- Hein? Que sont l’ENSEMBLE DE REGROUPEMENT, le CUBE et le CUMUL dans SQL ?
- Pourquoi ROLLUP ou CUBE me serait-il utile?
- Sont-ils des SQL standard ou sont-ils une chose réservée à Microsoft?
- Puis-je exclure une ou plusieurs colonnes du CUMUL ?
- Que sont les ensembles de REGROUPEMENT alors? Dois-je savoir pour eux?
- Pourquoi voudrions-nous combiner des colonnes dans n’importe quelle agrégation?
- Y a-t-il plus à REGROUPER des ENSEMBLES qu’une façon de faire des cubes « à la carte »?
- Pourquoi les fonctions Grouping() et Grouping_ID() sont-elles fournies ?
- Eh? Que sont l’ENSEMBLE DE REGROUPEMENT, le CUBE et le CUMUL dans SQL ?
- Pourquoi le CUMUL ou le CUBE me seraient-ils utiles?
- Sont-ils des SQL standard ou sont-ils une chose réservée à Microsoft?
- Puis-je exclure une ou plusieurs colonnes du CUMUL ?
- Que sont les ensembles de REGROUPEMENT alors? Dois-je savoir pour eux?
- Pourquoi voudrions-nous combiner des colonnes dans n’importe quelle agrégation?
- Y a-t-il plus à REGROUPER des ENSEMBLES qu’une façon de faire des cubes « à la carte »?
- Pourquoi les fonctions Grouping() et Grouping_ID() sont-elles fournies ?
Eh? Que sont l’ENSEMBLE DE REGROUPEMENT, le CUBE et le CUMUL dans SQL ?
CUBE, ROLLUP et GROUPING SET sont des opérateurs facultatifs de la clause GROUP BY de l’instruction SELECT pour effectuer des rapports contenant de grandes quantités d’informations. Ils vous permettent de faire plusieurs opérations de GROUPE PAR dans une seule instruction, ce qui permet d’économiser beaucoup de temps et d’efforts de calcul. Ils peuvent fournir toutes les informations nécessaires au reporting, y compris les totaux, tout en offrant de bonnes performances sur de grandes tables et en aidant l’optimiseur de requêtes à concevoir un bon plan d’exécution.
Les lignes supplémentaires de « super-agrégat » fournissent des valeurs de résumé, vous permettant ainsi d’avoir plusieurs « agrégations » telles que SUM() ou MAX() dans le même résultat. Les valeurs nulles dans ces lignes dans le résultat sont destinées à signifier « tous » plutôt que « inconnus ». Il vous permet d’obtenir toutes les agrégations dont vous avez besoin en un seul passage dans la table. En raison de la présence de lignes supplémentaires dans les résultats, des fonctions supplémentaires GROUPING() et GROUPING_ID() sont fournies pour indiquer ces lignes « super-agrégées » supplémentaires et quelles colonnes sont agrégées.
Cela a beaucoup de sens si vous avez une application qui a besoin d’exécuter plusieurs rapports sans calcul supplémentaire ou sans revenir à la base de données: Vous avez tout ce dont vous avez besoin en un seul résultat.
Prenez cet exemple standard d’un CUMUL (j’utilise AdventureWorks 2012 ici)..
|
1
2
3
4
5
6
|
SÉLECTIONNEZ t COMME région, t.name EN TANT QUE territoire, sum(TotalDue) EN TANT QUE revenu,
datepart(aaaa, OrderDate) EN TANT QUE, datepart(mm, OrderDate) EN TANT QUE
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPE PAR t., t.name, datepart(aaaa, OrderDate), datepart(mm, OrderDate)
AVEC CUMUL
|
Ainsi que le GROUPE simple PAR lignes agrégées, avec le total dû pour chaque mois, que vous obtiendrez avec un regroupement simple, vous obtenez également un sous-total ou des lignes super-agrégées, ainsi qu’une ligne totale. (voici le début du résultat)
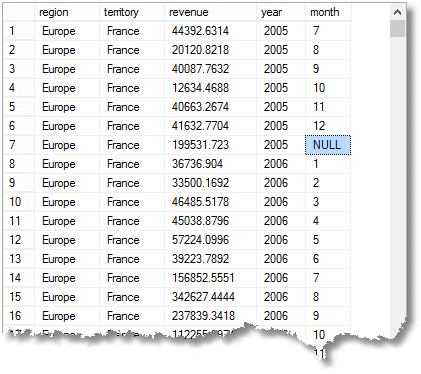
Cette valeur NULLE que j’ai soulignée signifie que la ligne est un agrégat pour ‘tous » les mois de 2005 en France (partie de la région Europe)
En plus de tout cela, vous obtenez le total dû pour chaque année, pour chaque territoire et groupe territorial, ainsi que le total dû. (à partir de la fin)
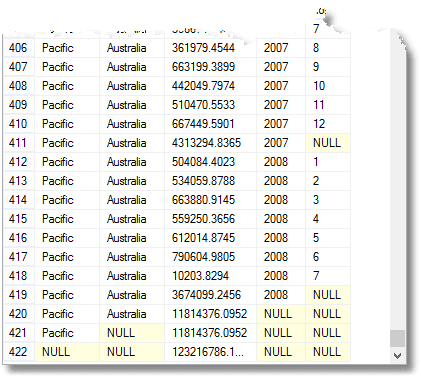
Ces valeurs nulles signifient « Tous », rappelez-vous. La dernière ligne est le total général, et au-dessus, le total pour la région du Pacifique. Au-dessus de cela, il y a la contribution de l’Australie à la région du Pacifique. La quatrième rangée du bas est la contribution de l’Australie en 2008. Le nombre de groupes renvoyés est supérieur d’un au nombre d’expressions de la liste d’éléments composites fournie à l’instruction GROUP BY.
Pour obtenir le même effet sans utiliser le cumul, vous devez faire quelque chose comme ceci (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
AVEC myGrouping(region, territory, totalDue, ,)
AS(SÉLECTIONNEZ t., t.name , sum(TotalDue) COMME chiffre d’affaires,
datepart(aaaa, OrderDate) COMME, datepart(mm, OrderDate) COMME
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPER PAR t.name , l., datepart(aaaa, OrderDate), datepart(mm, OrderDate))
SÉLECTIONNEZ Région, territoire, totalDue,,
DE Mon GROUPE
UNION ALL
SÉLECTIONNEZ Région, territoire, somme(totalDue),,NULL
DE mon GROUPE GROUPE PAR Région, territoire,
UNION ALL
SÉLECTIONNEZ Région, territoire, somme (totalDue), NULL, NULL
DE Mon GROUPE GROUPE PAR Région, territoire
UNION TOUT
SÉLECTIONNEZ Région, NULL, somme (totalDue), NULL, NULL
DE mon GROUPE GROUPE PAR Région
UNION TOUT
SÉLECTIONNEZ NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.name, datepart(aaaa, OrderDate), datepart(mm, OrderDate))’
|
Cette nouvelle syntaxe vous permet des fonctionnalités supplémentaires. Rappelez-vous également que l’ordre des colonnes affecte les groupes de sortie du CUMUL et peut affecter le nombre de lignes dans le jeu de résultats.
Le CUBE fait la même chose générale mais, au lieu de fournir une hiérarchie de totaux dans des lignes de super-agrégat ordonnées, il fournit toutes les permutations de « super-agrégat » (lignes de « super-agrégat symétrique »), les lignes dites de tabulation croisée. Si vous vouliez savoir quel territoire a donné le plus d’ordres en mars ou quel territoire a le moins bien performé en 2006, vous auriez besoin d’un CUBE. Vous fournissez toutes les sommations possibles dans le résultat.
L’ENSEMBLE DE REGROUPEMENT vous permet d’affiner votre résultat pour fournir des informations plus spécialisées au-delà du CUBE. Il peut fournir des informations sommaires sur les combinaisons de dimensions. Vous pouvez obtenir exactement le même résultat que dans notre exemple de CUMUL en utilisant des ENSEMBLES DE REGROUPEMENT, mais avec beaucoup plus de frappe.
|
1
2
3
4
5
6
7
8
9
10
|
SÉLECTIONNEZ t. COMME région, t.name EN TANT QUE territoire, sum(TotalDue) EN TANT QUE revenu,
datepart(aaaa, OrderDate) EN TANT QUE, datepart(mm, OrderDate) EN TANT QUE
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.Salesterritoire T SUR s. TerritoryID = T.Territoriyid
GROUPE EN REGROUPANT DES ENSEMBLES (
(T., T.name , datepart(aaaa, OrderDate), datepart(mm, OrderDate)),
(T., T.name , datepart(aaaa, OrderDate)),
(T., T.name ),
(T.),
())
|
Ceci est juste pour montrer comment ils se rapportent. En réalité, vous auriez recours à des ENSEMBLES DE REGROUPEMENT pour obtenir des résultats impossibles avec le CUMUL ou le CUBE.
Presque tous ces résumés peuvent être obtenus en utilisant uniquement GROUP BY, mais uniquement en regroupant à plusieurs reprises le résultat d’un GROUP BY, ou en faisant plusieurs passages dans les données.
Lorsque vous utilisez des ENSEMBLES de CUBE, de CUMUL ou de REGROUPEMENT, vous ne pouvez pas utiliser le mot-clé DISTINCT dans vos expressions agrégées, telles que AVG(nom_colonne DISTINCT), COUNT(nom_colonne DISTINCT) et SUM (nom_colonne DISTINCT)
Pourquoi le CUMUL ou le CUBE me seraient-ils utiles?
ROLLUP et CUBE ont connu leur heure de gloire avant les SSAS. Ils ont été utiles pour fournir le même type d’installations offertes par le cube à l’OLAP. Il a toujours ses utilisations cependant. Dans AdventureWorks, c’est exagéré, mais si vous gérez de gros volumes de données, vous ne devez les transmettre qu’une seule fois et en faire autant que possible sur les données qui ont été agrégées. Les événements qui se sont produits dans le passé ne peuvent pas être modifiés, il est donc rarement nécessaire de conserver les données historiques sur un système OLTP actif. Au lieu de cela, il vous suffit de conserver les données agrégées au niveau de détail (« granularité ») requis pour tous les rapports prévisibles.
Imaginez que vous êtes responsable de signaler un commutateur téléphonique qui a environ deux millions d’appels par jour. Si vous conservez tous ces appels sur votre serveur OLTP, vous allez bientôt trouver le serveur SQL travaillant sur les rapports d’utilisation. Vous devez conserver les informations d’appel d’origine pendant une période légale, mais vous déterminez de l’entreprise qu’elle n’est, tout au plus, intéressée que par le nombre d’appels en une minute. Ensuite, vous avez réduit vos besoins en stockage sur le serveur OLTP à 1.4% de ce qu’il était, et les enregistrements d’appels peuvent être archivés sur un autre serveur SQL pour des requêtes ad hoc et des relevés client. C’est probablement une économie qui en vaut la peine. Les clauses CUBE et ROLLUP vous permettent même de stocker les totaux de lignes, les totaux de colonnes et les totaux généraux sans avoir à effectuer une analyse de table ou d’index en cluster de la table récapitulative.
Tant que des modifications ne sont pas apportées rétrospectivement à ces données et que toutes les périodes sont terminées, vous n’avez jamais à répéter ou à modifier les agrégations en fonction des périodes passées, bien que les totaux généraux devront être sur-écrits!.
Faisons semblant, mais en utilisant AdventureWorks2012 pour que vous puissiez jouer.
Tout d’abord, nous allons créer le tableau récapitulatif des gram.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
div> 16
17
18
19
|
SI EXISTE (SÉLECTIONNEZ * DEPUIS tempdb.sys.tables DONT le nom EST COMME ‘#AggregationTable%’)
DROP TABLE #aggregationTabledelete supprime la table temporaire si elle existe
GO
SELECT
identity(INT, 1, 1) AS,so afin que nous puissions avoir une colonne unique
t. COMME région, t.name EN TANT QUE territoire, sum(TotalDue) EN TANT QUE revenu,
datepart(aaaa, OrderDate) EN TANT QUE, datepart(mm, OrderDate) EN TANT QUE,
grouping(t.name ) COMME isNameGroup,DoesCela concerne-t-il TOUS les groupements de territoires
(t.) COMME isGroupGroup,DoesCela concerne-t-il TOUS les continents
grouping(datepart(aaaa, OrderDate)) COMME isYearGroup,Does Cela concerne-t-il TOUTES les années
grouping(datepart(mm, OrderDate)) COMME isMonthGroup,– Cela concerne-t-il TOUS les mois
Grouping_ID(datepart(mm, OrderDate)) COMME isMonthGroup, Group Cela concerne-t-il TOUS les mois
Grouping_ID(t.name , t.,
datepart(aaaa, OrderDate), datepart(mm, OrderDate)) AS isGroupingRow
is s’agit-il d’une ligne supplémentaire sans données contenant des données agrégées
DANS #AggregationTable
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.Salesterritoire T SUR s. TerritoryID = T.Territoriyid
GROUPE PAR t.name , t., datepart(aaaa, OrderDate), datepart(mm, OrderDate)
AVEC CUMUL
|
Notez que nous ajoutons des colonnes « bit » supplémentaires qui nous indiquent quelles lignes contiennent les lignes de résumé. Si vous les ajoutez par erreur à d’autres agrégations, vous obtiendrez des résultats sérieusement gonflés. Vous ne pouvez pas utiliser Grouping() ou Grouping_ID sur le résultat enregistré, évidemment, vous devez donc fournir quelque chose à sa place.
Maintenant, nous pouvons produire le tableau croisé dynamique très rapidement
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
now maintenant, nous pouvons créer un tableau croisé dynamique simple avec une ligne et une colonne
column totaux
SÉLECTIONNEZ le territoire,
sum (CAS OÙ 2005 PUIS revenu AUTRE 0 FIN) COMME,
sum (CAS OÙ 2006 PUIS revenu AUTRE 0 FIN) COMME,
sum (CAS OÙ 2007 PUIS revenu AUTRE 0 FIN) COMME,
sum (CAS OÙ 2008 PUIS revenu AUTRE 0 FIN) COMME,
sum (revenu) COMME
DE #AggregationTable
div> OÙ isGroupingrow = 0
GROUPE PAR territoire
UNION DE TOUS
SÉLECTIONNEZ ‘Total’, somme (CAS OÙ 2005 PUIS revenu AUTRE 0 FIN) COMME,
somme (CAS OÙ 2006 PUIS revenu AUTRE 0 FIN) COMME,
somme (CAS OÙ 2007 PUIS revenu AUTRE 0 FIN) COMME,
somme (CAS OÙ 2007 PUIS revenu AUTRE 0 FIN) COMME ,
somme (CAS OÙ 2008 PUIS LE revenu SINON 0 SE TERMINE) COMME,
somme (revenu) COMME
DE #AggregationTable
OÙ isYearGroup = 0 ET isMonthGroup=1
|
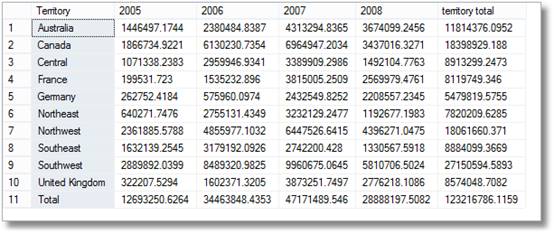
Il y a donc de brefs sourires des gestionnaires en voyant cela, mais ensuite ils disent vivement « Je suis sûr que j’ai également demandé une ventilation par territoire par mois
Avec un bref rire, vous faites ceci.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
div> 16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECT
datename(MONTH, dateadd(MONTH,, ’01 dec 2000′)) AS,
sum(CASE territory WHEN ‘Australia’ THEN revenue ELSE 0 END) AS,
sum(CASE territory WHEN ‘Canada’ THEN revenue ELSE 0 END) AS,
sum (CASE territory WHEN ‘Central ‘PUIS revenu AUTRE 0 FIN) COMME,
somme (Territoire DE CAS LORSQUE ‘France’ PUIS revenu AUTRE 0 FIN) COMME,
somme (territoire DE CAS LORSQUE ‘Allemagne’ PUIS revenu AUTRE 0 FIN) COMME,
somme (territoire DE CAS LORSQUE ‘Nord-Est’ PUIS revenu AUTRE 0 FIN) COMME,
somme (territoire de CAS LORSQUE ‘Nord-Est’ PUIS revenu AUTRE 0 FIN) COMME,
somme (territoire de CAS
sum (Territoire DE CASSE QUAND ‘Sud-Est’ PUIS revenu AUTRE 0 FIN) COMME,
sum (territoire DE CASSE QUAND ‘Sud-Est’ PUIS revenu AUTRE 0 FIN) COMME,
sum (territoire DE CASSE QUAND ‘Sud-Ouest’ PUIS revenu AUTRE 0 FIN) COMME,
sum (territoire DE CASSE QUAND ‘Royaume-Uni’ PUIS revenu AUTRE 0 FIN) COMME,
sum (revenu) COMME
DE #AggregationTable
OÙ isGroupingrow = 0
GROUPE PAR mois
UNION ALL
SELECT
‘Total’,
sum (territoire DE CASSE QUAND ‘Australie’ PUIS revenu SINON 0 FIN) AS,
sum (territoire DE CASSE QUAND ‘Australie’ PUIS revenu SINON 0 FIN) AS,
sum (territoire DE CASSE QUAND
sum (Territoire DE CAS LORSQUE ‘Central’ PUIS revenus ELSE 0 FIN) COMME,
sum (Territoire DE CAS LORSQUE ‘France’ PUIS revenus ELSE 0 FIN) COMME,
sum (territoire DE CAS LORSQUE ‘Allemagne’ PUIS revenus ELSE 0 FIN) COMME,
sum (territoire DE CAS LORSQUE ‘Nord-Est’ PUIS revenus ELSE 0 FIN) COMME,
sum (territoire DE CAS LORSQUE ‘Nord-Est’ PUIS revenus ELSE 0 FIN) COMME,
sum (territoire DE CAS LORSQUE ‘Allemagne’ PUIS revenus ELSE 0 FIN) COMME,
sum (territoire DE CAS LORSQUE ‘Nord-Est’ PUIS revenus ELSE 0 FIN) COMME,
sum (territoire DE CAS LORSQUE ‘ Nord-Ouest ‘ PUIS chiffre D’affaires ELSE 0 END) COMME,
somme (territoire DE CASSE QUAND ‘Sud-Est’ PUIS chiffre D’affaires ELSE 0 END) COMME,
somme (territoire DE CASSE QUAND ‘Sud-Ouest’ PUIS chiffre D’affaires ELSE 0 END) COMME,
somme (territoire DE CASSE QUAND ‘Sud-Ouest’ PUIS chiffre D’affaires ELSE 0 END) COMME,
sum (territoire DE CASSE LORSQUE ‘Royaume-Uni’ PUIS chiffre D’affaires SINON 0 FIN) COMME,
somme (chiffre d’affaires) COMME
DE #AggregationTable
OÙ isGroupingrow= 0
|

Mais si vous aviez utilisé CUBE au lieu de Rollup, cette dernière ligne « totale » serait déjà calculée. Dans un exemple réel, cela coûterait du temps à faire le rapport. Vous pouvez faire un CUBE sur jusqu’à dix dimensions; bien qu’elles aient tendance à grossir l’agrégation, elles ne sont pas trop coûteuses.
Sont-ils des SQL standard ou sont-ils une chose réservée à Microsoft?
Ce sont maintenant des SQL ANSI standard de 1999, bien qu’AVEC CUBE et AVEC ROLLUP aient été introduits pour la première fois par Microsoft. Cette inclusion est quelque peu surprenante en ce sens qu’elle introduit un deuxième sens, « tout », pour la valeur NULLE en plus de « inconnu ». Lorsque Microsoft a introduit CUBE et ROLLUP pour la première fois, la syntaxe était légèrement différente, mais les deux formes sont autorisées dans SQL Server. Un seul style de syntaxe peut être utilisé dans une seule instruction SELECT, et vous devez utiliser la syntaxe conforme ISO pour tous les nouveaux travaux.
Puis-je exclure une ou plusieurs colonnes du CUMUL ?
Si vous le souhaitez! Imaginez que je ne voulais pas d’un total super-agrégé pour toutes les régions (t.)
|
1
div> 2
3
4
5
6
|
SÉLECTIONNEZ t. COMME région, t.name EN TANT QUE territoire, sum(TotalDue) EN TANT QUE revenu,
datepart(aaaa, OrderDate) EN TANT QUE, datepart(mm, OrderDate) EN TANT QUE
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPE PAR t., CUMUL(t.name , datepart(aaaa, OrderDate), datepart(mm, OrderDate))
|
Nous utilisons ici la syntaxe conforme à la norme ANSI SQL 2006. Vous pouvez faire la même chose avec un cube. Je n’ai jamais trouvé d’utilisation pratique pour cela, mais vous pourriez le rencontrer
Que sont les ensembles de REGROUPEMENT alors? Dois-je savoir pour eux?
L’ENSEMBLE DE REGROUPEMENT signifie que vous demandez à SQL de regrouper le résultat plusieurs fois. Vous pouvez utiliser la syntaxe des ENSEMBLES DE REGROUPEMENT pour spécifier précisément les agrégations à calculer. Voici un exemple.
|
1
2
3
4
5
6
|
SÉLECTIONNEZ t COMME région, t.name EN TANT QUE territoire, sum(TotalDue) EN TANT QUE revenu,
datepart(aaaa, OrderDate) EN TANT QUE, datepart(mm, OrderDate) EN TANT QUE
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPER PAR t., GROUPER LES ENSEMBLES (ROLLUP(t.name ),
ROLLUP(datepart(aaaa, OrderDate), datepart(mm, OrderDate)))
|
Ici, vous demandez la ventilation par groupe de territoires pour chaque mois de chaque année avec les totaux mensuels et annuels, suivis d’un total récapitulatif par nom du territoire, mais sans grand total. Contrairement au CUMUL, vous obtenez le même résultat quel que soit l’ordre des colonnes dans chaque ENSEMBLE de REGROUPEMENT et l’ordre des ENSEMBLES de REGROUPEMENT.
Les ensembles de REGROUPEMENT peuvent vous donner précisément ce que CUBE et ROLLUP vous donnent et bien plus encore. Comme vous pouvez le voir avec ce dernier exemple, vous pouvez utiliser un CUBE « table d’hôte » standard et un ROLLUP mélangés avec des ensembles de REGROUPEMENT « à la carte » directement exprimés.
Pourquoi voudrions-nous combiner des colonnes dans n’importe quelle agrégation?
Lorsque deux colonnes doivent être combinées dans certains rapports, il est utile de déclarer une agrégation qui combine deux colonnes. Dans le premier exemple, nous combinons l’année et le mois pour le cumul, ce qui a pour effet de limiter les totaux à chaque territoire,
|
1
2
3
4
5
6
7
|
get obtenez les totaux pour chaque territoire uniquement – aucun total pour chaque région ou année
SÉLECTIONNEZ t. COMME région, t.nom EN TANT QUE territoire, somme (Total) EN TANT QUE revenu,
partie de date(aaaa, Date de commande) EN TANT QUE, partie de date(mm, date de commande) EN TANT QUE
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPE PAR t., t.name , ROLLUP
((datepart(aaaa, OrderDate), datepart(mm, OrderDate)))
|
Cette parenthèse supplémentaire dans la clause de ROLLUP a eu pour effet de limiter les agrégations au seul territoire et au mois/année. Laissez-les de côté, et vous obtenez des totaux pour chaque année.
|
1
2
3
4
5
6
7
8
9
10
|
getobtenez également les totaux pour chaque année dans chaque territoire en tant que totaux
SELECT pour chaque territoire
no aucun total pour chaque région
SÉLECTIONNEZ t. EN tant que région, t.nom EN TANT QUE territoire, somme (Total) EN TANT QUE revenu,
partie de date(aaaa, Date de commande) EN TANT QUE, partie de date(mm, date de commande) EN TANT QUE
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPE PAR t., t.name , ROLLUP
(datepart(aaaa, OrderDate), datepart(mm, OrderDate))
|
Cela peut être très utile pour certaines données. Nous avons évité d’avoir besoin de combiner des colonnes ici. Si vous deviez faire un CUBE et que les termes pour les territoires utilisaient des mots comme « Nord » ou « Sud » pour décrire un territoire dans plus d’une région, vous auriez des agrégations bizarres qui s’appliquent aux territoires « nord » qui ne sont pas liés. En combinant des colonnes, vous éviteriez cela.
Y a-t-il plus à REGROUPER des ENSEMBLES qu’une façon de faire des cubes « à la carte »?
Je ne suis pas sûr que je serais timide à l’idée de poser cette question. SQL:Les ENSEMBLES DE REGROUPEMENT DE 1999 fournissent une syntaxe récursive riche qui vous permet d’agréger des combinaisons de colonnes et de définir toutes sortes de rapports ésotériques fournissant jusqu’à dix dimensions. Les agrégations peuvent être imbriquées et vous pouvez imbriquer des CUBEs dans des cumuls et imbriquer des cumuls dans des CUBEs. Vous devrez lire une publication spécialisée pour en savoir plus à ce sujet.
Pourquoi les fonctions Grouping() et Grouping_ID() sont-elles fournies ?
Ce n’est pas vraiment une bonne idée d’utiliser NULL pour signifier qu’une colonne est une agrégation. Le problème est que, si une colonne de regroupement contient des valeurs nulles, toutes les valeurs nulles sont considérées comme égales et placées dans un seul groupe NULL qui se fait passer pour un résumé. Pour contourner la difficulté évidente des valeurs NULLES dans les données d’origine, deux fonctions sont fournies: Grouping() et Grouping_ID().
La fonction Grouping() reçoit le nom d’une colonne qui a participé à l’ENSEMBLE de CUMUL, de CUBE ou de REGROUPEMENT. Il renvoie zéro si cette ligne est un résumé de cette colonne avec une valeur NULLE signifiant « tout’ ou si elle contient une valeur.
La fonction GROUPING_ID reçoit une liste qui doit correspondre exactement à l’expression dans la liste GROUP BY. GROUPING_ID est créé comme un bitmap des colonnes de résumé respectives. Si, par exemple, la colonne territoire a une signification NULLE « tous » les territoires plutôt qu’un nom de territoire, et qu’elle est répertoriée comme la deuxième colonne, alors le deuxième bit de gauche est défini. Cet entier est ensuite renvoyé.
Grouping_ID() est généralement utilisé pour indiquer si la ligne est une agrégation primaire ou secondaire (0 ou > 0) et, si elle est secondaire, exclue de tout autre GROUPE PAR manipulation.
Il est généralement considéré comme une bonne pratique d’inclure une colonne de bits pour chaque dimension (telle que ‘Territoire’ ou ‘Région’ dans notre exemple) qui est définie si la ligne est un résumé pour cette dimension, avec une valeur Grouping_ID() pour faciliter tout regroupement ultérieur du résultat.
Pour illustrer le fonctionnement réel de Grouping_ID, nous examinons ici la façon dont les bits de Grouping_ID sont définis en fonction du type de résumé. Nous utiliserons la fonction ToBinaryString de Phil Factor pour afficher les bits.
|
1
2
3
4
5
6
7
8
9
|
SÉLECTIONNEZ t. COMME région, t.nom EN TANT QUE territoire, somme (Total) EN TANT QUE revenu,
partie de date(aaaa, date de commande) EN TANT QUE, partie de date(mm, date de commande) EN TANT QUE,
droite (
dbo.ToBinaryString(list liste tous les groupes par éléments tels qu’ils sont
Grouping_ID(t., t.name , datepart(aaaa, OrderDate), datepart(mm, OrderDate))
), 4) COMME use utilisez simplement les quatre derniers caractères car nous avons quatre colonnes dans notre liste.
DES ventes.SalesOrderHeader s
Ventes INTERNES DE JOINTURE.SalesTerritory T SUR s.Territoriyid = T.Territoriyid
GROUPE PAR CUBE (t., t.cela donne (juste un exemple, bien sûr)…
|
,%20la%20partie%20de%20la%20date(mm,%20date%20de%20la%20commande)))
Cela donne (juste un exemple bien sûr)…
