
det är en viktig punkt att förstå. Inte bara kommer att använda fel metod ibland leda till att sidor inte tas bort från indexet som avsett, men det kan också ha en negativ effekt på SEO.
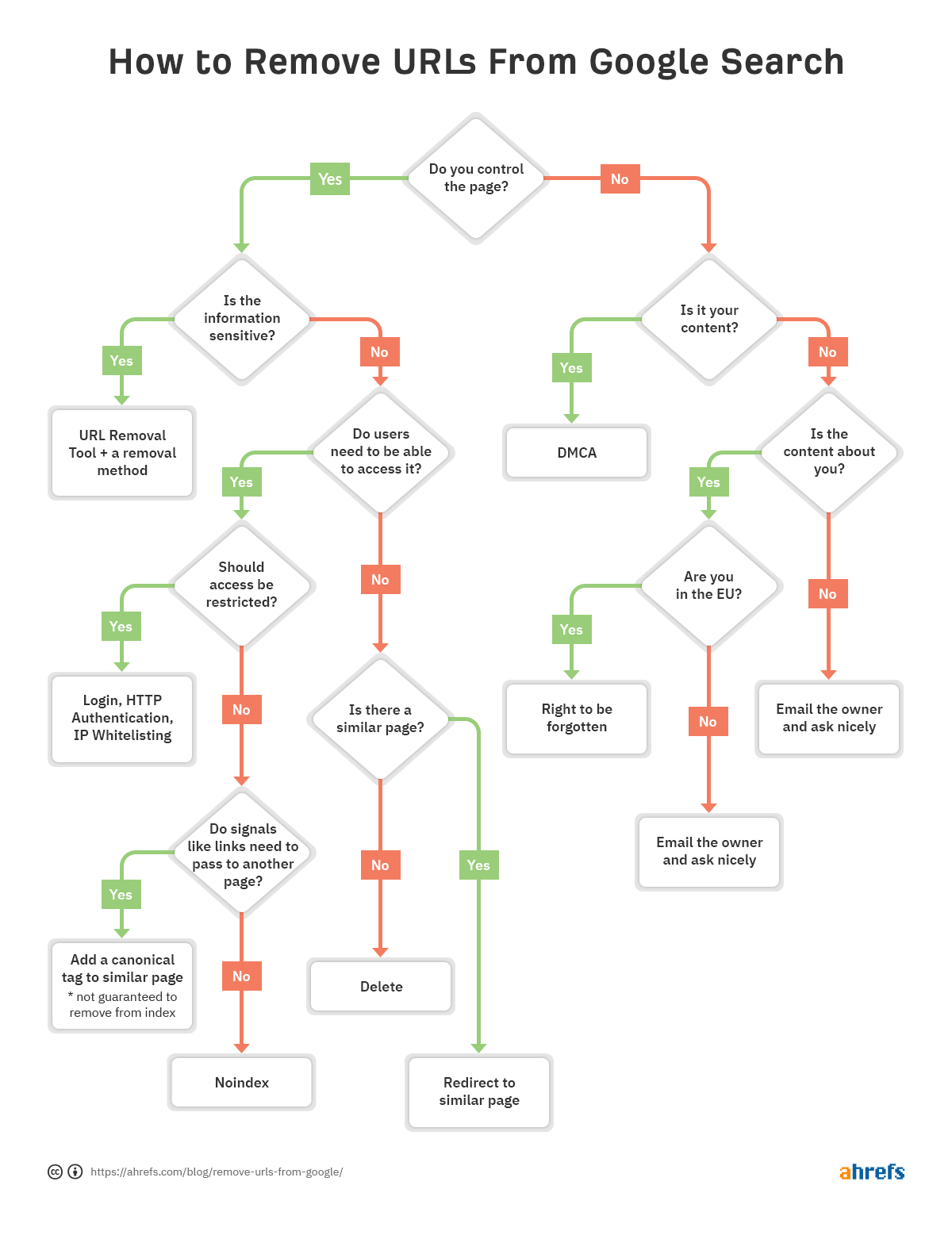
för att hjälpa dig att snabbt bestämma vilken metod för borttagning som är bäst för dig, gjorde vi ett flödesschema så att du kan hoppa till relevant avsnitt i artikeln.
i det här inlägget lär du dig:
- hur man kontrollerar om en URL är indexerad
- fem sätt att ta bort webbadresser från Google
- hur man prioriterar borttagningar
- vanliga borttagningsfel för att undvika
- hur man tar bort innehåll som inte finns på din webbplats
- hur man tar bort bilder
vad jag vanligtvis ser SEO: er göra för att kontrollera om innehållet är indexerat är använd en webbplats: sök i Google (t.ex. webbplats:https://ahrefs.com). Medan webbplatsen: sökningar kan vara användbara för att identifiera sidor eller delar av en webbplats som kan vara problematiska om de visas i sökresultaten, du måste vara försiktig eftersom de inte är vanliga frågor och kommer faktiskt inte att berätta om en sida är indexerad. De kan visa sidor som är kända för Google, men det betyder inte att de är berättigade att visa i normala sökresultat utan operatören site:.
till exempel kan site: – sökningar fortfarande visa sidor som omdirigerar eller kanoniseras till en annan sida. När du ber om en viss webbplats kan Google visa en sida från den domänen med innehåll, titel och beskrivning från en annan domän. Ta till exempel moz.com som brukade vara seomoz.org. alla vanliga användarfrågor som leder till sidor på moz.com kommer att visa moz.com i SERPs, medan site:seomoz.org kommer att visa seomoz.org i sökresultaten som visas nedan.
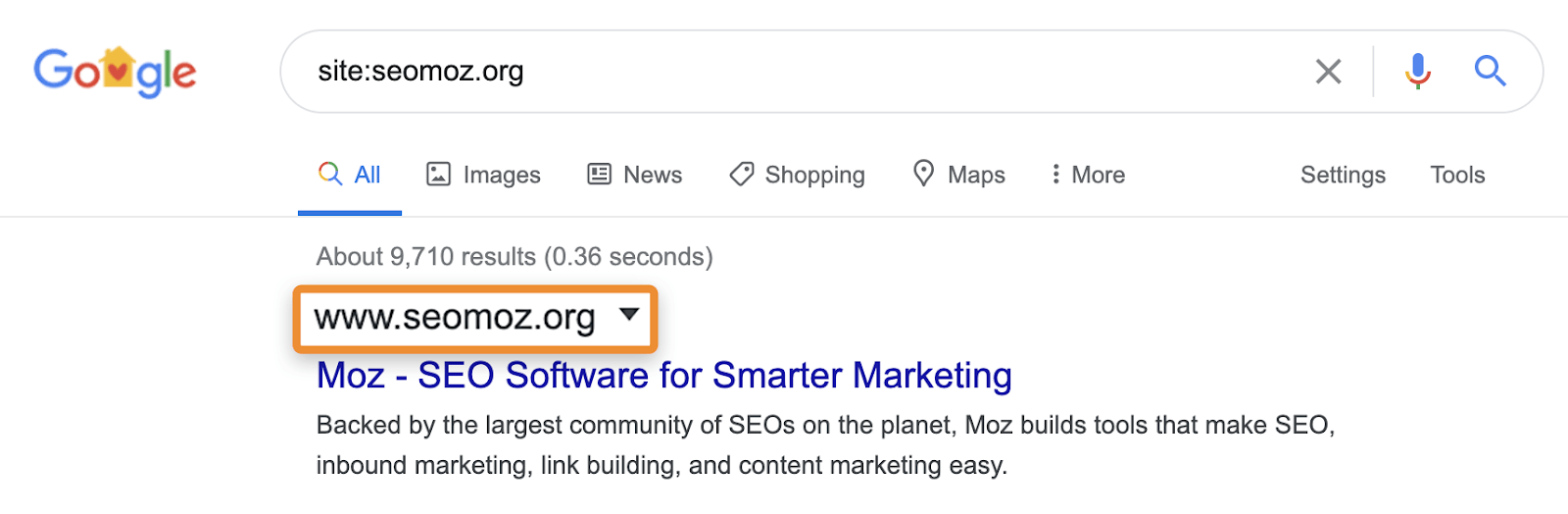
anledningen till att detta är en viktig skillnad är att det kan leda SEO att göra misstag som att aktivt blockera eller ta bort webbadresser från indexet för den gamla domänen, vilket förhindrar konsolidering av signaler som PageRank. Jag har sett många fall med domänmigrationer där folk tror att de gjorde ett misstag under migreringen eftersom dessa sidor fortfarande visar för site:old-domain.com sökningar och slutar aktivt skada deras webbplats när de försöker ”fixa” problemet.
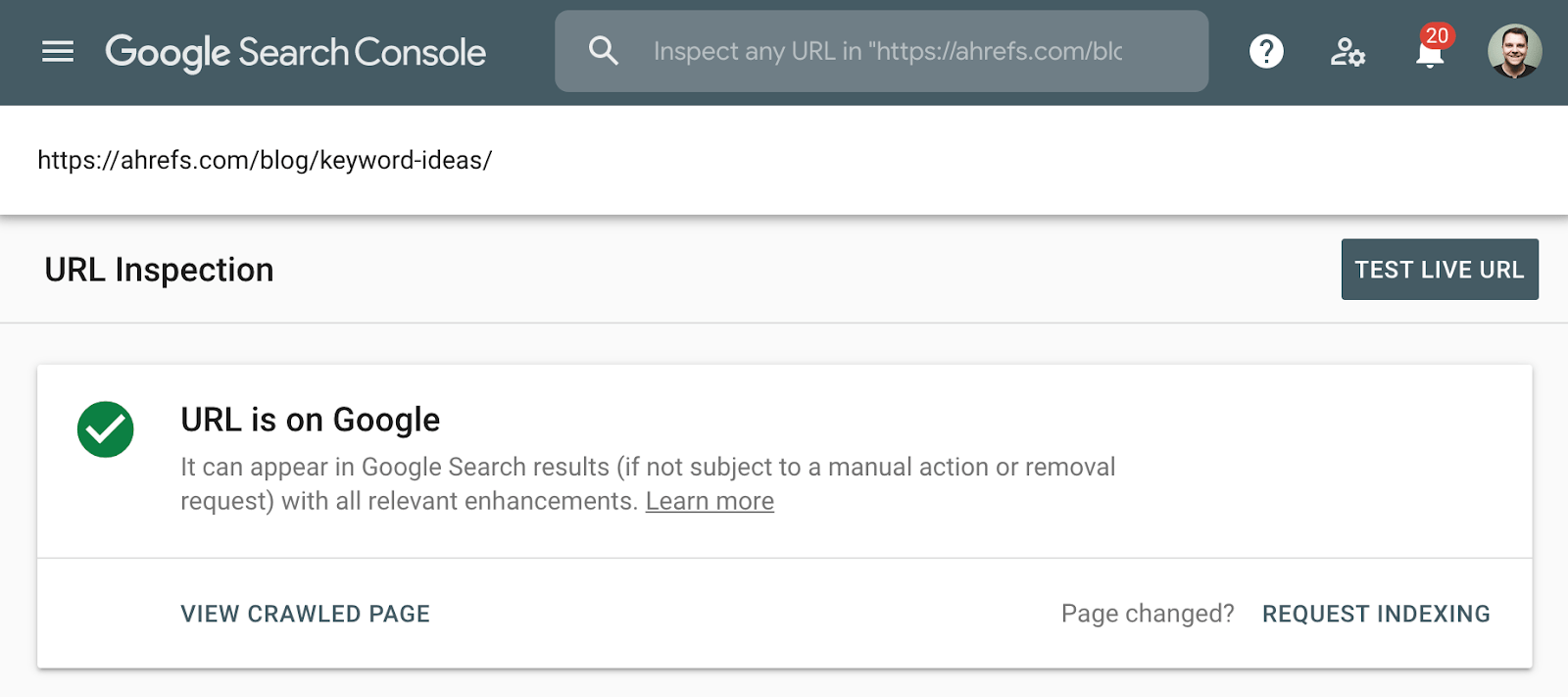
den bättre metoden för att kontrollera indexering är att använda Indextäckningsrapporten i Google Search Console eller URL-Inspektionsverktyget för en enskild URL. Dessa verktyg berättar om en sida är indexerad och ger ytterligare information om hur Google behandlar sidan. Om du inte har tillgång till detta, sök bara på Google efter hela webbadressen till din sida.
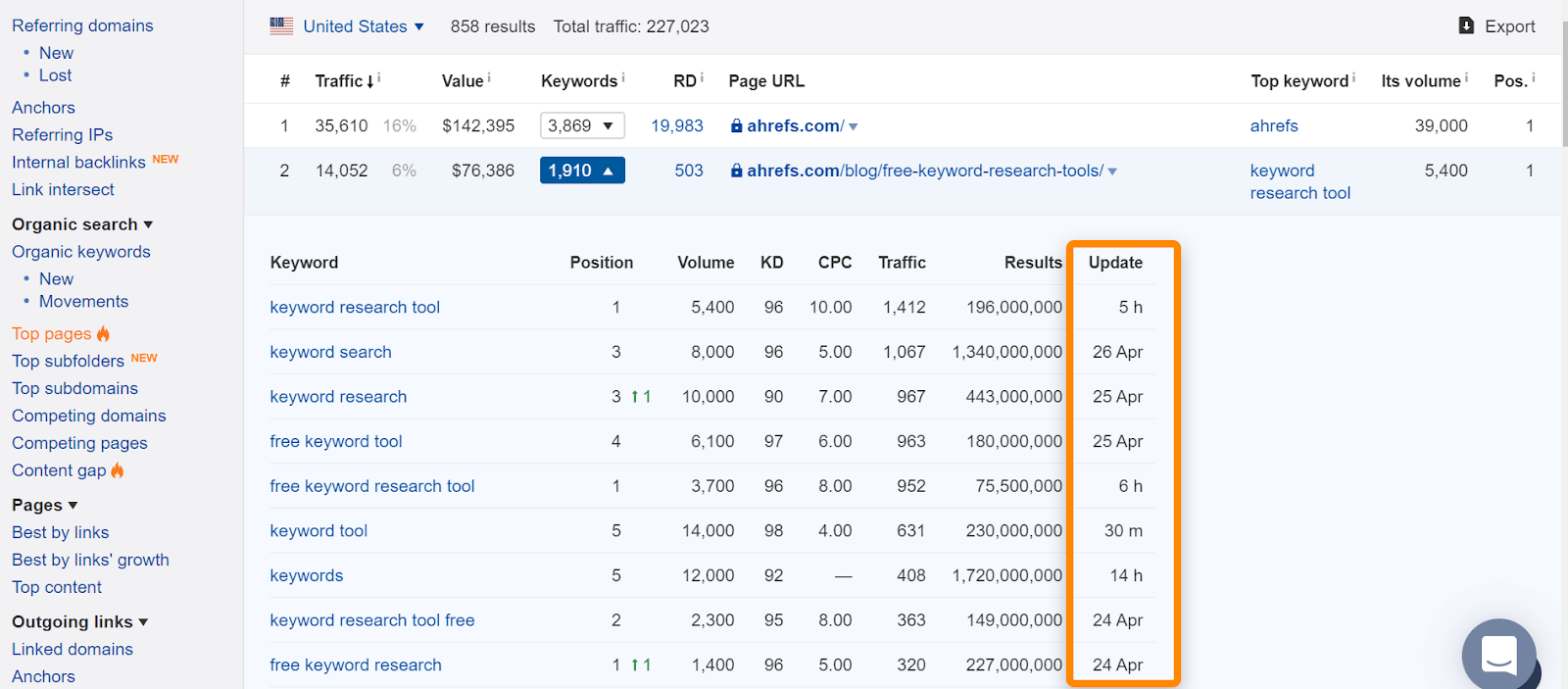
i Ahrefs, om du hittar sidan i vår” Top pages ” – rapport eller ranking för organiska nyckelord, betyder det vanligtvis att vi såg den rankning för normala sökfrågor och är en bra indikation på att sidan indexerades. Observera att sidorna indexerades när vi såg dem, men det kan ha ändrats. Kontrollera datumet vi senast såg sidan för en fråga.
om det finns ett problem med en viss URL och det behöver tas bort från indexet, följ flödesschemat i början av artikeln för att hitta rätt borttagningsalternativ och hoppa sedan till lämpligt avsnitt nedan.
om du tar bort sidan och serverar antingen en 404 (Hittades inte) eller 410 (borta) statuskod, kommer sidan att tas bort från indexet strax efter att sidan har genomsökts igen. Tills den tas bort kan sidan fortfarande visas i sökresultaten. Och även om själva sidan inte längre är tillgänglig kan en cachad version av sidan vara tillfälligt tillgänglig.
När du kanske behöver ett annat alternativ:
- jag behöver mer omedelbar borttagning. Se avsnittet URL removal tool.
- jag behöver konsolidera signaler som länkar. Se avsnittet kanonisering.
- jag behöver sidan tillgänglig för användare. Se om avsnitten noindex eller begränsa åtkomst passar din situation.
- Borttagningsalternativ 2: Noindex
- Borttagningsalternativ 3: begränsa åtkomst
- Borttagningsalternativ 4: URL Removal Tool
- Borttagningsalternativ 5: Canonicalization
- Noindex i robotar.txt
- blockering från krypning i robotar.Txt
- Nofollow
- Noindex och canonical till en annan URL
- Noindex, vänta på att Google ska genomsöka och sedan blockera från genomsökning
- vad händer om det är innehåll om dig men inte på en webbplats du äger?
- slutliga tankar
Borttagningsalternativ 2: Noindex
en noindex meta robots-tagg eller X-robots header-svar kommer att berätta för sökmotorer att ta bort en sida från indexet. Meta robots-taggen fungerar för sidor där X-robots-svaret fungerar för sidor och ytterligare filtyper som PDF-filer. För att dessa taggar ska kunna ses måste en sökmotor kunna genomsöka sidorna – så se till att de inte är blockerade i robotar.txt. Observera också att borttagning av sidor från indexet kan förhindra konsolidering av länk och andra signaler.
exempel på en meta robotar noindex:
<meta name="robots" content="noindex">
exempel på X‑robots noindex-taggen i rubriken svar:
HTTP/1.1 200 OKX-Robots-Tag: noindex
När du kanske behöver ett annat alternativ:
- jag vill inte att användarna ska komma åt dessa sidor. Se avsnittet begränsa åtkomst.
- jag behöver konsolidera signaler som länkar. Se avsnittet kanonisering.
Borttagningsalternativ 3: begränsa åtkomst
Om du vill att sidan ska vara tillgänglig för vissa användare men inte sökmotorer, är det du förmodligen vill ha ett av dessa tre alternativ:
- någon form av inloggningssystem;
- HTTP-autentisering (där ett lösenord krävs för åtkomst);
- IP-vitlistning (som endast tillåter specifika IP-adresser att komma åt sidorna)
denna typ av inställning är bäst för saker som interna nätverk, innehåll endast för medlemmar eller för iscensättning, test eller utvecklingswebbplatser. Det gör det möjligt för en grupp användare att komma åt sidan, men sökmotorer kommer inte att kunna komma åt dem och kommer inte att indexera sidorna.
När du kanske behöver ett annat alternativ:
- jag behöver mer omedelbar borttagning. Se avsnittet URL removal tool. I det här fallet kanske du vill ha mer omedelbar borttagning om innehållet du försöker dölja har cachats och du måste förhindra att användare ser det innehållet.
Borttagningsalternativ 4: URL Removal Tool
namnet på det här verktyget från Google är något vilseledande eftersom det fungerar är att det tillfälligt kommer att dölja innehållet. Google kommer fortfarande att se och genomsöka detta innehåll, men sidorna visas inte för användare. Denna tillfälliga effekt varar i sex månader i Google, medan Bing har ett liknande verktyg som varar i tre månader. Dessa verktyg bör användas i de mest extrema fallen för saker som säkerhetsproblem, dataläckor, personligt identifierbar information (PII) etc. För Google använder du borttagningsverktyget och för Bing, se hur du blockerar webbadresser.
Du måste fortfarande använda en annan metod tillsammans med borttagningsverktyget för att faktiskt få sidorna borttagna under en längre period (noindex eller delete) eller hindra användare från att komma åt innehållet om de fortfarande har länkarna (radera eller begränsa åtkomsten). Detta ger dig bara ett snabbare sätt att dölja sidorna medan borttagningen har tid att bearbeta. Begäran kan ta upp till en dag att behandla.
Borttagningsalternativ 5: Canonicalization
När du har flera versioner av en sida och vill konsolidera signaler som länkar till en enda version, vad du vill göra är någon form av canonicalization. Detta är främst för att förhindra duplicerat innehåll medan du konsoliderar flera versioner av en sida till en enda indexerad URL.
Du har flera kanoniseringsalternativ:
- Canonical tag. Detta anger en annan URL som den kanoniska versionen eller den version du vill ska visas. Om sidorna är dubbla eller mycket lika, borde det vara bra. När sidorna är för olika kan det kanoniska ignoreras eftersom det är en ledtråd och inte ett direktiv.
- omdirigeringar. En omdirigering tar en användare och en sökbot från en sida till en annan. 301 är den vanligaste omdirigeringen av SEO, och det berättar för sökmotorerna att du vill att den slutliga webbadressen ska vara den som visas i sökresultaten och var signalerna konsolideras. EN 302 eller tillfällig omdirigering berättar för sökmotorer att du vill att den ursprungliga webbadressen ska vara den som ska förbli i indexet och att konsolidera signaler där.
- URL-parameterhantering. En parameter läggs till i slutet av webbadressen och innehåller vanligtvis ett frågetecken, som ahrefs.com?this=parameterdet här verktyget från Google låter dig berätta för dem hur man behandlar webbadresser med specifika parametrar. Du kan till exempel ange om parametern ändrar sidinnehållet eller om det bara är tänkt att spåra användningen.
Om du har flera sidor att ta bort från Googles index, bör de prioriteras i enlighet därmed.
högsta prioritet: dessa sidor är vanligtvis säkerhetsrelaterade eller relaterade till konfidentiella data. Detta inkluderar innehåll som innehåller personuppgifter (PII), kunddata eller proprietär information.
Medelprioritet: detta involverar vanligtvis innehåll som är avsett för en viss grupp användare. Företagets intranät eller medarbetarportaler, innehåll som endast är avsett för medlemmar och iscensättning, test eller utvecklingsmiljöer.
låg prioritet: dessa sidor involverar vanligtvis duplicerat innehåll av något slag. Några exempel på detta skulle inkludera sidor som serveras från flera webbadresser, webbadresser med parametrar och återigen kan inkludera iscensättning, test eller utvecklingsmiljöer.
Jag vill täcka några av de sätt jag brukar se borttagningar gjort felaktigt och vad som händer i varje scenario för att hjälpa människor att förstå varför de inte fungerar.
Noindex i robotar.txt
medan Google brukade inofficiellt stödja noindex i robotar.txt, det var aldrig en officiell standard och de har nu formellt tagit bort support. Många av de webbplatser som gjorde detta gjorde det felaktigt och skadade sig själva.
blockering från krypning i robotar.Txt
genomsökning är inte samma sak som indexering. Även om Google är blockerat från genomsökningssidor, om det finns några interna eller externa länkar till en sida kan de fortfarande indexera den. Google vet inte vad som finns på sidan eftersom de inte kommer att genomsöka den, men de vet att en sida finns och kommer till och med att skriva en titel som ska visas i sökresultaten baserat på signaler som ankartexten på länkar till sidan.
Nofollow
detta blir vanligtvis förvirrad för noindex, och vissa människor kommer att använda den på en sidnivå och förväntar sig att sidan inte ska indexeras. Nofollow är en ledtråd, och medan det ursprungligen stoppade länkar på sidan och enskilda länkar med nofollow-attributet från att genomsökas, är det inte längre fallet. Google kan nu genomsöka dessa länkar om de vill. Nofollow användes också på enskilda länkar för att försöka stoppa Google från att krypa igenom till specifika sidor och för PageRank sculpting. Återigen fungerar detta inte längre eftersom nofollow är en ledtråd. Tidigare, om sidan hade en annan länk till den, kunde Google fortfarande upptäcka från den här alternativa genomsökningsvägen.
Observera att du kan hitta nofollowed sidor i bulk med hjälp av detta filter i Sidutforskaren i Ahrefs Webbplatsrevision.
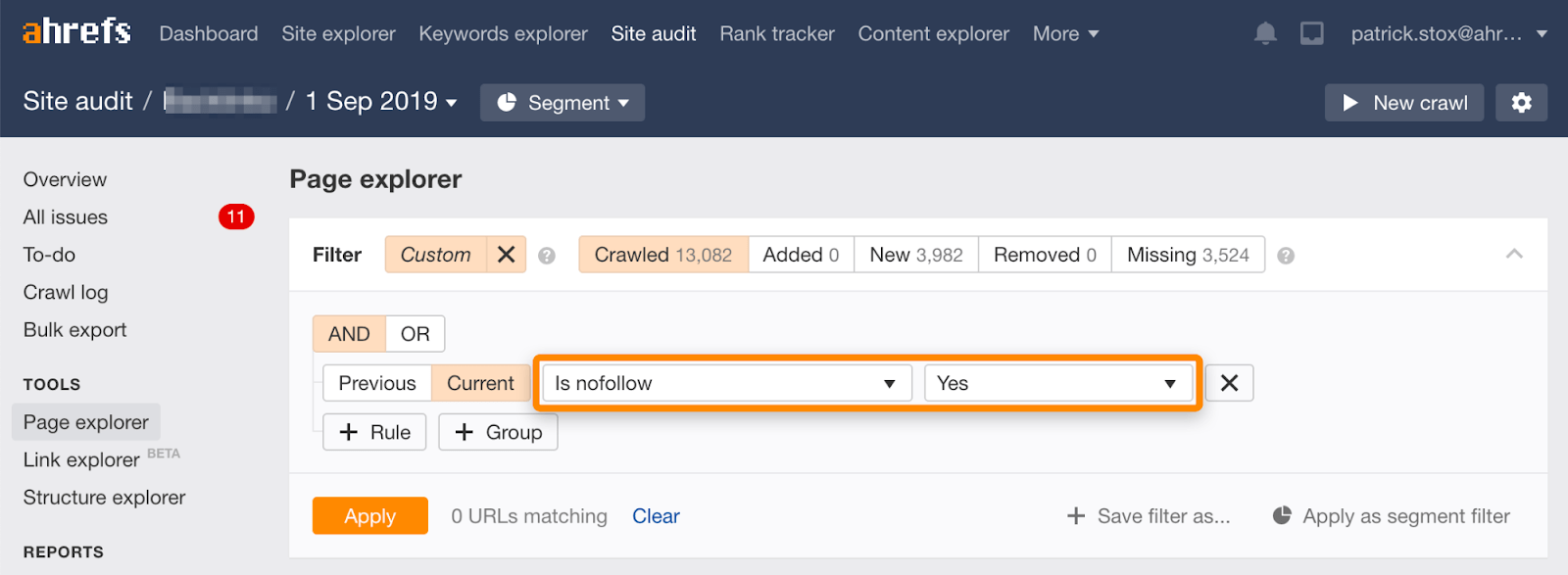
eftersom det sällan är vettigt att nofollow alla länkar på en sida, bör antalet resultat vara noll eller nära noll. Om det finns matchande resultat uppmanar jag er att kontrollera om nofollow-direktivet av misstag lades till i stället för noindex och att vid behov välja en lämpligare metod för borttagning.
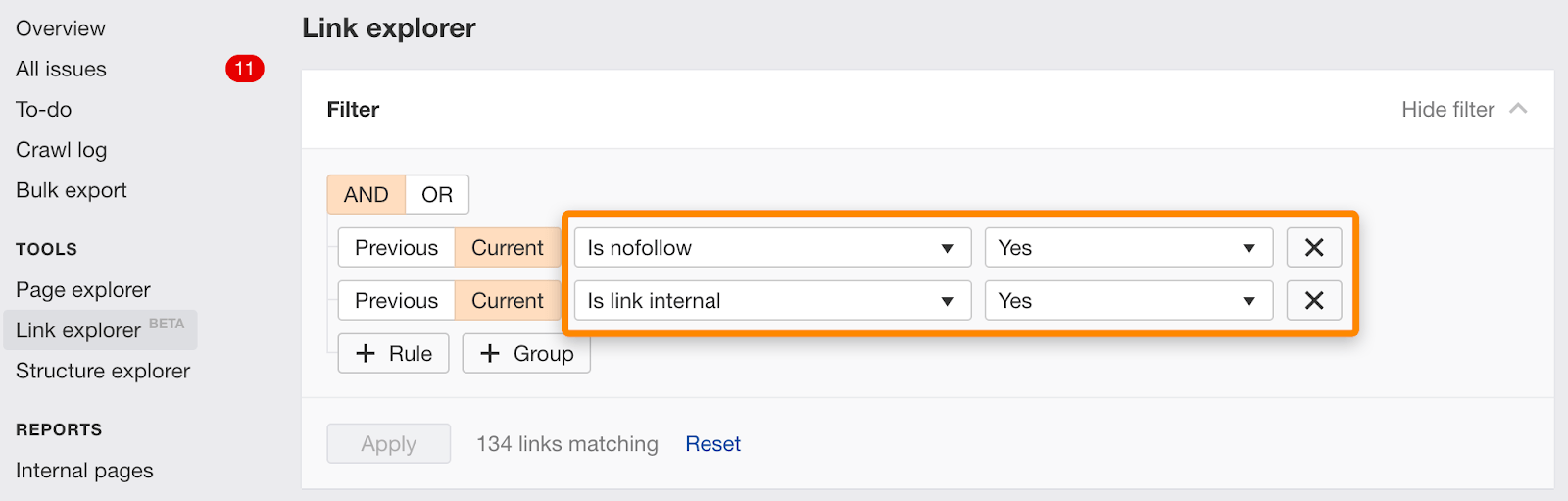
Du kan också hitta enskilda länkar markerade nofollow med det här filtret i Link Explorer.
Noindex och canonical till en annan URL
dessa signaler är motstridiga. Noindex säger att ta bort sidan från indexet, och canonical säger att en annan sida är den version som ska indexeras. Detta kan faktiskt fungera för konsolidering eftersom Google vanligtvis väljer att ignorera noindex och istället använda canonical som huvudsignal. Detta är dock inte ett absolut beteende. Det finns en algoritm involverad och det finns en risk att noindex-taggen kan vara signalen som räknas. Om så är fallet kommer sidorna inte att konsolideras ordentligt.
Observera att du kan hitta noindexed sidor med icke-självreferentiella canonicals med hjälp av denna uppsättning filter i Sidutforskaren i Site Audit:
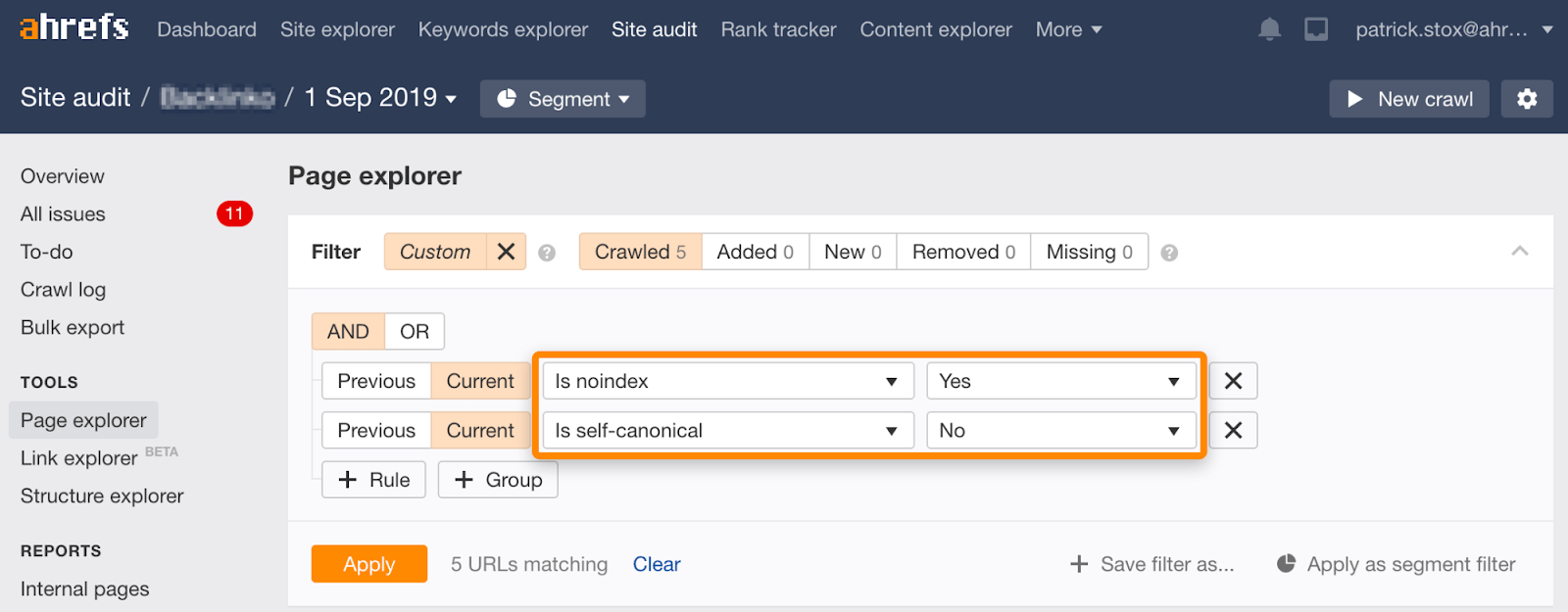
Noindex, vänta på att Google ska genomsöka och sedan blockera från genomsökning
det finns ett par sätt som detta vanligtvis händer:
- sidor är redan blockerade men indexeras, människor lägger till noindex och avblockerar så att Google kan genomsöka och se noindex och sedan blockera sidorna från att genomsöka igen.
- människor lägger till noindex-taggar för de sidor de vill ta bort och efter att Google har genomsökt och bearbetat noindex-taggen blockerar de sidorna från genomsökning.
hur som helst är det slutliga tillståndet blockerat från genomsökning. Om du kommer ihåg, tidigare pratade vi om hur krypning inte är detsamma som indexering. Även om dessa sidor är blockerade kan de fortfarande hamna i indexet.
om du äger innehållet som används på en annan webbplats kanske du kan lämna in ett krav baserat på Digital Millennium Copyright Act (DMCA). Du kan använda Googles verktyg för borttagning av upphovsrätt för att göra det som kallas en DMCA-borttagning, som begär borttagning av upphovsrättsskyddat material.
vad händer om det är innehåll om dig men inte på en webbplats du äger?
Om du är i EU kan du ta bort innehåll som innehåller information om dig tack vare ett domstolsbeslut för rätten att glömmas bort. Du kan begära att personuppgifter tas bort med hjälp av EU: s formulär för borttagning av personuppgifter.
för att ta bort bilder från Google är det enklaste sättet med robotar.txt. Medan det inofficiella stödet för att ta bort sidor togs bort från robotar.txt som vi nämnde tidigare är helt enkelt att inte tillåta genomsökning av bilder det rätta sättet att ta bort bilder.
För en enda bild:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
För alla bilder:
User-agent: Googlebot-ImageDisallow: /
slutliga tankar
hur du tar bort webbadresser är ganska situationsanpassat. Vi har pratat om flera alternativ, men om du fortfarande är förvirrad vilket är rätt för dig, se tillbaka till flödesschemat i början.
Du kan också gå igenom den juridiska felsökaren som tillhandahålls av Google för borttagning av innehåll.
har du frågor? Låt mig veta på Twitter.