©2002 Rus Shuler @Pomeroy IT Solutions, tous droits réservés
- Table des matières
- Introduction
- Par où commencer ? Adresses Internet
- Piles et paquets de protocole
- Infrastructure réseau
- Infrastructure Internet
- La hiérarchie de routage Internet
- Noms de domaine et résolution d’adresse
- Protocoles Internet revisités
- Protocoles d’application: HTTP et le World Wide Web
- Protocoles d’application: SMTP et courrier électronique
- Protocole de contrôle de transmission
- Internet Protocol
- Terminez
- Ressources
- Bibliographie
Table des matières
- Introduction
- Par où commencer ? Adresses Internet
- Piles et paquets de Protocoles
- Infrastructure Réseau
- Infrastructure Internet
- La Hiérarchie de Routage Internet
- Noms de domaine et Résolution d’Adresses
- Protocoles Internet Revisités
- Protocoles d’application : HTTP et le World Wide Web
- Protocoles d’application: SMTP et Courrier électronique
- Protocole de contrôle de transmission
- Protocole Internet
- Résumé
- Ressources
- Bibliographie
Introduction
Comment fonctionne Internet? Bonne question ! La croissance d’Internet est devenue explosive et il semble impossible d’échapper au bombardement de www.com on le voit constamment à la télévision, à la radio et dans les magazines. Parce qu’Internet est devenu une si grande partie de nos vies, une bonne compréhension est nécessaire pour utiliser ce nouvel outil le plus efficacement possible.
Ce livre blanc explique l’infrastructure et les technologies sous-jacentes qui font fonctionner Internet. Il n’entre pas dans une grande profondeur, mais couvre suffisamment chaque domaine pour donner une compréhension de base des concepts impliqués. Pour toute question sans réponse, une liste de ressources est fournie à la fin du document. Commentaires, suggestions, questions, etc. sont encouragés et peuvent être adressés à l’auteur à l’adresse suivante : [email protected] .
Par où commencer ? Adresses Internet
Parce qu’Internet est un réseau mondial d’ordinateurs, chaque ordinateur connecté à Internet doit avoir une adresse unique. Les adresses Internet sont sous la forme nnn.nnn.nnn.nnn où nnn doit être un nombre compris entre 0 et 255. Cette adresse est connue sous le nom d’adresse IP. (IP signifie Internet Protocol; plus à ce sujet plus tard.)
L’image ci-dessous illustre deux ordinateurs connectés à Internet; votre ordinateur avec l’adresse IP 1.2.3.4 et un autre ordinateur avec l’adresse IP 5.6.7.8. Internet est représenté comme un objet abstrait entre les deux. (Au fur et à mesure que cet article progresse, la partie Internet du diagramme 1 sera expliquée et redessinée plusieurs fois à mesure que les détails d’Internet seront exposés.)

Diagramme 1
Vérifiez-le – Le programme Ping
Si vous utilisez Microsoft Windows ou une version d’Unix et que vous avez une connexion à Internet, il existe un programme pratique pour voir si un ordinateur sur Internet est en vie. Cela s’appelle ping, probablement d’après le son émis par les anciens systèmes de sonars sous-marins.1 Si vous utilisez Windows, démarrez une fenêtre d’invite de commandes. Si vous utilisez une version d’Unix, accédez à une invite de commande. Type ping www.yahoo.com . Le programme ping enverra un « ping » (en fait un message de demande d’écho ICMP (Internet Control Message Protocol)) à l’ordinateur nommé. L’ordinateur pingé répondra par une réponse. Le programme ping comptera le temps expiré jusqu’à ce que la réponse revienne (si c’est le cas). De plus, si vous entrez un nom de domaine (c’est-à-dire www.yahoo.com ) au lieu d’une adresse IP, ping résoudra le nom de domaine et affichera l’adresse IP de l’ordinateur. Plus d’informations sur les noms de domaine et la résolution d’adresses plus tard.
Piles et paquets de protocole
Pour que votre ordinateur soit connecté à Internet et possède une adresse unique. Comment « parle-t-il » aux autres ordinateurs connectés à Internet? Un exemple devrait servir ici: Disons que votre adresse IP est 1.2.3.4 et vous souhaitez envoyer un message à l’ordinateur 5.6.7.8. Le message que vous souhaitez envoyer est « Hello computer 5.6.7.8! ». De toute évidence, le message doit être transmis sur n’importe quel type de fil reliant votre ordinateur à Internet. Disons que vous avez composé votre FAI depuis chez vous et que le message doit être transmis par la ligne téléphonique. Par conséquent, le message doit être traduit du texte alphabétique en signaux électroniques, transmis sur Internet, puis traduit en texte alphabétique. Comment cela se fait-il ? Grâce à l’utilisation d’une pile de protocoles. Chaque ordinateur en a besoin pour communiquer sur Internet et il est généralement intégré au système d’exploitation de l’ordinateur (Windows, Unix, etc.). La pile de protocoles utilisée sur Internet est appelée pile de protocoles TCP/IP en raison des deux principaux protocoles de communication utilisés. La pile TCP/IP ressemble à ceci :
| Couche de protocole | |
|---|---|
| Couche de protocoles d’application | Protocoles spécifiques aux applications telles que WWW, e-mail, FTP, etc. |
| Couche de protocole de contrôle de transmission | TCP dirige les paquets vers une application spécifique sur un ordinateur à l’aide d’un numéro de port. |
| Couche de protocole Internet | IP dirige les paquets vers un ordinateur spécifique à l’aide d’une adresse IP. |
| Couche matérielle | Convertit les données de paquets binaires en signaux réseau et inversement. (Par exemple carte réseau ethernet, modem pour lignes téléphoniques, etc.) |
Si nous devions suivre le chemin que le message « Bonjour ordinateur 5.6.7.8! »pris de notre ordinateur à l’ordinateur avec l’adresse IP 5.6.7.8, il se passerait quelque chose comme ceci:

Diagramme 2
- Le message commencerait en haut de la pile de protocoles sur votre ordinateur et fonctionnerait de manière descendante.
- Si le message à envoyer est long, chaque couche de pile traversée par le message peut diviser le message en plus petits morceaux de données. En effet, les données envoyées sur Internet (et la plupart des réseaux informatiques) sont envoyées en morceaux gérables. Sur Internet, ces morceaux de données sont appelés paquets.
- Les paquets passeraient par la couche Application et continueraient vers la couche TCP. Un numéro de port est attribué à chaque paquet. Les ports seront expliqués plus tard, mais il suffit de dire que de nombreux programmes peuvent utiliser la pile TCP / IP et envoyer des messages. Nous devons savoir quel programme sur l’ordinateur de destination doit recevoir le message car il écoutera sur un port spécifique.
- Après avoir traversé la couche TCP, les paquets passent à la couche IP. C’est là que chaque paquet reçoit son adresse de destination, 5.6.7.8.
- Maintenant que nos paquets de messages ont un numéro de port et une adresse IP, ils sont prêts à être envoyés sur Internet. La couche matérielle se charge de transformer nos paquets contenant le texte alphabétique de notre message en signaux électroniques et de les transmettre sur la ligne téléphonique.
- À l’autre bout de la ligne téléphonique, votre FAI dispose d’une connexion directe à Internet. Le routeur ISPs examine l’adresse de destination de chaque paquet et détermine où l’envoyer. Souvent, le prochain arrêt du paquet est un autre routeur. Plus d’informations sur les routeurs et l’infrastructure Internet plus tard.
- Finalement, les paquets atteignent l’ordinateur 5.6.7.8. Ici, les paquets commencent au bas de la pile TCP/ IP de l’ordinateur de destination et fonctionnent vers le haut.
- Au fur et à mesure que les paquets passent par la pile, toutes les données de routage ajoutées par la pile de l’ordinateur émetteur (telles que l’adresse IP et le numéro de port) sont supprimées des paquets.
- Lorsque les données atteignent le sommet de la pile, les paquets ont été réassemblés dans leur forme d’origine, « Hello computer 5.6.7.8! »
Infrastructure réseau
Vous savez maintenant comment les paquets voyagent d’un ordinateur à un autre sur Internet. Mais qu’y a-t-il entre les deux ? Qu’est-ce qui compose réellement Internet? Regardons un autre diagramme:
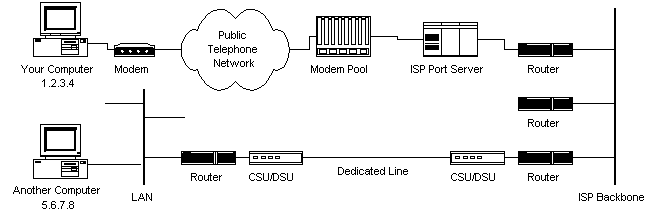
Diagramme 3
Le fournisseur de services Internet gère un pool de modems pour ses clients d’accès à distance. Ceci est géré par une certaine forme d’ordinateur (généralement un ordinateur dédié) qui contrôle le flux de données du pool de modem vers un routeur de ligne dorsale ou dédié. Cette configuration peut être considérée comme un serveur de port, car elle « sert » l’accès au réseau. Les informations de facturation et d’utilisation sont généralement également collectées ici.
Une fois que vos paquets traversent le réseau téléphonique et l’équipement local de votre FAI, ils sont acheminés sur le backbone du FAI ou sur un backbone auquel le FAI achète de la bande passante. De là, les paquets transitent généralement par plusieurs routeurs et sur plusieurs dorsales, lignes dédiées et autres réseaux jusqu’à ce qu’ils trouvent leur destination, l’ordinateur avec l’adresse 5.6.7.8. Mais ne serait-ce pas bien si nous connaissions l’itinéraire exact de nos paquets sur Internet? Il s’avère qu’il y a un moyen…
Vérifiez-le – Le programme Traceroute
Si vous utilisez Microsoft Windows ou une version d’Unix et que vous avez une connexion à Internet, voici un autre programme Internet pratique. Celui-ci s’appelle traceroute et montre le chemin que prennent vos paquets vers une destination Internet donnée. Comme ping, vous devez utiliser traceroute à partir d’une invite de commande. Sous Windows, utilisez tracert www.yahoo.com . À partir d’une invite Unix, tapez traceroute www.yahoo.com . Comme ping, vous pouvez également saisir des adresses IP au lieu de noms de domaine. Traceroute imprimera une liste de tous les routeurs, ordinateurs et autres entités Internet que vos paquets doivent traverser pour se rendre à leur destination.
Si vous utilisez traceroute, vous remarquerez que vos paquets doivent traverser de nombreuses choses pour arriver à leur destination. La plupart ont des noms longs tels que sjc2-core1-h2-0-0.atlas.digex.net et fddi0-0.br4.SJC.globalcenter.net . Ce sont des routeurs Internet qui décident où envoyer vos paquets. Plusieurs routeurs sont représentés dans le diagramme 3, mais seulement quelques-uns. Le diagramme 3 est destiné à montrer une structure de réseau simple. Internet est beaucoup plus complexe.
Infrastructure Internet
Le backbone Internet est constitué de nombreux grands réseaux qui s’interconnectent entre eux. Ces grands réseaux sont connus sous le nom de fournisseurs de services réseau ou NSP. Certains des grands NSP sont UUNet, CerfNet, IBM, BBN Planet, SprintNet, PSINet, ainsi que d’autres. Ces réseaux sont pairs les uns avec les autres pour échanger du trafic de paquets. Chaque NSP doit se connecter à trois points d’accès réseau ou NAP. Lors des SIESTES, le trafic de paquets peut passer de l’épine dorsale d’un NSP à l’épine dorsale d’un autre NSP. Les NSPS s’interconnectent également dans les centres d’échange des régions métropolitaines ou les MAE. Les MAES servent le même but que les PAN, mais sont une propriété privée. Les PAN étaient les points d’interconnexion Internet d’origine. Les NAPs et les MAE sont appelés Points d’échange Internet ou IX. Les FSN vendent également de la bande passante à des réseaux plus petits, tels que les FAI et les fournisseurs de bande passante plus petits. Vous trouverez ci-dessous une image montrant cette infrastructure hiérarchique.
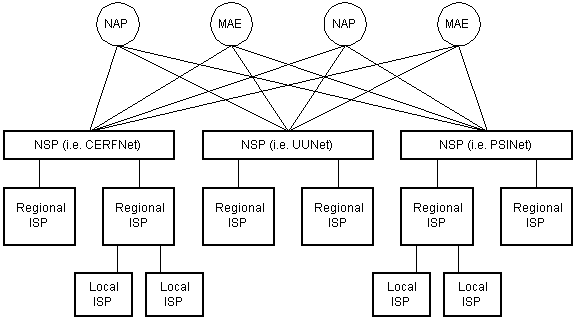
Diagramme 4
La hiérarchie de routage Internet
Alors, comment les paquets trouvent-ils leur chemin sur Internet? Chaque ordinateur connecté à Internet sait-il où se trouvent les autres ordinateurs? Les paquets sont-ils simplement « diffusés » sur tous les ordinateurs sur Internet? La réponse aux deux questions précédentes est » non « . Aucun ordinateur ne sait où se trouvent les autres ordinateurs et les paquets ne sont pas envoyés à tous les ordinateurs. Les informations utilisées pour acheminer les paquets vers leurs destinations sont contenues dans des tables de routage conservées par chaque routeur connecté à Internet.
Les routeurs sont des commutateurs de paquets. Un routeur est généralement connecté entre les réseaux pour acheminer les paquets entre eux. Chaque routeur connaît ses sous-réseaux et les adresses IP qu’il utilise. Le routeur ne sait généralement pas quelles adresses IP sont « au-dessus ». Examinez le diagramme 5 ci-dessous. Les boîtes noires reliant les os arrière sont des routeurs. Les os dorsaux NSP plus grands en haut sont connectés lors d’une SIESTE. Sous eux se trouvent plusieurs sous-réseaux, et sous eux, plus de sous-réseaux. En bas se trouvent deux réseaux locaux avec des ordinateurs connectés.

Diagramme 5
Noms de domaine et résolution d’adresse
Mais que se passe-t-il si vous ne connaissez pas l’adresse IP de l’ordinateur auquel vous souhaitez vous connecter? Que se passe-t-il si vous devez accéder à un serveur Web appelé www.anothercomputer.com ? Comment votre navigateur Web sait-il où se trouve cet ordinateur sur Internet? La réponse à toutes ces questions est le Service de noms de domaine ou DNS. Le DNS est une base de données distribuée qui garde une trace des noms des ordinateurs et de leurs adresses IP correspondantes sur Internet.
De nombreux ordinateurs connectés à Internet hébergent une partie de la base de données DNS et le logiciel qui permet aux autres d’y accéder. Ces ordinateurs sont connus sous le nom de serveurs DNS. Aucun serveur DNS ne contient la base de données entière ; ils n’en contiennent qu’un sous-ensemble. Si un serveur DNS ne contient pas le nom de domaine demandé par un autre ordinateur, le serveur DNS redirige l’ordinateur demandeur vers un autre serveur DNS.
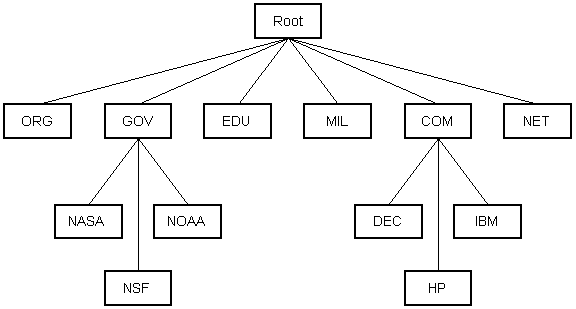
Diagramme 6
Lorsqu’une connexion Internet est configurée (par exemple pour un réseau LOCAL ou un réseau commuté sous Windows), un serveur DNS principal et un ou plusieurs serveurs DNS secondaires sont généralement spécifiés dans le cadre de l’installation. De cette façon, toutes les applications Internet nécessitant une résolution de nom de domaine pourront fonctionner correctement. Par exemple, lorsque vous entrez une adresse Web dans votre navigateur Web, le navigateur se connecte d’abord à votre serveur DNS principal. Après avoir obtenu l’adresse IP du nom de domaine que vous avez saisi, le navigateur se connecte ensuite à l’ordinateur cible et demande la page Web que vous souhaitez.
Vérifiez -Le – Désactivez le DNS sous Windows
Si vous utilisez Windows 95/NT et accédez à Internet, vous pouvez afficher vos serveurs DNS et même les désactiver.
Si vous utilisez le Réseau commuté :
Ouvrez votre fenêtre Réseau Commuté (qui se trouve dans l’Explorateur Windows sous votre lecteur de CD-ROM et au-dessus du voisinage réseau). Faites un clic droit sur votre connexion Internet et cliquez sur Propriétés. En bas de la fenêtre Propriétés de connexion, appuyez sur les paramètres TCP/IP… bouton.
Si vous avez une connexion permanente à Internet :
Faites un clic droit sur le voisinage du réseau et cliquez sur Propriétés. Cliquez sur Propriétés TCP/IP. Sélectionnez l’onglet Configuration DNS en haut.
Vous devriez maintenant regarder les adresses IP de vos serveurs DNS. Ici, vous pouvez désactiver le DNS ou définir vos serveurs DNS sur 0.0.0.0. (Notez d’abord les adresses IP de vos serveurs DNS. Vous devrez probablement également redémarrer Windows.) Entrez maintenant une adresse dans votre navigateur Web. Le navigateur ne sera pas en mesure de résoudre le nom de domaine et vous obtiendrez probablement une boîte de dialogue désagréable expliquant qu’un serveur DNS n’a pas pu être trouvé. Cependant, si vous entrez l’adresse IP correspondante au lieu du nom de domaine, le navigateur pourra récupérer la page Web souhaitée. (Utilisez ping pour obtenir l’adresse IP avant de désactiver DNS.) D’autres systèmes d’exploitation Microsoft sont similaires.
Protocoles Internet revisités
Comme indiqué précédemment dans la section sur les piles de protocoles, on peut supposer qu’il existe de nombreux protocoles utilisés sur Internet. C’est vrai; il existe de nombreux protocoles de communication nécessaires au fonctionnement d’Internet. Ceux-ci incluent les protocoles TCP et IP, les protocoles de routage, les protocoles de contrôle d’accès aux supports, les protocoles de niveau application, etc. Les sections suivantes décrivent certains des protocoles les plus importants et les plus couramment utilisés sur Internet. Les protocoles de niveau supérieur sont discutés en premier, suivis des protocoles de niveau inférieur.
Protocoles d’application: HTTP et le World Wide Web
L’un des services les plus couramment utilisés sur Internet est le World Wide Web (WWW). Le protocole d’application qui fait fonctionner le Web est le protocole de transfert hypertexte ou HTTP. Ne confondez pas cela avec le langage de balisage Hypertexte (HTML). HTML est le langage utilisé pour écrire des pages Web. HTTP est le protocole que les navigateurs Web et les serveurs Web utilisent pour communiquer entre eux sur Internet. Il s’agit d’un protocole de niveau application car il se trouve au-dessus de la couche TCP dans la pile de protocoles et est utilisé par des applications spécifiques pour se parler. Dans ce cas, les applications sont des navigateurs Web et des serveurs Web.
HTTP est un protocole basé sur du texte sans connexion. Les clients (navigateurs Web) envoient des demandes aux serveurs Web pour des éléments Web tels que des pages Web et des images. Une fois la demande traitée par un serveur, la connexion entre le client et le serveur sur Internet est déconnectée. Une nouvelle connexion doit être établie pour chaque demande. La plupart des protocoles sont orientés connexion. Cela signifie que les deux ordinateurs communiquant l’un avec l’autre gardent la connexion ouverte sur Internet. HTTP ne le fait cependant pas. Avant qu’une requête HTTP puisse être effectuée par un client, une nouvelle connexion doit être établie avec le serveur.
Lorsque vous tapez une URL dans un navigateur Web, voici ce qui se passe :
- Si l’URL contient un nom de domaine, le navigateur se connecte d’abord à un serveur de noms de domaine et récupère l’adresse IP correspondante pour le serveur Web.
- Le navigateur Web se connecte au serveur Web et envoie une requête HTTP (via la pile de protocoles) pour la page Web souhaitée.
- Le serveur Web reçoit la demande et vérifie la page souhaitée. Si la page existe, le serveur Web l’envoie. Si le serveur ne trouve pas la page demandée, il enverra un message d’erreur HTTP 404. (404 signifie « Page introuvable », comme le sait probablement quiconque a surfé sur le Web.)
- Le navigateur Web reçoit la page et la connexion est fermée.
- Le navigateur analyse ensuite la page et recherche d’autres éléments de page dont il a besoin pour compléter la page Web. Ceux-ci incluent généralement des images, des applets, etc.
- Pour chaque élément nécessaire, le navigateur établit des connexions supplémentaires et des requêtes HTTP au serveur pour chaque élément.
- Lorsque le navigateur a fini de charger toutes les images, applets, etc. la page sera complètement chargée dans la fenêtre du navigateur.
Vérifiez-Le – Utilisez Votre Client Telnet pour Récupérer une Page Web En utilisant HTTP
Telnet est un service de terminal distant utilisé sur Internet. Son utilisation a diminué ces derniers temps, mais c’est un outil très utile pour étudier Internet. Dans Windows, recherchez le programme telnet par défaut. Il peut se trouver dans le répertoire Windows nommé telnet.EXE. Une fois ouvert, tirez le menu Terminal vers le bas et sélectionnez Préférences. Dans la fenêtre préférences, cochez Écho local. (C’est ainsi que vous pouvez voir votre requête HTTP lorsque vous la tapez.) Maintenant, tirez le menu Connexion vers le bas et sélectionnez Système distant. Entrez www.Google.com pour le nom d’hôte et 80 pour le port. (Les serveurs Web écoutent généralement sur le port 80 par défaut.) Appuyez sur Connecter. Tapez maintenant
GET/HTTP/1.0
et appuyez deux fois sur Entrée. Il s’agit d’une simple requête HTTP à un serveur Web pour sa page racine. Vous devriez voir une page Web clignoter, puis une boîte de dialogue devrait apparaître pour vous indiquer que la connexion a été perdue. Si vous souhaitez enregistrer la page récupérée, activez la connexion au programme Telnet. Vous pouvez ensuite parcourir la page Web et voir le code HTML qui a été utilisé pour l’écrire.
La plupart des protocoles Internet sont spécifiés par des documents Internet connus sous le nom de Demande de commentaires ou RFC. Les RFC peuvent être trouvés à plusieurs endroits sur Internet. Voir la section Ressources ci-dessous pour les URL appropriées. HTTP version 1.0 est spécifiée par la RFC 1945.
Protocoles d’application: SMTP et courrier électronique
Un autre service Internet couramment utilisé est le courrier électronique. Le courrier électronique utilise un protocole de niveau application appelé Protocole de transfert de courrier simple ou SMTP. SMTP est également un protocole basé sur du texte, mais contrairement à HTTP, SMTP est orienté connexion. SMTP est également plus compliqué que HTTP. Il y a beaucoup plus de commandes et de considérations dans SMTP que dans HTTP.
Lorsque vous ouvrez votre client de messagerie pour lire votre courrier électronique, c’est ce qui se produit généralement :
- Le client de messagerie (Netscape Mail, Lotus Notes, Microsoft Outlook, etc.) ouvre une connexion à son serveur de messagerie par défaut. L’adresse IP ou le nom de domaine du serveur de messagerie est généralement configuré lorsque le client de messagerie est installé.
- Le serveur de messagerie transmettra toujours le premier message pour s’identifier.
- Le client enverra une commande SMTP HELO à laquelle le serveur répondra avec un message 250 OK.
- Selon que le client vérifie le courrier, envoie du courrier, etc. les commandes SMTP appropriées seront envoyées au serveur, qui répondra en conséquence.
- Cette transaction de demande/réponse se poursuivra jusqu’à ce que le client envoie une commande SMTP QUIT. Le serveur dira alors au revoir et la connexion sera fermée.
Une simple « conversation » entre un client SMTP et un serveur SMTP est illustrée ci-dessous. R : désigne les messages envoyés par le serveur (récepteur) et S : désigne les messages envoyés par le client (expéditeur).
This SMTP example shows mail sent by Smith at host USC-ISIF, to Jones, Green, and Brown at host BBN-UNIX. Here we assume that host USC-ISIF contacts host BBN-UNIX directly. The mail is accepted for Jones and Brown. Green does not have a mailbox at host BBN-UNIX. ------------------------------------------------------------- R: 220 BBN-UNIX.ARPA Simple Mail Transfer Service Ready S: HELO USC-ISIF.ARPA R: 250 BBN-UNIX.ARPA S: MAIL FROM:<[email protected]> R: 250 OK S: RCPT TO:<[email protected]> R: 250 OK S: RCPT TO:<[email protected]> R: 550 No such user here S: RCPT TO:<[email protected]> R: 250 OK S: DATA R: 354 Start mail input; end with <CRLF>.<CRLF> S: Blah blah blah... S: ...etc. etc. etc. S: . R: 250 OK S: QUIT R: 221 BBN-UNIX.ARPA Service closing transmission channel
Cette transaction SMTP est tirée de la RFC 821, qui spécifie SMTP.
Protocole de contrôle de transmission
Sous la couche application de la pile de protocoles se trouve la couche TCP. Lorsque des applications ouvrent une connexion à un autre ordinateur sur Internet, les messages qu’elles envoient (à l’aide d’un protocole de couche d’application spécifique) sont transmis dans la pile à la couche TCP. TCP est responsable du routage des protocoles d’application vers la bonne application sur l’ordinateur de destination. Pour ce faire, des numéros de port sont utilisés. Les ports peuvent être considérés comme des canaux séparés sur chaque ordinateur. Par exemple, vous pouvez surfer sur le Web tout en lisant le courrier électronique. En effet, ces deux applications (le navigateur Web et le client de messagerie) utilisaient des numéros de port différents. Lorsqu’un paquet arrive sur un ordinateur et remonte la pile de protocoles, la couche TCP décide quelle application reçoit le paquet en fonction d’un numéro de port.
TCP fonctionne comme ceci:
- Lorsque la couche TCP reçoit les données de protocole de la couche application par le haut, elle les segmente en « morceaux » gérables, puis ajoute un en-tête TCP avec des informations TCP spécifiques à chaque « morceau ». Les informations contenues dans l’en-tête TCP incluent le numéro de port de l’application à laquelle les données doivent être envoyées.
- Lorsque la couche TCP reçoit un paquet de la couche IP située en dessous, la couche TCP supprime les données d’en-tête TCP du paquet, effectue une reconstruction de données si nécessaire, puis envoie les données à la bonne application en utilisant le numéro de port tiré de l’en-tête TCP.
C’est ainsi que TCP achemine les données passant par la pile de protocoles vers l’application correcte.
TCP n’est pas un protocole textuel. TCP est un service de flux d’octets fiable et orienté connexion. Orienté connexion signifie que deux applications utilisant TCP doivent d’abord établir une connexion avant d’échanger des données. TCP est fiable car pour chaque paquet reçu, un accusé de réception est envoyé à l’expéditeur pour confirmer la livraison. TCP inclut également une somme de contrôle dans son en-tête pour vérifier les erreurs des données reçues. L’en-tête TCP ressemble à ceci:
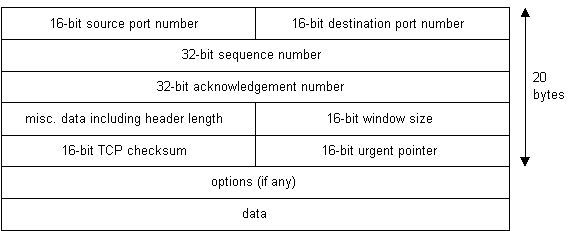
Diagramme 7
| Vérifiez-le – Les numéros de port Internet bien connus | ||||||||||
Ci-dessous sont les numéros de port de certains des services Internet les plus couramment utilisés.
|
Internet Protocol
Unlike TCP, IP is an unreliable, connectionless protocol. IP ne se soucie pas de savoir si un paquet arrive à sa destination ou non. IP ne connaît pas non plus les connexions et les numéros de port. Le travail d’IP est trop d’envoyer et de router des paquets vers d’autres ordinateurs. Les paquets IP sont des entités indépendantes et peuvent arriver hors service ou pas du tout. C’est le travail de TCP de s’assurer que les paquets arrivent et sont dans le bon ordre. La seule chose qu’IP a en commun avec TCP est la façon dont elle reçoit des données et ajoute ses propres informations d’en-tête IP aux données TCP. L’en-tête IP ressemble à ceci:
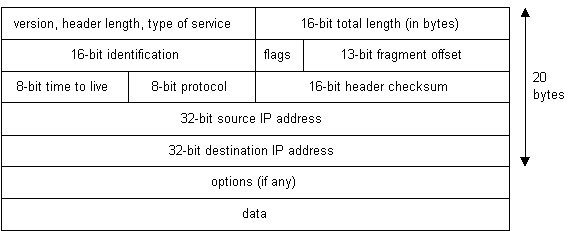
Diagramme 8
Diagramme 9
Terminez
Maintenant vous savez comment fonctionne Internet. Mais combien de temps cela va-t-il rester ainsi? La version de l’IP actuellement utilisée sur Internet (version 4) n’autorise que 232 adresses. Finalement, il ne restera plus d’adresses IP gratuites. Surpris ? Ne t’inquiète pas. La version IP 6 est actuellement testée sur une base de recherche par un consortium d’institutions de recherche et d’entreprises. Et après ça ? Qui le sait?. Internet a parcouru un long chemin depuis sa création en tant que projet de recherche du Département de la Défense. Personne ne sait vraiment ce que deviendra Internet. Une chose est sûre, cependant. Internet unira le monde comme aucun autre mécanisme ne l’a jamais fait. L’ère de l’information est en plein essor et je suis heureux d’en faire partie.
Rus Shuler, 1998
Mises à jour faites en 2002
Ressources
Voici quelques liens intéressants associés à certains des sujets abordés. (J’espère qu’ils travaillent tous encore. Tout s’ouvre dans une nouvelle fenêtre.)
http://www.ietf.org/ est la page d’accueil du Groupe de travail sur l’ingénierie Internet. Cet organisme est grandement responsable du développement des protocoles Internet et autres.
http://www.internic.org/ est l’organisation responsable de l’administration des noms de domaine.
http://www.nexor.com/public/rfc/index/rfc.html est un excellent moteur de recherche de RFC utile pour trouver n’importe quelle RFC.
http://www.internetweather.com/ affiche des cartes animées de la latence Internet.
http://routes.clubnet.net/iw/ est la météo Internet de ClubNET. Cette page montre la perte de paquets pour différents transporteurs.
http://navigators.com/isp.html est la page FAI de Russ Haynal. C’est un excellent site avec des liens vers la plupart des PSN et leurs cartes d’infrastructure dorsale.
Bibliographie
Les livres suivants sont d’excellentes ressources et ont grandement aidé à la rédaction de cet article. Je crois que le livre de Stevens est la meilleure référence TCP / IP de tous les temps et peut être considéré comme la bible d’Internet. Le livre de Sheldon couvre une portée beaucoup plus large et contient une grande quantité d’informations sur les réseaux.
- TCP/IP Illustré, Volume 1, Les protocoles.
W. Richard Stevens.
Addison-Wesley, Reading, Massachusetts. 1994. - Encyclopédie des réseaux.
Tom Sheldon.
Osbourne McGraw-Hill, New York. 1998.
Bien qu’il ne soit pas utilisé pour la rédaction de cet article, voici d’autres bons livres sur les thèmes d’Internet et de la mise en réseau:
- Pare-feu et Sécurité Internet; Repousser le pirate Wiley.
William R. Cheswick, Steven M. Bellovin.
Addison-Wesley, Reading, Massachusetts. 1994. - Communications de Données, Réseaux Informatiques et Systèmes Ouverts. Quatrième édition.
Fred Halsall.
Addison-Wesley, Harlow, Angleterre. 1996. - Télécommunications : Protocoles et conception.
Jean D. Spragins avec Joseph L. Hammond et Krzysztof Pawlikowski.
Addison-Wesley, Reading, Massachusetts. 1992.