
- Comment supprimer des images
Ce que je vois généralement faire des référenceurs pour vérifier si le contenu est indexé, c’est utiliser un site: recherche dans Google (par exemple, site: https://ahrefs.com). Alors que le site: les recherches peuvent être utiles pour identifier les pages ou les sections d’un site Web qui peuvent poser problème si elles apparaissent dans les résultats de recherche, vous devez faire attention car ce ne sont pas des requêtes normales et ne vous diront pas si une page est indexée. Ils peuvent afficher des pages connues de Google, mais cela ne signifie pas qu’ils sont éligibles pour afficher des résultats de recherche normaux sans l’opérateur site:.
Par exemple, site:les recherches peuvent toujours afficher des pages qui redirigent ou qui sont canonisées vers une autre page. Lorsque vous demandez un site spécifique, Google peut afficher une page de ce domaine avec le contenu, le titre et la description d’un autre domaine. Prenons par exemple moz.com qui était autrefois seomoz.org . Toutes les requêtes utilisateur régulières qui mènent à des pages sur moz.com montrera moz.com dans les SERPs, tandis que site:seomoz.org montrera seomoz.org dans les résultats de recherche comme indiqué ci-dessous.
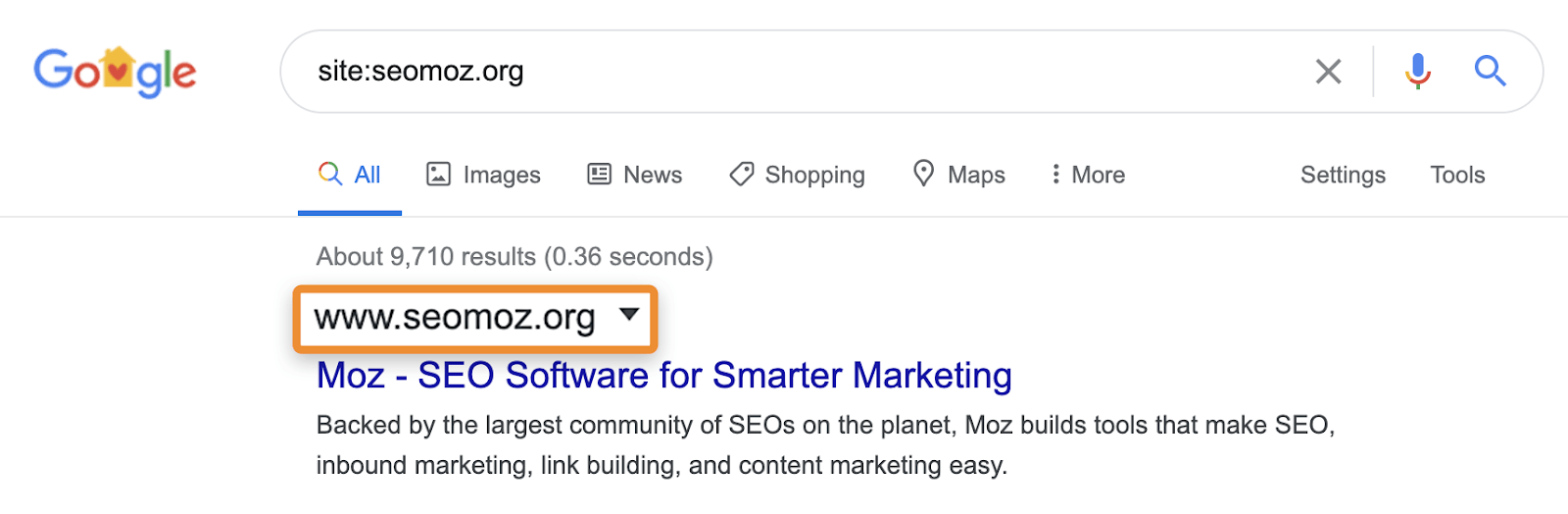
La raison pour laquelle cette distinction est importante est qu’elle peut conduire les référenceurs à commettre des erreurs telles que le blocage actif ou la suppression d’URL de l’index de l’ancien domaine, ce qui empêche la consolidation de signaux tels que PageRank. J’ai vu de nombreux cas avec des migrations de domaine où les gens pensent avoir fait une erreur pendant la migration car ces pages affichent toujours pour site:old-domain.com les recherches et finissent par nuire activement à leur site Web tout en essayant de « résoudre” le problème.
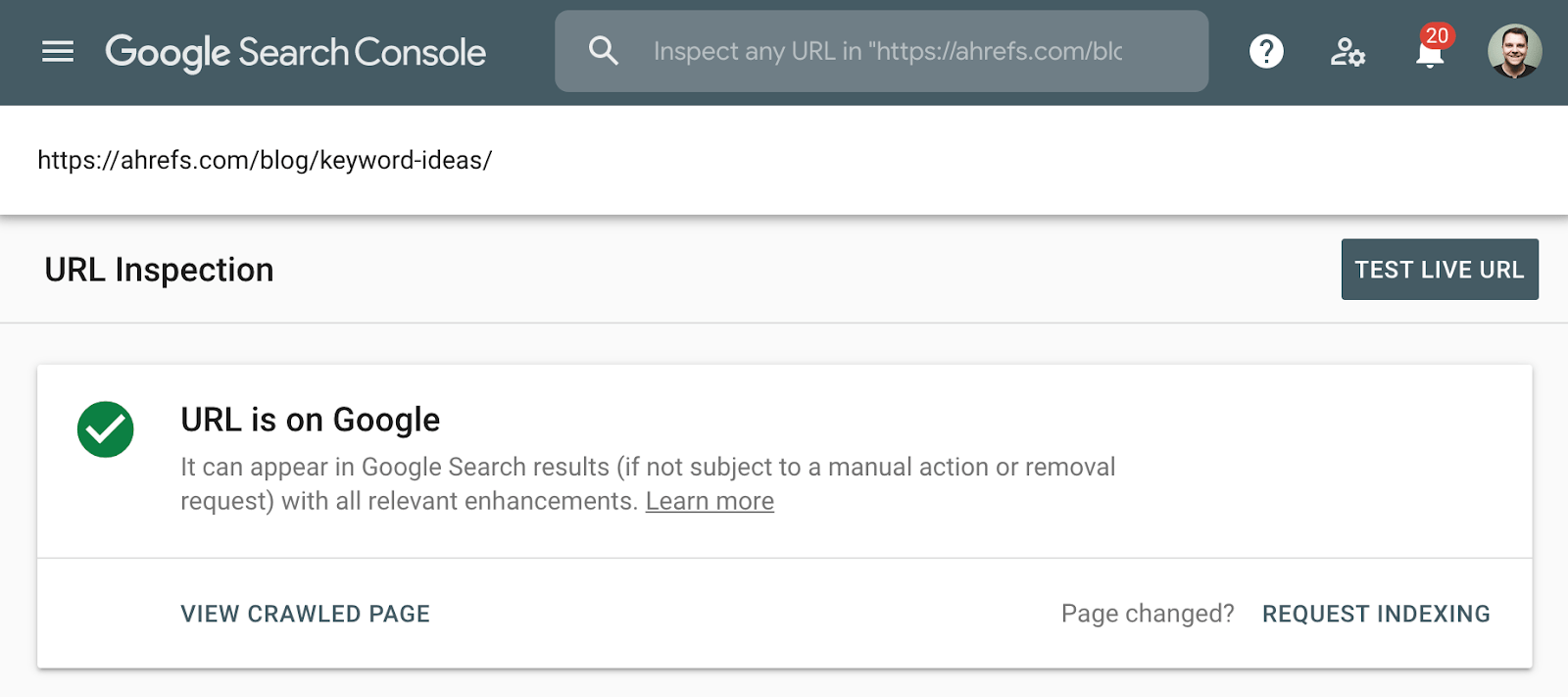
La meilleure méthode pour vérifier l’indexation consiste à utiliser le rapport de couverture d’index dans Google Search Console ou l’outil d’inspection d’URL pour une URL individuelle. Ces outils vous indiquent si une page est indexée et fournissent des informations supplémentaires sur la façon dont Google traite la page. Si vous n’y avez pas accès, recherchez simplement sur Google l’URL complète de votre page.
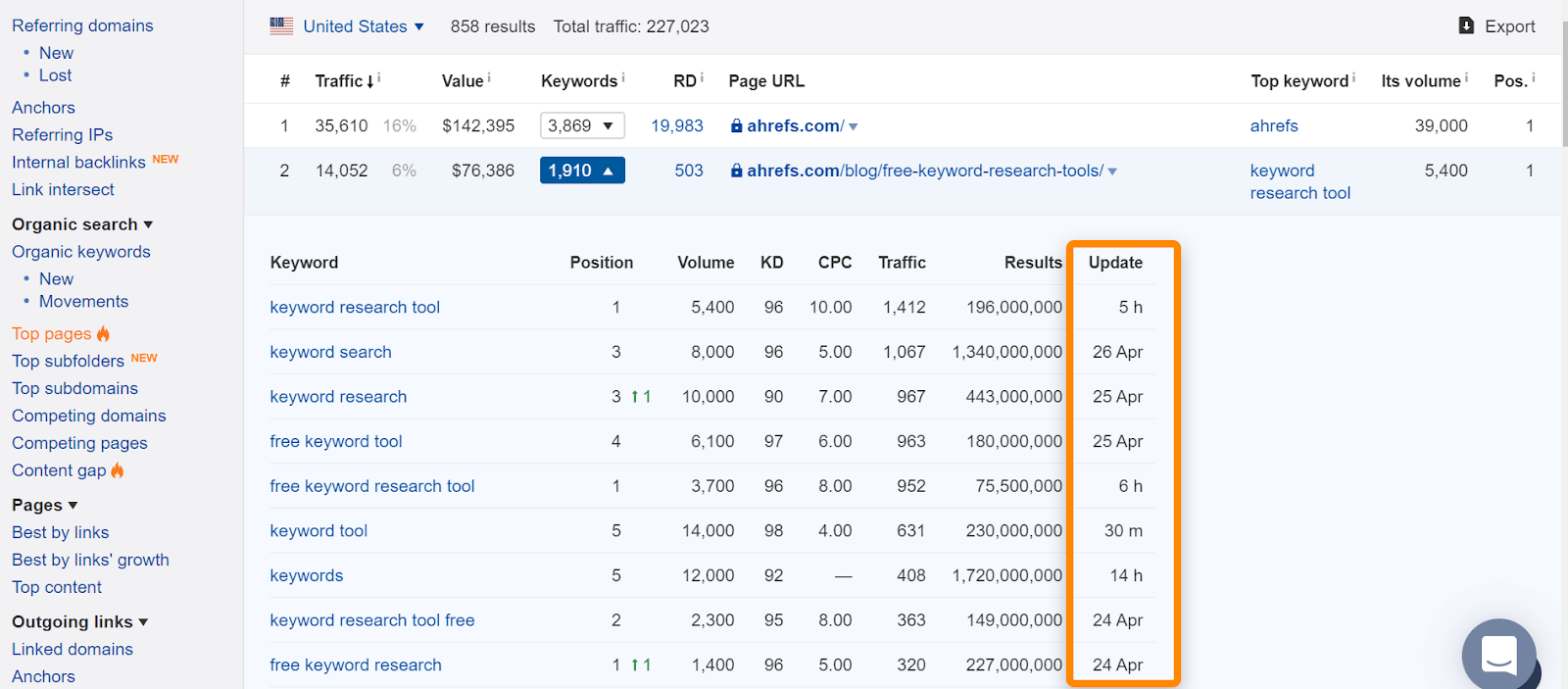
Dans Ahrefs, si vous trouvez la page dans notre rapport « Top pages” ou dans le classement des mots-clés organiques, cela signifie généralement que nous l’avons vue dans le classement des requêtes de recherche normales et est une bonne indication que la page a été indexée. Notez que les pages étaient indexées lorsque nous les avons vues, mais cela a peut-être changé. Vérifiez la date à laquelle nous avons vu la page pour la dernière fois pour une requête.
S’il y a un problème avec une URL particulière et qu’elle doit être supprimée de l’index, suivez l’organigramme au début de l’article pour trouver l’option de suppression correcte, puis passez à la section appropriée ci-dessous.
Si vous supprimez la page et que vous indiquez un code d’état 404 (introuvable) ou 410 (disparu), la page sera supprimée de l’index peu de temps après la nouvelle analyse de la page. Tant qu’elle n’est pas supprimée, la page peut toujours s’afficher dans les résultats de recherche. Et même si la page elle-même n’est plus disponible, une version en cache de la page peut être temporairement disponible.
Lorsque vous pourriez avoir besoin d’une option différente:
- J’ai besoin d’un retrait plus immédiat. Voir la section Outil de suppression d’URL.
- J’ai besoin de consolider des signaux comme des liens. Voir la section canonisation.
- J’ai besoin de la page disponible pour les utilisateurs. Vérifiez si les sections noindex ou restricting access correspondent à votre situation.
- Option de suppression 2: Noindex
- Option de suppression 3: Restreindre l’accès
- Option de suppression 4: Outil de suppression d’URL
- Option de suppression 5:Canonicalisation
- Noindex dans les robots.txt
- Blocage de l’exploration dans les robots.txt
- Nofollow
- Noindex et canonical vers une autre URL
- Noindex, attendez que Google explore, puis bloquez l’exploration
- Que se passe-t-il si c’est du contenu qui vous concerne mais pas sur un site que vous possédez?
- Pensées finales
Option de suppression 2: Noindex
Une balise meta robots noindex ou une réponse d’en‑tête x-robots indiqueront aux moteurs de recherche de supprimer une page de l’index. La balise meta robots fonctionne pour les pages où la réponse x‑robots fonctionne pour les pages et les types de fichiers supplémentaires tels que les PDF. Pour que ces balises soient visibles, un moteur de recherche doit pouvoir explorer les pages — assurez-vous donc qu’elles ne sont pas bloquées dans les robots.txt. Notez également que la suppression de pages de l’index peut empêcher la consolidation du lien et d’autres signaux.
Exemple de méta robots noindex:
<meta name="robots" content="noindex">
Exemple de balise x‑robots noindex dans la réponse d’en-tête:
HTTP/1.1 200 OKX-Robots-Tag: noindex
Lorsque vous pourriez avoir besoin d’une option différente:
- Je ne veux pas que les utilisateurs accèdent à ces pages. Voir la section Restriction d’accès.
- J’ai besoin de consolider des signaux comme des liens. Voir la section canonisation.
Option de suppression 3: Restreindre l’accès
Si vous voulez que la page soit accessible à certains utilisateurs mais pas aux moteurs de recherche, alors ce que vous voulez probablement, c’est l’une de ces trois options:
- une sorte de système de connexion;
- Authentification HTTP (où un mot de passe est requis pour l’accès);
- Liste blanche IP (qui permet uniquement aux adresses IP spécifiques d’accéder aux pages)
Ce type de configuration est idéal pour des choses comme les réseaux internes, le contenu réservé aux membres ou pour les sites de test, de test ou de développement. Il permet à un groupe d’utilisateurs d’accéder à la page, mais les moteurs de recherche ne pourront pas y accéder et n’indexeront pas les pages.
Lorsque vous pourriez avoir besoin d’une option différente:
- J’ai besoin d’un retrait plus immédiat. Voir la section Outil de suppression d’URL. Dans ce cas particulier, vous souhaiterez peut-être une suppression plus immédiate si le contenu que vous essayez de masquer a été mis en cache et que vous devez empêcher les utilisateurs de voir ce contenu.
Option de suppression 4: Outil de suppression d’URL
Le nom de cet outil de Google est légèrement trompeur car son fonctionnement est qu’il masquera temporairement le contenu. Google verra et explorera toujours ce contenu, mais les pages n’apparaîtront pas pour les utilisateurs. Cet effet temporaire dure six mois dans Google, tandis que Bing dispose d’un outil similaire qui dure trois mois. Ces outils doivent être utilisés dans les cas les plus extrêmes pour des problèmes de sécurité, des fuites de données, des informations personnellement identifiables (PII), etc. Pour Google, utilisez l’outil de suppression et pour Bing, consultez comment bloquer les URL.
Vous devez toujours appliquer une autre méthode en utilisant l’outil de suppression afin de supprimer les pages pendant une période plus longue (noindex ou delete) ou empêcher les utilisateurs d’accéder au contenu s’ils ont toujours les liens (supprimer ou restreindre l’accès). Cela vous donne juste un moyen plus rapide de masquer les pages pendant que la suppression a le temps de traiter. Le traitement de la demande peut prendre jusqu’à une journée.
Option de suppression 5:Canonicalisation
Lorsque vous avez plusieurs versions d’une page et que vous souhaitez consolider des signaux tels que des liens vers une seule version, ce que vous voulez faire est une forme de canonicalisation. Il s’agit principalement d’empêcher le contenu en double tout en consolidant plusieurs versions d’une page en une seule URL indexée.
Vous avez plusieurs options de canonisation :
- Balise canonique. Cela spécifie une autre URL comme la version canonique ou la version que vous souhaitez afficher. Si les pages sont en double ou très similaires, cela devrait aller. Lorsque les pages sont trop différentes, le canonique peut être ignoré car il s’agit d’un indice et non d’une directive.
- Redirige. Une redirection emmène un utilisateur et un bot de recherche d’une page à une autre. 301 est la redirection la plus couramment utilisée par les référenceurs, et il indique aux moteurs de recherche que vous souhaitez que l’URL finale soit celle affichée dans les résultats de recherche et où les signaux sont consolidés. Une redirection 302 ou temporaire indique aux moteurs de recherche que vous souhaitez que l’URL d’origine reste dans l’index et y consolide les signaux.
- Gestion des paramètres d’URL. Un paramètre est ajouté à la fin de l’URL et comprend généralement un point d’interrogation, comme ahrefs.com?this=parameter.Cet outil de Google vous permet de leur dire comment traiter les URL avec des paramètres spécifiques. Par exemple, vous pouvez spécifier si le paramètre modifie le contenu de la page ou s’il est simplement destiné à suivre l’utilisation.
Si vous avez plusieurs pages à supprimer de l’index de Google, elles doivent être priorisées en conséquence.
Priorité la plus élevée: Ces pages sont généralement liées à la sécurité ou à des données confidentielles. Cela inclut le contenu qui contient des données personnelles (PII), des données client ou des informations exclusives.
Priorité moyenne : Cela implique généralement du contenu destiné à un groupe spécifique d’utilisateurs. Intranets d’entreprise ou portails d’employés, contenu destiné uniquement aux membres et environnements de mise en scène, de test ou de développement.
Faible priorité: Ces pages impliquent généralement du contenu en double. Certains exemples de cela incluraient des pages servies à partir de plusieurs URL, des URL avec des paramètres, et pourraient à nouveau inclure des environnements de mise en scène, de test ou de développement.
Je veux couvrir quelques-unes des façons dont je vois habituellement les déménagements mal effectués et ce qui se passe dans chaque scénario pour aider les gens à comprendre pourquoi ils ne fonctionnent pas.
Noindex dans les robots.txt
Alors que Google supportait officieusement noindex dans les robots.txt, ce n’était jamais une norme officielle et ils ont maintenant officiellement supprimé le support. De nombreux sites qui le faisaient le faisaient de manière incorrecte et se faisaient du mal.
Blocage de l’exploration dans les robots.txt
L’exploration n’est pas la même chose que l’indexation. Même si Google est empêché d’analyser les pages, s’il existe des liens internes ou externes vers une page, ils peuvent toujours l’indexer. Google ne saura pas ce qui se trouve sur la page car il ne l’explorera pas, mais il sait qu’une page existe et écrira même un titre à afficher dans les résultats de recherche en fonction de signaux tels que le texte d’ancrage des liens vers la page.
Nofollow
Cela devient généralement confus pour noindex, et certaines personnes l’utiliseront au niveau de la page en s’attendant à ce que la page ne soit pas indexée. Nofollow est un indice, et bien qu’il ait initialement empêché les liens sur la page et les liens individuels avec l’attribut nofollow d’être explorés, ce n’est plus le cas. Google peut désormais explorer ces liens s’ils le souhaitent. Nofollow a également été utilisé sur des liens individuels pour essayer d’empêcher Google d’explorer des pages spécifiques et pour sculpter des PageRank. Encore une fois, cela ne fonctionne plus car nofollow est un indice. Dans le passé, si la page avait un autre lien vers elle, Google pouvait toujours découvrir à partir de ce chemin d’exploration alternatif.
Notez que vous pouvez trouver les pages non suivies en bloc à l’aide de ce filtre dans l’Explorateur de pages de l’Audit de site d’Ahrefs.
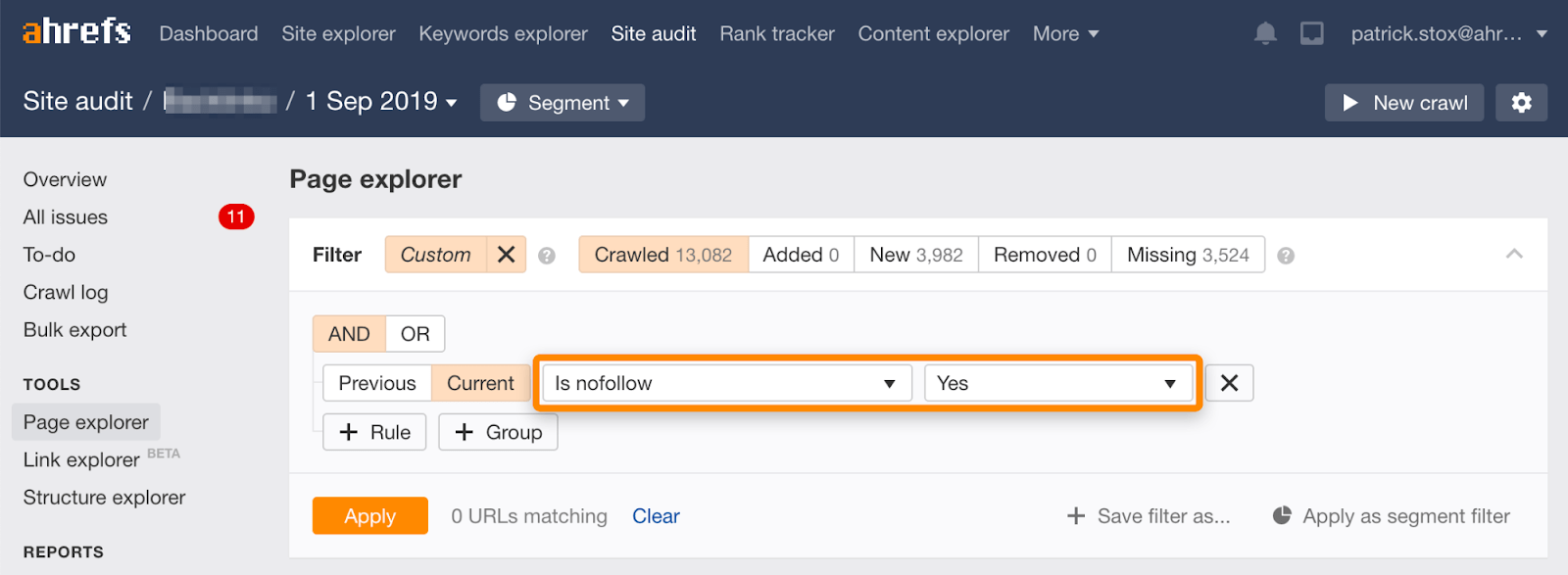
Comme il est rarement logique de ne pas suivre tous les liens d’une page, le nombre de résultats doit être nul ou proche de zéro. S’il y a des résultats correspondants, je vous invite à vérifier si la directive nofollow a été ajoutée accidentellement à la place de noindex et à choisir une méthode de suppression plus appropriée si nécessaire.
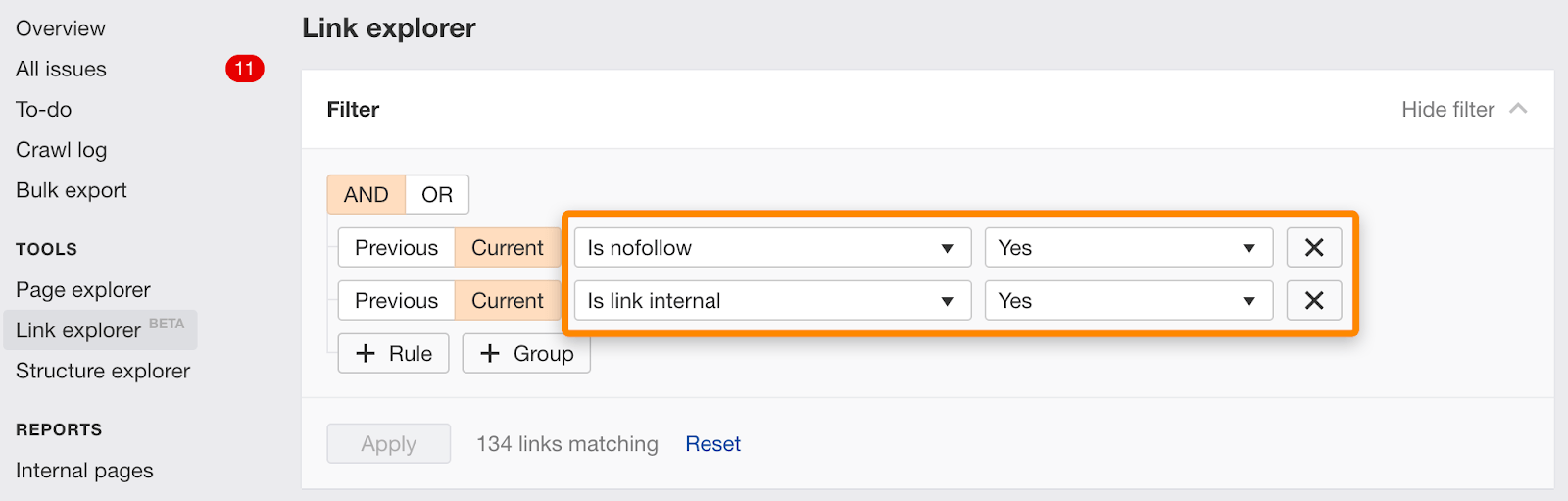
Vous pouvez également trouver des liens individuels marqués nofollow à l’aide de ce filtre dans l’Explorateur de liens.
Noindex et canonical vers une autre URL
Ces signaux sont en conflit. Noindex dit de supprimer la page de l’index, et canonical dit qu’une autre page est la version qui doit être indexée. Cela peut en fait fonctionner pour la consolidation car Google choisira généralement d’ignorer le noindex et d’utiliser à la place le canonique comme signal principal. Cependant, ce n’est pas un comportement absolu. Il y a un algorithme impliqué et il y a un risque que la balise noindex soit le signal compté. Si c’est le cas, les pages ne se consolideront pas correctement.
Notez que vous pouvez trouver des pages non indexées avec des canoniques non auto-référentiels à l’aide de cet ensemble de filtres dans l’Explorateur de pages dans Site Audit:
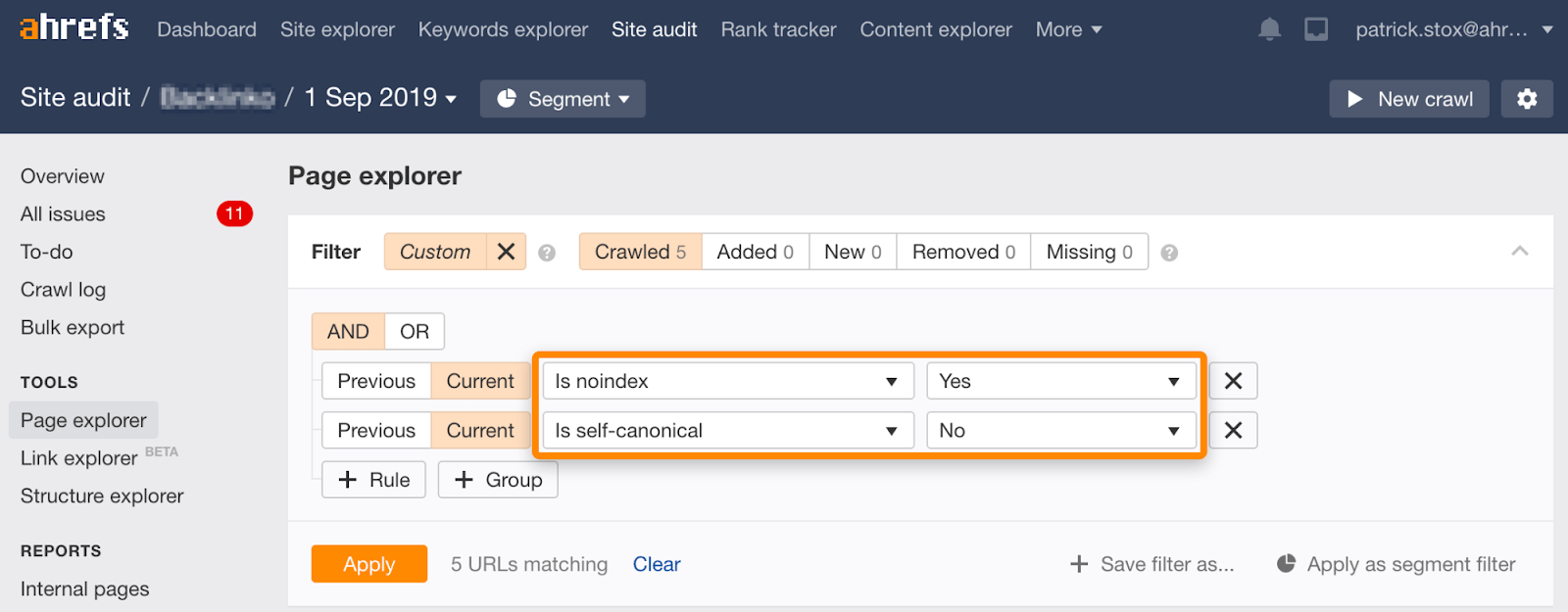
Noindex, attendez que Google explore, puis bloquez l’exploration
Il y a deux façons que cela se produit généralement:
- Les pages sont déjà bloquées mais sont indexées, les gens ajoutent noindex et débloquent afin que Google puisse explorer et voir le noindex, puis bloquer à nouveau l’exploration des pages.
- Les gens ajoutent des balises noindex pour les pages qu’ils souhaitent supprimer et une fois que Google a analysé et traité la balise noindex, ils bloquent l’exploration des pages.
De toute façon, l’état final est empêché de ramper. Si vous vous souvenez, plus tôt, nous avons parlé de la façon dont l’exploration n’est pas la même chose que l’indexation. Même si ces pages sont bloquées, elles peuvent toujours se retrouver dans l’index.
Si vous possédez le contenu utilisé sur un autre site Web, vous pourrez peut-être déposer une réclamation basée sur la Digital Millennium Copyright Act (DMCA). Vous pouvez utiliser l’outil de suppression des droits d’auteur de Google pour effectuer ce qu’on appelle un retrait DMCA, qui demande la suppression de tout matériel protégé par le droit d’auteur.
Que se passe-t-il si c’est du contenu qui vous concerne mais pas sur un site que vous possédez?
Si vous êtes dans l’UE, vous pouvez faire supprimer le contenu qui contient des informations vous concernant grâce à une ordonnance du tribunal pour le droit à l’oubli. Vous pouvez demander la suppression des informations personnelles en utilisant le formulaire de suppression de la confidentialité de l’UE.
Pour supprimer des images de Google, le moyen le plus simple est d’utiliser des robots.txt. Alors que le support non officiel pour la suppression de pages a été supprimé des robots.txt comme nous l’avons mentionné précédemment, le simple fait de refuser l’analyse des images est la bonne façon de supprimer des images.
Pour une seule image:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
Pour toutes les images:
User-agent: Googlebot-ImageDisallow: /
Pensées finales
La façon dont vous supprimez les URL est assez situationnelle. Nous avons parlé de plusieurs options, mais si vous ne savez toujours pas ce qui vous convient, reportez-vous à l’organigramme au début.
Vous pouvez également passer par l’outil de dépannage légal fourni par Google pour la suppression de contenu.
Vous avez des questions? Faites-le moi savoir sur Twitter.