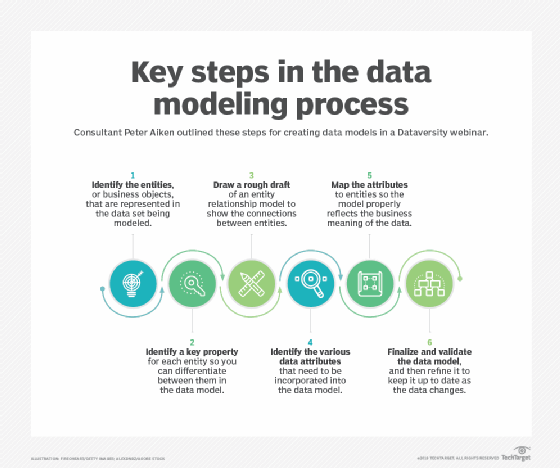
Data modeling is het proces van het documenteren van een complex software systeemontwerp als een gemakkelijk te begrijpen diagram, met behulp van tekst en symbolen om de manier waarop gegevens moeten stromen weer te geven. Het diagram kan worden gebruikt om een efficiënt gebruik van gegevens te garanderen, als blauwdruk voor de bouw van nieuwe software of voor het opnieuw ontwerpen van een oude applicatie.
datamodellering is een belangrijke vaardigheid voor datawetenschappers of anderen die betrokken zijn bij data-analyse. Traditioneel zijn datamodellen Gebouwd tijdens de analyse-en ontwerpfase van een project om ervoor te zorgen dat de vereisten voor een nieuwe toepassing volledig worden begrepen. De gegevensmodellen kunnen ook later in de gegevenslevenscyclus worden opgeroepen om gegevensontwerpen te rationaliseren die oorspronkelijk door programmeurs op ad hoc basis werden gemaakt.
Datamodelleringsbenaderingen
datamodellering kan een nauwgezet upfront proces zijn en wordt als zodanig soms gezien als strijdig met snelle ontwikkelingsmethoden. Aangezien Agile programmering in breder gebruik is gekomen om ontwikkelingsprojecten te versnellen, worden na-the-fact methoden van datamodellering in sommige gevallen aangepast. Typisch, kan een gegevensmodel worden gezien als een stroomdiagram dat de relaties tussen gegevens illustreert. Het stelt stakeholders in staat om fouten te identificeren en wijzigingen aan te brengen voordat een programmeercode is geschreven. Als alternatief kunnen modellen worden geïntroduceerd als onderdeel van reverse engineering-inspanningen die modellen uit bestaande systemen halen, zoals te zien is met NoSQL-gegevens.
gegevensmodellen gebruiken vaak meerdere modellen om dezelfde gegevens te bekijken en ervoor te zorgen dat alle processen, entiteiten, relaties en gegevensstromen zijn geïdentificeerd. Zij initiëren nieuwe projecten door eisen van belanghebbenden uit het bedrijfsleven te verzamelen. Data modellering fasen grofweg onderverdeeld in de creatie van logische data modellen die specifieke kenmerken, entiteiten en relaties tussen entiteiten en de fysieke data model tonen.
het logische datamodel dient als basis voor de creatie van een fysiek datamodel, dat specifiek is voor de te implementeren toepassing en database. Een datamodel kan de basis worden voor het opstellen van een gedetailleerder dataschema.
hiërarchische datamodellering
datamodellering als discipline begon zich in de jaren zestig voor te doen, bij de opleving van het gebruik van databasemanagementsystemen (dbmses). Datamodellering stelde organisaties in staat om consistentie, herhaalbaarheid en goed geordende ontwikkeling van gegevensverwerking te brengen. Application eindgebruikers en programmeurs konden het datamodel gebruiken als referentie in de communicatie met data-ontwerpers.
hiërarchische datamodellen die gegevens array in boomachtige, één-op-vele arrangementen markeerden deze vroege inspanningen en vervingen bestand-gebaseerde systemen in veel populaire use cases. IBM ‘ s Information Management System (IMS) is een primair voorbeeld van de hiërarchische aanpak, die veel gebruikt werd in bedrijven, vooral in het bankwezen. Hoewel hiërarchische datamodellen grotendeels werden vervangen-vanaf de jaren 1980-door relationele datamodellen, is de hiërarchische methode nog steeds gebruikelijk in XML (Extensible Markup Language) en geografische informatiesystemen (GISes) vandaag. Netwerkdatamodellen ontstonden ook in de begindagen van DBMSes als middel om data-ontwerpers een breed conceptueel beeld van hun systemen te geven. Een voorbeeld hiervan is de Conference on Data Systems Languages (CODASYL), die eind jaren vijftig werd opgericht om de ontwikkeling van een standaard programmeertaal te begeleiden die op verschillende typen computers kan worden gebruikt.
relationele gegevensmodellering
hoewel het de complexiteit van het programma ten opzichte van bestandgebaseerde systemen verminderde, vereiste het hiërarchische model nog steeds een gedetailleerd inzicht in de specifieke fysieke gegevensopslag die wordt gebruikt. Voorgesteld als een alternatief voor het hiërarchische datamodel, vereist het relationele datamodel niet dat ontwikkelaars gegevenspaden definiëren. Relationele data modeling werd voor het eerst beschreven in een 1970 technische paper door IBM onderzoeker E. F. Codd. Het relationele model van Codd vormde de basis voor het industriële gebruik van relationele databases waarin gegevenssegmenten expliciet worden samengevoegd door gebruik van tabellen, in vergelijking met het hiërarchische model waarin gegevens impliciet worden samengevoegd. Al snel na de oprichting werd het relationele datamodel gekoppeld aan de Structured Query Language (SQL) en begon een steeds grotere voet aan de grond te krijgen in enterprise computing als een efficiënt middel om gegevens te verwerken.
het entity relationship model
relationele datamodellering nam vanaf het midden van de jaren zeventig een nieuwe stap voorwaarts, omdat het gebruik van entity relationship (ER) modellen steeds vaker voorkwam. Nauw geà ntegreerd met relationele datamodellen, ER-modellen gebruiken diagrammen om de elementen in een database grafisch weer te geven en om het begrip van onderliggende modellen te vergemakkelijken.
bij relationele modellering worden gegevenstypen bepaald en zelden in de loop van de tijd gewijzigd. Entiteiten omvatten attributen; bijvoorbeeld, attributen van een werknemer entiteit kan omvatten achternaam, voornaam, jaren werkzaam, enzovoort. Relaties worden visueel in kaart gebracht, het verstrekken van een klaar middel om data design doelstellingen te communiceren aan verschillende deelnemers in data-ontwikkeling en onderhoud. Na verloop van tijd werden modelleringstools, waaronder Idera ‘ s ER/Studio, ERwin Data Modeler en SAP PowerDesigner, veel gebruikt bij data architects voor het ontwerpen van systemen.
toen objectgeoriënteerd programmeren terrein won in de jaren 1990, kreeg objectgeoriënteerde modellering tractie als een andere manier om systemen te ontwerpen. Hoewel objectgeoriënteerde benaderingen enige gelijkenis vertonen met ER-methoden, verschillen ze in het feit dat ze zich richten op objectabstracties van reële entiteiten. Objecten worden gegroepeerd in klassenhiërarchieën, en de objecten binnen dergelijke klassenhiërarchieën kunnen attributen en methoden van bovenliggende klassen erven. Vanwege deze erfelijke eigenschap hebben objectgeoriënteerde datamodellen enkele voordelen ten opzichte van ER-modellering, in termen van het waarborgen van gegevensintegriteit en het ondersteunen van meer complexe datarelaties. Ook ontstaan in de jaren 1990 waren datamodellen specifiek gericht op data warehousing behoeften. Opmerkelijke voorbeelden zijn Sneeuwvlok schema en ster schema dimensionale modellen.
Graph data Modelling
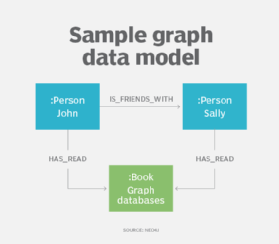
een uitloper van hiërarchische en netwerk data modellering is het property graph model, dat, samen met graph databases, meer gebruik heeft gevonden voor het beschrijven van complexe relaties binnen datasets, met name in sociale media, aanbevelingen en fraude detectie toepassingen.
met behulp van het graph data model beschrijven ontwerpers hun systeem als een verbonden grafiek van knooppunten en relaties, net zoals ze zouden kunnen doen met ER of object data modellering. Grafiekgegevensmodellen kunnen worden gebruikt voor tekstanalyse, waarbij modellen worden gemaakt die relaties tussen gegevenspunten in documenten blootleggen.