마이크로 프로세서라고도하는 CPU 는 컴퓨터의 심장 및/또는 뇌입니다. 컴퓨터의 핵심에 깊은 다이빙과 우리가 효율적으로 컴퓨터 프로그램을 작성하는 데 도움이됩니다 어떻게 CPU 작업을 이해할 수 있습니다.기계가 동물이나 증기 동력에 의해 자주 움직이는 동안 일반적으로 손으로 사용하는 것이 좋습니다.
–Charles Babbage
컴퓨터 시스템 구동에 의해 대부분 전기이지만 유연성과 프로그래밍을 도왔다 달성하는 단순한 도구입니다.
CPU 는 컴퓨터의 심장 및/또는 뇌입니다. 그것은 그들에게 제공되는 지침을 실행합니다. 주요 작업은 산술 및 논리 연산을 수행하고 지침을 함께 조율하는 것입니다. 하기 전에 다이빙으로 주요 부분을 시작하자에 의해 무엇을 찾고 있는 주요 구성 요소의 CPU 그 역할은 무엇인:
두 가지 주요 구성 요소의 CPU(프로세서)
- 제어 장치—CU
- 산술 및 논리 단위—ALU
제어 장치—CU
제어 장치 CU 의 일부입니다 CPU 는 데 도움이 조정 실행을 기다리게 하지 않는다. 그것은 무엇을해야하는지 알려줍니다. 지시에 따르면,그것은 ALU 를 포함하여 컴퓨터의 다른 다른 부분에 CPU 를 연결하는 전선을 활성화하는 데 도움이됩니다. 제어 유닛은 처리 명령을 수신하는 CPU 의 첫 번째 구성 요소입니다.
제어 장치에는 두 가지 유형이 있습니다.
- 하드 와이어드 제어 장치.
- 마이크로 풀그릴(microprogrammed)통제 단위.
Hardwired 통제 단위는 하드웨어 및 필요한 변경 하드웨어에서 추가 수정 작동하면 마이크로 프로그래밍이 가능한 제어 장치될 수 있는 프로그램을 변경하는 동작입니다. Hardwired CU 는 처리 명령에서 더 빠른 반면 마이크로 프로그래밍은 더 유연합니다.
산술 및 논리 단위—ALU
산술 및 논리 단위 ALU 이름처럼 모든 산술 및 논리 연산. ALU 는 덧셈,뺄셈과 같은 연산을 수행합니다. ALU 는 이러한 작업을 수행하는 논리 회로 또는 논리 게이트로 구성됩니다.
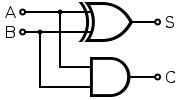
대부분의 논리 게이트에서 두 개의 입력 및 생산 중 하나로 출력
아래의 예를 반기는 회로에서는 두 개의 입력과 출력의 결과입니다. 여기서 A 와 B 는 입력,S 는 출력 및 C 는 캐리입니다.
스토리지 레지스터 및 메모리
CPU 의 주요 작업은 제공된 명령어를 실행하는 것입니다. 이러한 지침을 대부분의 시간에 처리하려면 데이터가 필요합니다. 일부 데이터는 중간 데이터이며 그 중 일부는 입력이고 다른 데이터는 출력입니다. 이러한 데이터와 함께 지침에 저장되어 다음과 같은 저장소:
등록
등록 작은 설정하는 곳에 데이터를 저장할 수 있습니다. 레지스터는 래치의 조합입니다. 플립 플롭이라고도하는 래치는 1 비트의 정보를 저장하는 로직 게이트의 조합입니다.
래치에는 두 개의 입력 와이어,쓰기 및 입력 와이어와 하나의 출력 와이어가 있습니다. 쓰기 와이어를 활성화하여 저장된 데이터를 변경할 수 있습니다. 쓰기 와이어가 비활성화되면 출력은 항상 동일하게 유지됩니다.
CPU 는 레지스터 데이터를 저장하기 위해 출력합니다. 메인 메모리(RAM)로 보내는 것은 중간 데이터이기 때문에 느려질 것입니다. 이 데이터는 버스로 연결된 다른 레지스터로 전송됩니다. 레지스터는 명령어,출력 데이터,저장 주소 또는 모든 종류의 데이터를 저장할 수 있습니다.
메모리(RAM)
Ram 의 모음 등록 배열 및 소형에서 함께 최적화된 방법으로 저장할 수 있도록 높은 수의 데이터입니다. RAM(랜덤 액세스 메모리)은 휘발성이며 전원을 끌 때 데이터가 손실됩니다. 라 램의 컬렉션을 레지스터를 읽기/쓰기 데이터를 RAM 입력의 8 비트 주소,데이터 입력을 위해 실제 데이터가 저장되고 마지막으로 읽고 쓰는 인에이블러는 작품으로 그것이 래치.
명령어 란 무엇입니까
명령어는 컴퓨터가 수행 할 수있는 세분화 된 레벨 계산입니다. CPU 가 처리 할 수있는 다양한 유형의 명령이 있습니다.
지침은 다음과 같습니다:
- 산술 등 더하기 및 빼기
- 로직 지침과 같고,또는지
- 데이터한 사항은로 이동,입력,출력,부하 및 store
- 제어 흐름 지침과 같은 고토,if…goto, 전화 및 반환
- 알 CPU 는 프로그램을 종료 Halt
지침을 제공하는 컴퓨터를 사용하여 어셈블리 언어 또는 의해 생성되는 컴파일러 또는 해석서는 수준 높은 언어입니다.
이 명령어는 CPU 내부에 하드 와이어되어 있습니다. 제어 흐름은 CU 에 의해 관리되는 반면 ALU 는 산술 및 논리를 포함합니다.
하나의 클럭 사이클에서 컴퓨터는 하나의 명령을 수행 할 수 있지만 최신 컴퓨터는 둘 이상을 수행 할 수 있습니다.
컴퓨터가 수행할 수 있는 명령어 그룹을 명령어 세트라고 합니다.
CPU 클럭
클록 사이클
컴퓨터의 속도는 클록 사이클에 의해 결정됩니다. 그것은 컴퓨터가 작동하는 초당 클럭 기간의 수입니다. 단일 클럭 사이클은 주변과 같이 매우 작습니다 250 * 10 *-12 초.클럭 사이클이 높을수록 프로세서가 더 빠릅니다.
CPU 클럭 사이클은 GHz(기가 헤르츠)단위로 측정됩니다. 1gHz 는 10⁹Hz(헤르츠)와 같습니다. 헤르츠는 두 번째를 의미합니다. 따라서 1Gigahertz 는 초당 10⁹사이클을 의미합니다.
클럭 사이클이 빠를수록 CPU 가 실행할 수있는 명령어가 많아집니다. 클럭 주기=1/클럭 속도의 CPU 시간=숫자의 클럭 사이클 시계 평가
이것을 개선하는 것을 의미합니다 CPU 시간을 증가시킬 수 있습계 평가 또는 감소의 번호를 클럭 사이클을 최적화하여 명령을 우리에게 제공하 CPU. 일부 프로세서를 제공합을 증가시킬 수있는 능력 클럭 사이클 이후하지만 그것은 육체적인 변경이 있는 과열도 담배/가 발생합니다.
명령어는 어떻게 실행됩니까
명령어는 순차적 인 순서로 RAM 에 저장됩니다. 가상 CPU 의 경우 명령어는 연산 코드(연산 코드)와 메모리 또는 레지스터 주소로 구성됩니다.
두 레지스터 내부에는 제어 장치 교육 등록(IR)로드하는 OP 코드의 명령과 지시 주소를 등록드의 주소는 현재 실행하는 명령입니다. 명령어의 마지막 4 비트의 주소에 저장된 값을 저장하는 CPU 내부에는 다른 레지스터가 있습니다.
두 개의 숫자를 추가하는 일련의 명령어의 예를 들어 보겠습니다. 다음은 설명과 함께 지침입니다. CPU 작품을 실행하는 다음과 같은 명령:
1 단계—LOAD_A8:
명령이 RAM 에 저장되어 처음으로 말하자<>. 처음 4 비트는 연산 코드입니다. 이것은 지시를 결정합니다. 이 명령어는 제어 장치의 IR 로 가져옵니다. 명령어 디코딩하 load_A 을 의미하는 데 필요한 데이터 주소 1000 는 지난 4 비트의 명령을 등록하 A.
2 단계—LOAD_B2
유사한 위의 이중 데이터에서는 메모리 주소 2(0010)CPU register B.
3 단계—추가 B
이제 다음 명령을 추가 이러한 두 개의 숫자입니다. 여기서 CU 는 alu 에게 add 작업을 수행하고 결과를 register A 에 다시 저장하도록 지시합니다.
4 단계—STORE_A23
이것은 매우 간단한 설정 지시의 도움을 추가 두 번호입니다.
우리는 성공적으로 두 개의 숫자를 추가했습니다!
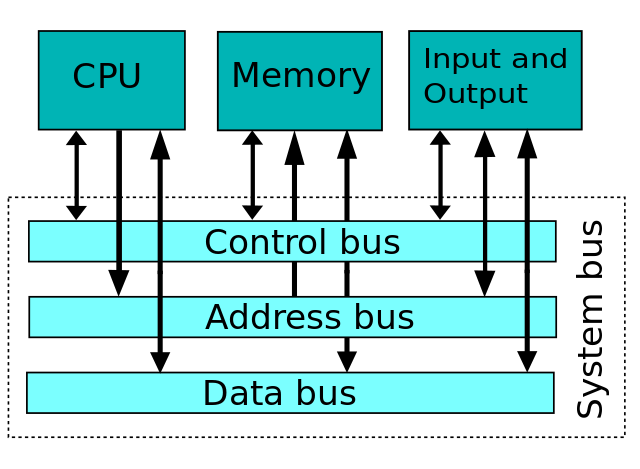
버스
CPU,레지스터,메모리 및 IO 고안 사이의 모든 데이터는 버스를 통해 전송됩니다. 을 로드하는 데이터를 메모리는 그것은 단지 추가,CPU 넣는 메모리 주소를 주는 버스와 결과의 합계 데이터 버스할 수 있는 권에서 신호 제어-버스입니다. 이 방법으로 데이터는 버스의 도움을 받아 메모리에로드됩니다.
캐시
CPU 에는 명령어를 캐시 된 것으로 프리 페치하는 메커니즘도 있습니다. 우리가 알고 있듯이 프로세서가 1 초 이내에 완료 할 수있는 수백만 개의 지침이 있습니다. 즉,명령을 실행하는 것보다 RAM 에서 가져 오는 데 더 많은 시간이 소요된다는 것을 의미합니다. 따라서 CPU 캐시는 명령어의 일부와 데이터를 프리 페치하여 실행이 빨라집니다.
캐시와 운영 메모리의 데이터가 다른 경우 데이터가 더티 비트로 표시됩니다.
명령어 파이프 라이닝
최신 CPU 는 명령어 실행에서 병렬화를 위해 명령어 파이프 라이닝을 사용합니다. 가져 오기,디코딩,실행. 하나의 명령어가 디코드 단계에있을 때 CPU 는 페치 단계에 대한 다른 명령어를 처리 할 수 있습니다.
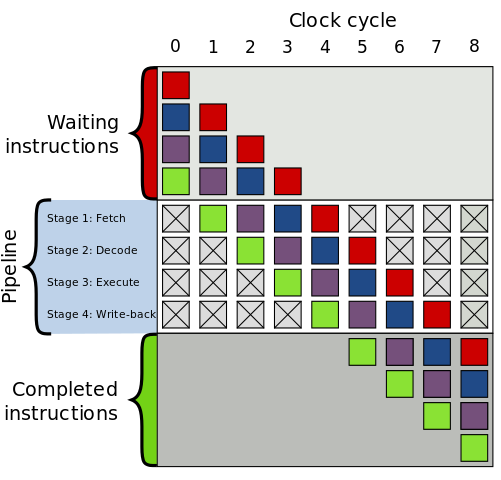
이것은 하나의 명령어가 다른 명령어에 종속 될 때 하나의 문제가 있습니다. 따라서 프로세서는 종속적이지 않고 다른 순서로 명령을 실행합니다.
멀티 코어 컴퓨터
기본적으로 다른 CPU 이지만 캐시와 같은 공유 리소스가 있습니다.
성능
CPU 의 성능은 실행 시간에 의해 결정됩니다. 성능=1/실행 시간
프로그램이 실행되는 데 20ms 가 걸린다고합시다. CPU 의 성능은 1/20=0 입니다.05msRelative 성능=행 시간 1/실행 시간 2
는 요인에 나오는 고려한 CPU 성능을 명령은 실행 시간 및 CPU 클럭 속도입니다. 따라서 프로그램의 성능을 높이려면 클럭 속도를 높이거나 프로그램의 명령어 수를 줄여야합니다. 프로세서 속도는 제한적이며 멀티 코어가있는 최신 컴퓨터는 초당 수백만 개의 명령어를 지원할 수 있습니다. 그러나 우리가 작성한 프로그램이 많은 지침을 가지고 있다면 이것은 전반적인 성능을 저하시킬 것입니다.
Big O 표기법은 성능이 어떻게 영향을 받는지에 대한 주어진 입력으로 결정합니다.
cpu 에서 수행 된 최적화가 많아서 더 빨리 만들고 최대한 많이 수행 할 수 있습니다. 쓰고 있는 동안 모든 프로그램 우리는 방법을 고려해야의 수를 줄이고 지침이 우리를 제공하여 CPU 증가할 것이 성능의 컴퓨터 프로그램입니다.
데이터베이스 최적화에 관심이 있으십니까? 여기에 대해 알아보십시오:https://milapneupane.com.np/2019/07/06/how-to-work-optimally-with-relational-databases/