de structuur van DNA biedt een mechanisme voor erfelijkheid
genen dragen biologische informatie die nauwkeurig moet worden gekopieerd voor transmissie naar de volgende generatie telkens wanneer een cel zich verdeelt om twee dochtercellen te vormen. Uit deze vereisten komen twee centrale biologische vragen naar voren: hoe kan de informatie voor de specificatie van een organisme in chemische vorm worden vervoerd en hoe wordt deze nauwkeurig gekopieerd? De ontdekking van de structuur van de dubbele helix van DNA was een mijlpaal in de biologie van de twintigste eeuw omdat het onmiddellijk antwoorden op beide vragen voorstelde, waardoor het probleem van erfelijkheid op moleculair niveau werd opgelost. In dit hoofdstuk bespreken wij de antwoorden op deze vragen in het kort en in de volgende hoofdstukken zullen wij ze nader bestuderen.
DNA codeert informatie via de volgorde of sequentie van de nucleotiden langs elke streng. Elke base-A, C, T, of G-kan worden beschouwd als een letter in een vier-letter alfabet dat biologische boodschappen in de chemische structuur van het DNA spelt. Zoals we in Hoofdstuk 1 zagen, verschillen organismen van elkaar omdat hun respectievelijke DNA-moleculen verschillende nucleotidesequenties hebben en bijgevolg verschillende biologische boodschappen dragen. Maar hoe wordt het nucleotide-alfabet gebruikt om berichten te maken, en wat spellen ze?
zoals hierboven besproken, was het goed bekend voordat de structuur van DNA werd bepaald dat genen de instructies voor het produceren van eiwitten bevatten. De DNA berichten moeten daarom op de een of andere manier eiwitten coderen (figuur 4-6). Deze relatie Maakt het probleem onmiddellijk gemakkelijker te begrijpen, vanwege het chemische karakter van eiwitten. Zoals besproken in hoofdstuk 3, worden de eigenschappen van een eiwit, die verantwoordelijk zijn voor zijn biologische functie, bepaald door zijn driedimensionale structuur, en zijn structuur wordt op zijn beurt bepaald door de lineaire volgorde van de aminozuren waaruit het is samengesteld. De lineaire opeenvolging van nucleotiden in een gen moet daarom op de een of andere manier de lineaire opeenvolging van aminozuren in een proteã ne beschrijven. De exacte overeenstemming tussen het vierletterige nucleotidealabet van DNA en het twintig-letterige aminozuuralabet van proteã nen—de genetische code—is niet duidelijk van de structuur van DNA, en het duurde meer dan een decennium na de ontdekking van de dubbele helix voordat het werd uitgewerkt. In hoofdstuk 6 beschrijven we deze code in detail in de loop van het uitwerken van het proces, bekend als genexpressie, waardoor een cel de nucleotidesequentie van een gen vertaalt in de aminozuursequentie van een eiwit.

figuur 4-6
de relatie tussen genetische informatie die in DNA en eiwitten wordt overgedragen.
de volledige set informatie in het DNA van een organisme wordt het genoom genoemd, en het bevat de informatie voor alle eiwitten die het organisme ooit zal synthetiseren. (De term genoom wordt ook gebruikt om DNA te beschrijven dat deze informatie draagt.) De hoeveelheid informatie in genomen is onthutsend: bijvoorbeeld, een typische menselijke cel bevat 2 meter DNA. Geschreven in het vier-letterige nucleotide alfabet, de nucleotide sequentie van een zeer klein menselijk gen beslaat een kwart van een pagina tekst (figuur 4-7), terwijl de volledige sequentie van nucleotiden in het menselijk genoom zou vullen meer dan duizend boeken de grootte van deze. Naast andere kritieke informatie, draagt het de instructies voor ongeveer 30.000 verschillende proteã nen.

figuur 4-7
de nucleotidesequentie van het humane β-globinegen. Dit gen draagt de informatie voor de aminozuurvolgorde van één van de twee soorten subeenheden van het hemoglobinemolecuul, dat zuurstof in het bloed vervoert. Een ander gen, de α-globine (meer…)
bij elke celdeling moet de cel zijn genoom kopiëren om het door te geven aan beide dochtercellen. De ontdekking van de structuur van DNA onthulde ook het principe dat dit kopiëren mogelijk maakt: omdat elke bundel van DNA een opeenvolging van nucleotiden bevat die precies aan de nucleotideopeenvolging van zijn partner bundel complementair is, kan elke bundel als malplaatje, of vorm, voor de synthese van een nieuwe bijkomende bundel dienst doen. Met andere woorden, als we de twee DNA-strengen aanwijzen als S en S’, kan streng S dienen als een sjabloon voor het maken van een nieuwe streng S’, terwijl streng S’ kan dienen als een sjabloon voor het maken van een nieuwe streng S (Figuur 4-8). Zo kan de genetische informatie in het DNA nauwkeurig worden gekopieerd door het prachtig eenvoudige proces waarin streng S scheidt van streng S’, en elke gescheiden streng dient dan als een sjabloon voor de productie van een nieuwe complementaire partnerstreng die identiek is aan zijn vroegere partner.
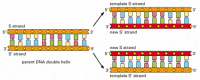
figuur 4-8
DNA als een sjabloon voor zijn eigen duplicatie. Aangezien nucleotide A met succes slechts met T, en G met C paren, kan elke bundel van DNA de opeenvolging van nucleotiden in zijn bijkomende bundel specificeren. Op deze manier kan dubbel spiraalvormig DNA exact worden gekopieerd. (meer…)
het vermogen van elke streng van een DNA-molecuul om te fungeren als een sjabloon voor het produceren van een complementaire streng stelt een cel in staat om zijn genen te kopiëren of te repliceren voordat deze aan zijn nakomelingen worden doorgegeven. In het volgende hoofdstuk beschrijven we de elegante machines die de cel gebruikt om deze enorme taak uit te voeren.