- Eh? Was sind GRUPPIERUNGSSATZ, CUBE und ROLLUP in SQL?
- Warum wäre ROLLUP oder CUBE für mich nützlich?
- Handelt es sich um Standard-SQL oder handelt es sich nur um Microsoft?
- Kann ich eine oder mehrere Spalten vom ROLLUP ausschließen?
- Was sind dann GRUPPIERUNGSMENGEN? Soll ich über sie Bescheid wissen?
- Warum sollten wir Spalten in einer Aggregation kombinieren wollen?
- Gibt es mehr zum GRUPPIEREN von SETS als eine Möglichkeit, À-la-carte-Würfel zu erstellen?
- Warum werden die Funktionen Grouping() und Grouping_ID() bereitgestellt?
- Nicht wahr? Was sind GRUPPIERUNGSSATZ, CUBE und ROLLUP in SQL?
- Warum sollten ROLLUP oder CUBE für mich nützlich sein?
- Handelt es sich um Standard-SQL oder handelt es sich nur um Microsoft?
- Kann ich eine oder mehrere Spalten vom ROLLUP ausschließen?
- Was sind dann Gruppierungssätze? Soll ich über sie Bescheid wissen?
- Warum sollten wir Spalten in einer Aggregation kombinieren wollen?
- Gibt es mehr zum GRUPPIEREN von SETS als eine Möglichkeit, À-la-carte-Würfel zu erstellen?
- Warum werden die Funktionen Grouping() und Grouping_ID() bereitgestellt?
Nicht wahr? Was sind GRUPPIERUNGSSATZ, CUBE und ROLLUP in SQL?
CUBE, ROLLUP und GROUPING SET sind optionale Operatoren der GROUP BY-Klausel der SELECT-Anweisung, um Berichte mit großen Informationsmengen zu erstellen. Sie ermöglichen es Ihnen, mehrere GROUP BY-Operationen in einer Anweisung auszuführen, was möglicherweise viel Zeit und Rechenaufwand spart. Sie können alle für die Berichterstellung erforderlichen Informationen bereitstellen, einschließlich der Gesamtsummen, und gleichzeitig eine gute Leistung über große Tabellen erzielen und dem Abfrageoptimierer helfen, einen guten Ausführungsplan zu erstellen.
Die zusätzlichen ‚Super-Aggregate‘-Zeilen liefern Zusammenfassungswerte, wodurch Sie mehrere ‚Aggregationen‘ wie SUM() oder MAX() innerhalb eines Ergebnisses haben können. Die Nullen innerhalb dieser Zeilen im Ergebnis sollen ‚alle‘ und nicht ‚unbekannt‘ bedeuten. Sie können alle benötigten Aggregationen in einem Durchgang durch die Tabelle abrufen. Aufgrund des Vorhandenseins zusätzlicher Zeilen in den Ergebnissen werden zusätzliche Funktionen GROUPING() und GROUPING_ID() bereitgestellt, um diese zusätzlichen „superaggregierten“ Zeilen anzugeben und welche Spalten aggregiert werden.
Dies ist sehr sinnvoll, wenn Sie eine Anwendung haben, die mehrere Berichte ohne zusätzliche Berechnung oder ohne Rückkehr zur Datenbank ausführen muss: Sie haben alles, was Sie brauchen, in einem Ergebnis.
Nehmen Sie dieses Standardbeispiel für ein ROLLUP (ich verwende hier AdventureWorks 2012 )..
|
1
2
3
4
5 6
|
WÄHLEN SIE t. ALS Region, t.name ALS Territorium, Summe(TotalDue) ALS Umsatz,
datepart(yyyy, OrderDate) ALS , datepart(mm, OrderDate) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriyid = T.Territoriyid
GRUPPE VON t., t.name, datepart(yyyy, OrderDate), datepart(mm, OrderDate)
MIT ROLLUP
|
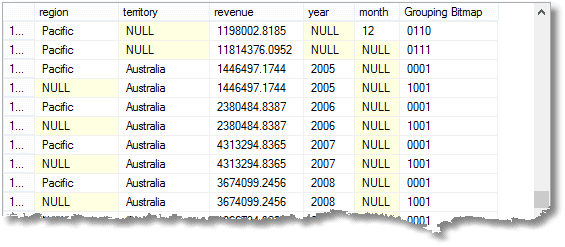
Neben der einfachen GRUPPIERUNG NACH aggregierten Zeilen, mit der Gesamtsumme für jeden Monat, die Sie mit einer einfachen Gruppierung erhalten würden, erhalten Sie auch Zwischensummen- oder superaggregierte Zeilen sowie eine Gesamtsummenzeile. (hier ist der Anfang des Ergebnisses)
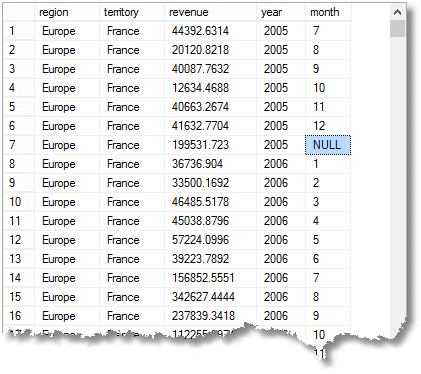
Diese NULL, die ich hervorgehoben habe, bedeutet, dass die Zeile ein Aggregat für ‚alle‘ Monate des Jahres 2005 in Frankreich (Teil der Region Europa)
ist. (vom Ende)
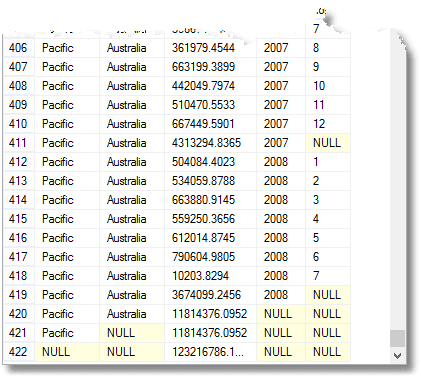
Diese Nullen bedeuten ‚Alle‘, denken Sie daran. Die letzte Zeile ist die Gesamtsumme und darüber die Gesamtsumme für die Pazifikregion. Darüber hinaus ist Australiens Beitrag zur Pazifikregion. Die vierte Reihe von unten ist Australiens Beitrag 2008. Die Anzahl der zurückgegebenen Gruppierungen ist eins mehr als die Anzahl der Ausdrücke in der Liste der zusammengesetzten Elemente, die der GROUP BY-Anweisung bereitgestellt werden.
Um den gleichen Effekt zu erzielen, ohne das Rollup zu verwenden, müssen Sie Folgendes tun (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
MIT myGrouping ( region, territory, totalDue, , )
ALS ( SELECT t., t.name , sum(TotalDue) ALS Umsatz,
datepart(yyyy, OrderDate) ALS , datepart(mm, OrderDate) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriyid = T.Territoriyid
GRUPPIEREN NACH t.name , t., datepart(yyyy, OrderDate), datepart(mm, OrderDate))
SELECT Region, territory, totalDue, ,
FROM myGrouping
UNION ALL
SELECT Region, territory, sum(totalDue), , NULL
FROM myGrouping GRUPPE NACH Region, Gebiet,
UNION ALL
SELECT Region, territory, sum(totalDue ), NULL, NULL
VON myGrouping GRUPPE NACH Region, Gebiet
UNION ALL
SELECT Region, NULL, Summe(totalDue), NULL, NULL
VON myGrouping GRUPPE NACH Region
UNION ALL
SELECT NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‚GROUPBY ROLLUP (t.,t.name,datepart(yyyy,OrderDate),datepart(mm,OrderDate))‘
|
Diese neue Syntax ermöglicht Ihnen einige zusätzliche Funktionen. Denken Sie auch daran, dass die Spaltenreihenfolge die Ausgabegruppen von ROLLUP beeinflusst und die Anzahl der Zeilen in der Ergebnismenge beeinflussen kann.
Der WÜRFEL macht dasselbe Allgemeine, aber anstatt eine Hierarchie von Summen in geordneten Superaggregatzeilen bereitzustellen, stellt er alle ‚Superaggregat‘-Permutationen (’symmetrische Superaggregat‘-Zeilen) bereit, die sogenannten Kreuztabellierungszeilen. Wenn Sie wissen möchten, welches Gebiet im März die meisten Aufträge erteilt hat oder welches Gebiet 2006 am wenigsten gut abgeschnitten hat, benötigen Sie einen WÜRFEL. Sie geben alle möglichen Summationen im Ergebnis an.
Mit dem GRUPPIERUNGSSET können Sie Ihr Ergebnis verfeinern, um über CUBE hinaus speziellere Informationen bereitzustellen. Es kann zusammenfassende Informationen zu Kombinationen von Dimensionen bereitstellen. Sie können genau das gleiche Ergebnis wie in unserem ROLLUP-Beispiel erzielen, indem Sie GRUPPIERUNGSSÄTZE verwenden, jedoch mit viel mehr Eingabe.
|
1
2
3
4
5 6
7
8
9
10
|
WÄHLEN SIE t. ALS Region, t.name ALS Territorium, Summe(TotalDue) ALS Umsatz,
datepart(yyyy, OrderDate) ALS , datepart(mm, OrderDate) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriumid = T.GEBIETS-ID
GRUPPIEREN NACH GRUPPIERUNGSSÄTZEN(
(T., T.name ,datepart(yyyy, OrderDate), datepart(mm, OrderDate)),
(T., T.name ,datepart(yyyy, OrderDate) ),
(T., T.name ),
(T.),
())
|
Dies soll nur zeigen, wie sie sich beziehen. In Wirklichkeit würden Sie auf GRUPPIERUNGSSÄTZE zurückgreifen, um Ergebnisse zu erhalten, die mit ROLLUP oder CUBE nicht möglich sind.
Fast alle diese Zusammenfassungen können durch die Verwendung von GROUP BY gewonnen werden, aber nur durch wiederholtes Gruppieren des Ergebnisses einer GROUP BY oder durch mehr als einen Durchgang durch die Daten.
Wenn Sie CUBE-, ROLLUP- oder GRUPPIERUNGSSÄTZE verwenden, können Sie das Schlüsselwort DISTINCT nicht in Ihren Aggregatausdrücken verwenden, z. B. AVG (DISTINCT column_name), COUNT (DISTINCT column_name) und SUM (DISTINCT column_name)
Warum sollten ROLLUP oder CUBE für mich nützlich sein?
ROLLUP und CUBE hatten ihre Blütezeit vor SSAS. Sie waren nützlich, um die gleichen Einrichtungen bereitzustellen, die der Cube in OLAP bietet. Es hat jedoch immer noch seine Verwendung. In AdventureWorks ist es übertrieben, aber wenn Sie große Datenmengen verarbeiten, müssen Sie Ihre Daten nur einmal übergeben und so viel wie möglich mit aggregierten Daten arbeiten. Ereignisse, die in der Vergangenheit aufgetreten sind, können nicht geändert werden, daher ist es selten erforderlich, historische Daten auf einem aktiven OLTP-System beizubehalten. Stattdessen müssen Sie nur die aggregierten Daten auf der Detailebene (‚Granularität‘) beibehalten, die für alle vorhersehbaren Berichte erforderlich ist.
Stellen Sie sich vor, Sie sind für die Berichterstattung über eine Telefonzentrale verantwortlich, die etwa zwei Millionen Anrufe pro Tag hat. Wenn Sie alle diese Aufrufe auf Ihrem OLTP-Server behalten, werden Sie bald feststellen, dass der SQL Server an Nutzungsberichten arbeitet. Sie müssen die ursprünglichen Anrufinformationen für einen gesetzlichen Zeitraum aufbewahren, aber Sie bestimmen aus dem Geschäft, dass sie höchstens nur an der Anzahl der Anrufe in einer Minute interessiert sind. Dann haben Sie Ihren Speicherbedarf auf dem OLTP-Server auf 1 reduziert.4% von dem, was es war, und die Anrufaufzeichnungen können für Ad-hoc-Abfragen und Kundenanweisungen auf einem anderen SQL Server archiviert werden. Das ist wahrscheinlich eine Ersparnis, die es wert ist, gemacht zu werden. Mit den CUBE- und ROLLUP-Klauseln können Sie sogar die Zeilensummen, Spaltensummen und Gesamtsummen speichern, ohne einen Tabellen- oder Clusterindex-Scan der Übersichtstabelle durchführen zu müssen.
Solange diese Daten nicht nachträglich geändert werden und alle Zeiträume vollständig sind, müssen Sie die Aggregationen auf der Grundlage vergangener Zeiträume niemals wiederholen oder ändern, obwohl die Gesamtsummen überschrieben werden müssen!.
Lassen Sie uns so tun, aber mit AdventureWorks2012 so können Sie mitspielen.
Zunächst erstellen wir die gram summary table.
|
1
2
3
4
5 6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
FALLS VORHANDEN (WÄHLEN SIE * AUS tempdb.sys.tabellen, IN DENEN Name WIE ‚#AggregationTable%‘)
DROP TABLE #aggregationTable –Löschen Sie die temporäre Tabelle, falls vorhanden
GO
SELECT
identity(INT,1,1) AS , –so können wir eine eindeutige Spalte haben
t. ALS Region, t.name ALS Territorium, Summe(TotalDue) ALS Umsatz,
datepart(yyyy, OrderDate) ALS , datepart(mm, OrderDate) ALS ,
grouping(t.name ) WIE isNameGroup, –Bezieht sich dies auf ALLE Gebiete
Gruppierung(t.) WIE isGroupGroup,–Betrifft das ALLE Kontinente
Gruppierung(datepart(yyyy, OrderDate)) WIE isYearGroup,–Betrifft das ALLE Jahre
Gruppierung(datepart(mm, OrderDate)) WIE isMonthGroup,–Betrifft das ALLE Monate
Grouping_ID(t.name ,t.,
datepart(yyyy, OrderDate),datepart(mm, OrderDate)) ALS isGroupingRow
– ist dies eine zusätzliche Nicht-Datenzeile, die aggregierte Daten enthält
IN #AggregationTable
VON Sales.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriumid = T.GEBIETS-ID
GRUPPIEREN NACH t.name , t., datepart(yyyy, OrderDate), datepart(mm, OrderDate)
MIT ROLLUP
|
Beachten Sie, dass wir zusätzliche „Bit“ -Spalten hinzufügen, die uns mitteilen, welche Zeilen die Zusammenfassungszeilen enthalten. Wenn Sie sie fälschlicherweise zu weiteren Aggregationen hinzufügen, erhalten Sie einige ernsthaft überhöhte Ergebnisse. Sie können natürlich nicht Grouping() oder Grouping_ID für das gespeicherte Ergebnis verwenden, daher sollten Sie stattdessen etwas bereitstellen.
Jetzt können wir die Pivot-Tabelle sehr schnell erstellen
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
— jetzt können wir eine einfache Pivot-Tabelle mit Zeile und
erstellen– Spaltensummen
Gebiet auswählen,
Summe (FALL WENN 2005 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL WENN 2006 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL WENN 2007 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL WENN 2008 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Umsatz) ALS
VON #AggregationTable
WHERE isGroupingrow = 0
GROUP BY territory
UNION ALL
SELECT ‚Total‘, Summe(FALL, WENN 2005 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL, WENN 2006 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL, WENN 2007 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL, WENN 2008 DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Umsatz) ALS
VON #AggregationTable
WHERE isYearGroup =0 UND isMonthGroup=1
|
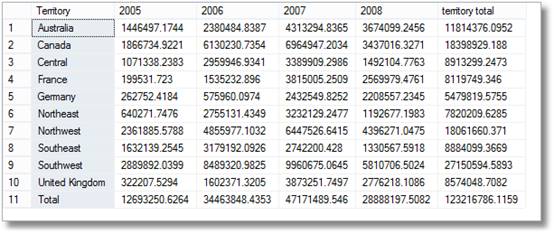
Es gibt also ein kurzes Lächeln von den Managern, wenn sie das sehen, aber dann sagen sie hell: ‘Ich bin sicher, ich habe auch um eine Aufschlüsselung nach Territorium pro Monat gebeten
Mit einem kurzen Kichern tun Sie dies.
|
1
2
3
4
5 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECT
dataame(MONTH,dateadd(MONTH, ,’01 dec 2000′)) AS ,
Summe (Fallgebiet, WENN „Australien“, DANN Umsatz SONST 0 ENDE) AS ,
Summe(Fallgebiet, WENN „Kanada“, DANN Umsatz SONST 0 ENDE) AS ,
Summe(Fallgebiet, WENN „Zentral“, DANN Umsatz SONST 0 ENDE) AS ,
Summe (Fallgebiet WENN ‚Frankreich‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Deutschland‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Nordosten‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Deutschland‘ DANN Umsatz 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Südosten‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Südwesten‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Vereinigtes Königreich‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Umsatz) ALS
VON #AggregationTable
WHERE isGroupingrow =0
GROUP BY month
UNION ALL
SELECT
‚Total‘,
Summe(FALL Gebiet, WENN ‚Australien‘ DANN Umsatz SONST 0 ENDE) AS ,
Summe(FALL Gebiet, WENN 0 ENDE) ALS ,
Summe (Fallgebiet WENN ‚Zentral‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Frankreich‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe (Fallgebiet WENN ‚Deutschland‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe (Fallgebiet WENN ‚Nordosten‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(Fallgebiet WENN ‚Nordwesten‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe (FALL Gebiet, WENN ‚Südosten‘ DANN Umsatz SONST 0 ENDE) ALS ,
Summe(FALL Gebiet, WENN ‚Südwesten‘ DANN Umsatz SONST 0 ENDE) ALS ,
sum(CASE territory WHEN ‚United Kingdom‘ THEN revenue ELSE 0 END) AS ,
sum(revenue) AS
FROM #AggregationTable
WHERE isGroupingrow =0
|

Aber wenn Sie CUBE anstelle von Rollup verwendet hätten, wäre diese letzte ‚Gesamt‘-Zeile bereits berechnet. In einem realen Beispiel würde das Zeit kosten, den Bericht zu erstellen. Sie können einen WÜRFEL für bis zu zehn Dimensionen erstellen. Obwohl sie dazu neigen, die Aggregation zu erhöhen, sind sie nicht zu teuer.
Handelt es sich um Standard-SQL oder handelt es sich nur um Microsoft?
Dies sind jetzt Standard-ANSI-SQL von 1999, obwohl MIT CUBE und MIT ROLLUP zuerst von Microsoft eingeführt wurden. Diese Einbeziehung ist insofern etwas überraschend, als sie eine zweite Bedeutung, ‚all‘, für den Nullwert neben ‚unknown‘ einführt. Als Microsoft CUBE und ROLLUP zum ersten Mal einführte, unterschied sich die Syntax geringfügig, aber beide Formulare sind in SQL Server zulässig. In einer einzelnen SELECT-Anweisung kann nur ein Syntaxstil verwendet werden, und Sie sollten die ISO-konforme Syntax für alle neuen Arbeiten verwenden.
Kann ich eine oder mehrere Spalten vom ROLLUP ausschließen?
Wenn du willst! Stellen Sie sich vor, ich wollte keine Superaggregatsumme für alle Regionen (t.)
|
1
2
3
4
5
6
|
WÄHLEN SIE t. ALS Region, t.name ALS Territorium, Summe(TotalDue) ALS Umsatz,
datepart(yyyy, OrderDate) ALS , datepart(mm, OrderDate) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriyid = T.Territoriyid
GRUPPE NACH t., ROLLUP (t.name , datepart(yyyy, OrderDate), datepart(mm, OrderDate))
|
Hier verwenden wir die ANSI SQL 2006-konforme Syntax. Sie können dasselbe mit einem Würfel tun. Ich habe nie eine praktische Verwendung dafür gefunden, aber Sie könnten darauf stoßen
Was sind dann Gruppierungssätze? Soll ich über sie Bescheid wissen?
GROUPING SET bedeutet, dass Sie SQL bitten, das Ergebnis mehrmals zu gruppieren. Mit der Syntax GRUPPIERUNGSSÄTZE können Sie genau angeben, welche Aggregationen berechnet werden sollen. Hier ein Beispiel.
|
1
2
3
4
5 6
|
WÄHLEN SIE t. ALS Region, t.name ALS Territorium, Summe(TotalDue) ALS Umsatz,
datepart(yyyy, OrderDate) ALS , datepart(mm, OrderDate) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.TERRITORIYID = T.Territoriyid
GRUPPIEREN NACH t., GRUPPIEREN VON SETS(ROLLUP(t.name ),
ROLLUP(datepart(yyyy, OrderDate), datepart(mm, OrderDate)))
|
Hier fragen Sie nach der Aufschlüsselung nach Gebietsgruppe für jeden Monat eines jeden Jahres mit Monats- und Jahressummen, gefolgt von einer zusammenfassenden Summe nach Gebietsnamen, jedoch ohne Gesamtsumme. Im Gegensatz zum ROLLUP erhalten Sie unabhängig von der Reihenfolge der Spalten in jedem GRUPPIERUNGSSATZ und der Reihenfolge der GRUPPIERUNGSSÄTZE das gleiche Ergebnis.
GRUPPIERUNGSSÄTZE können Ihnen genau das geben, was CUBE und ROLLUP Ihnen bieten, und vieles mehr. Wie Sie in diesem letzten Beispiel sehen können, können Sie den Standardwürfel ‚table d’hôte‘ und das ROLLUP zusammen mit direkt ausgedrückten Gruppierungssätzen ‚à la carte‘ verwenden.
Warum sollten wir Spalten in einer Aggregation kombinieren wollen?
Wenn in einigen Berichten zwei Spalten kombiniert werden sollen, ist es sinnvoll, eine Aggregation zu deklarieren, die zwei Spalten kombiniert. Im ersten Beispiel kombinieren wir Jahr und Monat für das Rollup, wodurch die Summen auf jedes Gebiet beschränkt werden,
|
1
2
3
4
5
6
7
|
–holen Sie sich die Summen für jedes Gebiet nur – keine Summen für jede Region oder Jahr
Wählen SIE t. ALS Region, t.name ALS Gebiet, Summe(TotalDue) ALS Umsatz,
Datumsteil(JJJJ, Bestelldatum) ALS , Datumsteil(mm, Bestelldatum) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriyid = T.Territoriyid
GRUPPE NACH t., t.name , ROLLUP
((datepart(yyyy, OrderDate), datepart(mm, OrderDate)))
|
Diese zusätzliche Klammer in der ROLLUP-Klausel hat dazu geführt, dass die Aggregationen nur auf das Gebiet und den Monat/das Jahr beschränkt wurden. Lassen Sie sie aus, und Sie erhalten Summen für jedes Jahr.
|
1
2
3
4
5 6
7
8
9
10
|
–Holen Sie sich die Summen für jedes Jahr in jedem Gebiet sowie die Summen
–für jedes Gebiet
— keine Summen für jede Region
WÄHLEN SIE t. ALS Region, t.name ALS Gebiet, Summe(TotalDue) ALS Umsatz,
Datumsteil(JJJJ, Bestelldatum) ALS , Datumsteil(mm, Bestelldatum) ALS
AUS Verkäufen.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriyid = T.Territoriyid
GRUPPE NACH t., t.name , ROLLUP
(datepart(yyyy, OrderDate), datepart(mm, OrderDate))
|
Dies kann für bestimmte Daten sehr nützlich sein. Wir haben es vermieden, Spalten hier zu kombinieren. Wenn Sie einen WÜRFEL erstellen würden und die Begriffe für Gebiete Wörter wie ‚Nord‘ oder ‚Süd‘ verwenden würden, um ein Gebiet in mehr als einer Region zu beschreiben, hätten Sie einige bizarre Aggregationen, die für ’nördliche‘ Gebiete gelten, die nichts miteinander zu tun haben. Durch das Kombinieren von Spalten würden Sie dies vermeiden.
Gibt es mehr zum GRUPPIEREN von SETS als eine Möglichkeit, À-la-carte-Würfel zu erstellen?
Ich bin mir nicht sicher, ob ich diese Frage scheuen würde. SQL:Die GRUPPIERUNGSSÄTZE von 1999 bieten eine umfangreiche rekursive Syntax, mit der Sie Spaltenkombinationen aggregieren und alle Arten von esoterischen Berichten mit bis zu zehn Dimensionen definieren können. Die Aggregationen können verschachtelt werden, und Sie können CUBEs in ROLLUPs und ROLLUPs in CUBEs verschachteln. Sie müssen eine Fachpublikation lesen, um mehr darüber zu erfahren.
Warum werden die Funktionen Grouping() und Grouping_ID() bereitgestellt?
Es ist nicht wirklich eine gute Idee, NULL zu verwenden, um anzuzeigen, dass eine Spalte eine Aggregation ist. Das Problem besteht darin, dass, wenn eine Gruppierungsspalte Nullwerte enthält, alle Nullwerte als gleich betrachtet und in eine einzelne Nullgruppe eingefügt werden, die sich als Zusammenfassung maskiert. Um die offensichtliche Schwierigkeit von Nullwerten in den Originaldaten zu umgehen, werden zwei Funktionen bereitgestellt: Grouping() und Grouping_ID() .
Der Grouping() Funktion wird der Name einer Spalte übergeben, die am ROLLUP, CUBE oder GRUPPIERUNGSSATZ teilgenommen hat. Es gibt Null zurück, wenn diese Zeile eine Zusammenfassung für diese Spalte mit einem Nullwert ist, der ‚all‘ bedeutet, oder ob sie einen Wert enthält.
Der Funktion GROUPING_ID wird eine Liste übergeben, die genau mit dem Ausdruck in der Liste GROUP BY übereinstimmen muss. GROUPING_ID wird als Bitmap der jeweiligen Zusammenfassungsspalten erstellt. Wenn zum Beispiel die Gebietsspalte eine NULL hat, die ‚alle‘ Gebiete anstelle eines Gebietsnamens bedeutet, und als zweite Spalte aufgeführt ist, wird das zweite Bit von links gesetzt. Diese Ganzzahl wird dann zurückgegeben.
Grouping_ID() wird im Allgemeinen verwendet, um anzugeben, ob die Zeile eine primäre oder sekundäre Aggregation ist (0 oder >0) und, wenn sekundär, dann durch Manipulation von jeder weiteren GRUPPE ausgeschlossen.
Es wird normalerweise als gute Praxis angesehen, eine Bitspalte für jede Dimension (wie „Territory“ oder „Region“ in unserem Beispiel) einzuschließen, die gesetzt wird, wenn die Zeile eine Zusammenfassung für diese Dimension ist, zusammen mit einem Grouping_ID() Wert, um eine weitere Gruppierung des Ergebnisses zu unterstützen.
Um zu veranschaulichen, wie Grouping_ID tatsächlich funktioniert, sehen wir uns hier an, wie die Bits in der Grouping_ID entsprechend dem Typ der Zusammenfassung gesetzt werden. Wir verwenden die Funktion toBinaryString von Phil Factor, um die Bits anzuzeigen.
|
1
2
3
4
5 6
7
8
9
|
WÄHLEN SIE t. ALS Region, t.name ALS Gebiet, Summe (TotalDue) ALS Umsatz,
Datumsteil(JJJJ, Bestelldatum) ALS , Datumsteil(mm, Bestelldatum) ALS ,
rechts (
dbo.toBinaryString(–listet alle Group by-Elemente auf, wie sie sind
Grouping_ID(t., t.name , datepart(yyyy, OrderDate),datepart(mm, OrderDate))
),4) AS – Verwenden Sie einfach die letzten vier Zeichen, da wir vier Spalten in unserer Liste haben.
AUS DEM Verkauf.SalesOrderHeader s
INNER JOIN Umsatz.SalesTerritory T AUF s.Territoriyid = T.Territoriyid
GRUPPE NACH WÜRFEL(t., t.name, Datumsteil(JJJJ, Bestelldatum), Datumsteil(mm, Bestelldatum))
|
Dies ergibt (natürlich nur ein Beispiel)…