DNA-strukturen ger en mekanism för ärftlighet
gener bär biologisk information som måste kopieras exakt för överföring till nästa generation varje gång en cell delar sig för att bilda två dotterceller. Två centrala biologiska frågor härrör från dessa krav: hur kan informationen för att specificera en organism transporteras i kemisk form och hur kopieras den exakt? Upptäckten av strukturen hos DNA – dubbelhelixen var ett landmärke i det tjugonde århundradet biologi eftersom det omedelbart föreslog svar på båda frågorna och därigenom löste på molekylär nivå problemet med ärftlighet. Vi diskuterar kortfattat svaren på dessa frågor i detta avsnitt, och vi kommer att undersöka dem mer detaljerat i efterföljande kapitel.
DNA kodar information genom ordningen eller sekvensen av nukleotiderna längs varje sträng. Varje bas-A, C, T eller G—kan betraktas som en bokstav i ett alfabet med fyra bokstäver som stavar ut biologiska meddelanden i DNA: s kemiska struktur. Som vi såg i kapitel 1 skiljer sig organismer från varandra eftersom deras respektive DNA-molekyler har olika nukleotidsekvenser och följaktligen bär olika biologiska meddelanden. Men hur används nukleotidalfabetet för att skapa meddelanden, och vad stavar de ut?
som diskuterats ovan var det känt långt innan DNA-strukturen bestämdes att gener innehåller instruktionerna för att producera proteiner. DNA-meddelandena måste därför på något sätt koda proteiner (figur 4-6). Detta förhållande gör omedelbart problemet lättare att förstå på grund av proteins kemiska karaktär. Som diskuterats i kapitel 3 bestäms egenskaperna hos ett protein, som är ansvariga för dess biologiska funktion, av dess tredimensionella struktur, och dess struktur bestäms i sin tur av den linjära sekvensen av de aminosyror som den består av. Den linjära sekvensen av nukleotider i en gen måste därför på något sätt stava ut den linjära sekvensen av aminosyror i ett protein. Den exakta korrespondensen mellan DNA: s fyra bokstäver nukleotidalfabet och proteinets tjugo bokstäver aminosyraalfabet-den genetiska koden-är inte uppenbar från DNA—strukturen, och det tog över ett decennium efter upptäckten av dubbelhelixen innan den utarbetades. I kapitel 6 beskriver vi denna kod i detalj under utarbetandet av processen, känd som genuttryck, genom vilken en cell översätter nukleotidsekvensen för en gen till aminosyrasekvensen för ett protein.

figur 4-6
förhållandet mellan genetisk information som bärs i DNA och proteiner.
den kompletta uppsättningen information i en organisms DNA kallas dess genom, och den bär informationen för alla proteiner som organismen någonsin kommer att syntetisera. (Termen genom används också för att beskriva DNA som bär denna information.) Mängden information som finns i genom är svindlande: till exempel innehåller en typisk mänsklig cell 2 meter DNA. Skriven i nukleotidalfabetet med fyra bokstäver upptar nukleotidsekvensen för en mycket liten mänsklig gen en fjärdedel av en textsida (figur 4-7), medan den fullständiga sekvensen av nukleotider i det mänskliga genomet skulle fylla mer än tusen böcker storleken på den här. Förutom annan kritisk information bär den instruktionerna för cirka 30 000 distinkta proteiner.

figur 4-7
nukleotidsekvensen för den humana genen av CI-globin. Denna gen bär informationen för aminosyrasekvensen av en av de två typerna av subenheter i hemoglobinmolekylen, som bär syre i blodet. En annan gen, den Kubi-globin (mer…)
vid varje celldelning måste cellen kopiera sitt genom för att överföra det till båda dottercellerna. Upptäckten av DNA-strukturen avslöjade också principen som gör denna kopiering möjlig: eftersom varje DNA-sträng innehåller en sekvens av nukleotider som exakt kompletterar nukleotidsekvensen för sin partnersträng, kan varje sträng fungera som en mall eller mögel för syntesen av en ny komplementär sträng. Med andra ord, om vi betecknar de två DNA-strängarna som S och S’, kan sträng s fungera som en mall för att göra en ny sträng S’, medan sträng S’ kan fungera som en mall för att göra en ny sträng S (figur 4-8). Således kan den genetiska informationen i DNA kopieras exakt av den vackert enkla processen där sträng s skiljer sig från sträng S’, och varje Separerad sträng tjänar sedan som en mall för produktion av en ny komplementär partnersträng som är identisk med sin tidigare partner.
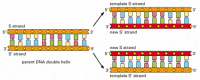
figur 4-8
DNA som en mall för egen duplicering. Eftersom nukleotiden a framgångsrikt parar endast med T och G med C, kan varje DNA-sträng specificera sekvensen av nukleotider i dess komplementära sträng. På detta sätt kan Dubbel-spiralformigt DNA kopieras exakt. (mer…)
förmågan hos varje sträng av en DNA-molekyl att fungera som en mall för att producera en komplementär sträng gör det möjligt för en cell att kopiera eller replikera sina gener innan de överförs till sina ättlingar. I nästa kapitel beskriver vi de eleganta maskiner cellen använder för att utföra denna enorma uppgift.