La modélisation des données est le processus de documentation d’une conception de système logiciel complexe sous la forme d’un diagramme facile à comprendre, utilisant du texte et des symboles pour représenter la manière dont les données doivent circuler. Le diagramme peut être utilisé pour assurer une utilisation efficace des données, comme plan directeur pour la construction de nouveaux logiciels ou pour la réingénierie d’une application héritée.
La modélisation des données est une compétence importante pour les scientifiques des données ou d’autres personnes impliquées dans l’analyse des données. Traditionnellement, des modèles de données ont été construits pendant les phases d’analyse et de conception d’un projet pour s’assurer que les exigences d’une nouvelle application sont parfaitement comprises. Les modèles de données peuvent également être invoqués plus tard dans le cycle de vie des données pour rationaliser les conceptions de données créées à l’origine par les programmeurs sur une base ad hoc.
Approches de modélisation des données
La modélisation des données peut être un processus initial laborieux et, en tant que tel, est parfois considérée comme étant en contradiction avec les méthodologies de développement rapide. La programmation Agile étant de plus en plus utilisée pour accélérer les projets de développement, des méthodes de modélisation des données après coup sont parfois adaptées. En règle générale, un modèle de données peut être considéré comme un organigramme qui illustre les relations entre les données. Il permet aux parties prenantes d’identifier les erreurs et d’apporter des modifications avant l’écriture d’un code de programmation. Alternativement, des modèles peuvent être introduits dans le cadre d’efforts de rétro-ingénierie qui extraient des modèles de systèmes existants, comme on le voit avec les données NoSQL.
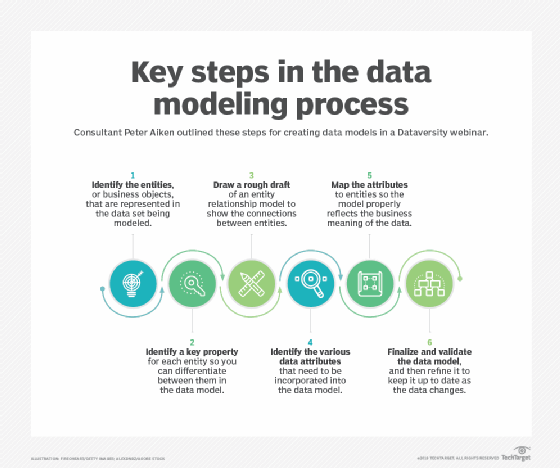
Les modélisateurs de données utilisent souvent plusieurs modèles pour afficher les mêmes données et s’assurer que tous les processus, entités, relations et flux de données ont été identifiés. Ils initient de nouveaux projets en recueillant les besoins des parties prenantes de l’entreprise. Les étapes de modélisation des données se décomposent grossièrement en création de modèles de données logiques qui montrent des attributs, des entités et des relations spécifiques entre les entités et le modèle de données physiques.
Le modèle de données logiques sert de base à la création d’un modèle de données physiques, spécifique à l’application et à la base de données à implémenter. Un modèle de données peut devenir la base pour construire un schéma de données plus détaillé.
Modélisation hiérarchique des données
La modélisation des données en tant que discipline a commencé à apparaître dans les années 1960, accompagnant la reprise de l’utilisation de systèmes de gestion de bases de données (SGBD). La modélisation des données a permis aux organisations d’apporter cohérence, répétabilité et développement bien ordonné au traitement des données. Les utilisateurs finaux et les programmeurs d’applications ont pu utiliser le modèle de données comme référence dans les communications avec les concepteurs de données.
Les modèles de données hiérarchiques qui regroupent les données dans des arrangements arborescents, un à plusieurs, ont marqué ces premiers efforts et ont remplacé les systèmes basés sur des fichiers dans de nombreux cas d’utilisation populaires. Le système de gestion de l’information (IMS) d’IBM est un exemple principal de l’approche hiérarchique, qui a trouvé une large utilisation dans les entreprises, en particulier dans le secteur bancaire. Bien que les modèles de données hiérarchiques aient été largement remplacés – à partir des années 1980 – par des modèles de données relationnelles, la méthode hiérarchique est encore courante aujourd’hui dans XML (Extensible Markup Language) et les systèmes d’information géographique (GISE). Les modèles de données de réseau sont également apparus au début des SGBD comme un moyen de fournir aux concepteurs de données une vision conceptuelle large de leurs systèmes. Un tel exemple est la Conférence sur les langages de systèmes de données (CODASYL), qui s’est formée à la fin des années 1950 pour guider le développement d’un langage de programmation standard pouvant être utilisé sur différents types d’ordinateurs.
Modélisation des données relationnelles
Bien qu’elle réduise la complexité des programmes par rapport aux systèmes basés sur des fichiers, le modèle hiérarchique nécessitait toujours une compréhension détaillée du stockage physique spécifique des données utilisé. Proposé comme alternative au modèle de données hiérarchique, le modèle de données relationnelles n’oblige pas les développeurs à définir des chemins de données. La modélisation des données relationnelles a été décrite pour la première fois dans un article technique de 1970 par le chercheur d’IBM E.F. Codd. Le modèle relationnel de Codd a préparé le terrain pour l’utilisation industrielle de bases de données relationnelles dans lesquelles des segments de données sont explicitement joints par l’utilisation de tables, par rapport au modèle hiérarchique où les données sont implicitement jointes. Peu de temps après sa création, le modèle de données relationnelles a été couplé au Langage de requête structuré (SQL) et a commencé à prendre pied de plus en plus dans l’informatique d’entreprise en tant que moyen efficace de traiter les données.
Le modèle de relation d’entité
La modélisation des données relationnelles a fait un autre pas en avant à partir du milieu des années 1970, alors que l’utilisation de modèles de relation d’entité (ER) est devenue plus répandue. Étroitement intégrés aux modèles de données relationnelles, les modèles ER utilisent des diagrammes pour représenter graphiquement les éléments d’une base de données et faciliter la compréhension des modèles sous-jacents.
Avec la modélisation relationnelle, les types de données sont déterminés et rarement modifiés au fil du temps. Les entités comprennent des attributs ; par exemple, les attributs d’une entité employée peuvent inclure le nom, le prénom, les années d’emploi, etc. Les relations sont cartographiées visuellement, ce qui permet de communiquer les objectifs de conception des données aux différents participants au développement et à la maintenance des données. Au fil du temps, les outils de modélisation, notamment ER/Studio d’Idera, Erwin Data Modeler et SAP PowerDesigner, ont été largement utilisés par les architectes de données pour la conception de systèmes.
Au fur et à mesure que la programmation orientée objet gagnait du terrain dans les années 1990, la modélisation orientée objet devenait une autre façon de concevoir des systèmes. Bien que présentant une certaine ressemblance avec les méthodes ER, les approches orientées objet diffèrent en ce sens qu’elles se concentrent sur les abstractions d’objets d’entités du monde réel. Les objets sont regroupés dans des hiérarchies de classes, et les objets de ces hiérarchies de classes peuvent hériter des attributs et des méthodes des classes parentes. En raison de ce trait d’héritage, les modèles de données orientés objet présentent certains avantages par rapport à la modélisation ER, en termes d’intégrité des données et de prise en charge de relations de données plus complexes. Des modèles de données spécifiquement orientés vers les besoins d’entreposage de données sont également apparus dans les années 1990. Des exemples notables sont les modèles dimensionnels de schéma flocon de neige et de schéma en étoile.
Modèles de données graphiques
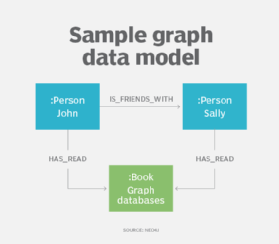
Une ramification de la modélisation de données hiérarchiques et de réseau est le modèle de graphique de propriétés, qui, avec les bases de données graphiques, a trouvé une utilisation accrue pour décrire des relations complexes au sein d’ensembles de données, en particulier dans les applications de médias sociaux, de recommandation et de détection de fraude.
À l’aide du modèle de données de graphe, les concepteurs décrivent leur système comme un graphique connecté de nœuds et de relations, tout comme ils pourraient le faire avec la modélisation de données ER ou d’objets. Les modèles de données graphiques peuvent être utilisés pour l’analyse de texte, créant des modèles qui révèlent les relations entre les points de données dans les documents.