- Eh? Wat zijn GROEPERINGSSET, kubus en ROLLUP in SQL?
- waarom zou ROLLUP of CUBE nuttig zijn voor mij?
- zijn deze standaard SQL of zijn ze een Microsoft-only ding?
- kan ik een of meer kolommen uitsluiten van de ROLLUP?
- Wat zijn GROEPEERVERZAMELINGEN dan? Moet ik het weten?
- waarom zouden we kolommen in een aggregatie willen combineren?
- is er meer aan het groeperen van Verzamelingen dan een manier om ‘à la carte’ kubussen te maken?
- Waarom worden de functies Grouping() en Grouping_ID() gegeven?
- Eh? Wat zijn GROEPERINGSSET, kubus en ROLLUP in SQL?
- waarom zou ROLLUP of CUBE nuttig zijn voor mij?
- zijn deze standaard SQL of zijn ze een Microsoft – only ding?
- kan ik een of meer kolommen uitsluiten van de ROLLUP?
- Wat zijn GROEPERINGSSETS dan? Moet ik het weten?
- waarom zouden we kolommen in een aggregatie willen combineren?
- is er meer aan het groeperen van Verzamelingen dan een manier om ‘à la carte’ kubussen te maken?
- Waarom worden de functies Grouping() en Grouping_ID() gegeven?
Eh? Wat zijn GROEPERINGSSET, kubus en ROLLUP in SQL?
CUBE, ROLLUP en GROUPING SET zijn optionele operators van de groep door clausule van de SELECT statement voor het doen van rapporten met grote hoeveelheden informatie. Ze stellen u in staat om verschillende groepen te doen door bewerkingen in één statement, potentieel bespaart een hoop tijd en computationele inspanning. Ze kunnen alle informatie verstrekken die nodig is voor de rapportage, inclusief totalen, terwijl ze goede prestaties leveren over grote tabellen en de Query Optimiser helpen een goed uitvoeringsplan op te stellen.
de extra’ super-aggregaat ‘ rijen bieden samenvattende waarden, waardoor u meerdere ‘aggregaties’ kunt hebben, zoals SUM() of MAX() binnen het ene resultaat. De NULLs binnen deze rijen in het resultaat zijn bedoeld om ‘alle’ te betekenen in plaats van ‘Onbekend’. Hiermee kunt u alle aggregaties die u nodig hebt in een pas door de tabel. Vanwege de aanwezigheid van extra rijen in de resultaten worden extra functies GROUPING() en GROUPING_ID() verstrekt om deze extra “supergeaggregeerde” rijen aan te geven en welke kolommen worden geaggregeerd.
Dit heeft veel zin als u een applicatie hebt die meerdere rapporten moet draaien zonder extra berekening of zonder terug te gaan naar de database: U hebt alles wat u nodig hebt in één resultaat.
neem dit standaard voorbeeld van een ROLLUP (Ik gebruik hier AdventureWorks 2012)..
|
1
2
3
4
5
6
|
SELECTEER t. ALS regio, t.naam grondgebied, sum(TotalDue) ALS omzet,
datepart(jjjj, OrderDate) ALS datepart(mm, OrderDate) ALS
VAN de Omzet.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory t ON s. TerritoryID = T. TerritoryID
groep per t., t. naam, datepart(jjjj, Orderdatum), datepart(mm, Orderdatum)
met ROLLUP
|
evenals de eenvoudige groep op geaggregeerde rijen, met het totaal dat voor elke maand verschuldigd is, dat je krijgt met een eenvoudige groepering, krijg je ook subtotaal of supergeaggregeerde rijen, en ook een totaal-generaal rij. (hier is het begin van het resultaat)
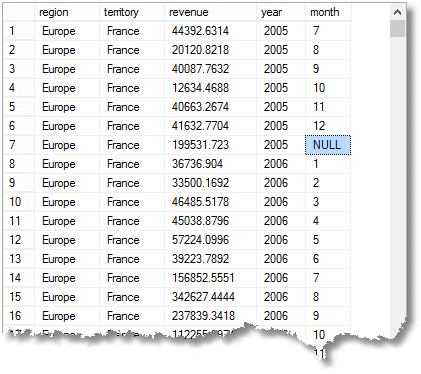
Dat NULL I ‘ve highlit betekent dat de rij een aggregaat is voor’ alle ‘ maanden van 2005 in Frankrijk (deel van de regio Europa)
evenals dit alles, krijg je het totaal verschuldigd voor elk jaar, voor elk grondgebied en territoriale groep, evenals het volledige Totaal verschuldigd. (vanaf het einde)
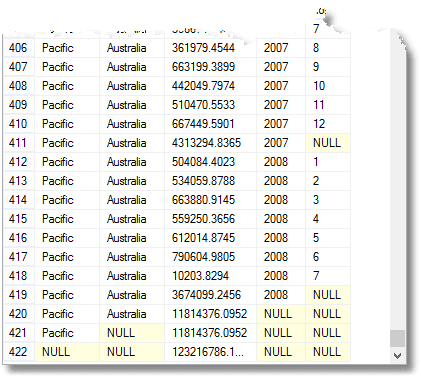
deze NULLs betekenen ‘All’, onthoud. De laatste rij is het totaal, en daarboven is het totaal voor de Stille Oceaan. Boven dat is de bijdrage van Australië aan de Stille Oceaan. De vierde rij van de onderkant is Australië ‘ s 2008 bijdrage. Het aantal groepen dat wordt geretourneerd is één meer dan het aantal uitdrukkingen in de lijst met samengestelde elementen die aan de groep wordt verstrekt door een statement.
om hetzelfde effect Te krijgen zonder gebruik te maken van de rollup, zou je nodig hebt om iets te doen als dit (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
met myGrouping (region, territory, totalDue,,)
Als ( selecteer t., t.name, Som (totaal) als inkomsten,
datepart(jjjj, Orderdatum) als , datepart (mm, Orderdatum) als
uit verkopen.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory t ON s. TerritoryID = T. TerritoryID
groep door t.name, t., datepart(jjjj, OrderDate), datepart(mm, OrderDate))
SELECTEER Regio, gebied, totalDue, ,
VAN myGrouping
UNION
SELECTEER Regio, gebied, sum(totalDue), NULL
VAN myGrouping GROEP PER Regio, gebied,
UNION
SELECTEER Regio, gebied, sum(totalDue), NULL, NULL
VAN myGrouping GROEP PER Regio, gebied
UNION
SELECTEER Regio, NULL, sum(totalDue), NULL, NULL
VAN myGrouping GROEP PER Regio
UNION
SELECTEER NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.name, datepart(yyyy,OrderDate),datepart (mm,OrderDate))’
|
Deze nieuwe syntaxis geeft u wat extra functionaliteit. Onthoud ook dat de kolomvolgorde de uitvoergroepen van ROLLUP beïnvloedt en het aantal rijen in de resultaatset kan beïnvloeden.
De Kubus doet hetzelfde algemene ding, maar in plaats van een hiërarchie van totalen in geordende supergeaggregeerde rijen te geven, geeft hij alle ‘supergeaggregeerde’ permutaties (‘symmetrische supergeaggregeerde’ rijen), de zogenaamde cross-tabulation rijen. Als je wilt weten welk gebied de meeste orders gaf in maart, of welk gebied het minst goed presteerde in 2006, dan heb je een kubus nodig. U geeft alle mogelijke samenvattingen in het resultaat.
GROUPING SET stelt u in staat om uw resultaat te verfijnen om meer gespecialiseerde informatie te bieden boven en buiten de kubus. Het kan beknopte informatie geven over combinaties van afmetingen. Je zou precies hetzelfde resultaat kunnen krijgen als in ons ROLLUP Voorbeeld door GROEPERINGSSETS te gebruiken, maar met veel meer typen.
|
1
2
3
4
5
6
7
8
9
10
|
SELECTEER t. ALS regio, t.naam grondgebied, sum(TotalDue) ALS omzet,
datepart(jjjj, OrderDate) ALS datepart(mm, OrderDate) ALS
VAN de Omzet.SalesOrderHeader s
INNER JOIN Sales.Verkoopgebied T op s. TerritoryID = T.TerritoryID
groep door groepen SETS (
(T., T.name,datepart (jjjj, Orderdatum), datepart(mm, Orderdatum)),
(T., T.name, datum(jjjj, Orderdatum)),
(T., T.name),
(T.),
())
|
Dit is alleen om te laten zien hoe ze betrekking hebben. In werkelijkheid, je zou toevlucht nemen tot het groeperen van SETS om resultaten die onmogelijk zijn met ROLLUP of CUBE te krijgen.
bijna al deze samenvattingen kunnen worden verkregen door alleen groep door te gebruiken, maar alleen door het resultaat van een groep herhaaldelijk te groeperen door, of door meer dan één door de gegevens te laten passeren.
wanneer u CUBE, ROLLUP of GROUPING SETS gebruikt, kunt u het verschillende trefwoord niet gebruiken in uw samengevoegde expressies, zoals AVG (DISTINCT column_name), COUNT (DISTINCT column_name), en SUM (DISTINCT column_name)
waarom zou ROLLUP of CUBE nuttig zijn voor mij?
ROLLUP en CUBE hadden hun hoogtijdagen voor SSA ‘ s. Ze waren nuttig voor het verstrekken van dezelfde soort faciliteiten aangeboden door de kubus in OLAP. Het heeft echter nog steeds zijn nut. In AdventureWorks, het is overkill, maar als u omgaan met grote hoeveelheden gegevens die u nodig hebt om uw gegevens slechts één keer door te geven, en doe zo veel mogelijk op gegevens die is samengevoegd. Gebeurtenissen uit het verleden kunnen niet worden veranderd, dus het is zelden nodig om historische gegevens op een actief OLTP-systeem te bewaren. In plaats daarvan hoeft u alleen de geaggregeerde gegevens te bewaren op het detailniveau (‘granulariteit’) dat vereist is voor alle te verwachten rapporten.
stel je voor dat je verantwoordelijk bent voor het rapporteren van een telefoonschakelaar met ongeveer twee miljoen oproepen per dag. Als je al deze oproepen op je OLTP server bewaart, zul je snel merken dat de SQL Server bezig is met gebruiksrapporten. U moet de oorspronkelijke belinformatie voor een wettelijke periode bewaren, maar u bepaalt vanuit het bedrijf dat ze hoogstens geïnteresseerd zijn in het aantal gesprekken in een minuut. Dan heb je je opslagbehoefte op de OLTP server teruggebracht tot 1.4% van wat het was, en de oproeprecords kunnen worden gearchiveerd naar een andere SQL Server voor ad-hoc query ‘ s en klantafschriften. Dat is waarschijnlijk een besparing waard. Met de kubus-en ROLLUP-clausules kunt u zelfs de rijtotalen, kolomtotalen en grote totalen opslaan zonder dat u een tabel of geclusterde indexscan van de samenvattingstabel hoeft te maken.
zolang wijzigingen niet achteraf worden aangebracht in deze gegevens, en alle tijdsperioden volledig zijn, hoeft u nooit de aggregaties te herhalen of te wijzigen op basis van vroegere tijdsperioden, hoewel grote totalen overschreven moeten worden!.
laten we doen alsof, maar AdventureWorks2012 gebruiken om mee te spelen.
ten eerste maken we de gramsamenvatting tabel.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
ALS EXISTS (SELECT * FROM tempdb.sys.tabellen WAAR de naam ‘#AggregationTable%’)
DROP TABLE #aggregationTable –verwijderen van de tijdelijke tabel indien aanwezig
GO
SELECTEER
identiteit(INT,1,1), –dus we kunnen een unieke kolom
t. ALS regio, t.naam grondgebied, sum(TotalDue) ALS omzet,
datepart(jjjj, OrderDate) ALS datepart(mm, OrderDate) ALS ,
groeperen(t.naam isNameGroup, –verhoudt dit zich tot ALLE gebieden
groeperen(t.) ALS isGroupGroup,–Kan dit betrekking hebben op ALLE continenten
groeperen(datepart(jjjj, OrderDate)) ALS isYearGroup,–verhoudt dit zich tot ALLE jaar
groeperen(datepart(mm, OrderDate)) ALS isMonthGroup,–verhoudt dit zich tot ALLE maanden
Grouping_ID (t.naam,t.,
datepart(jjjj, OrderDate),datepart(mm, OrderDate)) ALS isGroupingRow
–dit is een extra niet-data rij met geaggregeerde gegevens
IN #AggregationTable
VAN de Omzet.SalesOrderHeader s
INNER JOIN Sales.Verkoopgebied T op s. TerritoryID = T.TerritoryID
groep door t.name, t., datepart(yyyy, OrderDate), datepart (mm, OrderDate)
met ROLLUP
|
merk op dat we extra ‘bit’ – kolommen toevoegen die ons vertellen welke rijen de samenvattingsrijen bevatten. Als je ze per ongeluk toe te voegen aan verdere aggregaties krijg je een aantal serieus opgeblazen resultaten. U kunt Grouping() of Grouping_ID natuurlijk niet gebruiken op het opgeslagen resultaat, dus u moet iets in plaats daarvan opgeven.
Nu kunnen we produceren de draaitabel heel snel
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
— nu kunnen we het maken van een eenvoudige draaitabel met rij-en
— kolom totalen
SELECTEER Grondgebied,
sum(GEVAL WANNEER 2005 omzet ELSE 0 END) ALS ,
sum(ZAAK ALS IN 2006 TOEN de omzet ELSE 0 END) ALS ,
sum(ZAAK ALS IN 2007 TOEN de omzet ELSE 0 END) ALS ,
sum(ZAAK ALS IN 2008 TOEN de omzet ELSE 0 END) ALS ,
sum(omzet) ALS
VAN #AggregationTable
WAAR isGroupingrow =0
GROEP PER gebied
UNION
KIES ‘Totaal’, sum(GEVAL WANNEER 2005 omzet ELSE 0 END) ALS ,
sum(ZAAK ALS IN 2006 TOEN de omzet ELSE 0 END) ALS ,
sum(ZAAK ALS IN 2007 TOEN de omzet ELSE 0 END) ALS ,
Som(wanneer 2008 dan inkomsten anders 0 einde) als ,
Som(inkomsten) als
uit #AggregationTable
waar isYearGroup =0 en isMonthGroup=1
|

dus er zijn korte glimlachen van de managers als ze dit zien, maar dan zeggen ze helder: ‘Ik weet zeker dat ik ook gevraagd heb om een uitsplitsing naar Territorium per maand
met een korte lach, doe je dit.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECTEER
datename(MAAND,dateadd(MAAND -, , ’01 dec 2000′)) ALS ,
sum(ZAAK grondgebied ALS ‘Australië’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Canada’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK gebied BIJ het ‘Centrum’ en VERVOLGENS de inkomsten ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Frankrijk’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Duitsland’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Noordoost’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied WANNEER ‘Noordwest’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Zuidoost’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Zuidwest’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK gebied BIJ het ‘Verenigd Koninkrijk’ DAN de omzet ELSE 0 END) ALS ,
sum(omzet) ALS
VAN #AggregationTable
WAAR isGroupingrow =0
GROEP PER maand
UNION
SELECTEER
‘Totaal’,
sum(ZAAK grondgebied ALS ‘Australië’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied WANNEER ‘Canada’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK gebied BIJ het ‘Centrum’ en VERVOLGENS de inkomsten ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Frankrijk’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Duitsland’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Noordoost’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Noordwest’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Zuidoost’ DAN de omzet ELSE 0 END) ALS ,
sum(ZAAK grondgebied ALS ‘Zuidwest’ DAN de omzet ELSE 0 END) ALS ,
sum(CASE territory WHEN”United Kingdom”THEN revenue ELSE 0 END) AS ,
sum(revenue) AS
FROM #AggregationTable
waar isGroupingrow =0
|

maar als u kubus in plaats van Rollup had gebruikt, zou die laatste rij’ Totaal ‘ al zijn berekend. In een echt voorbeeld zou dat tijd kosten om het verslag op te stellen. U kunt een kubus doen op maximaal tien dimensies; hoewel ze de neiging om bulk up van de aggregatie, ze zijn niet te duur.
zijn deze standaard SQL of zijn ze een Microsoft – only ding?
Deze zijn nu standaard ANSI SQL uit 1999, hoewel met CUBE en met ROLLUP voor het eerst werden geïntroduceerd door Microsoft. Deze insluiting is enigszins verrassend in het feit dat ze een tweede Betekenis, ‘alle’, voor de nulwaarde naast ‘onbekend’introduceren. Toen Microsoft voor het eerst CUBE en ROLLUP introduceerde, was de syntaxis iets anders, maar beide vormen zijn toegestaan in SQL Server. Slechts één syntaxisstijl kan worden gebruikt in een enkele SELECT statement, en je moet de ISO-compatibele syntaxis gebruiken voor al het nieuwe werk.
kan ik een of meer kolommen uitsluiten van de ROLLUP?
Als u dat wilt! Stel je voor dat ik wilde niet een super-totale voor alle regio ‘ s (t.)
|
1
2
3
4
5
6
|
SELECTEER t. ALS regio, t.naam grondgebied, sum(TotalDue) ALS omzet,
datepart(jjjj, OrderDate) ALS datepart(mm, OrderDate) ALS
VAN de Omzet.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory t ON s. TerritoryID = T. TerritoryID
groep per T., ROLLUP (t.name, datepart(yyyy, OrderDate), datepart (mm, OrderDate))
|
Hier gebruiken we de syntaxis die voldoet aan ANSI SQL 2006. Je kunt hetzelfde doen met een kubus. Ik heb hier nooit een praktisch nut voor gevonden, maar je zou het kunnen tegenkomen
Wat zijn GROEPERINGSSETS dan? Moet ik het weten?
groeperen betekent dat u SQL meerdere keren vraagt om het resultaat te groeperen. U kunt de syntaxis GROEPERINGSSETS gebruiken om precies te specificeren welke aggregaties moeten worden berekend. Hier is een voorbeeld.
|
1
2
3
4
5
6
|
SELECTEER t. ALS regio, t.naam grondgebied, sum(TotalDue) ALS omzet,
datepart(jjjj, OrderDate) ALS datepart(mm, OrderDate) ALS
VAN de Omzet.SalesOrderHeader s
INNER JOIN Sales.Verkoopruimte t ON s.TerritoryID = T. TerritoryID
groep per t., GROEPEERVERZAMELINGEN (ROLLUP(t.name),
ROLLUP(datepart(yyyy, Orderdatum), datepart(mm, Orderdatum))
|
hier vraagt u voor elke maand van elk jaar de uitsplitsing naar gebiedsgroep met maand-en jaartotalen, gevolgd door een samenvattend totaal per gebiedsnaam, maar zonder totaal. In tegenstelling tot de ROLLUP, krijg je hetzelfde resultaat ongeacht de volgorde van de kolommen binnen elke groep SET en de volgorde van de groep SETS.
GROEPERINGSSETS kunnen je precies geven wat CUBE en ROLLUP je geven en nog veel meer. Zoals u kunt zien met dit laatste voorbeeld, kunt u standaard’ table d ‘hôte’ kubus en ROLLUP gemengd met direct uitgedrukte ‘à la carte ‘GROEPENSETS gebruiken.
waarom zouden we kolommen in een aggregatie willen combineren?
wanneer in sommige rapporten twee kolommen moeten worden gecombineerd, is het nuttig een aggregatie te declareren die twee kolommen combineert. In het eerste voorbeeld combineren we het jaar en de maand voor het pakket, dat het effect van het beperken van de totalen gewoon elk gebied,
|
1
2
3
4
5
6
7
|
–voor de totalen voor elk gebied alleen – geen totalen voor elke regio of het hele jaar
SELECTEER t. ALS regio, t.naam als gebied, Som (totaal) als inkomsten,
datepart(jjjj, Orderdatum) als , datepart (mm, Orderdatum) als
uit verkopen.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory t ON s. TerritoryID = T. TerritoryID
groep per t., t.name, ROLLUP
((datepart (yyyy, OrderDate), datepart(mm, OrderDate)))
|
Deze extra haakje in de ROLLUP-clausule heeft tot gevolg gehad dat de aggregaties beperkt zijn tot alleen het gebied en de maand/jaar. Laat ze weg, en je krijgt totalen voor elk jaar.
|
1
2
3
4
5
6
7
8
9
10
|
–voor de totalen voor ieder jaar binnen elke grondgebied alsmede de totalen
–voor elk gebied
— geen totalen voor elke regio
SELECTEER t. ALS regio, t.naam als gebied, Som (totaal) als inkomsten,
datepart(jjjj, Orderdatum) als , datepart (mm, Orderdatum) als
uit verkopen.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory t ON s. TerritoryID = T. TerritoryID
groep per t., t.name, ROLLUP
(datepart (jjjj, Orderdatum), datepart(mm, Orderdatum))
|
Dit kan zeer nuttig zijn voor bepaalde gegevens. We hebben hier geen kolommen hoeven te combineren. Als je een kubus zou maken, en de termen voor gebieden de woorden ‘noordelijk’ of ‘Zuidelijk’ gebruiken om een gebied in meer dan één regio te beschrijven, zou je een aantal bizarre aggregaties hebben die van toepassing zijn op ‘noordelijke’ gebieden die niet verwant zijn. Door kolommen te combineren, zou je dit vermijden.
is er meer aan het groeperen van Verzamelingen dan een manier om ‘à la carte’ kubussen te maken?
Ik weet niet zeker of ik Verlegen zou zijn om deze vraag te stellen. SQL:1999 ‘ s groepering SETS bieden een rijke recursieve syntaxis die u toelaat om combinaties van kolommen te aggregeren en definiëren van allerlei esoterische rapporten die tot tien dimensies. De aggregaties kunnen worden genest en u kunt Nest kubussen binnen ROLLUPs en nest ROLLUPs binnen kubussen. U moet een gespecialiseerde publicatie lezen om hier meer over te weten te komen.
Waarom worden de functies Grouping() en Grouping_ID() gegeven?
Het is niet echt een goed idee om NULL te gebruiken om aan te geven dat een kolom een aggregatie is. Het probleem is dat, als een groep kolom null waarden bevat, alle null waarden worden beschouwd als gelijk, en zet in een enkele NULL groep die zich voordoet als een samenvatting. Om de voor de hand liggende moeilijkheid van NULL-waarden in de oorspronkelijke gegevens te omzeilen, worden twee functies geleverd: Grouping() en Grouping_ID().
de functie Grouping() wordt doorgegeven aan de naam van een kolom die deelnam aan de ROLLUP, CUBE of GROUPING SET. Het geeft nul terug als deze rij een samenvatting is voor deze kolom met een nulwaarde die ‘alles’ betekent of als deze een waarde bevat.
De functie GROUPING_ID wordt doorgegeven aan een lijst die exact overeenkomt met de expressie in de groep per lijst. GROUPING_ID wordt aangemaakt als een bitmap van de respectievelijke samenvattingskolommen. Als bijvoorbeeld de territoriumkolom een NULL betekent voor’ alle ‘ gebieden in plaats van een naam van een territorium, en het wordt vermeld als de tweede kolom, dan is het tweede bit van links ingesteld. Dit geheel getal wordt dan geretourneerd.
Grouping_ID() wordt in het algemeen gebruikt om aan te geven of de rij een primaire of secundaire aggregatie is (0 of >0) en, indien secundair, dan door manipulatie van een andere groep uitgesloten.
Het wordt meestal als een goede praktijk beschouwd om voor elke dimensie (zoals ‘Territory’ of ‘Region’ in ons voorbeeld) een bitkolom op te nemen die is ingesteld als de rij een samenvatting is voor die dimensie, samen met een Grouping_ID() waarde om verdere groepering van het resultaat te ondersteunen.
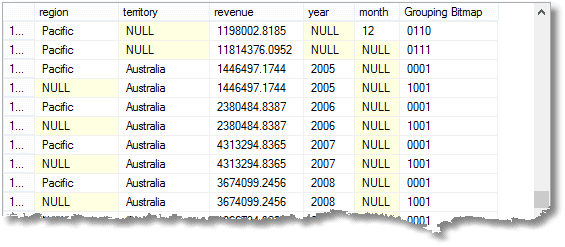
om de manier te illustreren waarop Grouping_ID eigenlijk werkt, kunnen we hier kijken naar de manier waarop de bits in de Grouping_ID zijn ingesteld op basis van het type samenvatting. We gebruiken Phil Factor ‘ s functie om de stukjes te laten zien.
|
1
2
3
4
5
6
7
8
9
|
SELECTEER t. ALS regio, t.naam als gebied, Som (totaal) als inkomsten,
datepart(jjjj, Orderdatum) AS , datepart (mm, Orderdatum) AS ,
right (
dbo.ToBinaryString (–list all the group by items as they are
Grouping_ID(t., t.name, datepart(yyyy,OrderDate), datepart (mm,OrderDate))
), 4) AS –gebruik gewoon de laatste vier tekens omdat we vier kolommen in onze lijst hebben.
uit verkopen.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory t ON s. TerritoryID = T. TerritoryID
groep per kubus (t., t.naam, datepart(jjjj,Orderdatum), datepart(mm, Orderdatum))
|
Dit geeft (slechts een voorbeeld natuurlijk)…