
dat is een belangrijk punt om te begrijpen. Niet alleen zal het gebruik van de verkeerde methode soms leiden tot pagina ‘ s niet worden verwijderd uit de index zoals bedoeld, maar het kan ook een negatief effect hebben op SEO.
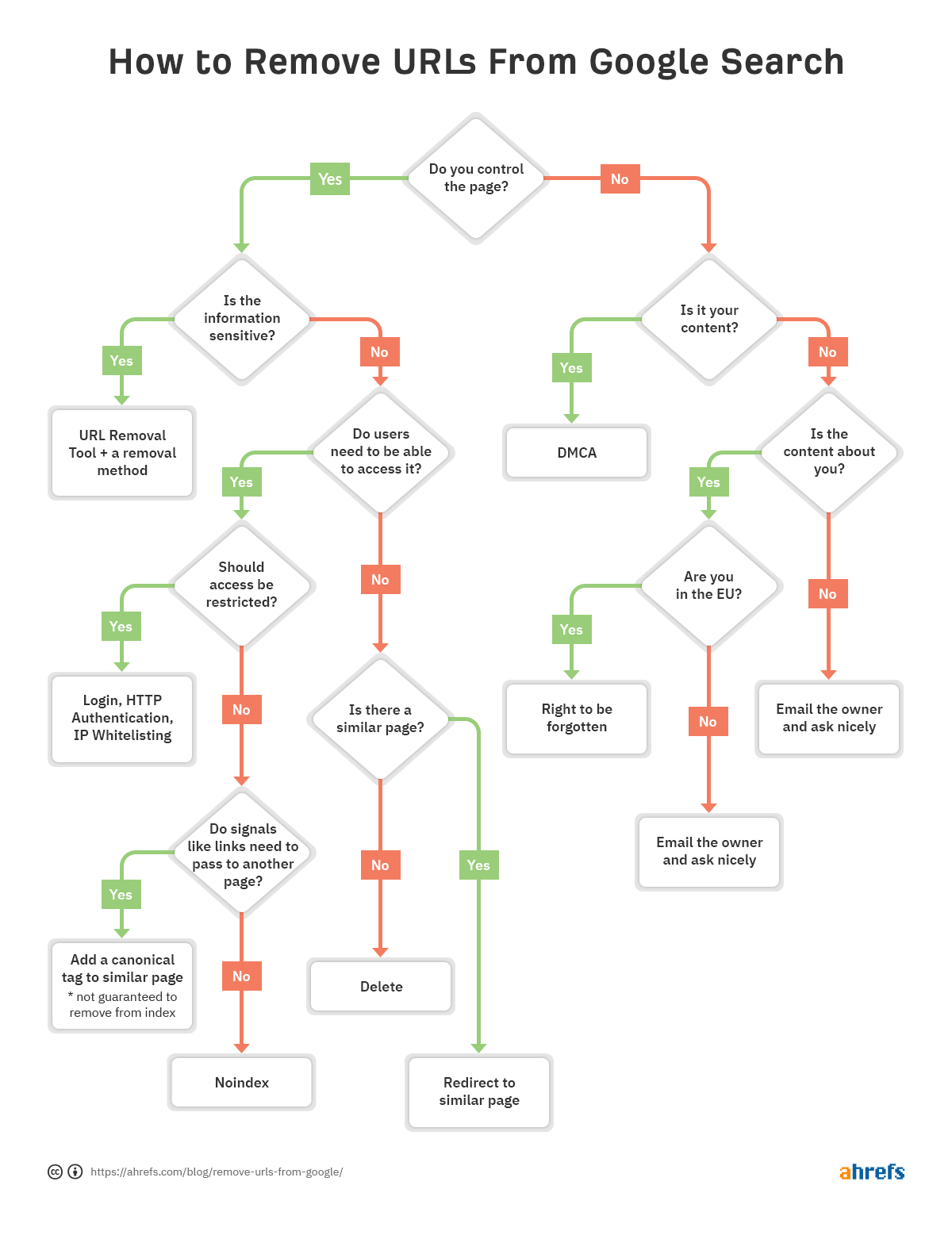
om u te helpen snel te beslissen welke methode van verwijdering het beste voor u is, hebben we een stroomdiagram gemaakt zodat u naar de relevante sectie van het artikel kunt overslaan.
In dit bericht, zult u leren:
- Hoe te controleren of een URL is geïndexeerd
- vijf manieren om URL ’s van Google te verwijderen
- Hoe prioriteit te geven aan verwijderingen
- veelvoorkomende verwijderingsfouten om
- te vermijden Hoe inhoud te verwijderen die niet op uw site staat
- Hoe afbeeldingen te verwijderen
wat ik meestal zie SEO’ s doen om te controleren of inhoud is geïndexeerd is een site gebruiken: zoeken in Google (bijv. site:https://ahrefs.com). While site: zoekopdrachten kunnen nuttig zijn voor het identificeren van de pagina ’s of secties van een website die problematisch kunnen zijn als ze worden weergegeven in de zoekresultaten, Je moet voorzichtig zijn, omdat ze niet normale query’ s en zal je eigenlijk niet vertellen of een pagina is geïndexeerd. Ze kunnen pagina ‘ s weergeven die bij Google bekend zijn, maar dat betekent niet dat ze in aanmerking komen om te laten zien in normale zoekresultaten zonder de site: operator.
bijvoorbeeld, site: zoekopdrachten kunnen nog steeds pagina ‘ s tonen die worden omgeleid of gecanoniseerd naar een andere pagina. Wanneer u om een specifieke site vraagt, kan Google een pagina van dat domein weergeven met de inhoud, titel en beschrijving van een ander domein. Neem bijvoorbeeld moz.com die vroeger seomoz.org. elke reguliere gebruiker queries die leiden naar pagina ‘ s op moz.com zal tonen moz.com in de SERPs, terwijl site:seomoz.org zal tonen seomoz.org in de zoekresultaten zoals hieronder weergegeven.
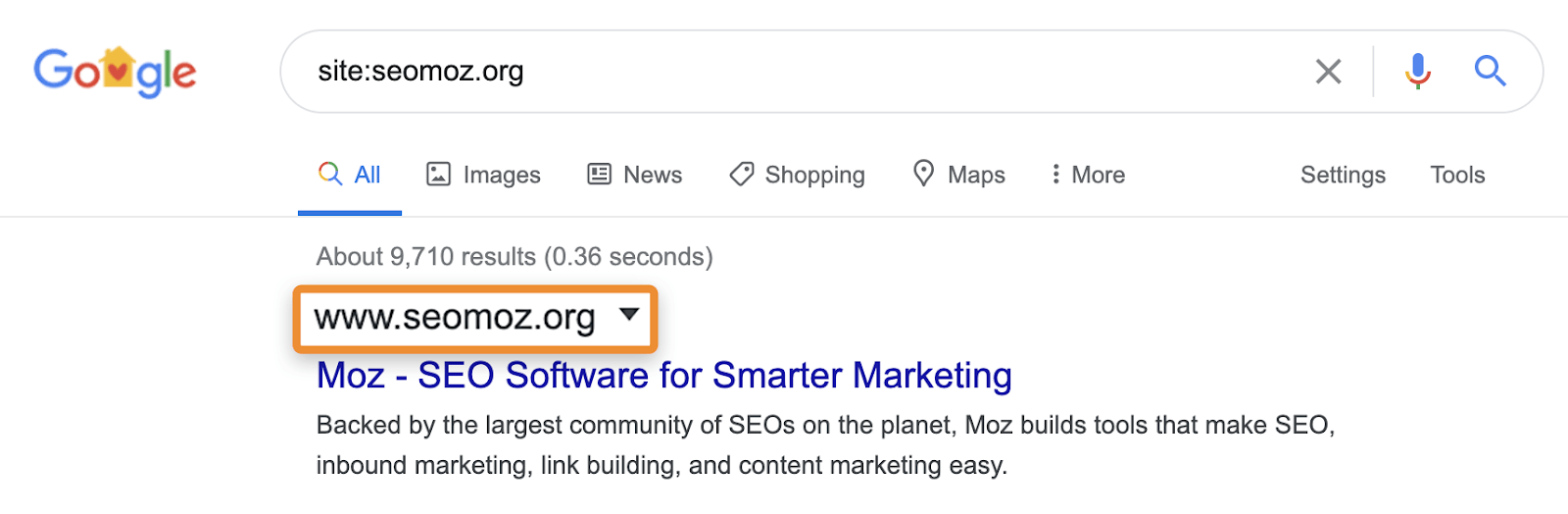
De reden dat dit een belangrijk onderscheid is, is dat het SEO ’s kan leiden tot fouten zoals het actief blokkeren of verwijderen van URL’ s uit de index voor het oude domein, wat consolidatie van signalen zoals PageRank voorkomt. Ik heb veel gevallen gezien met domein migraties waar mensen denken dat ze een fout gemaakt tijdens de migratie, omdat deze pagina ’s nog steeds te zien voor site:old-domain.com zoekopdrachten en uiteindelijk actief schade toebrengen aan hun website, terwijl het proberen om” fix ” het probleem.
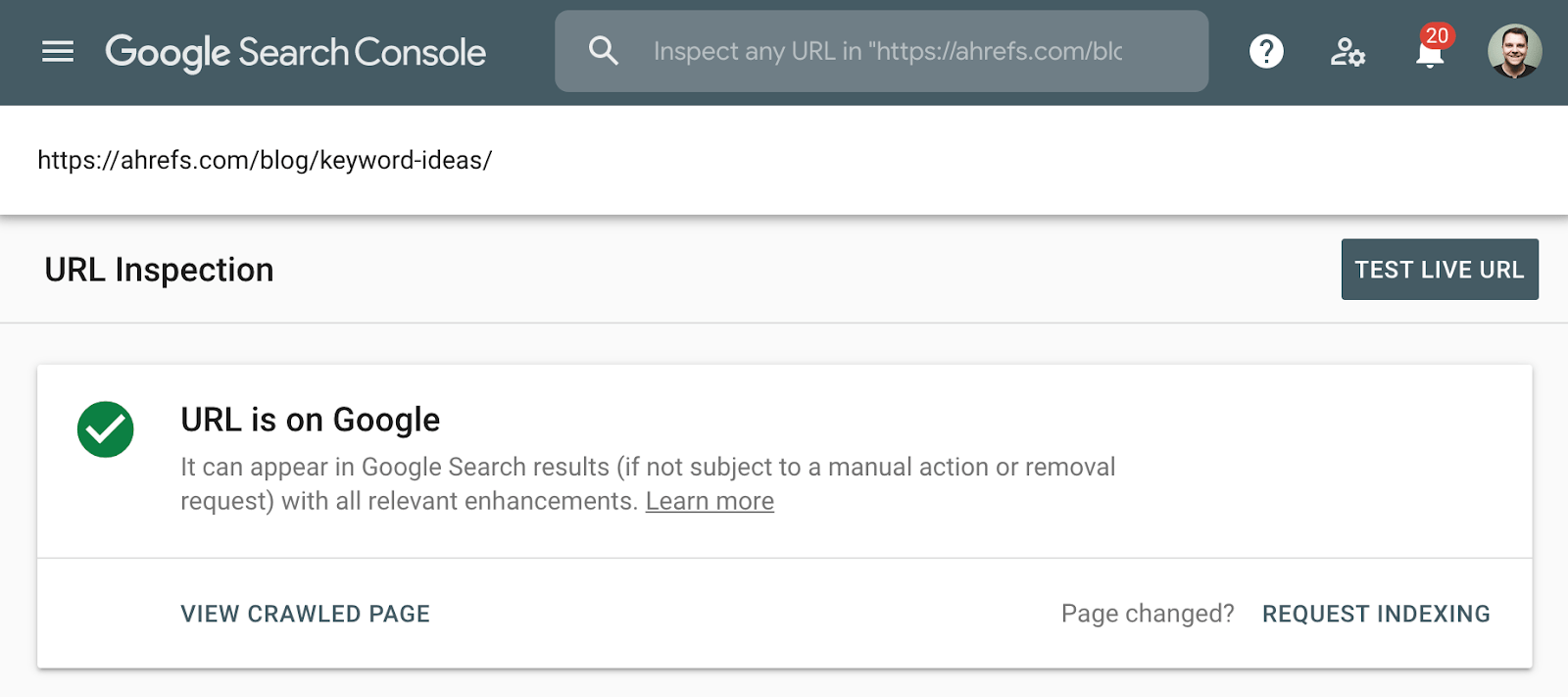
de betere methode om de indexering te controleren is het Index Coverage report te gebruiken in de Google Search Console, of het URL inspectie Tool voor een individuele URL. Deze tools vertellen u of een pagina is geïndexeerd en bieden aanvullende informatie over hoe Google de pagina behandelt. Als u geen toegang tot deze, gewoon zoeken Google voor de volledige URL van uw pagina.
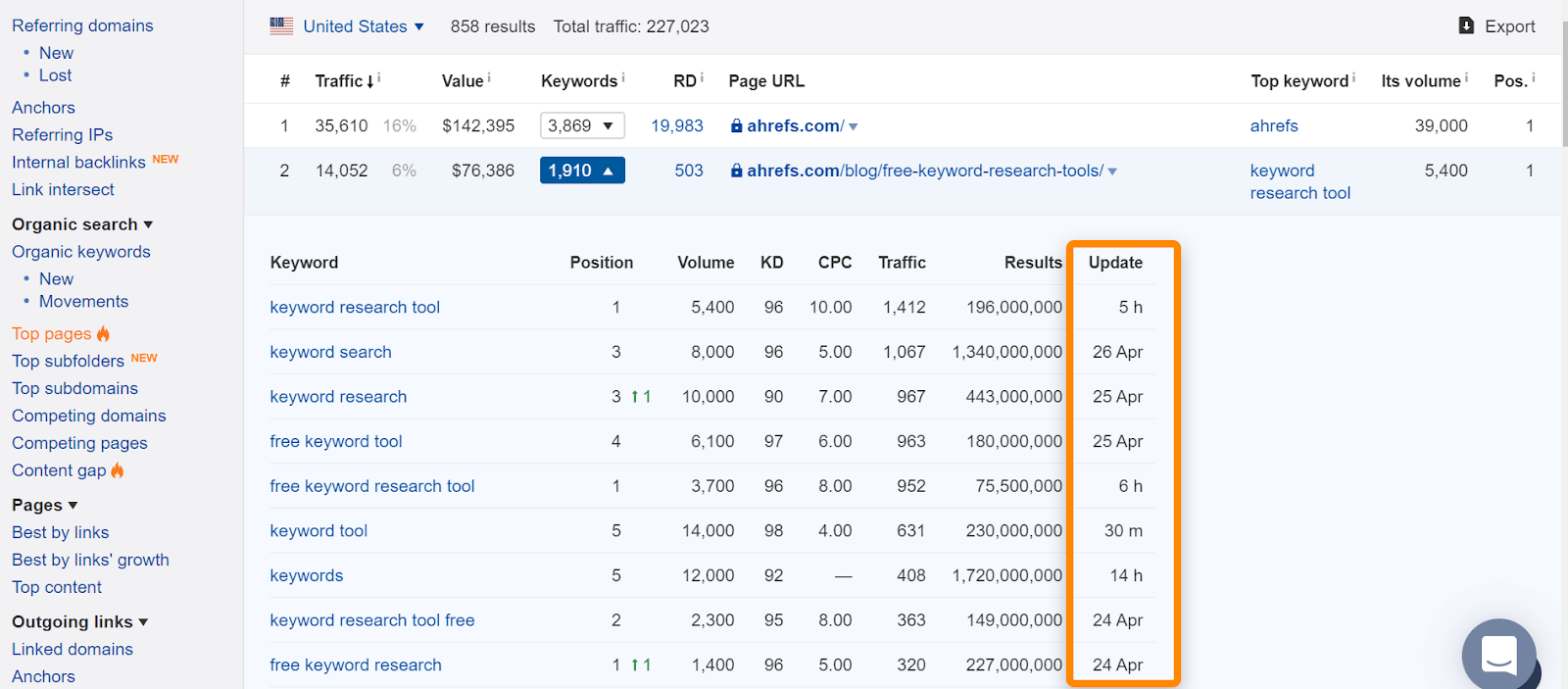
in Ahrefs, als u de pagina in onze” Top pages ” rapport of ranking voor organische zoekwoorden, het betekent meestal dat we zagen het ranking voor normale zoekopdrachten en is een goede indicatie dat de pagina werd geïndexeerd. Merk op dat de pagina ‘ s werden geïndexeerd toen we ze zagen, maar dat kan zijn veranderd. Controleer de datum waarop we de pagina voor het laatst zagen voor een zoekopdracht.
als er een probleem is met een bepaalde URL en het moet worden verwijderd uit de index, volg dan het stroomdiagram aan het begin van het artikel om de juiste verwijderingsoptie te vinden, ga dan naar de juiste sectie hieronder.
Als u de pagina verwijdert en een statuscode 404 (not found) of 410 (gone) gebruikt, wordt de pagina kort nadat de pagina opnieuw is gecrawld uit de index verwijderd. Totdat het wordt verwijderd, kan de pagina nog steeds worden weergegeven in de zoekresultaten. En zelfs als de pagina zelf niet meer beschikbaar is, kan een cacheversie van de pagina Tijdelijk beschikbaar zijn.
wanneer u een andere optie nodig heeft:
- ik heb meer onmiddellijke verwijdering nodig. Zie het gedeelte url removal tool.
- ik moet signalen zoals koppelingen consolideren. Zie de sectie canonicalisatie.
- ik heb de pagina nodig die beschikbaar is voor gebruikers. Kijk of de noindex of het beperken van toegang secties past bij uw situatie.
- verwijderingsoptie 2: Noindex
- verwijderingsoptie 3: toegang beperken
- Removal optie 4: URL Removal Tool
- verwijderingsoptie 5: Canonicalisatie
- Geenindex in robots.txt
- blokkeren van kruipen in robots.txt
- Nofollow
- Noindex en canonical naar een andere URL
- Noindex, wachten voor Google te kruipen, dan blokkeren crawlen
- wat als het inhoud over u betreft, maar niet op een site die u bezit?
- Final thoughts
verwijderingsoptie 2: Noindex
een noindex meta robots tag of X‑robots header antwoord zal zoekmachines vertellen om een pagina uit de index te verwijderen. De meta robots tag werkt voor pagina ’s waar de x-robots response werkt voor pagina’ s en extra bestandstypen zoals PDF ‘ s. Om deze tags te zien, moet een zoekmachine in staat zijn om de pagina ‘ s te crawlen—dus zorg ervoor dat ze niet worden geblokkeerd in robots.txt. Merk ook op dat het verwijderen van pagina ‘ s uit de index de consolidatie van link en andere signalen kan voorkomen.
voorbeeld van een meta robots noindex:
<meta name="robots" content="noindex">
voorbeeld van X‑robots noindex tag in the header response:
HTTP/1.1 200 OKX-Robots-Tag: noindex
wanneer u een andere optie nodig heeft:
- Ik wil niet dat gebruikers toegang krijgen tot deze pagina ‘ s. Zie het gedeelte toegang beperken.
- ik moet signalen zoals koppelingen consolideren. Zie de sectie canonicalisatie.
verwijderingsoptie 3: toegang beperken
Als u wilt dat de pagina toegankelijk is voor sommige gebruikers, maar niet voor zoekmachines, dan wilt u waarschijnlijk een van deze drie opties:
- Een soort aanmeldsysteem;
- HTTP-authenticatie (waar een wachtwoord vereist is voor toegang);
- IP-Whitelisting (waardoor alleen specifieke IP-adressen toegang krijgen tot de pagina ‘ s)
Dit type instelling is het beste voor dingen als interne netwerken, alleen voor leden, of voor staging -, test-of ontwikkelingssites. Het maakt het mogelijk voor een groep gebruikers om toegang te krijgen tot de pagina, maar zoekmachines zullen niet in staat zijn om toegang te krijgen tot hen en zal de pagina ‘ s niet indexeren.
wanneer u een andere optie nodig heeft:
- ik heb meer onmiddellijke verwijdering nodig. Zie het gedeelte url removal tool. In dit specifieke geval wilt u misschien meer onmiddellijke verwijdering als de inhoud die u probeert te verbergen in de cache is geplaatst en u moet voorkomen dat gebruikers die inhoud zien.
Removal optie 4: URL Removal Tool
De naam van deze tool van Google is enigszins misleidend omdat de manier waarop het werkt is dat het tijdelijk de inhoud zal verbergen. Google zal nog steeds zien en kruipen deze inhoud, maar de pagina ‘ s zullen niet verschijnen voor gebruikers. Dit tijdelijke effect duurt zes maanden in Google, terwijl Bing een soortgelijke tool heeft die drie maanden duurt. Deze tools moeten worden gebruikt in de meest extreme gevallen voor dingen zoals veiligheidsproblemen, datalekken, persoonlijk identificeerbare informatie (PII), enz. Voor Google, gebruik maken van de hulpprogramma ’s verwijderen en voor Bing, zie hoe u URL’ s te blokkeren.
u moet nog steeds een andere methode toepassen, samen met het verwijderhulpprogramma, om de pagina ‘ s voor een langere periode te verwijderen (geen index of verwijderen) of gebruikers te verhinderen toegang te krijgen tot de inhoud als ze nog steeds de links hebben (verwijderen of toegang beperken). Dit geeft je gewoon een snellere manier van het verbergen van de pagina ‘ s, terwijl de verwijdering tijd heeft om te verwerken. De aanvraag kan tot een dag duren om te verwerken.
verwijderingsoptie 5: Canonicalisatie
wanneer u meerdere versies van een pagina hebt en signalen zoals koppelingen naar een enkele versie wilt consolideren, wilt u een vorm van canonicalisatie doen. Dit is meestal om dubbele inhoud te voorkomen, terwijl het consolideren van meerdere versies van een pagina naar een enkele geïndexeerde URL.
u hebt verschillende canonicalisatieopties:
- Canonical tag. Dit specificeert een andere URL als de canonieke versie of de versie die u wilt weergeven. Als pagina ‘ s dupliceren of zeer vergelijkbaar zijn, moet dit prima zijn. Wanneer pagina ‘ s te verschillend zijn, kan het canonieke worden genegeerd omdat het een hint is en geen richtlijn.
- Redirects. Een redirect neemt een gebruiker en een zoekbot van de ene pagina naar de andere. 301 is de meest gebruikte redirect door SEOs, en het vertelt de zoekmachines dat u wilt dat de uiteindelijke URL wordt weergegeven in de zoekresultaten en waar signalen worden geconsolideerd. Een 302 of tijdelijke redirect vertelt zoekmachines u wilt dat de oorspronkelijke URL om te blijven in de index en om signalen daar te consolideren.
- URL parameter handling. Een parameter wordt toegevoegd aan het einde van de URL en bevat meestal een vraagteken, zoals ahrefs.com?this=parameter. deze tool van Google laat je hen vertellen hoe ze URL ‘ s met specifieke parameters moeten behandelen. U kunt bijvoorbeeld opgeven of de parameter de inhoud van de pagina verandert of dat het alleen bedoeld is om het gebruik bij te houden.
Als u meerdere pagina ‘ s uit de index van Google wilt verwijderen, moeten deze dienovereenkomstig worden geprioriteerd.
hoogste prioriteit: deze pagina ‘ s hebben meestal betrekking op beveiliging of op vertrouwelijke gegevens. Dit omvat inhoud die persoonsgegevens (PII), klantgegevens of bedrijfseigen informatie bevat.
Mediumprioriteit: dit betreft meestal inhoud die bedoeld is voor een specifieke groep gebruikers. Bedrijfsintranetten of medewerkersportals, content die alleen bedoeld is voor leden, en omgevingen voor staging, test of ontwikkeling.
lage prioriteit: deze pagina ‘ s hebben meestal een soort dubbele inhoud. Enkele voorbeelden hiervan zijn pagina ’s die vanuit meerdere URL’ s worden geserveerd, URL ‘ s met parameters, en opnieuw zouden staging -, test-of ontwikkelomgevingen kunnen bevatten.
Ik wil een paar van de manieren behandelen waarop verwijderingen meestal verkeerd worden uitgevoerd en wat er in elk scenario gebeurt om mensen te helpen begrijpen waarom ze niet werken.
Geenindex in robots.txt
terwijl Google onofficieel noindex in robots ondersteunde.txt, het was nooit een officiële standaard en ze hebben nu formeel verwijderd ondersteuning. Veel van de sites die dit deden, deden dit verkeerd en brachten zichzelf schade toe.
blokkeren van kruipen in robots.txt
kruipen is niet hetzelfde als indexeren. Zelfs als Google is geblokkeerd voor het crawlen van pagina ‘ s, als er interne of externe links naar een pagina kunnen ze nog steeds indexeren. Google zal niet weten wat er op de pagina, omdat ze niet zal crawlen, maar ze weten dat een pagina bestaat en zal zelfs een titel te laten zien in de zoekresultaten op basis van signalen zoals de anchor tekst van links naar de pagina te schrijven.
Nofollow
Dit wordt vaak verward met noindex, en sommige mensen zullen het op paginaniveau gebruiken in de verwachting dat de pagina niet wordt geïndexeerd. Nofollow is een hint, en hoewel het oorspronkelijk gestopt links op de pagina en individuele links met de Nofollow attribuut worden gekropen, dat is niet langer het geval. Google kan nu kruipen deze links als ze willen. Nofollow werd ook gebruikt op individuele links om te proberen te voorkomen dat Google door zou kruipen naar specifieke pagina ‘ s en voor pagerank beeldhouwen. Nogmaals, dit werkt niet meer omdat nofollow een hint is. In het verleden, als de pagina had een andere link naar het, dan Google kon nog steeds ontdekken van deze alternatieve crawl pad.
merk op dat u nofollowed pagina’ s in bulk kunt vinden met behulp van dit filter in de pagina Verkenner in Ahrefs ‘ Site Audit.
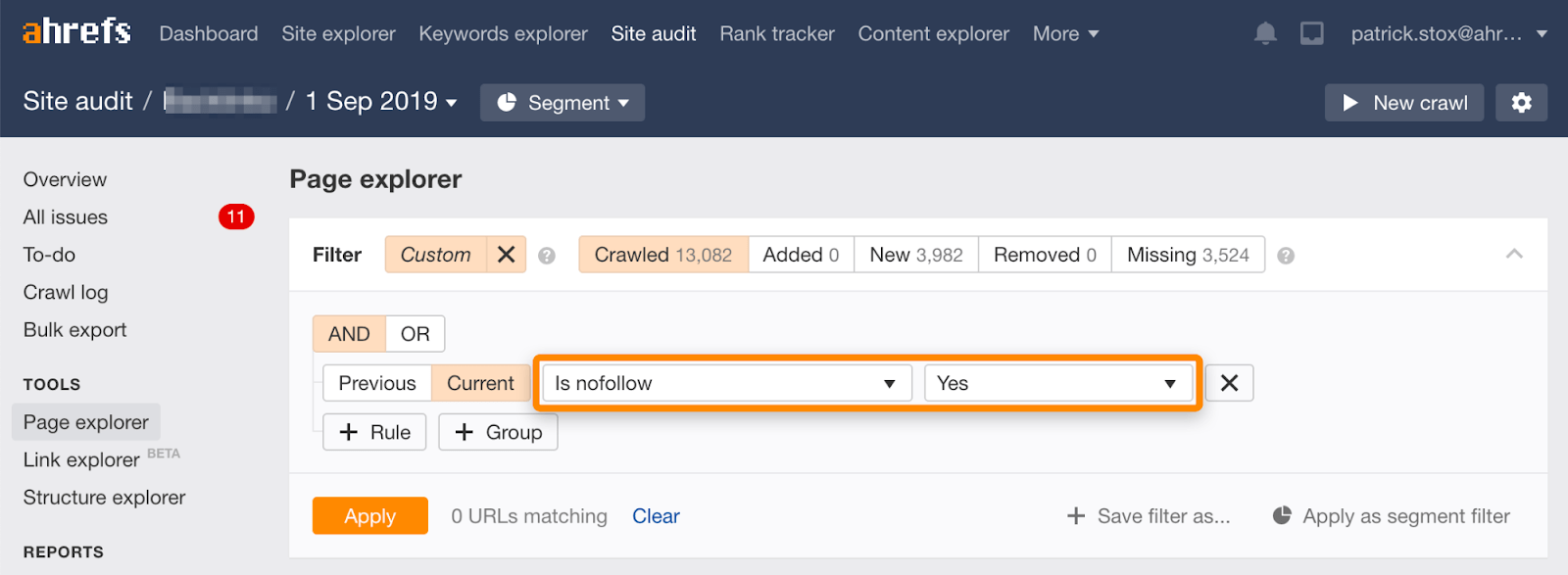
omdat het zelden zinvol is om alle links op een pagina te volgen, moet het aantal resultaten nul of dicht bij nul zijn. Als er overeenkomstige resultaten zijn, verzoek ik u om te controleren of de nofollow-richtlijn per ongeluk is toegevoegd in plaats van noindex en om een meer geschikte methode van verwijdering te kiezen indien nodig.
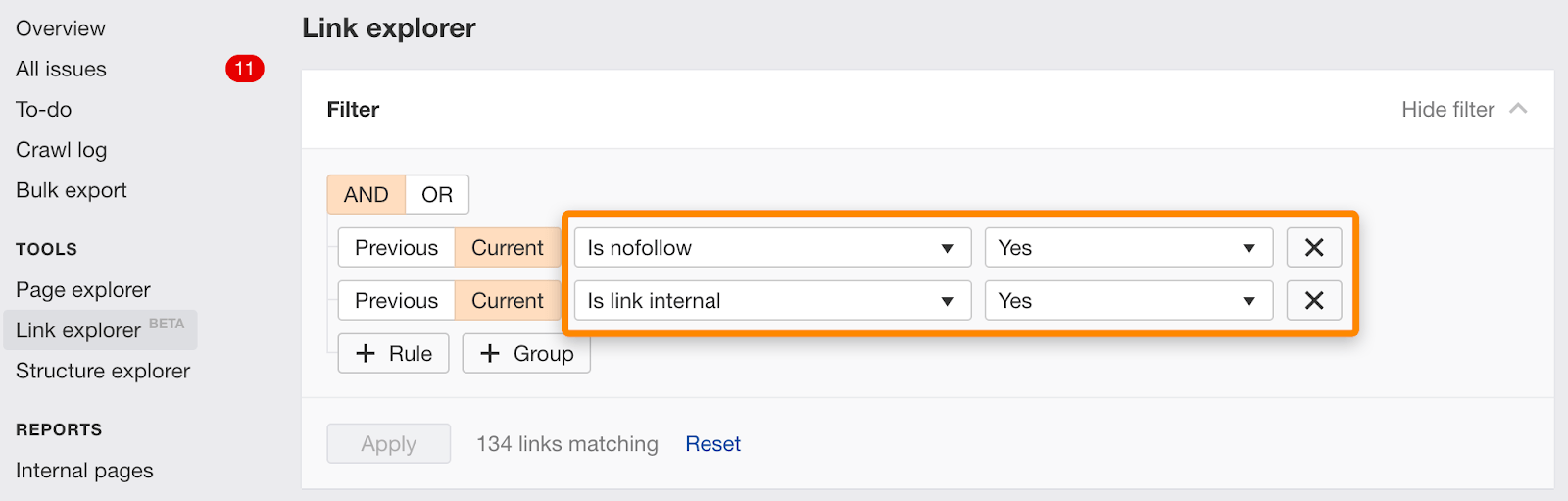
u kunt ook afzonderlijke links met nofollow vinden met behulp van dit filter in Link Explorer.
Noindex en canonical naar een andere URL
deze signalen zijn tegenstrijdig. Noindex zegt om de pagina uit de index te verwijderen, en canonical zegt dat een andere pagina is de versie die moet worden geïndexeerd. Dit kan eigenlijk werken voor consolidatie als Google zal meestal ervoor kiezen om de noindex negeren en in plaats daarvan gebruik maken van de canonieke als het belangrijkste signaal. Dit is echter geen absoluut gedrag. Er is een algoritme bij betrokken en er is een risico dat de noindex tag het signaal kan zijn. Als dat het geval is, dan zullen pagina ‘ s niet goed te consolideren.
Opmerking die u kunt vinden noindexed pagina ‘ s met niet-zelf-referentiële gewaad met behulp van deze set van filters in de Pagina Explorer op de Site Audit:
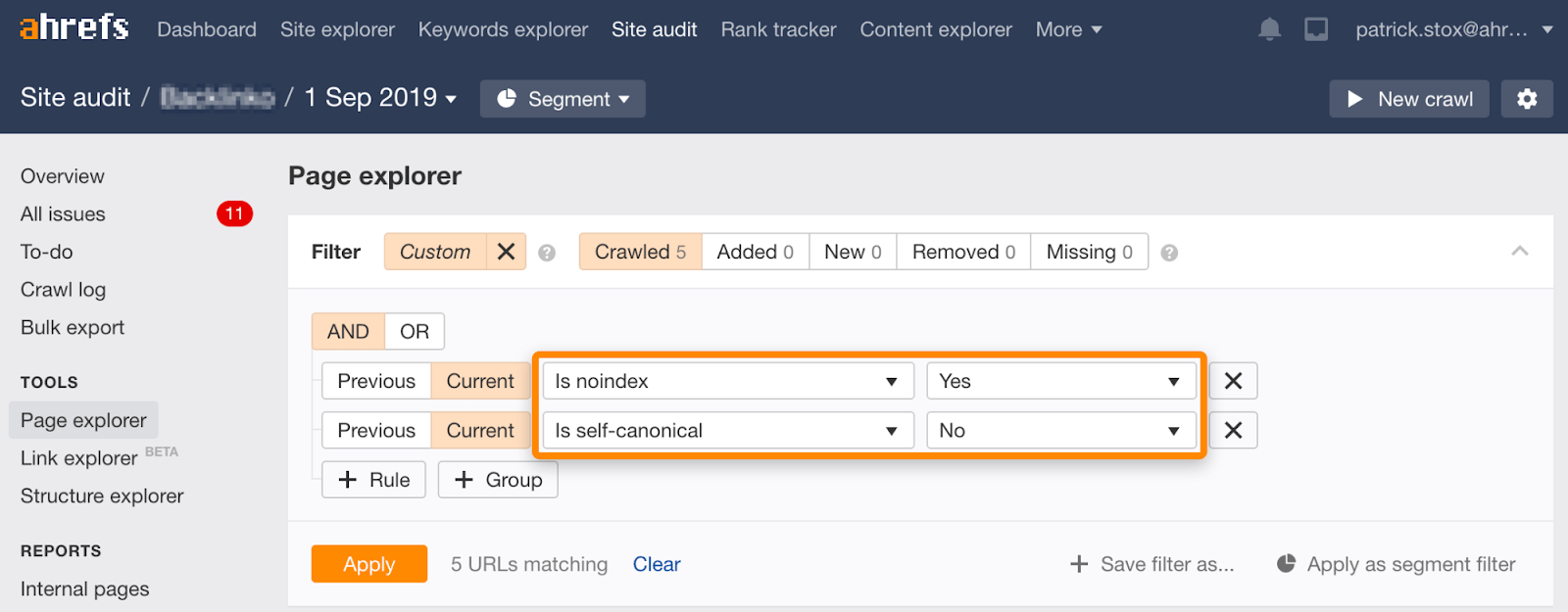
Noindex, wachten voor Google te kruipen, dan blokkeren crawlen
Er zijn een paar van de manieren waarop dit gebeurt meestal:
- Pagina ’s zijn al geblokkeerd, maar zijn geïndexeerd, mensen toevoegen noindex en deblokkeren, zodat Google kan kruipen en de’ noindex, dan blokkeren de pagina ‘ s crawlen weer.
- mensen voegen noindex-tags toe voor de pagina ’s die ze willen verwijderen en nadat Google de noindex-tag heeft gekropen en verwerkt, blokkeren ze het crawlen van de pagina’ s.
hoe dan ook, de uiteindelijke status is geblokkeerd voor het crawlen. Als je je herinnert, eerder, hebben we gesproken over hoe kruipen niet hetzelfde is als indexeren. Ook al zijn deze pagina ‘ s Geblokkeerd, ze kunnen nog steeds in de index terecht komen.
Als u eigenaar bent van de inhoud die wordt gebruikt op een andere website, kunt u mogelijk een claim indienen op basis van de Digital Millennium Copyright Act (DMCA). U kunt gebruik maken van Google ‘ s Copyright Removal tool om te doen wat wordt genoemd een DMCA takedown, die vraagt om de verwijdering van auteursrechtelijk beschermd materiaal.
wat als het inhoud over u betreft, maar niet op een site die u bezit?
Als u zich in de EU bevindt, kunt u inhoud die informatie over u bevat laten verwijderen dankzij een gerechtelijk bevel voor het recht om te worden vergeten. U kunt verzoeken om persoonlijke informatie te laten verwijderen via het EU-Privacyverwijderingsformulier.
om afbeeldingen van Google te verwijderen, is de makkelijkste manier met robots.txt. Terwijl de onofficiële ondersteuning voor het verwijderen van pagina ‘ s werd verwijderd uit robots.txt zoals we eerder vermeld, gewoon het verbieden van de crawl van afbeeldingen is de juiste manier om afbeeldingen te verwijderen.
voor een enkele afbeelding:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
voor alle afbeeldingen:
User-agent: Googlebot-ImageDisallow: /
Final thoughts
hoe u URL ‘ s verwijdert is vrij situationeel. We hebben het gehad over verschillende opties, maar als je nog steeds in de war bent wat voor jou het beste is, ga dan terug naar het stroomdiagram aan het begin.
u kunt ook de juridische probleemoplosser van Google doorlopen voor het verwijderen van inhoud.
heeft u vragen? Laat het me weten op Twitter.