
Das ist ein wichtiger Punkt zu verstehen. Die Verwendung der falschen Methode führt nicht nur manchmal dazu, dass Seiten nicht wie beabsichtigt aus dem Index entfernt werden, sondern kann sich auch negativ auf die SEO auswirken.
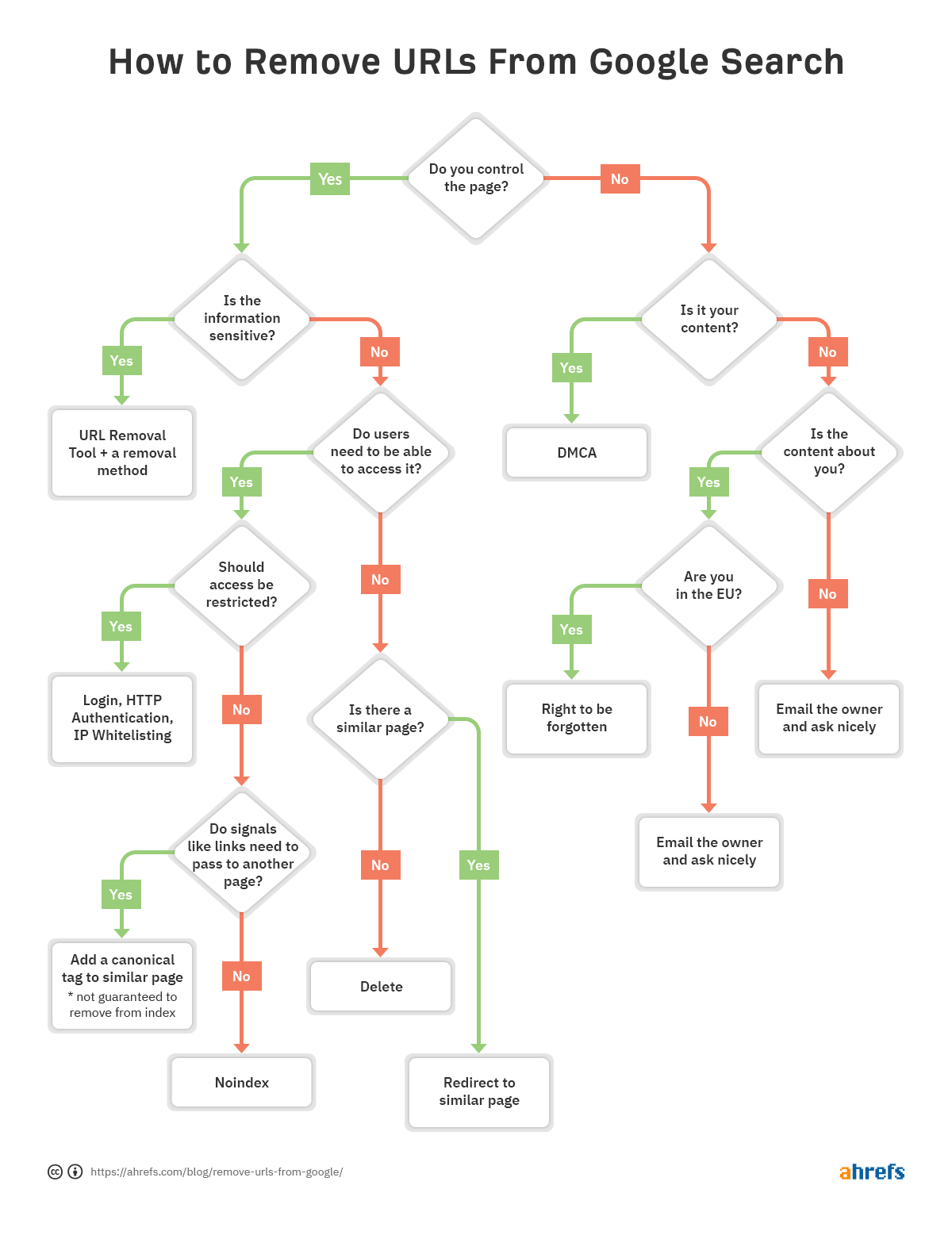
Damit Sie schnell entscheiden können, welche Entfernungsmethode für Sie am besten geeignet ist, haben wir ein Flussdiagramm erstellt, damit Sie zum entsprechenden Abschnitt des Artikels springen können.
In diesem Beitrag erfahren Sie:
- So überprüfen Sie, ob eine URL indiziert ist
- Fünf Möglichkeiten, URLs von Google zu entfernen
- So priorisieren Sie Umzüge
- Häufige Fehler beim Entfernen zu vermeiden
- So entfernen Sie Inhalte, die sich nicht auf Ihrer Website befinden
- So entfernen Sie Bilder
:https://ahrefs.com). Während Website: suchanfragen können nützlich sein, um die Seiten oder Abschnitte einer Website zu identifizieren, die problematisch sein können, wenn sie in Suchergebnissen angezeigt werden. Sie können Seiten anzeigen, die Google bekannt sind, aber das bedeutet nicht, dass sie in normalen Suchergebnissen ohne den site: Operator angezeigt werden können.
Site:-Suchen können beispielsweise weiterhin Seiten anzeigen, die auf eine andere Seite umleiten oder kanonisiert sind. Wenn Sie nach einer bestimmten Website fragen, zeigt Google möglicherweise eine Seite dieser Domain mit dem Inhalt, dem Titel und der Beschreibung einer anderen Domain an. Nehmen wir zum Beispiel moz.com was früher war seomoz.org . Alle regelmäßigen Benutzeranfragen, die zu Seiten auf moz.com wird zeigen moz.com in den SERPs, während site:seomoz.org wird zeigen seomoz.org in den Suchergebnissen wie unten gezeigt.
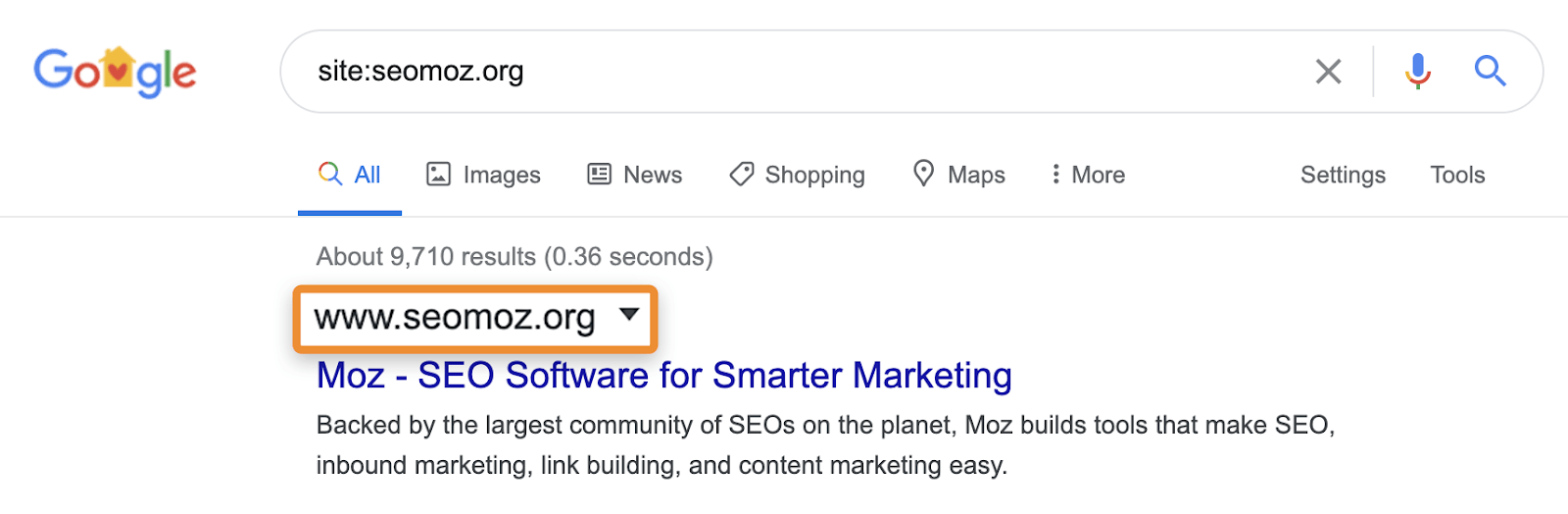
Der Grund, warum dies eine wichtige Unterscheidung ist, ist, dass SEOs Fehler machen können, z. B. das aktive Blockieren oder Entfernen von URLs aus dem Index für die alte Domain, wodurch die Konsolidierung von Signalen wie PageRank verhindert wird. Ich habe viele Fälle mit Domain-Migrationen gesehen, in denen Leute denken, dass sie während der Migration einen Fehler gemacht haben, weil diese Seiten immer noch für site:old-domain.com sucht und am Ende ihrer Website aktiv schadet, während sie versucht, das Problem zu „beheben“.
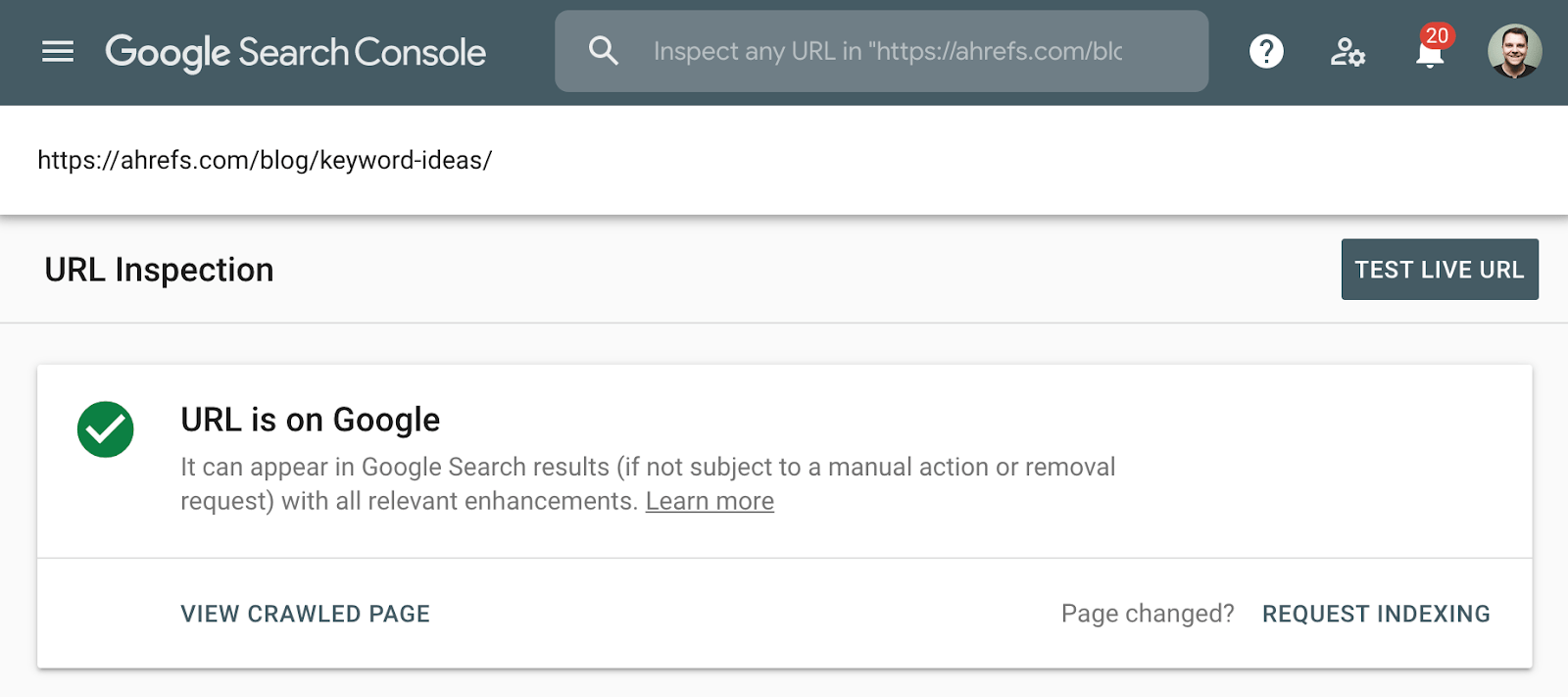
Die bessere Methode zum Überprüfen der Indexierung ist die Verwendung des Indexabdeckungsberichts in der Google Search Console oder des URL-Inspektionstools für eine einzelne URL. Diese Tools sagen Ihnen, ob eine Seite indiziert ist, und liefern zusätzliche Informationen darüber, wie Google die Seite behandelt. Wenn Sie keinen Zugriff darauf haben, suchen Sie einfach bei Google nach der vollständigen URL Ihrer Seite.
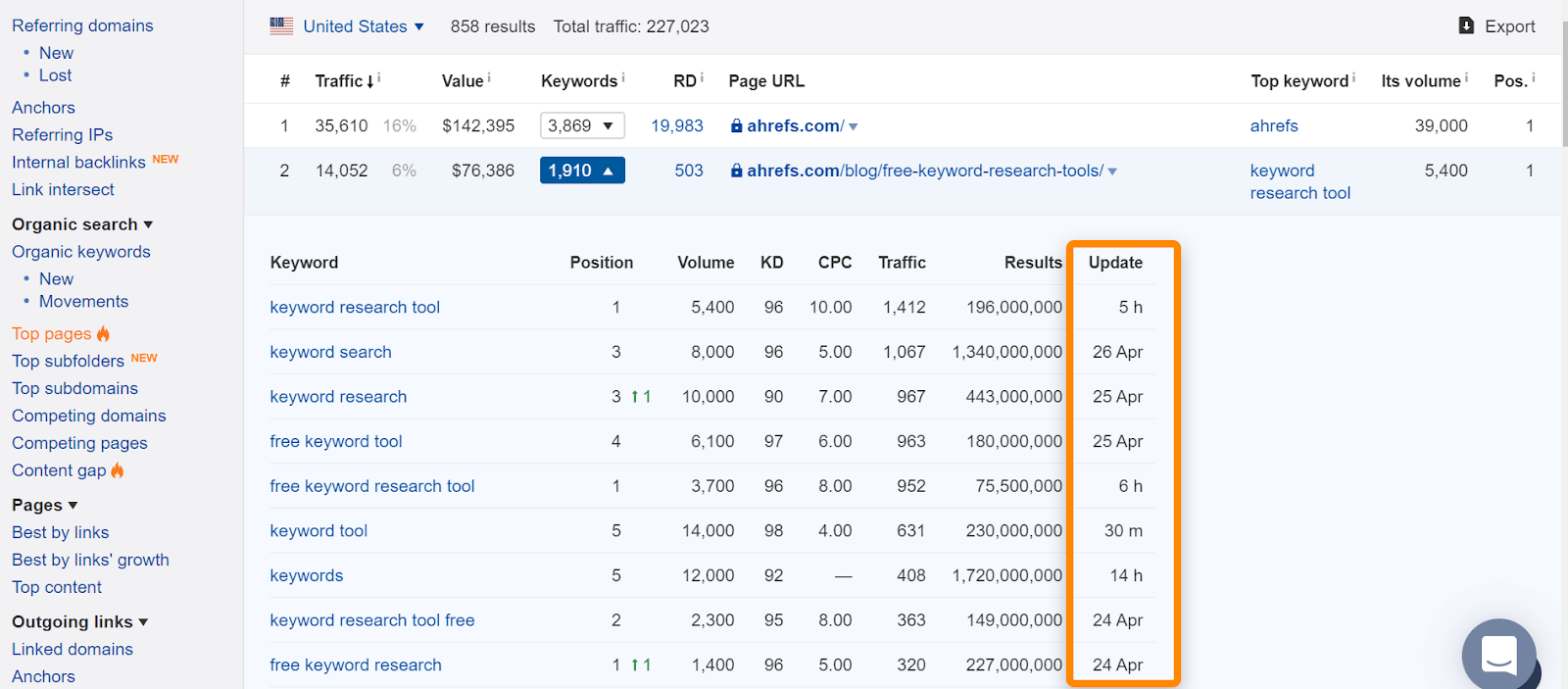
Wenn Sie in Ahrefs die Seite in unserem „Top Pages“ -Bericht oder Ranking für organische Keywords finden, bedeutet dies normalerweise, dass wir sie für normale Suchanfragen eingestuft haben und ein guter Hinweis darauf ist, dass die Seite indiziert wurde. Beachten Sie, dass die Seiten indiziert wurden, als wir sie sahen, aber das hat sich möglicherweise geändert. Überprüfen Sie das Datum, an dem wir die Seite zuletzt für eine Abfrage gesehen haben.
Wenn es ein Problem mit einer bestimmten URL gibt und diese aus dem Index entfernt werden muss, folgen Sie dem Flussdiagramm am Anfang des Artikels, um die richtige Entfernungsoption zu finden, und springen Sie dann zum entsprechenden Abschnitt unten.
Wenn Sie die Seite entfernen und entweder einen Statuscode 404 (nicht gefunden) oder 410 (verschwunden) bereitstellen, wird die Seite kurz nach dem erneuten Crawlen der Seite aus dem Index entfernt. Bis zum Entfernen wird die Seite möglicherweise weiterhin in den Suchergebnissen angezeigt. Und selbst wenn die Seite selbst nicht mehr verfügbar ist, kann eine zwischengespeicherte Version der Seite vorübergehend verfügbar sein.
Wenn Sie eine andere Option benötigen:
- Ich brauche mehr sofortige Entfernung. Siehe den Abschnitt URL Removal Tool.
- Ich muss Signale wie Links konsolidieren. Siehe Abschnitt Kanonisierung.
- Ich brauche die Seite für Benutzer verfügbar. Prüfen Sie, ob die Abschnitte noindex oder restricting access zu Ihrer Situation passen.
- Entfernungsoption 2: Noindex
- Entfernungsoption 3: Zugriff einschränken
- Entfernungsoption 4: URL Removal Tool
- Entfernen Option 5: Kanonisierung
- Noindex in Robotern.txt
- Blockieren des Crawlens in Robotern.txt
- Nofollow
- Noindex und canonical zu einer anderen URL
- Noindex, warten Sie, bis Google crawlt, und blockieren Sie dann das Crawlen
- Was ist, wenn es Inhalte über Sie, aber nicht auf einer Website, die Sie besitzen?
- Abschließende Gedanken
Entfernungsoption 2: Noindex
Ein Noindex‑Meta-Robots-Tag oder eine x-Robots-Header-Antwort weisen Suchmaschinen an, eine Seite aus dem Index zu entfernen. Das Meta Robots-Tag funktioniert für Seiten, auf denen die x‑Robots-Antwort für Seiten und zusätzliche Dateitypen wie PDFs funktioniert. Damit diese Tags sichtbar sind, muss eine Suchmaschine in der Lage sein, die Seiten zu crawlen — stellen Sie also sicher, dass sie nicht in Robotern blockiert werden.txt. Beachten Sie auch, dass das Entfernen von Seiten aus dem Index die Konsolidierung von Links und anderen Signalen verhindern kann.
Beispiel eines Meta robots noindex:
<meta name="robots" content="noindex">
Beispiel für das x‑robots noindex-Tag in der Header-Antwort:
HTTP/1.1 200 OKX-Robots-Tag: noindex
Wenn Sie möglicherweise eine andere Option benötigen:
- Ich möchte nicht, dass Benutzer auf diese Seiten zugreifen. Siehe Abschnitt Zugriff einschränken.
- Ich muss Signale wie Links konsolidieren. Siehe Abschnitt Kanonisierung.
Entfernungsoption 3: Zugriff einschränken
Wenn Sie möchten, dass die Seite für einige Benutzer, aber nicht für Suchmaschinen zugänglich ist, möchten Sie wahrscheinlich eine dieser drei Optionen:
- eine Art Anmeldesystem;
- HTTP-Authentifizierung (für den Zugriff ist ein Kennwort erforderlich);
- IP-Whitelisting (das nur bestimmten IP-Adressen den Zugriff auf die Seiten ermöglicht)
Diese Art der Einrichtung eignet sich am besten für interne Netzwerke, Inhalte nur für Mitglieder oder für Staging-, Test- oder Entwicklungsseiten. Es ermöglicht einer Gruppe von Benutzern den Zugriff auf die Seite, aber Suchmaschinen können nicht darauf zugreifen und indizieren die Seiten nicht.
Wenn Sie eine andere Option benötigen:
- Ich brauche mehr sofortige Entfernung. Siehe den Abschnitt URL Removal Tool. In diesem speziellen Fall möchten Sie möglicherweise sofort entfernt werden, wenn der Inhalt, den Sie ausblenden möchten, zwischengespeichert wurde und Sie verhindern müssen, dass Benutzer diesen Inhalt sehen.
Entfernungsoption 4: URL Removal Tool
Der Name dieses Tools von Google ist etwas irreführend, da es so funktioniert, dass der Inhalt vorübergehend ausgeblendet wird. Google wird diesen Inhalt weiterhin sehen und crawlen, aber die Seiten werden für Benutzer nicht angezeigt. Dieser temporäre Effekt dauert in Google sechs Monate, während Bing ein ähnliches Tool hat, das drei Monate dauert. Diese Tools sollten in den extremsten Fällen für Dinge wie Sicherheitsprobleme, Datenlecks, personenbezogene Daten (PII) usw. verwendet werden. Verwenden Sie für Google das Tool zum Entfernen und für Bing das Tool zum Blockieren von URLs.
Sie müssen neben dem Entfernungstool noch eine andere Methode anwenden, um die Seiten tatsächlich für einen längeren Zeitraum zu entfernen (noindex oder delete) oder um zu verhindern, dass Benutzer auf den Inhalt zugreifen, wenn sie noch über die Links verfügen (delete oder restrict access). Dies gibt Ihnen nur eine schnellere Möglichkeit, die Seiten auszublenden, während die Entfernung Zeit zum Verarbeiten hat. Die Bearbeitung der Anfrage kann bis zu einem Tag dauern.
Entfernen Option 5: Kanonisierung
Wenn Sie mehrere Versionen einer Seite haben und Signale wie Links zu einer einzigen Version konsolidieren möchten, möchten Sie eine Form der Kanonisierung durchführen. Dies dient hauptsächlich dazu, doppelten Inhalt zu verhindern, während mehrere Versionen einer Seite zu einer einzigen indizierten URL konsolidiert werden.
Sie haben mehrere Kanonisierungsoptionen:
- Kanonisches Tag. Dies gibt eine andere URL als die kanonische Version oder die Version an, die angezeigt werden soll. Wenn Seiten doppelt oder sehr ähnlich sind, sollte dies in Ordnung sein. Wenn Seiten zu unterschiedlich sind, kann das Kanonische ignoriert werden, da es ein Hinweis und keine Direktive ist.
- Leitet um. Eine Weiterleitung führt einen Benutzer und einen Suchbot von einer Seite zur anderen. 301 ist die von SEOs am häufigsten verwendete Weiterleitung und teilt den Suchmaschinen mit, dass die endgültige URL die in den Suchergebnissen angezeigte sein soll und wo die Signale konsolidiert werden. Eine 302- oder temporäre Weiterleitung teilt Suchmaschinen mit, dass die ursprüngliche URL im Index verbleiben und dort konsolidiert werden soll.
- Behandlung von URL-Parametern. Ein Parameter wird an das Ende der URL angehängt und enthält normalerweise ein Fragezeichen wie ahrefs.com?this=parameter. Mit diesem Tool von Google können Sie festlegen, wie URLs mit bestimmten Parametern behandelt werden. Sie können beispielsweise angeben, ob der Parameter den Seiteninhalt ändert oder nur die Verwendung verfolgen soll.
Wenn Sie mehrere Seiten aus dem Google-Index entfernen möchten, sollten diese entsprechend priorisiert werden.
Höchste Priorität: Diese Seiten sind in der Regel sicherheitsrelevant oder beziehen sich auf vertrauliche Daten. Dazu gehören Inhalte, die personenbezogene Daten (PII), Kundendaten oder geschützte Informationen enthalten.
Mittlere Priorität: Hierbei handelt es sich in der Regel um Inhalte, die für eine bestimmte Benutzergruppe bestimmt sind. Firmen-Intranets oder Mitarbeiterportale, Inhalte nur für Mitglieder und Staging-, Test- oder Entwicklungsumgebungen.
Niedrige Priorität: Diese Seiten enthalten in der Regel doppelte Inhalte. Einige Beispiele hierfür wären Seiten, die von mehreren URLs bereitgestellt werden, URLs mit Parametern und wiederum Staging-, Test- oder Entwicklungsumgebungen.
Ich möchte einige der Arten behandeln, wie Umzüge normalerweise falsch durchgeführt werden und was in jedem Szenario passiert, um den Leuten zu helfen, zu verstehen, warum sie nicht funktionieren.
Noindex in Robotern.txt
Während Google früher inoffiziell noindex in Robotern unterstützte.txt, es war nie ein offizieller Standard und sie haben jetzt offiziell Unterstützung entfernt. Viele der Websites, die dies taten, taten dies falsch und verletzten sich selbst.
Blockieren des Crawlens in Robotern.txt
Crawlen ist nicht dasselbe wie Indizieren. Selbst wenn Google das Crawlen von Seiten blockiert, wenn es interne oder externe Links zu einer Seite können sie immer noch indizieren. Google weiß nicht, was sich auf der Seite befindet, da sie nicht gecrawlt wird, aber sie wissen, dass eine Seite existiert, und schreiben sogar einen Titel, der in den Suchergebnissen angezeigt wird, basierend auf Signalen wie dem Ankertext von Links zur Seite.
Nofollow
Dies wird häufig für noindex verwechselt, und einige Leute verwenden es auf Seitenebene und erwarten, dass die Seite nicht indiziert wird. Nofollow ist ein Hinweis, und obwohl ursprünglich verhindert wurde, dass Links auf der Seite und einzelne Links mit dem Nofollow-Attribut gecrawlt werden, ist dies nicht mehr der Fall. Google kann diese Links jetzt crawlen, wenn sie möchten. Nofollow wurde auch für einzelne Links verwendet, um zu verhindern, dass Google zu bestimmten Seiten crawlt, und um den PageRank zu verbessern. Auch dies funktioniert nicht mehr, da Nofollow ein Hinweis ist. Wenn die Seite in der Vergangenheit einen anderen Link dazu hatte, konnte Google immer noch über diesen alternativen Crawling-Pfad ermitteln.
Beachten Sie, dass Sie Nofollow-Seiten in großen Mengen mit diesem Filter im Seiten-Explorer in Ahrefs ‚Site Audit finden können.
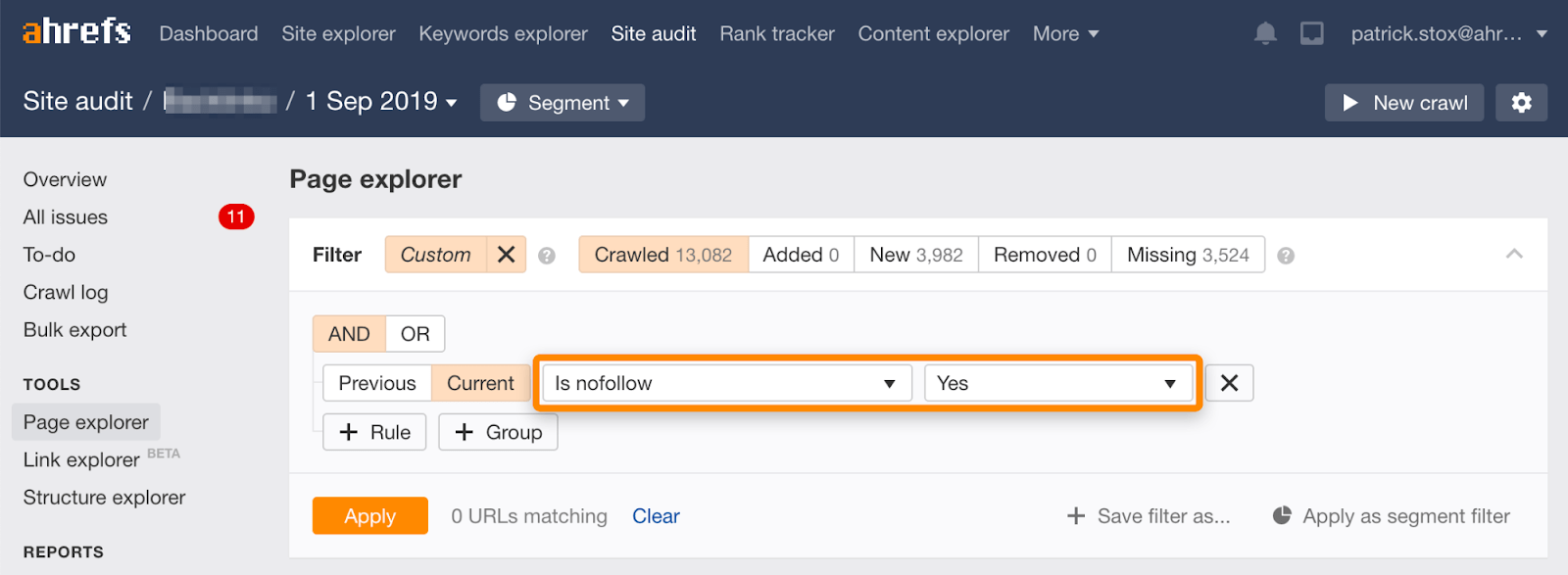
Da es selten sinnvoll ist, alle Links auf einer Seite zu nofollow, sollte die Anzahl der Ergebnisse Null oder nahe Null sein. Wenn es übereinstimmende Ergebnisse gibt, fordere ich Sie auf, zu überprüfen, ob die Nofollow-Direktive versehentlich anstelle von noindex hinzugefügt wurde, und gegebenenfalls eine geeignetere Methode zum Entfernen zu wählen.
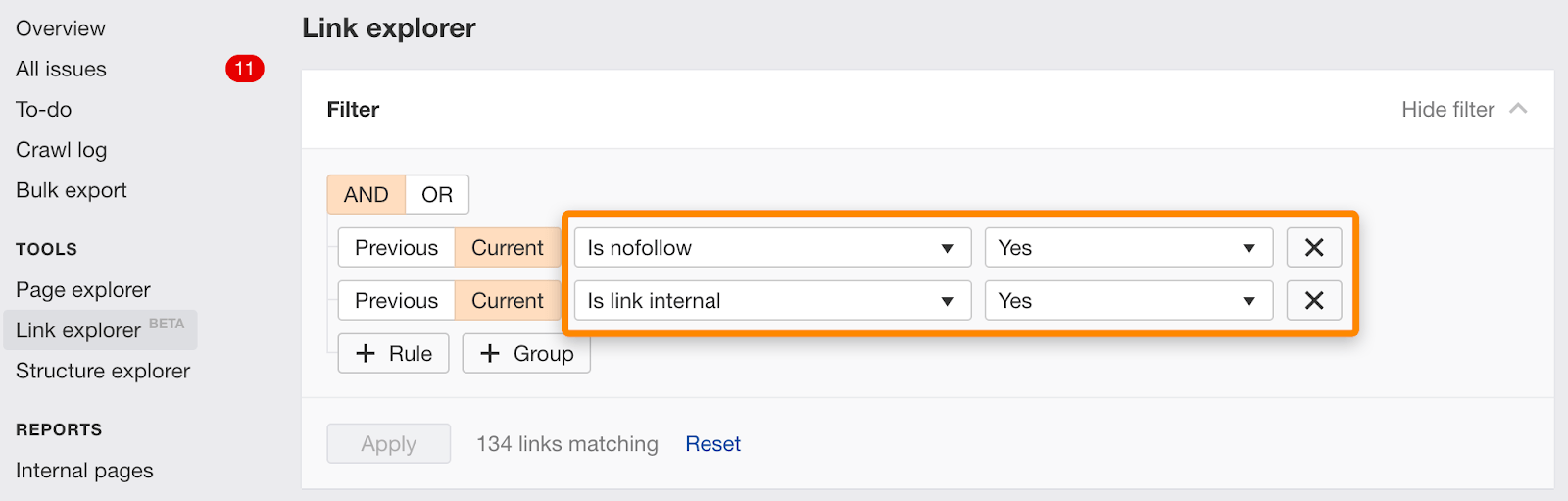
Sie können einzelne Links, die mit nofollow gekennzeichnet sind, auch mit diesem Filter im Link Explorer finden.
Noindex und canonical zu einer anderen URL
Diese Signale sind widersprüchlich. Noindex sagt, dass die Seite aus dem Index entfernt werden soll, und Canonical sagt, dass eine andere Seite die Version ist, die indiziert werden soll. Dies kann für Sie tatsächlich funktionieren, da Google normalerweise den Noindex ignoriert und stattdessen den Canonical als Hauptsignal verwendet. Dies ist jedoch kein absolutes Verhalten. Es ist ein Algorithmus beteiligt und es besteht das Risiko, dass das Noindex-Tag das Signal sein könnte, das gezählt wird. Wenn dies der Fall ist, werden die Seiten nicht richtig konsolidiert.
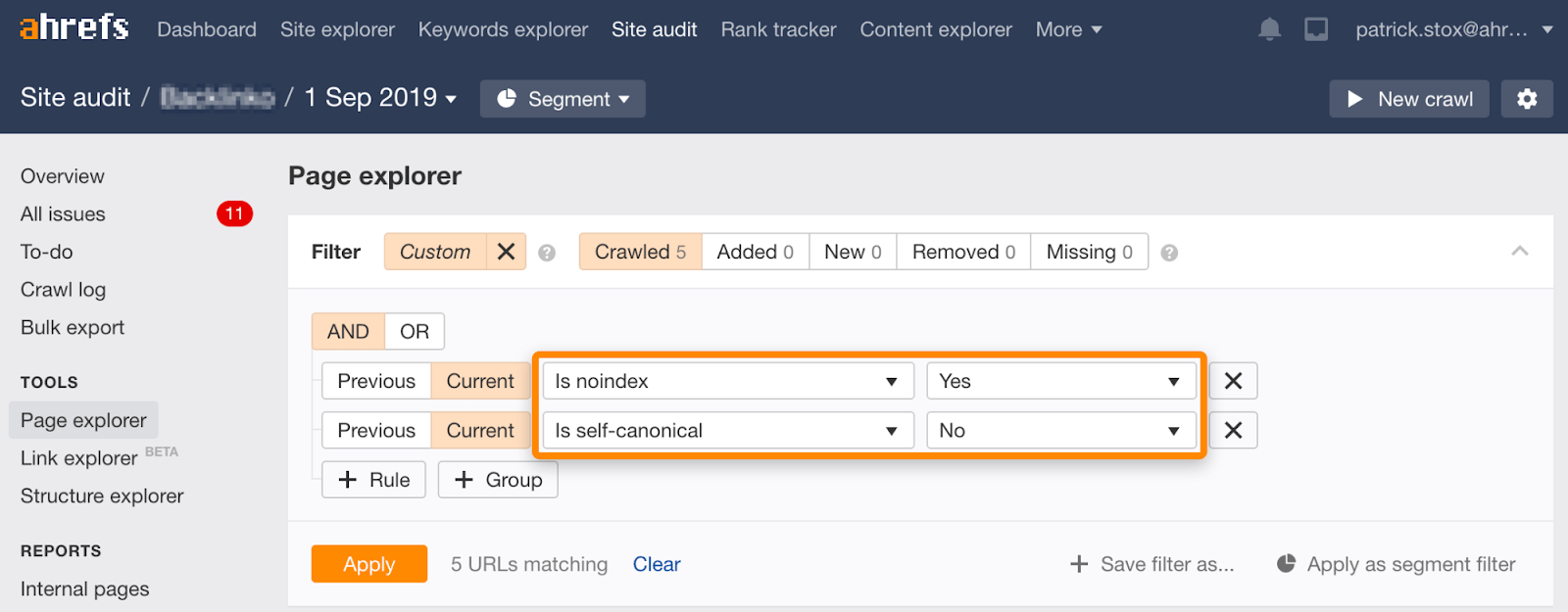
Beachten Sie, dass Sie noindexierte Seiten mit nicht selbstreferenziellen kanonischen Seiten mit diesem Filtersatz im Seiten-Explorer in Site Audit finden können:
Noindex, warten Sie, bis Google crawlt, und blockieren Sie dann das Crawlen
Dies geschieht normalerweise auf verschiedene Arten:
- Seiten sind bereits blockiert, werden indiziert, fügen die Leute Noindex hinzu und entsperren, damit Google den Noindex crawlen und sehen kann, und blockieren dann das erneute Crawlen der Seiten.
- Benutzer fügen Noindex-Tags für die Seiten hinzu, die sie entfernen möchten, und nachdem Google das Noindex-Tag gecrawlt und verarbeitet hat, blockieren sie das Crawlen der Seiten.
In jedem Fall wird der endgültige Status vom Crawlen blockiert. Wenn Sie sich erinnern, haben wir früher darüber gesprochen, dass Crawling nicht dasselbe ist wie Indizieren. Obwohl diese Seiten blockiert sind, können sie dennoch im Index landen.Wenn Sie den Inhalt besitzen, der auf einer anderen Website verwendet wird, können Sie möglicherweise einen Anspruch auf der Grundlage des Digital Millennium Copyright Act (DMCA) geltend machen. Sie können das Copyright Removal Tool von Google verwenden, um einen sogenannten DMCA-Takedown durchzuführen, der die Entfernung von urheberrechtlich geschütztem Material anfordert.
Was ist, wenn es Inhalte über Sie, aber nicht auf einer Website, die Sie besitzen?
Wenn Sie sich in der EU befinden, können Sie Inhalte entfernen lassen, die Informationen über Sie enthalten, dank einer gerichtlichen Anordnung für das Recht auf Vergessen. Sie können beantragen, dass personenbezogene Daten mithilfe des EU-Datenschutz-Entfernungsformulars entfernt werden.
Um Bilder von Google zu entfernen, ist der einfachste Weg mit Robotern.txt. Während die inoffizielle Unterstützung zum Entfernen von Seiten von Robotern entfernt wurde.txt Wie bereits erwähnt, ist es der richtige Weg, Bilder zu entfernen, wenn Sie das Crawlen von Bildern einfach nicht zulassen.
Für ein einzelnes Bild:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
Für alle Bilder:
User-agent: Googlebot-ImageDisallow: /
Abschließende Gedanken
Wie Sie URLs entfernen, ist ziemlich situativ. Wir haben über verschiedene Optionen gesprochen, aber wenn Sie immer noch verwirrt sind, welches für Sie das Richtige ist, lesen Sie das Flussdiagramm am Anfang.
Sie können auch die von Google bereitgestellte rechtliche Problembehandlung zum Entfernen von Inhalten durchgehen.
Haben Sie Fragen? Lass es mich auf Twitter wissen.