La Structure de l’ADN Fournit un mécanisme d’hérédité
Les gènes portent des informations biologiques qui doivent être copiées avec précision pour être transmises à la génération suivante chaque fois qu’une cellule se divise pour former deux cellules filles. Deux questions biologiques centrales découlent de ces exigences: comment les informations permettant de spécifier un organisme peuvent-elles être transportées sous forme chimique et comment sont-elles copiées avec précision? La découverte de la structure de la double hélice d’ADN a fait date dans la biologie du XXe siècle car elle a immédiatement suggéré des réponses aux deux questions, résolvant ainsi au niveau moléculaire le problème de l’hérédité. Nous discutons brièvement des réponses à ces questions dans cette section, et nous les examinerons plus en détail dans les chapitres suivants.
L’ADN code l’information à travers l’ordre, ou la séquence, des nucléotides le long de chaque brin. Chaque base – A, C, T ou G — peut être considérée comme une lettre dans un alphabet à quatre lettres qui énonce des messages biologiques dans la structure chimique de l’ADN. Comme nous l’avons vu au chapitre 1, les organismes diffèrent les uns des autres parce que leurs molécules d’ADN respectives ont des séquences nucléotidiques différentes et, par conséquent, portent des messages biologiques différents. Mais comment l’alphabet nucléotidique est-il utilisé pour faire des messages, et que précisent-ils?
Comme discuté ci-dessus, il était connu bien avant que la structure de l’ADN ne soit déterminée que les gènes contiennent les instructions pour produire des protéines. Les messages d’ADN doivent donc en quelque sorte coder des protéines (Figure 4-6). Cette relation rend immédiatement le problème plus facile à comprendre, en raison du caractère chimique des protéines. Comme discuté au chapitre 3, les propriétés d’une protéine, qui sont responsables de sa fonction biologique, sont déterminées par sa structure tridimensionnelle, et sa structure est déterminée à son tour par la séquence linéaire des acides aminés dont elle est composée. La séquence linéaire des nucléotides dans un gène doit donc en quelque sorte préciser la séquence linéaire des acides aminés dans une protéine. La correspondance exacte entre l’alphabet nucléotidique à quatre lettres de l’ADN et l’alphabet des acides aminés à vingt lettres des protéines – le code génétique – n’est pas évidente d’après la structure de l’ADN, et il a fallu plus d’une décennie après la découverte de la double hélice avant qu’elle ne soit élaborée. Au chapitre 6, nous décrivons ce code en détail au cours de l’élaboration du processus, appelé expression génique, par lequel une cellule traduit la séquence nucléotidique d’un gène en séquence d’acides aminés d’une protéine.

Figure 4-6
La relation entre l’information génétique véhiculée dans l’ADN et les protéines.
L’ensemble complet d’informations dans l’ADN d’un organisme s’appelle son génome, et il porte l’information pour toutes les protéines que l’organisme synthétisera jamais. (Le terme génome est également utilisé pour décrire l’ADN qui porte cette information.) La quantité d’informations contenues dans les génomes est stupéfiante: par exemple, une cellule humaine typique contient 2 mètres d’ADN. Écrite dans l’alphabet nucléotidique à quatre lettres, la séquence nucléotidique d’un très petit gène humain occupe un quart de page de texte (Figure 4-7), tandis que la séquence complète des nucléotides du génome humain remplirait plus d’un millier de livres de la taille de celui-ci. En plus d’autres informations critiques, il contient les instructions pour environ 30 000 protéines distinctes.

Figure 4-7
La séquence nucléotidique du gène de la β-globine humaine. Ce gène porte l’information pour la séquence d’acides aminés de l’un des deux types de sous-unités de la molécule d’hémoglobine, qui transporte l’oxygène dans le sang. Un gène différent, l’α-globine (plus…)
À chaque division cellulaire, la cellule doit copier son génome pour le transmettre aux deux cellules filles. La découverte de la structure de l’ADN a également révélé le principe qui rend cette copie possible: comme chaque brin d’ADN contient une séquence de nucléotides exactement complémentaire de la séquence nucléotidique de son brin partenaire, chaque brin peut servir de matrice, ou de moule, pour la synthèse d’un nouveau brin complémentaire. En d’autres termes, si l’on désigne les deux brins d’ADN par S et S’, le brin S peut servir de gabarit pour faire un nouveau brin S’, tandis que le brin S’ peut servir de gabarit pour faire un nouveau brin S (Figure 4-8). Ainsi, l’information génétique dans l’ADN peut être copiée avec précision par le processus magnifiquement simple dans lequel le brin S se sépare du brin S ‘, et chaque brin séparé sert alors de modèle pour la production d’un nouveau brin partenaire complémentaire identique à son ancien partenaire.
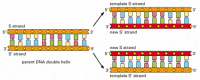
Figure 4-8
L’ADN comme modèle pour sa propre duplication. Comme le nucléotide A ne se couple avec succès qu’avec T et G avec C, chaque brin d’ADN peut spécifier la séquence de nucléotides dans son brin complémentaire. De cette façon, l’ADN à double hélice peut être copié avec précision. (plus…)
La capacité de chaque brin d’une molécule d’ADN à servir de modèle pour produire un brin complémentaire permet à une cellule de copier, ou de répliquer, ses gènes avant de les transmettre à ses descendants. Dans le chapitre suivant, nous décrivons l’élégante machinerie utilisée par la cellule pour accomplir cette tâche énorme.