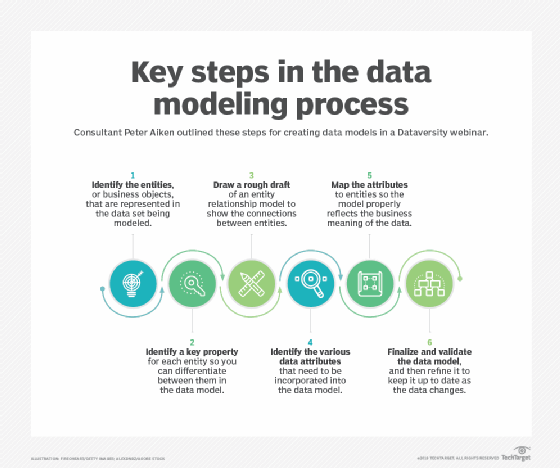
datamodellering är processen att dokumentera en komplex mjukvarusystemdesign som ett lättförståeligt diagram, med hjälp av text och symboler för att representera hur data behöver flöda. Diagrammet kan användas för att säkerställa effektiv användning av data, som en ritning för konstruktion av ny programvara eller för omkonstruktion av en äldre applikation.
datamodellering är en viktig färdighet för Dataforskare eller andra som är involverade i dataanalys. Traditionellt har datamodeller byggts under analys-och designfaserna i ett projekt för att säkerställa att kraven för en ny applikation är fullt förstådda. Datamodeller kan också åberopas senare i datalivscykeln för att rationalisera datadesigner som ursprungligen skapades av programmerare på ad hoc-basis.
datamodelleringsmetoder
datamodellering kan vara en noggrann upfront process och, som sådan, ibland ses som i strid med snabba utvecklingsmetoder. Eftersom Agil programmering har kommit i större utsträckning för att påskynda utvecklingsprojekt, anpassas i vissa fall metoder för datamodellering. Vanligtvis kan en datamodell betraktas som ett flödesschema som illustrerar relationerna mellan data. Det gör det möjligt för intressenter att identifiera fel och göra ändringar innan någon programmeringskod har skrivits. Alternativt kan modeller introduceras som en del av omvänd teknikarbete som extraherar modeller från befintliga system, vilket ses med NoSQL-data.
datamodeller använder ofta flera Modeller för att visa samma data och se till att alla processer, enheter, relationer och dataflöden har identifierats. De initierar nya projekt genom att samla krav från affärsintressenter. Datamodellering steg grovt delas in i skapandet av logiska datamodeller som visar specifika attribut, enheter och relationer mellan enheter och den fysiska datamodellen.
den logiska datamodellen fungerar som grund för skapandet av en fysisk datamodell, som är specifik för applikationen och databasen som ska implementeras. En datamodell kan bli grunden för att bygga ett mer detaljerat dataschema.
hierarkisk datamodellering
datamodellering som en disciplin började uppstå på 1960-talet, som åtföljer uppgången i bruk databashanteringssystem (dbmses). Datamodellering gjorde det möjligt för organisationer att få konsekvens, repeterbarhet och välordnad utveckling till databehandling. Applikationens slutanvändare och programmerare kunde använda datamodellen som referens i kommunikation med datadesigners.
hierarkiska datamodeller som array data i treelike, en-till-många arrangemang markerade dessa tidiga ansträngningar och ersatte filbaserade system i många populära användningsfall. IBMs Information Management System (IMS) är ett primärt exempel på det hierarkiska tillvägagångssättet, som fann stor användning i företag, särskilt inom bank. Även om hierarkiska datamodeller till stor del ersattes-från och med 1980-talet-av relationella datamodeller, är den hierarkiska metoden vanlig fortfarande i XML (Extensible Markup Language) och geographic information systems (GISes) idag. Nätverks datamodeller uppstod också i början av DBMSes som ett sätt att ge data designers med en bred konceptuell syn på sina system. Ett sådant exempel är konferensen om Datasystemspråk (CODASYL), som bildades i slutet av 1950-talet för att styra utvecklingen av ett standardprogrammeringsspråk som kan användas över olika typer av datorer.
relationell datamodellering
medan det minskade programkomplexiteten jämfört med filbaserade system, krävde den hierarkiska modellen fortfarande detaljerad förståelse för den specifika fysiska datalagringen som användes. Den relationella datamodellen föreslås som ett alternativ till den hierarkiska datamodellen och kräver inte att utvecklare definierar datavägar. Relationell datamodellering beskrevs först i ett tekniskt papper från 1970 av IBM-forskaren E. F. Codd. Codds relationsmodell satte scenen för branschanvändning av relationsdatabaser där datasegment uttryckligen förenas med användning av tabeller, jämfört med den hierarkiska modellen där data implicit sammanfogas. Strax efter starten kopplades relationsdatamodellen med Structured Query Language (SQL) och började få ett allt större fotfäste i företagsberäkning som ett effektivt sätt att bearbeta data.
entity relationship model
relationell datamodellering tog ytterligare ett steg framåt med början i mitten av 1970-talet när användningen av entity relationship (ER) – modeller blev vanligare. Nära integrerade med relationella datamodeller använder ER-modeller diagram för att grafiskt avbilda elementen i en databas och för att underlätta förståelsen av underliggande modeller.
med relationell modellering bestäms datatyper och ändras sällan över tiden. Entiteter består av attribut; till exempel kan en anställds entitets attribut inkludera efternamn, förnamn, år anställda och så vidare. Relationer kartläggs visuellt, vilket ger ett klart sätt att kommunicera datadesignmål till olika deltagare i datautveckling och underhåll. Med tiden fick modelleringsverktyg, inklusive Idera ER/Studio, Erwin Data Modeler och SAP PowerDesigner, stor användning bland dataarkitekter för att designa system.
När objektorienterad programmering fick mark på 1990-talet fick Objektorienterad modellering dragkraft som ännu ett sätt att designa system. Medan de liknar ER-metoder skiljer sig objektorienterade tillvägagångssätt genom att de fokuserar på objektabstraktioner av verkliga enheter. Objekt grupperas i klasshierarkier, och objekten i sådana klasshierarkier kan ärva attribut och metoder från överordnade klasser. På grund av detta arvdrag har objektorienterade datamodeller vissa fördelar jämfört med er-modellering, när det gäller att säkerställa dataintegritet och stödja mer komplexa dataförhållanden. Även på 1990-talet uppstod datamodeller specifikt inriktade på datalagringsbehov. Anmärkningsvärda exempel är snöflinga schema och stjärnschema dimensionella modeller.
Graph datamodeller
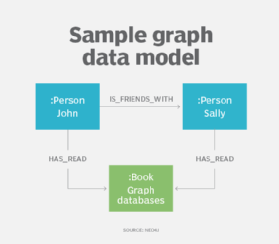
en utlöpare av hierarkisk och nätverks datamodellering är egenskapen graph model, som tillsammans med graph databaser, har funnit ökad användning för att beskriva komplexa relationer inom datamängder, särskilt i sociala medier, recommender och bedrägeri upptäckt applikationer.
med hjälp av grafdatamodellen beskriver designers sitt system som en ansluten Graf över noder och relationer, mycket som de kan göra med er-eller objektdatamodellering. Grafdatamodeller kan användas för textanalys, skapa modeller som avslöjar relationer mellan datapunkter i dokument.