- Eh? Vad grupperar SET, CUBE och ROLLUP i SQL?
- Varför skulle ROLLUP eller CUBE vara användbart för mig?
- är dessa standard SQL eller är de en Microsoft-enda sak?
- kan jag utesluta en eller flera kolumner från den samlade?
- vad grupperar uppsättningar då? Ska jag veta om dem?
- Varför skulle vi vilja kombinera kolumner i någon aggregering?
- finns det mer att gruppera uppsättningar än ett sätt att göra ’kuberna i’ la carte’?
- Varför tillhandahålls funktionerna gruppering() och Gruppering_id ()?
- Eh? Vad grupperar SET, CUBE och ROLLUP i SQL?
- varför skulle ROLLUP eller CUBE vara användbart för mig?
- är dessa standard SQL eller är de en Microsoft-enda sak?
- kan jag utesluta en eller flera kolumner från den samlade?
- vad grupperar uppsättningar då? Ska jag veta om dem?
- varför skulle vi vilja kombinera kolumner i någon aggregering?
- finns det mer att gruppera uppsättningar än ett sätt att göra ’kuberna i’ la carte’?
- varför tillhandahålls funktionerna gruppering() och Gruppering_id ()?
Eh? Vad grupperar SET, CUBE och ROLLUP i SQL?
CUBE, ROLLUP och GROUPING SET är valfria operatörer av GROUP BY-klausulen i Select-uttalandet för att göra rapporter med stora mängder information. De låter dig göra flera grupper av operationer i ett uttalande, vilket kan spara mycket tid och beräkningsinsats. De kan ge all information som behövs för rapportering, inklusive summor, samtidigt som de ger bra prestanda över stora tabeller och hjälper Frågeoptimeraren att utarbeta en bra exekveringsplan.
de extra ’superaggregerade’ raderna ger sammanfattningsvärden, vilket gör att du kan ha flera ’aggregeringar’ som summa() eller MAX() inom ett resultat. Nollorna inom dessa rader i resultatet är avsedda att betyda ’alla’ snarare än’okända’. Det låter dig få alla aggregeringar du behöver i ett pass genom bordet. På grund av närvaron av extra rader i resultaten tillhandahålls extrafunktioner GROUPING() och GROUPING_ID() för att indikera dessa extra ”superaggregerade” rader och vilka kolumner som aggregeras.
detta är mycket meningsfullt om du har ett program som behöver köra flera rapporter utan extra beräkning eller utan att gå tillbaka till databasen: du har allt du behöver i ett resultat.
ta detta standardexempel på en samlad (jag använder AdventureWorks 2012 Här)..
|
1
2
3
4
5
6
|
välj t. som region, t.name som territorium, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på S. Territoriid = T. Territoriid
grupp av T., T.namn, datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate)
med samlad
|
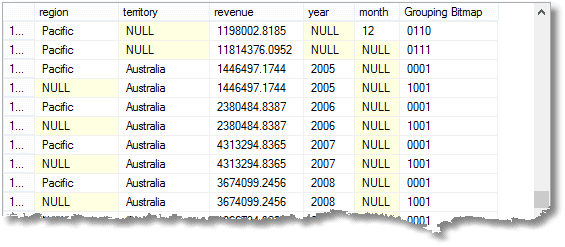
förutom den enkla gruppen med sammanlagda rader, med den totala förfallodagen för varje månad, som du skulle få med en enkel gruppering, får du också delsumma eller delsumma superaggregerade rader, och även en total rad. (här är början på resultatet)

det NULL jag har highlit betyder att raden är ett aggregat för ’alla’ månader 2005 i Frankrike (en del av Europa-regionen)
förutom allt detta får du den totala förfallodagen för varje år, för varje territorium och territoriell grupp, samt hela den totala förfallodagen. (från slutet)

dessa nollor betyder ’alla’, kom ihåg. Den sista raden är totalsumman, och ovanför är den totala för Stillahavsområdet. Ovan är Australiens bidrag till Stillahavsområdet. Den fjärde raden från botten är Australiens bidrag från 2008. Antalet grupperingar som returneras är ett mer än antalet uttryck i den sammansatta elementlistan som ges till gruppen genom uttalande.
för att få samma effekt utan att använda den samlade, skulle du behöva göra något liknande (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
19
20
21
|
;
med myGrouping (region, territorium, totalDue,,)
AS (välj t., t.name, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på S. Territoriid = T. Territoriid
grupp av t.name, t., datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate))
välj Region, territorium, totalDue, ,
från myGrouping
UNION ALL
välj Region, territorium, summa(totalDue), , NULL
från MYGROUPING grupp efter Region, territorium,
UNION ALL
välj region, territorium, summa(totaldue), null, null
från Mygrouping grupp efter region, territorium
Union alla
välj region, null, summa(TOTALDUE), null, null
från MYGROUPING grupp efter region
Union alla
välj null, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
’GROUPBY ROLLUP (t.,t.namn,datepart (ÅÅÅÅ, OrderDate), datepart(mm, OrderDate))’
|
denna nya syntax ger dig lite extra funktionalitet. Kom också ihåg att kolumnordningen påverkar utdatagrupperna för samlad och kan påverka antalet rader i resultatuppsättningen.
kuben gör samma allmänna sak, men istället för att tillhandahålla en hierarki av summor i ordnade superaggregerade rader, ger den alla ’superaggregerade’ permutationer (’symmetriska superaggregerade’ rader), de så kallade korstabuleringsraderna. Om du ville veta vilket territorium som gav flest beställningar i mars, eller vilket territorium som fungerade minst bra 2006, skulle du behöva en kub. Du ger alla möjliga summeringar i resultatet.
gruppering SET kan du finjustera ditt resultat för att ge mer specialiserad information utöver CUBE. Det kan ge sammanfattande information om kombinationer av dimensioner. Du kan få exakt samma resultat som i vårt samlade exempel genom att använda GRUPPUPPSÄTTNINGAR, men med mycket mer skrivning.
|
1
2
3
4
5
6
7
8
9
10
|
välj t. som region, t.name som territorium, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på S. Territoriid = T.Territoriid
gruppera genom att gruppera uppsättningar (
(T., T.name, datumdel (ÅÅÅÅ, orderdatum), datumdel (mm, orderdatum)),
(T., T.name, datumdel (ÅÅÅÅ, orderdatum),
(T., T.name),
(T.),
())
|
detta är bara för att visa hur de relaterar. I verkligheten skulle du tillgripa GRUPPERINGSSATSER för att få resultat som är omöjliga med samlad eller kub.
nästan alla dessa sammanfattningar kan erhållas genom att bara Gruppera efter, men bara genom att upprepade gånger gruppera resultatet av en grupp efter, eller genom att mer än en passerar genom data.
När du använder Cube, ROLLUP eller GRUPPERINGSSATSER kan du inte använda det distinkta sökordet i dina aggregerade uttryck, till exempel AVG (distinkt kolumnnamn), COUNT (distinkt kolumnnamn) och SUM (distinkt kolumnnamn)
varför skulle ROLLUP eller CUBE vara användbart för mig?
ROLLUP och CUBE hade sin storhetstid före SSAS. De var användbara för att tillhandahålla samma typ av anläggningar som erbjuds av kuben i OLAP. Den har dock fortfarande sina användningsområden. I AdventureWorks är det överdrivet, men om du hanterar stora datamängder behöver du bara överföra dina data en gång och göra så mycket som möjligt på data som har aggregerats. Händelser som hänt tidigare kan inte ändras, så det är sällan nödvändigt att behålla historiska data på ett aktivt OLTP-system. Istället behöver du bara behålla de aggregerade uppgifterna på den detaljnivå (’granularitet’) som krävs för alla förutsebara rapporter.
Tänk dig att du är ansvarig för att rapportera på en telefonbrytare som har två miljoner eller så samtal om dagen. Om du behåller alla dessa samtal på din OLTP-server kommer du snart att hitta SQL Server som arbetar över användningsrapporter. Du måste behålla den ursprungliga samtalsinformationen under en lagstadgad tidsperiod, men du bestämmer från företaget att de högst bara är intresserade av antalet samtal på en minut. Då har du minskat ditt lagringskrav på OLTP-servern till 1.4% av vad det var, och samtalsposterna kan arkiveras till en annan SQL-Server för ad hoc-frågor och Kundutlåtanden. Det kommer sannolikt att vara en besparing värd att göra. Kuben och samlade klausuler kan du även lagra radsummor, kolumnsummor och totalsummor utan att behöva göra en tabell, eller grupperade index, genomsökning av sammanfattningstabellen.
så länge ändringar inte görs retroaktivt till dessa data, och alla tidsperioder är fullständiga, behöver du aldrig upprepa eller ändra aggregeringarna baserat på tidigare tidsperioder, även om totalsummor måste skrivas över!.
Låt oss låtsas, men använder AdventureWorks2012 så att du kan spela tillsammans.
För det första skapar vi gram-sammanfattningstabellen.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
Lägg märke till att vi lägger till extra ” bit ” kolumner som berättar vilka rader som innehåller sammanfattningsraderna. Om du felaktigt lägger till dem i ytterligare aggregeringar får du några allvarligt uppblåsta resultat. Du kan inte använda Grouping() eller Grouping_ID på det sparade resultatet, självklart, så du borde ge något i stället.
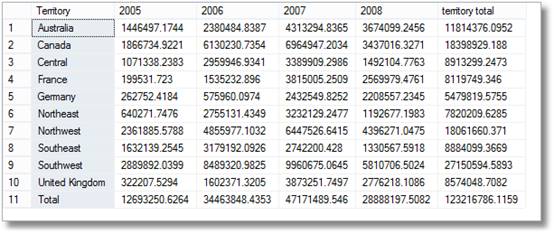
Nu kan vi producera pivottabellen mycket snabbt
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
– nu kan vi skapa en enkel pivottabell med rad och
— column totals
välj område,
summa(fall när 2005 då intäkter annat 0 slut) som,
summa(fall när 2006 då intäkter annat 0 slut) som,
summa(fall när 2007 då intäkter annat 0 slut) som,
summa(fall när 2008 då intäkter annat 0 slut) som,
Summa(intäkter) som
från #AggregationTable
där ISGROUPINGROW =0
grupp efter territorium
UNION ALL
välj ’total’, summa(fall när 2005 då intäkter annars 0 slut) som,
summa(fall när 2006 då intäkter annat 0 slut) som,
summa(fall när 2007 då intäkter annat 0 slut) som ,
summa(fall när 2008 då intäkter annars 0 slut) som ,
Summa(intäkter) som
från #AggregationTable
var isYearGroup =0 och ISMONTHGROUP=1
|
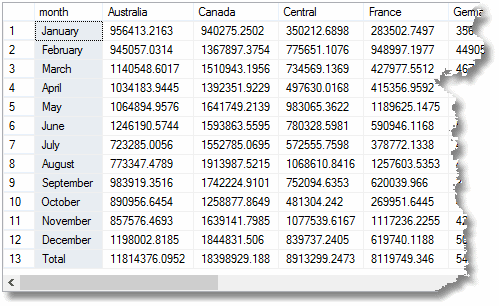
så det finns korta leenden från cheferna om att se detta, men då säger de starkt ’Jag är säker på att jag också bad om en uppdelning efter territorium per månad
med en kort skratt gör du det här.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
välj
datename(månad,dateadd(Månad, ,’01 dec 2000′)) AS ,
sum(Case territory när ’Australien’ sedan revenue ELSE 0 END) AS ,
sum(CASE territory När ’Kanada’ då revenue ELSE 0 END) AS ,
sum(CASE territory när ’0 slut) som ,
summa(fallområde när’ Frankrike ’då intäkter annat 0 slut) som ,
summa(fallområde när’ Tyskland ’då intäkter annat 0 slut) som ,
summa(fallområde när’ nordost ’då intäkter annat 0 slut) som ,
summa(fallområde när’ nordost ’ då intäkter annat 0 slut) som,
summa (fallområde När ’nordväst’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’sydost’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’sydväst’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’Storbritannien’ då intäkter annat 0 slut) som ,
Summa(intäkter) som
från #AggregationTable
var ISGROUPINGROW =0
grupp efter månad
UNION ALL
välj
’total’,
summa(case Territory när ’Australien’ då intäkter annars 0 End) som ,
summa(Case Territory när ’Kanada’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’Central’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’Frankrike’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’Tyskland’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’nordost’ då intäkter annat 0 slut) som ,
summa(FALLOMRÅDE när ’Northwest’ då intäkter annat 0 slut) som ,
summa(fall territorium när ’sydost’ då intäkter annat 0 slut) som ,
summa(fall territorium när ’sydväst’ då intäkter annat 0 slut) som ,
summa(fall territorium när ’Storbritannien’ då intäkter annars 0 slut) som ,
Summa(intäkter) som
från #AggregationTable
där isGroupingrow =0
|
men om du hade använt kub istället för samlad, skulle den sista ’totala’ raden redan beräknas. I ett verkligt exempel skulle det kosta tid att göra rapporten. Du kan göra en kub på upp till tio dimensioner; även om de tenderar att bulk upp aggregeringen, de är inte alltför kostsamma.
är dessa standard SQL eller är de en Microsoft-enda sak?
dessa är nu standard ANSI SQL från 1999, men med CUBE och med ROLLUP introducerades först av Microsoft. Denna inkludering är något överraskande genom att de introducerar en andra betydelse, ’allt’, för nollvärdet förutom ’okänt’. När Microsoft först introducerade CUBE och ROLLUP var syntaxen något annorlunda, men båda formerna är tillåtna i SQL Server. Endast en syntaxstil kan användas i ett enda select-uttalande, och du bör använda ISO-kompatibel syntax för allt nytt arbete.
kan jag utesluta en eller flera kolumner från den samlade?
Om du vill! Föreställ dig att jag inte ville ha en super-aggregerad summa för alla regioner (t.)
|
1
2
3
4
5
6
|
välj t. som region, t.name som territorium, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på S. Territoriid = T. Territoriid
grupp av T., samlad (t.name, datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate))
|
här använder vi ANSI SQL 2006-kompatibel syntax. Du kan göra samma sak med en kub. Jag har aldrig hittat en praktisk användning för detta men du kan komma över det
vad grupperar uppsättningar då? Ska jag veta om dem?
gruppuppsättning innebär att du ber SQL att gruppera resultatet flera gånger. Du kan använda syntaxen GRUPPERINGSSATSER för att ange exakt vilka aggregeringar som ska beräknas. Här är ett exempel.
|
1
2
3
4
5
6
|
välj t. som region, t.name som territorium, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på s.Territoriid = T. Territoriid
Gruppera efter t., gruppera uppsättningar(samlad (t.name),
samlad(datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate)))
|
Här ber du om uppdelning efter territoriegrupp för varje månad varje år med månad och år, följt av en sammanfattande summa per territorium namn, men utan en total summa. Till skillnad från den samlade får du samma resultat oavsett ordningen på kolumnerna inom varje gruppuppsättning och ordningen på GRUPPUPPSÄTTNINGARNA.
GRUPPERINGSSATSER kan ge dig exakt vad kub och samlad ger dig och mycket mer Förutom. Som du kan se med det här sista exemplet kan du använda standard ’table d’ h jacobte ’CUBE och samlad blandad tillsammans med DIREKTUTTRYCKTA grupperingssatser för ’sacrib la carte’.
varför skulle vi vilja kombinera kolumner i någon aggregering?
där två kolumner ska kombineras i vissa rapporter är det användbart att deklarera en aggregering som kombinerar två kolumner. I det första exemplet kombinerar vi år och månad för den samlade, med effekten att begränsa summan till bara varje territorium,
|
1
2
3
4
5
6
7
|
–få summorna för varje territorium endast – inga summor för varje region eller år
välj t. som region, t.namn som territorium, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på S. Territoriid = T. Territoriid
grupp av T., t.name, samlad
((datepart( ÅÅÅÅ, OrderDate), datepart(mm, OrderDate)))
|
den extra fästet i SAMLINGSKLAUSULEN har medfört att aggregeringarna begränsas till bara territoriet och månaden/året. Lämna dem ut, och du får summor för varje år.
|
1
2
3
4
5
6
7
8
9
10
|
detta kan vara mycket användbart för vissa data. Vi har undvikit att behöva kombinera kolumner här. Om du skulle göra en kub, och termerna för territorier använde orden som ’Norra’ eller ’södra’ för att beskriva ett territorium i mer än en region, skulle du ha några bisarra aggregeringar som gäller för ’norra’ territorier som inte är relaterade. Genom att kombinera kolumner skulle du undvika detta.
finns det mer att gruppera uppsättningar än ett sätt att göra ’kuberna i’ la carte’?
jag är inte säker på att jag skulle vara blyg om att ställa denna fråga. SQL:1999S GRUPPUPPSÄTTNINGAR ger en rik rekursiv syntax som låter dig aggregera kombinationer av kolumner och definiera alla typer av esoteriska rapporter som ger upp till tio dimensioner. Aggregeringarna kan kapslas och du kan häcka kuber inom samlade och Nest ROLLUPs inom kuber. Du måste läsa en specialpublikation för att ta reda på mer om detta.
varför tillhandahålls funktionerna gruppering() och Gruppering_id ()?
det är inte riktigt bra att använda NULL för att beteckna att en kolumn är en aggregering. Problemet är att om en grupperingskolumn innehåller null-värden anses alla null-värden vara lika och placeras i en enda NULL-grupp som maskeras som en sammanfattning. För att komma runt den uppenbara svårigheten med NULL-värden i originaldata tillhandahålls två funktioner: gruppering() och Grouping_ID().
funktionenGrouping() skickas namnet på en kolumn som deltog i uppsättningen samlad, kub eller gruppering. Den returnerar noll om den här raden är en sammanfattning för den här kolumnen med ett NULL-värde som betyder ’alla’ eller om det innehåller ett värde.
GROUPING_ID-funktionen skickas en lista som exakt måste matcha uttrycket i grupp för lista. GROUPING_ID skapas som en bitmapp för respektive sammanfattningskolumner. Om till exempel kolumnen territorium har en NULL som betyder ’alla’ territorier snarare än ett namn på ett territorium, och det är listat som den andra kolumnen, är den andra biten från vänster inställd. Detta heltal returneras sedan.
Grouping_ID() används vanligtvis för att ange om raden är en primär eller sekundär aggregering (0 eller >0) och, om sekundär, utesluts sedan från någon ytterligare grupp genom manipulation.
det anses vanligtvis vara god praxis att inkludera en bitkolumn för varje dimension (till exempel”territorium”eller” Region ”i vårt exempel) som ställs in om raden är en sammanfattning för den dimensionen, tillsammans med ett Grouping_ID() – värde för att hjälpa till med ytterligare gruppering av resultatet.
för att illustrera hur Grouping_ID faktiskt fungerar, här får vi titta på hur bitarna i Grouping_ID ställs in enligt typen av sammanfattning. Vi använder Phil factors funktion ToBinaryString för att visa bitarna.
|
1
2
3
4
5
6
7
8
9
|
välj t. som region, t.namn som territorium, summa(TotalDue) som intäkter,
datepart(ÅÅÅÅ, OrderDate) som , datepart (mm, OrderDate) som ,
höger (
dbo.ToBinaryString (–lista alla gruppen efter objekt som de är
Grouping_ID(t., t.name, datepart(ÅÅÅÅ,OrderDate), datepart(mm,OrderDate))
), 4) AS-använd bara de fyra sista tecknen eftersom vi har fyra kolumner i vår lista.
från försäljning.SalesOrderHeader s
inre gå försäljning.SalesTerritory T på S. Territoriid = T. Territoriid
grupp av kub (t., t.namn, datepart(ÅÅÅÅ, OrderDate),datepart(mm, OrderDate))
|
detta ger (bara ett prov naturligtvis)…