Die Struktur der DNA bietet einen Mechanismus für die Vererbung
Gene tragen biologische Informationen, die jedes Mal, wenn sich eine Zelle teilt, um zwei Tochterzellen zu bilden, genau kopiert werden müssen, um sie an die nächste Generation zu übertragen. Aus diesen Anforderungen ergeben sich zwei zentrale biologische Fragen: Wie können die Informationen zur Spezifizierung eines Organismus in chemischer Form transportiert werden und wie werden sie genau kopiert? Die Entdeckung der Struktur der DNA-Doppelhelix war ein Meilenstein in der Biologie des zwanzigsten Jahrhunderts, da sie sofort Antworten auf beide Fragen vorschlug und damit das Problem der Vererbung auf molekularer Ebene löste. Wir diskutieren kurz die Antworten auf diese Fragen in diesem Abschnitt, und wir werden sie im Detail in den folgenden Kapiteln untersuchen.DNA kodiert Informationen durch die Reihenfolge oder Sequenz der Nukleotide entlang jedes Strangs. Jede Base – A, C, T oder G — kann als Buchstabe in einem vierbuchstabigen Alphabet betrachtet werden, das biologische Botschaften in der chemischen Struktur der DNA buchstabiert. Wie wir in Kapitel 1 gesehen haben, unterscheiden sich Organismen voneinander, weil ihre jeweiligen DNA-Moleküle unterschiedliche Nukleotidsequenzen haben und folglich unterschiedliche biologische Botschaften tragen. Aber wie wird das Nukleotidalphabet verwendet, um Nachrichten zu machen, und was buchstabieren sie?
Wie oben diskutiert, war lange vor der Bestimmung der DNA-Struktur bekannt, dass Gene die Anweisungen zur Herstellung von Proteinen enthalten. Die DNA-Nachrichten müssen daher irgendwie Proteine kodieren (Abbildung 4-6). Diese Beziehung macht das Problem aufgrund des chemischen Charakters von Proteinen sofort verständlicher. Wie in Kapitel 3 erläutert, werden die Eigenschaften eines Proteins, die für seine biologische Funktion verantwortlich sind, durch seine dreidimensionale Struktur bestimmt, und seine Struktur wird wiederum durch die lineare Sequenz der Aminosäuren bestimmt, aus denen es besteht. Die lineare Sequenz von Nukleotiden in einem Gen muss daher irgendwie die lineare Sequenz von Aminosäuren in einem Protein buchstabieren. Die genaue Übereinstimmung zwischen dem aus vier Buchstaben bestehenden Nukleotidalphabet der DNA und dem aus zwanzig Buchstaben bestehenden Aminosäurenalphabet der Proteine – dem genetischen Code – ist aus der DNA—Struktur nicht ersichtlich, und es dauerte über ein Jahrzehnt nach der Entdeckung der Doppelhelix, bevor es ausgearbeitet wurde. In Kapitel 6 beschreiben wir diesen Code im Detail im Zuge der Ausarbeitung des als Genexpression bekannten Prozesses, durch den eine Zelle die Nukleotidsequenz eines Gens in die Aminosäuresequenz eines Proteins übersetzt.

Abbildung 4-6
Die Beziehung zwischen genetischer Information in DNA und Proteinen.
Der vollständige Informationssatz in der DNA eines Organismus wird als Genom bezeichnet und enthält die Informationen für alle Proteine, die der Organismus jemals synthetisieren wird. (Der Begriff Genom wird auch verwendet, um die DNA zu beschreiben, die diese Information trägt.) Die Menge an Informationen, die in Genomen enthalten sind, ist atemberaubend: Zum Beispiel enthält eine typische menschliche Zelle 2 Meter DNA. Die Nukleotidsequenz eines sehr kleinen menschlichen Gens, das im vierbuchstabigen Nukleotidalphabet geschrieben ist, nimmt ein Viertel einer Textseite ein (Abbildung 4-7), während die vollständige Nukleotidsequenz im menschlichen Genom mehr als tausend Bücher von der Größe dieses Buches füllen würde. Neben anderen wichtigen Informationen enthält es die Anweisungen für etwa 30.000 verschiedene Proteine.

Abbildung 4-7
Die Nukleotidsequenz des humanen β-Globin-Gens. Dieses Gen trägt die Information für die Aminosäuresequenz einer der beiden Arten von Untereinheiten des Hämoglobinmoleküls, das Sauerstoff im Blut transportiert. Ein anderes Gen, das α-Globin (mehr…)
Bei jeder Zellteilung muss die Zelle ihr Genom kopieren, um es an beide Tochterzellen weiterzugeben. Die Entdeckung der Struktur der DNA enthüllte auch das Prinzip, das dieses Kopieren ermöglicht: da jeder DNA-Strang eine Nukleotidsequenz enthält, die genau komplementär zur Nukleotidsequenz seines Partnerstrangs ist, kann jeder Strang als Vorlage oder Form für die Synthese eines neuen komplementären Strangs dienen. Mit anderen Worten, wenn wir die beiden DNA-Stränge als S und S‘ bezeichnen, kann Strang S als Vorlage für die Herstellung eines neuen Strangs S‘ dienen, während Strang S‘ als Vorlage für die Herstellung eines neuen Strangs S dienen kann (Abbildung 4-8). Somit kann die genetische Information in der DNA durch den sehr einfachen Prozess, bei dem sich Strang S von Strang S’trennt, genau kopiert werden, und jeder getrennte Strang dient dann als Vorlage für die Herstellung eines neuen komplementären Partnerstrangs, der mit seinem früheren Partner identisch ist.
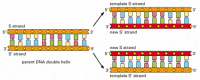
Abbildung 4-8
DNA als Vorlage für ihre eigene Vervielfältigung. Da das Nukleotid A nur mit T und G mit C erfolgreich paart, kann jeder DNA-Strang die Sequenz der Nukleotide in seinem komplementären Strang spezifizieren. Auf diese Weise kann doppelhelikale DNA präzise kopiert werden. (Mehr…)
Die Fähigkeit jedes Strangs eines DNA-Moleküls, als Vorlage für die Herstellung eines komplementären Strangs zu fungieren, ermöglicht es einer Zelle, ihre Gene zu kopieren oder zu replizieren, bevor sie an ihre Nachkommen weitergegeben werden. Im nächsten Kapitel beschreiben wir die elegante Maschinerie, mit der die Zelle diese enorme Aufgabe erfüllt.