Dernière mise à jour le 5 juillet 2019
La reconnaissance faciale est le problème de l’identification et de la vérification des personnes sur une photo par leur visage.
C’est une tâche qui est trivialement effectuée par les humains, même sous une lumière variable et lorsque les visages sont modifiés par l’âge ou obstrués par des accessoires et des poils du visage. Néanmoins, il est resté un problème de vision par ordinateur difficile pendant des décennies jusqu’à récemment.
Les méthodes d’apprentissage en profondeur sont capables d’exploiter de très grands ensembles de données de visages et d’apprendre des représentations riches et compactes de visages, permettant aux modèles modernes de fonctionner d’abord aussi bien et plus tard de surpasser les capacités de reconnaissance faciale des humains.
Dans cet article, vous découvrirez le problème de la reconnaissance faciale et comment les méthodes d’apprentissage en profondeur peuvent atteindre des performances surhumaines.
Après avoir lu cet article, vous saurez:
- La reconnaissance faciale est un vaste problème d’identification ou de vérification des personnes sur des photographies et des vidéos.
- La reconnaissance faciale est un processus composé de détection, d’alignement, d’extraction de fonctionnalités et d’une tâche de reconnaissance
- Les modèles d’apprentissage profond ont d’abord été approchés puis ont dépassé les performances humaines pour les tâches de reconnaissance faciale.
Lancez votre projet avec mon nouveau livre Deep Learning for Computer Vision, comprenant des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Commençons.

Une Introduction Douce à l’Apprentissage Profond pour la Reconnaissance Faciale
Photo de Susanne Nilsson, certains droits réservés.
- Aperçu
- Visages sur des photographies
- Vous voulez des résultats avec l’apprentissage en profondeur pour la vision par ordinateur?
- Processus de Reconnaissance automatique des visages
- Tâche de détection de visage
- Tâches de reconnaissance faciale
- Apprentissage profond pour la reconnaissance faciale
- Pour en savoir plus
- Livres
- Papiers de reconnaissance faciale
- Papiers de reconnaissance faciale en apprentissage profond
- Articles
- Résumé
- Développez des Modèles d’Apprentissage profond pour la Vision Aujourd’hui!
- Développez Vos Propres Modèles de Vision en Quelques Minutes
- Apportez enfin l’Apprentissage profond à vos projets de vision
Aperçu
Ce tutoriel est divisé en cinq parties; elles sont:
- Visages sur des photographies
- Processus de Reconnaissance Automatique des Visages
- Tâche de Détection des Visages
- Tâches de Reconnaissance des Visages
- Apprentissage profond pour la Reconnaissance des visages
Visages sur des photographies
Il est souvent nécessaire de reconnaître automatiquement les personnes sur une photographie.
Il existe de nombreuses raisons pour lesquelles nous pourrions vouloir reconnaître automatiquement une personne sur une photographie.
Par exemple :
- Nous pouvons vouloir restreindre l’accès à une ressource à une seule personne, appelée authentification faciale.
- Nous pouvons vouloir confirmer que la personne correspond à son identité, appelée vérification du visage.
- Nous pouvons vouloir attribuer un nom à un visage, appelé identification du visage.
Généralement, nous appelons cela le problème de la « reconnaissance faciale » automatique et cela peut s’appliquer à la fois aux photographies fixes ou aux visages dans les flux vidéo.
Les humains peuvent effectuer cette tâche très facilement.
Nous pouvons trouver les visages dans une image et commenter qui sont les gens, s’ils sont connus. Nous pouvons très bien le faire, par exemple lorsque les gens ont vieilli, portent des lunettes de soleil, ont des cheveux de couleur différente, regardent dans des directions différentes, etc. Nous pouvons le faire si bien que nous trouvons des visages où il n’y en a pas, comme dans les nuages.
Néanmoins, cela reste un problème difficile à réaliser automatiquement avec un logiciel, même après 60 ans ou plus de recherche. Jusqu’à peut-être très récemment.
Par exemple, la reconnaissance des images de visage acquises dans un environnement extérieur avec des changements d’éclairage et / ou de pose reste un problème largement non résolu. En d’autres termes, les systèmes actuels sont encore loin de la capacité du système de perception humaine.
— Reconnaissance faciale : Enquête documentaire, 2003.
Vous voulez des résultats avec l’apprentissage en profondeur pour la vision par ordinateur?
Suivez mon cours intensif gratuit de 7 jours par e-mail maintenant (avec un exemple de code).
Cliquez pour vous inscrire et obtenez également une version PDF Ebook gratuite du cours.
Téléchargez votre Mini-Cours GRATUIT
Processus de Reconnaissance automatique des visages
La reconnaissance faciale est le problème de l’identification ou de la vérification des visages sur une photographie.
Un énoncé général du problème de la reconnaissance automatique des visages peut être formulé comme suit:étant donné des images fixes ou vidéo d’une scène, identifier ou vérifier une ou plusieurs personnes dans la scène à l’aide d’une base de données stockée de visages
— Reconnaissance des visages:Une enquête documentaire, 2003.
La reconnaissance faciale est souvent décrite comme un processus qui comporte d’abord quatre étapes : la détection des visages, l’alignement des visages, l’extraction des caractéristiques et enfin la reconnaissance faciale.
- Détection de visage. Localisez un ou plusieurs visages dans l’image et marquez avec une boîte englobante.
- Alignement du visage. Normalisez le visage pour qu’il soit cohérent avec la base de données, comme la géométrie et la photométrie.
- Extraction de fonctionnalités. Extrayez les traits du visage qui peuvent être utilisés pour la tâche de reconnaissance.
- Reconnaissance faciale. Effectuer une mise en correspondance de la face avec une ou plusieurs faces connues dans une base de données préparée.
Un système donné peut avoir un module ou un programme distinct pour chaque étape, ce qui était traditionnellement le cas, ou peut combiner certaines ou toutes les étapes en un seul processus.
Un aperçu utile de ce processus est fourni dans le livre « Handbook of Face Recognition”, fourni ci-dessous:
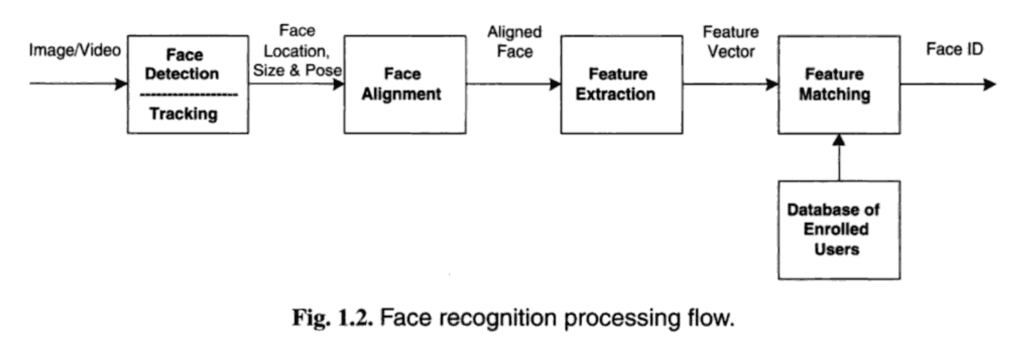
Aperçu des Étapes d’un Processus de reconnaissance faciale. Tiré du « Manuel de reconnaissance faciale », 2011.
Tâche de détection de visage
La détection de visage est la première étape non triviale de la reconnaissance faciale.
C’est un problème de reconnaissance d’objet qui nécessite à la fois que l’emplacement de chaque visage sur une photographie soit identifié (par exemple la position) et que l’étendue du visage soit localisée (par exemple avec une boîte englobante). La reconnaissance d’objet elle-même est un problème difficile, bien que dans ce cas, elle soit similaire car il n’y a qu’un seul type d’objet, par exemple des visages, à localiser, bien que les visages puissent varier énormément.
Le visage humain est un objet dynamique et présente un degré élevé de variabilité de son apparence, ce qui rend la détection de visage un problème difficile en vision par ordinateur.
— Détection des visages: Une enquête, 2001.
De plus, parce qu’il s’agit de la première étape d’un système de reconnaissance faciale plus large, la détection des visages doit être robuste. Par exemple, un visage ne peut pas être reconnu s’il ne peut pas être détecté au préalable. Cela signifie que les visages doivent être détectés avec toutes sortes d’orientations, d’angles, de niveaux de lumière, de coiffures, de chapeaux, de lunettes, de poils du visage, de maquillage, d’âges, etc.
En tant que processeur frontal visuel, un système de détection de visage devrait également être capable de réaliser la tâche indépendamment de l’éclairage, de l’orientation et de la distance de la caméra
– Détection de visage: Une enquête, 2001.
L’article de 2001 intitulé « Face Detection:A Survey » fournit une taxonomie des méthodes de détection des visages qui peuvent être largement divisées en deux groupes principaux:
- Basé sur les fonctionnalités.
- Basé sur l’image.
La détection des visages basée sur les fonctionnalités utilise des filtres fabriqués à la main qui recherchent et localisent des visages sur des photographies en fonction d’une connaissance approfondie du domaine. Ils peuvent être très rapides et très efficaces lorsque les filtres correspondent, bien qu’ils puissent échouer de manière spectaculaire lorsqu’ils ne le sont pas, par exemple en les rendant quelque peu fragiles.
make utilisez explicitement la connaissance du visage et suivez la méthodologie de détection classique dans laquelle les caractéristiques de bas niveau sont dérivées avant l’analyse basée sur les connaissances. Les propriétés apparentes du visage telles que la couleur de la peau et la géométrie du visage sont exploitées à différents niveaux du système.
— Détection des visages: Une enquête, 2001.
Alternativement, la détection des visages basée sur l’image est holistique et apprend à localiser et à extraire automatiquement les visages de l’image entière. Les réseaux de neurones entrent dans cette classe de méthodes.
address adresse la détection des visages comme un problème général de reconnaissance. Les représentations basées sur des images de visages, par exemple dans des tableaux d’intensité 2D, sont directement classées dans un groupe de visages à l’aide d’algorithmes d’apprentissage sans dérivation et analyse de caractéristiques. ces techniques relativement nouvelles intègrent implicitement la connaissance du visage dans le système par le biais de schémas de cartographie et de formation.
— Détection des visages: Une enquête, 2001.
La méthode dominante de détection des visages utilisée depuis de nombreuses années (et utilisée dans de nombreuses caméras) a peut-être été décrite dans l’article de 2004 intitulé « Robust Real-time Object Detection”, appelé la cascade du détecteur ou simplement « cascade ». »
Leur détecteur, appelé cascade de détecteurs, consiste en une séquence de classificateurs de visages simples à complexes et a suscité de nombreux efforts de recherche. De plus, detector cascade a été déployé dans de nombreux produits commerciaux tels que les smartphones et les appareils photo numériques. Bien que les détecteurs en cascade puissent trouver avec précision des faces verticales visibles, ils ne parviennent souvent pas à détecter des faces sous différents angles, par exemple une vue latérale ou des faces partiellement occultées.
— Détection de Visage Multi-vues À L’Aide De Réseaux De Neurones Convolutifs Profonds, 2015.
Pour un tutoriel sur le deep learning pour la détection de visage, voir:
- Comment effectuer la détection de visage avec le Deep Learning dans Keras
Tâches de reconnaissance faciale
La tâche de reconnaissance faciale est large et peut être adaptée aux besoins spécifiques d’un problème de prédiction.
Par exemple, dans l’article de 1995 intitulé « Reconnaissance humaine et machine des visages:Une enquête”, les auteurs décrivent trois tâches de reconnaissance faciale:
- Correspondance faciale: Trouvez la meilleure correspondance pour un visage donné.
- Similitude de visage: Trouvez les visages les plus similaires à un visage donné.
- Transformation du visage : Génère de nouveaux visages similaires à un visage donné.
Ils résument ces trois tâches distinctes comme suit :
L’appariement nécessite que l’image de visage correspondante candidate soit dans un ensemble d’images de visage sélectionnées par le système. La détection de similarité nécessite, en plus de l’appariement, que des images de visages soient trouvées similaires à un visage rappelé, cela nécessite que la mesure de similitude utilisée par le système de reconnaissance corresponde étroitement aux mesures de similitude utilisées par les applications de transformation humaines, ce qui nécessite que les nouvelles images créées par le système soient similaires aux souvenirs humains d’un visage.
— Reconnaissance humaine et machine des visages : Une enquête, 1995.
Le livre de 2011 sur la reconnaissance faciale intitulé « Handbook of Face Recognition » décrit deux modes principaux de reconnaissance faciale, comme:
- Vérification du visage. Une cartographie individuelle d’un visage donné par rapport à une identité connue (par exemple, est-ce la personne?).
- Identification du visage. Un mappage un à plusieurs pour un visage donné par rapport à une base de données de visages connus (par exemple, qui est cette personne?).
Un système de reconnaissance faciale est censé identifier automatiquement les visages présents dans les images et les vidéos. Il peut fonctionner dans l’un ou l’autre des deux modes : (1) vérification du visage (ou authentification) et (2) identification du visage (ou reconnaissance).
— Page 1, Manuel de reconnaissance faciale. 2011.
Nous pouvons décrire le problème de la reconnaissance faciale comme une tâche de modélisation prédictive supervisée formée sur des échantillons avec des entrées et des sorties.
Dans toutes les tâches, l’entrée est une photo qui contient au moins un visage, très probablement un visage détecté qui peut également avoir été aligné.
La sortie varie en fonction du type de prédiction requis pour la tâche ; par exemple :
- Il peut alors s’agir d’une étiquette de classe binaire ou d’une probabilité de classe binaire dans le cas d’une tâche de vérification de visage.
- Il peut s’agir d’une étiquette de classe catégorielle ou d’un ensemble de probabilités pour une tâche d’identification de visage.
- Il peut s’agir d’une métrique de similarité dans le cas d’une tâche de type similarité.
Apprentissage profond pour la reconnaissance faciale
La reconnaissance faciale est restée un domaine de recherche actif en vision par ordinateur.
L’une des méthodes d' »apprentissage automatique” les plus connues et les plus adoptées pour la reconnaissance faciale a peut-être été décrite dans l’article de 1991 intitulé « Face Recognition Using Eigenfaces. »Leur méthode, appelée simplement « Eigenfaces », a été une étape importante car elle a obtenu des résultats impressionnants et a démontré la capacité d’approches holistiques simples.
Les images de visage sont projetées sur un espace d’entités (« espace de visage”) qui code le mieux la variation parmi les images de visage connues. L’espace des visages est défini par les » faces propres”, qui sont les vecteurs propres de l’ensemble des faces ; elles ne correspondent pas nécessairement à des caractéristiques isolées telles que les yeux, les oreilles et le nez
— Reconnaissance des visages à l’aide de faces propres, 1991.
L’article de 2018 intitulé « Deep Face Recognition:A Survey » fournit un résumé utile de l’état de la recherche sur la reconnaissance faciale au cours des près de 30 dernières années, mettant en évidence la tendance générale allant des méthodes d’apprentissage holistiques (telles que les faces propres) à la détection de fonctionnalités artisanales locales, aux méthodes d’apprentissage superficielles, et enfin aux méthodes d’apprentissage en profondeur qui sont actuellement à la pointe de la technologie.
Les approches holistiques ont dominé la communauté de la reconnaissance faciale dans les années 1990. Au début des années 2000, les descripteurs locaux fabriqués à la main sont devenus populaires et l’approche d’apprentissage des fonctionnalités locales a été introduite à la fin des années 2000. les performances s’améliorent régulièrement d’environ 60% à plus de 90%, tandis que l’apprentissage en profondeur augmente les performances à 99,80% en seulement trois ans.
— Reconnaissance faciale profonde: Une enquête, 2018.
Compte tenu de la percée d’AlexNet en 2012 pour le problème plus simple de la classification des images, il y a eu une vague de recherches et de publications en 2014 et 2015 sur les méthodes d’apprentissage profond pour la reconnaissance faciale. Les capacités ont rapidement atteint des performances proches du niveau humain, puis ont dépassé les performances au niveau humain sur un ensemble de données de reconnaissance faciale standard en trois ans, ce qui représente un taux d’amélioration incroyable compte tenu des décennies d’efforts précédentes.
Il y a peut-être quatre systèmes d’étape sur l’apprentissage profond pour la reconnaissance faciale qui ont conduit ces innovations; ce sont: DeepFace, la série de systèmes DeepID, VGGFace et FaceNet. Abordons brièvement chacun.
DeepFace est un système basé sur des réseaux de neurones convolutifs profonds décrits par Yaniv Taigman, et al. de Facebook AI Research et Tel Aviv. Il a été décrit dans l’article de 2014 intitulé « DeepFace: Combler l’écart avec les Performances au Niveau Humain en matière de Vérification du Visage. »C’était peut-être le premier grand bond en avant en utilisant l’apprentissage en profondeur pour la reconnaissance faciale, atteignant des performances proches du niveau humain sur un ensemble de données de référence standard.
Notre méthode atteint une précision de 97,35% sur l’ensemble de données Labellised Faces in the Wild (LFW), réduisant l’erreur de l’état actuel de la technique de plus de 27%, approchant de près les performances au niveau humain.
– DeepFace: Combler l’écart avec les Performances au niveau Humain dans la Vérification du Visage, 2014.
Le DeepID, ou » Deep hidden IDentity features « , est une série de systèmes (par exemple DeepID, DeepID2, etc.), d’abord décrit par Yi Sun, et al. dans leur article de 2014 intitulé « Deep Learning Face Representation from Predicting 10,000 Classes. »Leur système a d’abord été décrit un peu comme DeepFace, bien qu’il ait été étendu dans des publications ultérieures pour prendre en charge les tâches d’identification et de vérification par une formation par perte contrastive.
Le principal défi de la reconnaissance faciale est de développer des représentations de caractéristiques efficaces pour réduire les variations intra-personnelles tout en élargissant les différences inter-personnelles. La tâche d’identification du visage augmente les variations inter-personnelles en séparant les caractéristiques DeepID2 extraites de différentes identités, tandis que la tâche de vérification du visage réduit les variations intra-personnelles en regroupant les caractéristiques DeepID2 extraites de la même identité, qui sont toutes deux essentielles à la reconnaissance faciale.
— Représentation faciale en Apprentissage profond par Identification conjointe – Vérification, 2014.
Les systèmes DeepID ont été parmi les premiers modèles d’apprentissage profond à obtenir des performances supérieures à celles de l’homme sur la tâche, par exemple DeepID2 a atteint 99,15% sur l’ensemble de données Labellised Faces in the Wild (LFW), soit une performance supérieure à celle de l’homme de 97,53%. Des systèmes ultérieurs tels que FaceNet et VGGFace ont amélioré ces résultats.
FaceNet a été décrit par Florian Schroff, et al. chez Google dans leur article de 2015 intitulé « FaceNet: Une Intégration Unifiée pour la Reconnaissance Faciale et le Clustering. »Leur système a obtenu des résultats à la pointe de la technologie et a présenté une innovation appelée « perte de triplets » qui a permis de coder efficacement les images en tant que vecteurs de caractéristiques, ce qui a permis de calculer rapidement la similarité et la correspondance via des calculs de distance.
FaceNet, qui apprend directement un mappage des images de visage vers un espace euclidien compact où les distances correspondent directement à une mesure de similitude de visage. Notre méthode utilise un réseau convolutif profond formé pour optimiser directement l’intégration elle-même, plutôt qu’une couche de goulot d’étranglement intermédiaire comme dans les approches d’apprentissage profond précédentes. Pour s’entraîner, nous utilisons des triplets de patchs faciaux appariés / non appariés grossièrement alignés générés à l’aide d’une nouvelle méthode d’extraction de triplets en ligne
– FaceNet: Une intégration unifiée pour la reconnaissance faciale et le Clustering, 2015.
Pour un tutoriel sur FaceNet, voir:
- Comment développer un Système de Reconnaissance Faciale Utilisant FaceNet dans Keras
Le VGGFace (faute de meilleur nom) a été développé par Omkar Parkhi, et al. du Groupe de géométrie visuelle (VGG) à Oxford et a été décrit dans leur article de 2015 intitulé « Reconnaissance faciale profonde. »En plus d’un modèle mieux ajusté, l’accent a été mis sur la façon de collecter un très grand ensemble de données d’entraînement et de l’utiliser pour former un modèle CNN très approfondi pour la reconnaissance faciale qui leur a permis d’obtenir des résultats à la pointe de la technologie sur des ensembles de données standard.
we nous montrons comment un ensemble de données à très grande échelle (2,6 millions d’images, plus de 2,6 K personnes) peut être assemblé par une combinaison d’automatisation et d’humain dans la boucle
— Deep Face Recognition, 2015.
Pour un tutoriel sur VGGFace, voir:
- Comment effectuer la reconnaissance faciale Avec VGGFace2 dans Keras
Bien que ce soient les premières étapes clés dans le domaine de l’apprentissage en profondeur pour la vision par ordinateur, les progrès se sont poursuivis, avec beaucoup d’innovations axées sur les fonctions de perte pour entraîner efficacement les modèles.
Pour un excellent résumé à jour, voir l’article 2018 « Reconnaissance faciale profonde: Une enquête. »
Pour en savoir plus
Cette section fournit plus de ressources sur le sujet si vous cherchez à aller plus loin.
Livres
- Manuel de reconnaissance faciale, Deuxième édition, 2011.
Papiers de reconnaissance faciale
- Reconnaissance faciale: Enquête documentaire, 2003.
- Détection des visages: Une enquête, 2001.
- Reconnaissance des visages par l’homme et la machine : Une enquête, 1995.
- Détection d’objets en temps réel robuste, 2004.
- Reconnaissance faciale À L’aide De Faces propres, 1991.
Papiers de reconnaissance faciale en apprentissage profond
- Reconnaissance faciale profonde: Une enquête, 2018.Reconnaissance faciale profonde, 2015.
- FaceNet : Une intégration unifiée pour la Reconnaissance Faciale et le Clustering, 2015.
- DeepFace: Combler l’écart avec la Performance au niveau humain dans la Vérification du Visage, 2014.
- Représentation faciale en Apprentissage profond par Identification-Vérification conjointe, 2014.
- Représentation faciale en apprentissage profond à partir de la prédiction de 10 000 classes, 2014.
- Détection de Visages Multi-vues À L’aide De Réseaux Neuronaux convolutifs Profonds, 2015.
- Des Réponses des Parties Faciales à la Détection des Visages: Une approche d’apprentissage en Profondeur, 2015.
- Surpassant les Performances de Vérification de Visage au Niveau Humain sur LFW avec GaussianFace, 2014.
Articles
- Système de reconnaissance faciale, Wikipedia.
- Reconnaissance faciale, Wikipedia.
- Détection des visages, Wikipedia.
- Visages étiquetés dans l’ensemble de données wild
Résumé
Dans cet article, vous avez découvert le problème de la reconnaissance faciale et comment les méthodes d’apprentissage en profondeur peuvent atteindre des performances surhumaines.
Plus précisément, vous avez appris:
- La reconnaissance faciale est un vaste problème d’identification ou de vérification des personnes sur des photographies et des vidéos.
- La reconnaissance faciale est un processus composé de détection, d’alignement, d’extraction de fonctionnalités et d’une tâche de reconnaissance
- Les modèles d’apprentissage profond ont d’abord été approchés puis ont dépassé les performances humaines pour les tâches de reconnaissance faciale.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.
Développez des Modèles d’Apprentissage profond pour la Vision Aujourd’hui!

Développez Vos Propres Modèles de Vision en Quelques Minutes
…avec seulement quelques lignes de code python
Découvrez comment dans mon nouvel Ebook:
Deep Learning for Computer Vision
Il fournit des tutoriels d’auto-apprentissage sur des sujets tels que:
classification, détection d’objets (yolo et rcnn), reconnaissance faciale (vggface et facenet), préparation de données et bien plus encore…
Apportez enfin l’Apprentissage profond à vos projets de vision
Évitez les universitaires. Juste des résultats.
Voir ce qu’il y a à l’intérieur