Datenmodellierung ist der Prozess der Dokumentation eines komplexen Softwaresystemdesigns als leicht verständliches Diagramm, wobei Text und Symbole verwendet werden, um die Art und Weise darzustellen, wie Daten fließen müssen. Das Diagramm kann verwendet werden, um eine effiziente Datennutzung zu gewährleisten, als Blaupause für den Aufbau neuer Software oder für das Re-Engineering einer Legacy-Anwendung.
Datenmodellierung ist eine wichtige Fähigkeit für Data Scientists oder andere, die mit Datenanalyse zu tun haben. Traditionell werden Datenmodelle während der Analyse- und Entwurfsphase eines Projekts erstellt, um sicherzustellen, dass die Anforderungen an eine neue Anwendung vollständig verstanden werden. Datenmodelle können auch später im Datenlebenszyklus aufgerufen werden, um Datenentwürfe zu rationalisieren, die ursprünglich von Programmierern ad hoc erstellt wurden.
Ansätze zur Datenmodellierung
Die Datenmodellierung kann ein mühsamer Prozess im Vorfeld sein und wird daher manchmal als Widerspruch zu schnellen Entwicklungsmethoden angesehen. Da die agile Programmierung zur Beschleunigung von Entwicklungsprojekten breiter eingesetzt wird, werden in einigen Fällen nachträgliche Methoden der Datenmodellierung angepasst. In der Regel kann ein Datenmodell als Flussdiagramm betrachtet werden, das die Beziehungen zwischen Daten veranschaulicht. Es ermöglicht Stakeholdern, Fehler zu identifizieren und Änderungen vorzunehmen, bevor Programmiercode geschrieben wurde. Alternativ können Modelle als Teil von Reverse Engineering-Bemühungen eingeführt werden, die Modelle aus vorhandenen Systemen extrahieren, wie bei NoSQL-Daten.Datenmodellierer verwenden häufig mehrere Modelle, um dieselben Daten anzuzeigen und sicherzustellen, dass alle Prozesse, Entitäten, Beziehungen und Datenflüsse identifiziert wurden. Sie initiieren neue Projekte, indem sie Anforderungen von Geschäftsakteuren sammeln. Die Phasen der Datenmodellierung gliedern sich grob in die Erstellung logischer Datenmodelle, die bestimmte Attribute, Entitäten und Beziehungen zwischen Entitäten und dem physischen Datenmodell anzeigen.
Das logische Datenmodell dient als Grundlage für die Erstellung eines physikalischen Datenmodells, das spezifisch für die zu implementierende Anwendung und Datenbank ist. Ein Datenmodell kann zur Grundlage für die Erstellung eines detaillierteren Datenschemas werden.
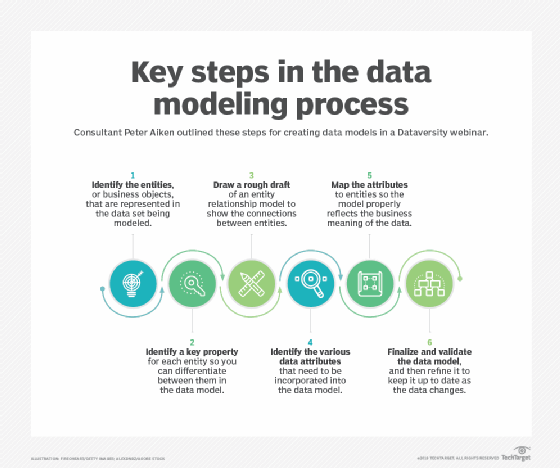
Hierarchische Datenmodellierung
Die Datenmodellierung als Disziplin begann in den 1960er Jahren zu entstehen und begleitete den Aufschwung bei der Verwendung von Datenbankmanagementsystemen (DBMSes). Die Datenmodellierung ermöglichte es Unternehmen, Konsistenz, Wiederholbarkeit und geordnete Entwicklung in die Datenverarbeitung zu bringen. Anwendungsendbenutzer und Programmierer konnten das Datenmodell als Referenz für die Kommunikation mit Datendesignern verwenden.Hierarchische Datenmodelle, die Daten in baumartigen Eins-zu-Viele-Anordnungen anordnen, kennzeichneten diese frühen Bemühungen und ersetzten dateibasierte Systeme in vielen gängigen Anwendungsfällen. IBMs Information Management System (IMS) ist ein primäres Beispiel für den hierarchischen Ansatz, der in Unternehmen, insbesondere im Bankwesen, breite Anwendung fand. Obwohl hierarchische Datenmodelle – beginnend in den 1980er Jahren – weitgehend durch relationale Datenmodelle ersetzt wurden, ist die hierarchische Methode noch heute in XML (Extensible Markup Language) und geographischen Informationssystemen (GISes) üblich. Netzwerkdatenmodelle entstanden auch in den frühen Tagen von DBMSes, um Datendesignern eine breite konzeptionelle Sicht auf ihre Systeme zu ermöglichen. Ein solches Beispiel ist die Conference on Data Systems Languages (CODASYL), die Ende der 1950er Jahre gegründet wurde, um die Entwicklung einer Standardprogrammiersprache zu leiten, die für verschiedene Computertypen verwendet werden kann.
Relationale Datenmodellierung
Das hierarchische Modell reduzierte zwar die Programmkomplexität im Vergleich zu dateibasierten Systemen, erforderte jedoch ein detailliertes Verständnis der spezifischen physischen Datenspeicherung. Das relationale Datenmodell, das als Alternative zum hierarchischen Datenmodell vorgeschlagen wird, erfordert von Entwicklern keine Definition von Datenpfaden. Relationale Datenmodellierung wurde erstmals 1970 in einem technischen Artikel des IBM-Forschers E.F. Codd beschrieben. Das relationale Modell von Codd hat die Voraussetzungen für die industrielle Verwendung relationaler Datenbanken geschaffen, in denen Datensegmente explizit mithilfe von Tabellen verknüpft werden, im Vergleich zum hierarchischen Modell, bei dem Daten implizit miteinander verknüpft werden. Bald nach seiner Einführung wurde das relationale Datenmodell mit der Structured Query Language (SQL) gekoppelt und begann, im Enterprise Computing als effizientes Mittel zur Verarbeitung von Daten immer mehr Fuß zu fassen.
Das Entity-Relationship-Modell
Die relationale Datenmodellierung machte ab Mitte der 1970er Jahre einen weiteren Schritt nach vorne, da die Verwendung von Entity-Relationship-Modellen (ER) immer häufiger wurde. ER-Modelle sind eng in relationale Datenmodelle integriert und verwenden Diagramme, um die Elemente in einer Datenbank grafisch darzustellen und das Verständnis der zugrunde liegenden Modelle zu erleichtern.
Bei der relationalen Modellierung werden Datentypen bestimmt und im Laufe der Zeit selten geändert. Entitäten umfassen Attribute; Zu den Attributen einer Mitarbeiterentität können beispielsweise Nachname, Vorname, Beschäftigungsjahre usw. gehören. Beziehungen werden visuell abgebildet, wodurch ein Mittel zur Verfügung steht, um Datenentwurfsziele an verschiedene Teilnehmer der Datenentwicklung und -pflege zu kommunizieren. Im Laufe der Zeit haben Modellierungstools, einschließlich ER / Studio von Idera, Erwin Data Modeler und SAP PowerDesigner, breite Verwendung bei Datenarchitekten für die Gestaltung von Systemen gefunden.
Als die objektorientierte Programmierung in den 1990er Jahren an Boden gewann, gewann die objektorientierte Modellierung als weitere Möglichkeit, Systeme zu entwerfen, an Bedeutung. Objektorientierte Ansätze ähneln zwar ER-Methoden, unterscheiden sich jedoch darin, dass sie sich auf Objektabstraktionen realer Entitäten konzentrieren. Objekte werden in Klassenhierarchien gruppiert, und die Objekte innerhalb solcher Klassenhierarchien können Attribute und Methoden von übergeordneten Klassen erben. Aufgrund dieses Vererbungsmerkmals haben objektorientierte Datenmodelle einige Vorteile gegenüber der ER-Modellierung, was die Gewährleistung der Datenintegrität und die Unterstützung komplexerer Datenbeziehungen betrifft. In den 1990er Jahren entstanden auch Datenmodelle, die sich speziell an den Bedürfnissen des Data Warehousing orientierten. Bemerkenswerte Beispiele sind Dimensionsmodelle für Schneeflockenschemata und Sternschemata.
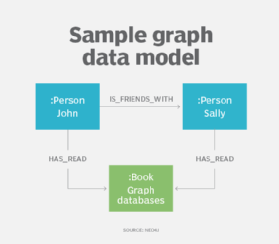
Graph data models
Ein Ableger der hierarchischen und Netzwerkdatenmodellierung ist das Property Graph Model, das zusammen mit Graph-Datenbanken zunehmend zur Beschreibung komplexer Beziehungen innerhalb von Datensätzen eingesetzt wird, insbesondere in Social Media-, Empfehlungs- und Betrugserkennungsanwendungen.
Mit Hilfe des Graph-Datenmodells beschreiben Designer ihr System als einen verbundenen Graphen von Knoten und Beziehungen, ähnlich wie sie es mit der ER- oder Objektdatenmodellierung tun könnten. Diagrammdatenmodelle können für die Textanalyse verwendet werden, um Modelle zu erstellen, die Beziehungen zwischen Datenpunkten in Dokumenten aufdecken.