
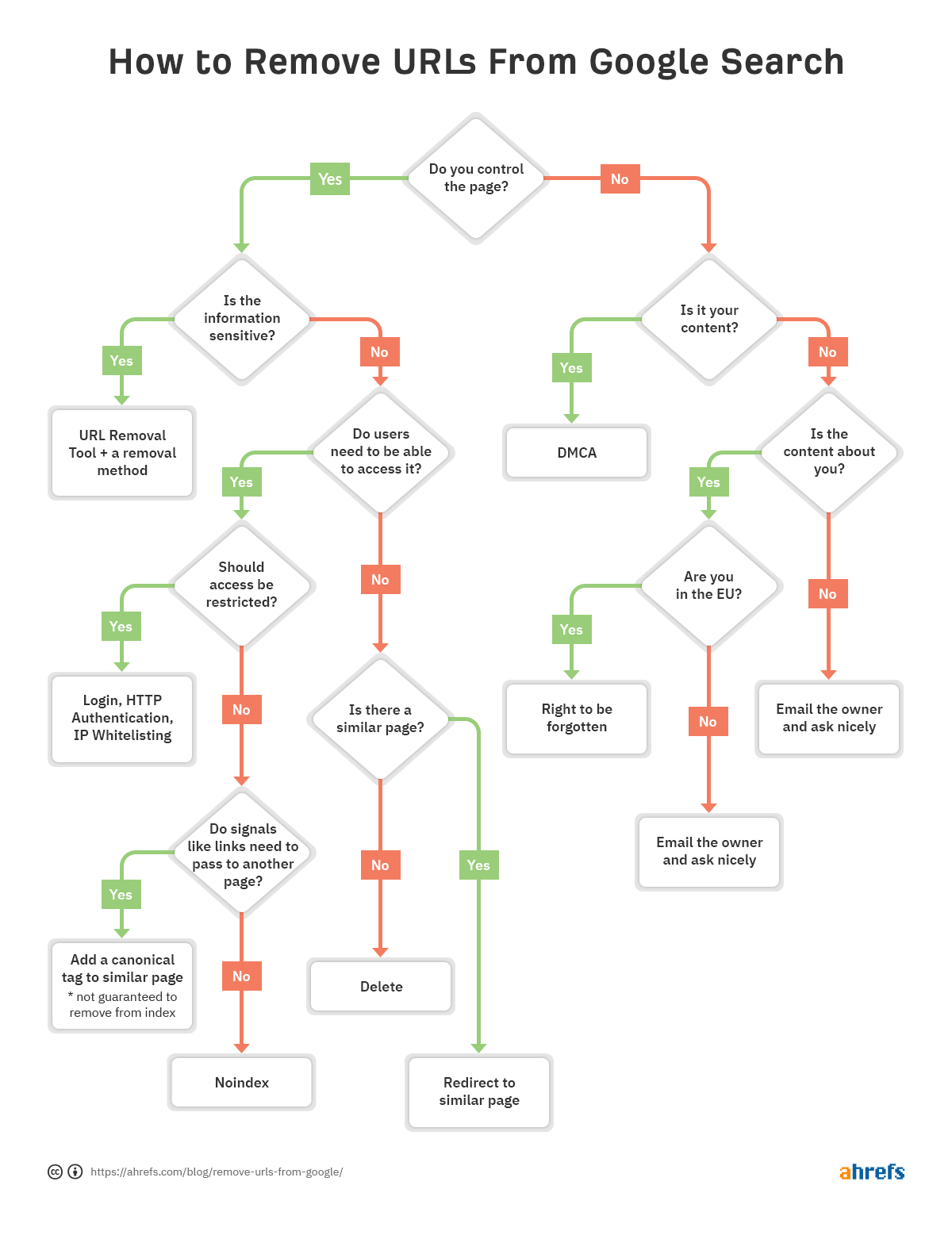
을 신속하게 당신을 도울 방법을 결정의 제거를 위해 최선을,우리는 흐름도 건너뛸 수 있도록 해당 섹션의 문서입니다.
이 게시물에서 배우게됩니다:
- 는 방법을 확인하는 경우에 URL 을 인덱싱
- 다섯 가지 방법을 제거에서 Url 을 구글
- 우선 순위를 지정하는 방법을 제거
- 일반적인 제거를 실수를 피하기 위해
- 는 방법을 제거하지 않는 콘텐츠 사이트에서
- 제거하는 방법 이미지
내가 무슨 일반적으로 보 SEOs 지 확인하는 경우 컨텐츠 인덱스가 사이트를 사용:구글에서 검색을(예를 들어,사이트:https://ahrefs.com). 동안 사이트: 검색에 유용할 수 있습을 식별하기 위한의 섹션 또는 페이지는 웹사이트 문제가 있을 수 있습니다면 그들은 검색결과에 표시되는 조심해야하지 않기 때문에 그들은 정상적인 쿼리와 연결되어 있지 않으면 말해 페이지를 인덱싱됩니다. 그들이 보여줄 수 있습 페이지의하는 것으로 알려진 구글,그러나 의미하지 않는 그들 자격에 표시할 일반적인 검색 결과가 없이 사이트 운영자입니다.
예를 들어,site:searches 는 여전히 다른 페이지로 리디렉션되거나 시성화 된 페이지를 표시 할 수 있습니다. 특정 사이트를 요청할 때 Google 은 다른 도메인의 콘텐츠,제목 및 설명과 함께 해당 도메인의 페이지를 표시 할 수 있습니다. 예를 들어,moz.com 로 사용되는 seomoz.org. 일반 사용자가 쿼리를 지도하는 페이지 moz.com 보 moz.com 에서 상승하는 동안,site:seomoz.org 보 seomoz.org 검색 결과에서 아래와 같습니다.
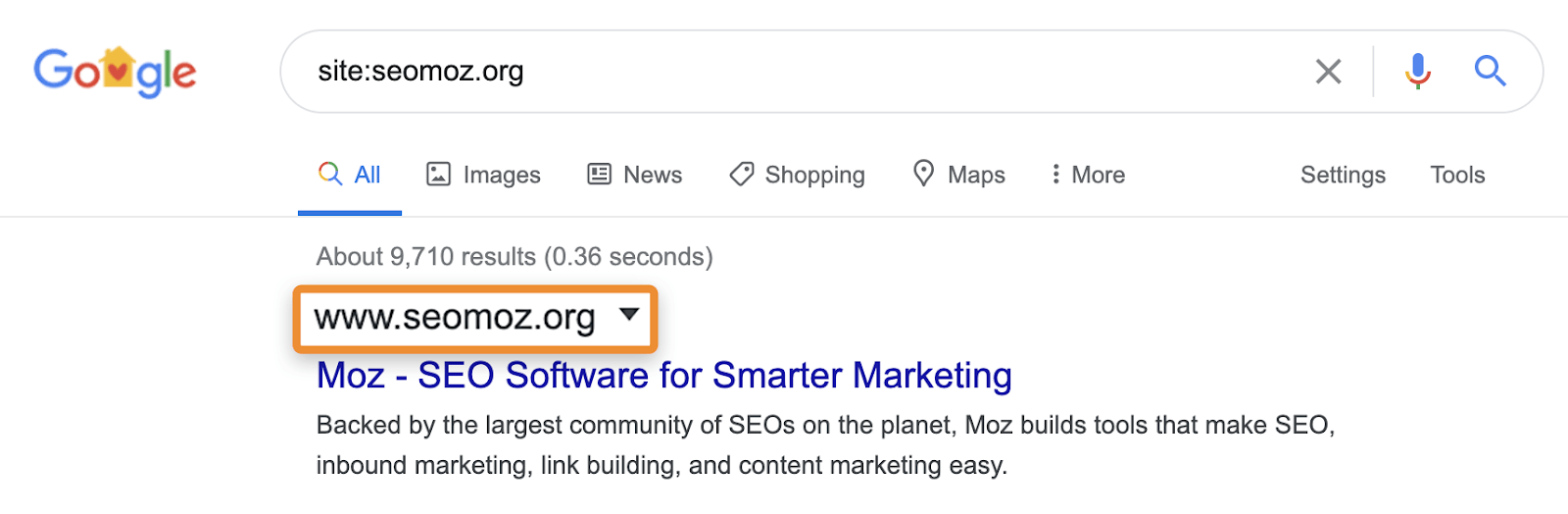
이 중요한 차이점으로 이어질 수 있다는 점이다 SEOs 실수하는 등의 적극적으로 차단하거나 제거하는 Url 에서는 인덱스에 대한 오래된 도메인을 방지하는 통합의 신호를 같은 PageRank. 본 경우가 많으로 도메인 마이그레이션을 어디에 사람들이 생각하는 실수를 마이그레이션 도중기 때문에 이러한 페이지를 표시해 site:old-domain.com 검색 결국이 적극적으로 손상이 자신의 웹 사이트하는 동안”수정”이 문제입니다.
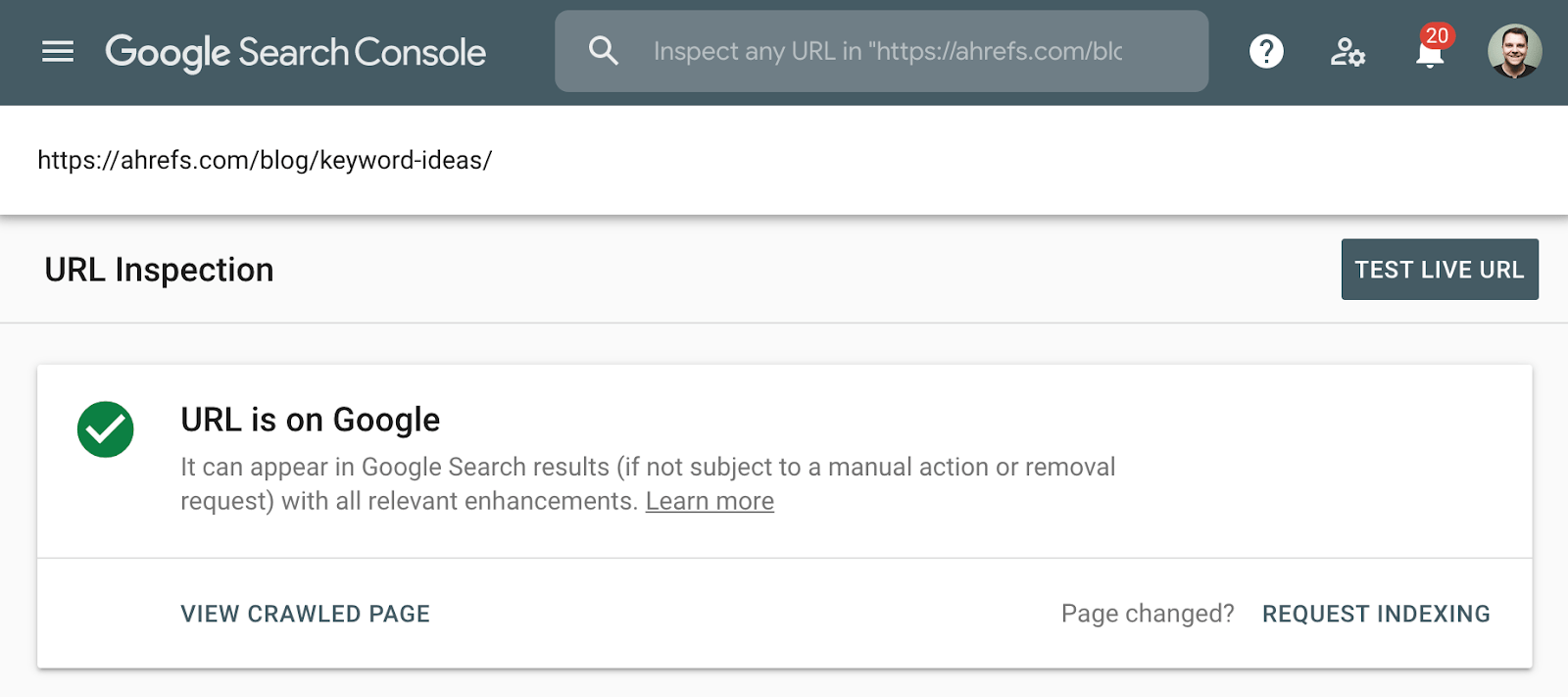
색인을 확인하는 더 좋은 방법은 Google 검색 콘솔의 색인 적용 범위 보고서 또는 개별 URL 의 URL 검사 도구를 사용하는 것입니다. 이러한 도구는 페이지가 색인되어 있는지 알려주고 Google 이 페이지를 처리하는 방법에 대한 추가 정보를 제공합니다. 이에 대한 액세스 권한이 없으면 Google 에서 페이지의 전체 URL 을 검색하기 만하면됩니다.
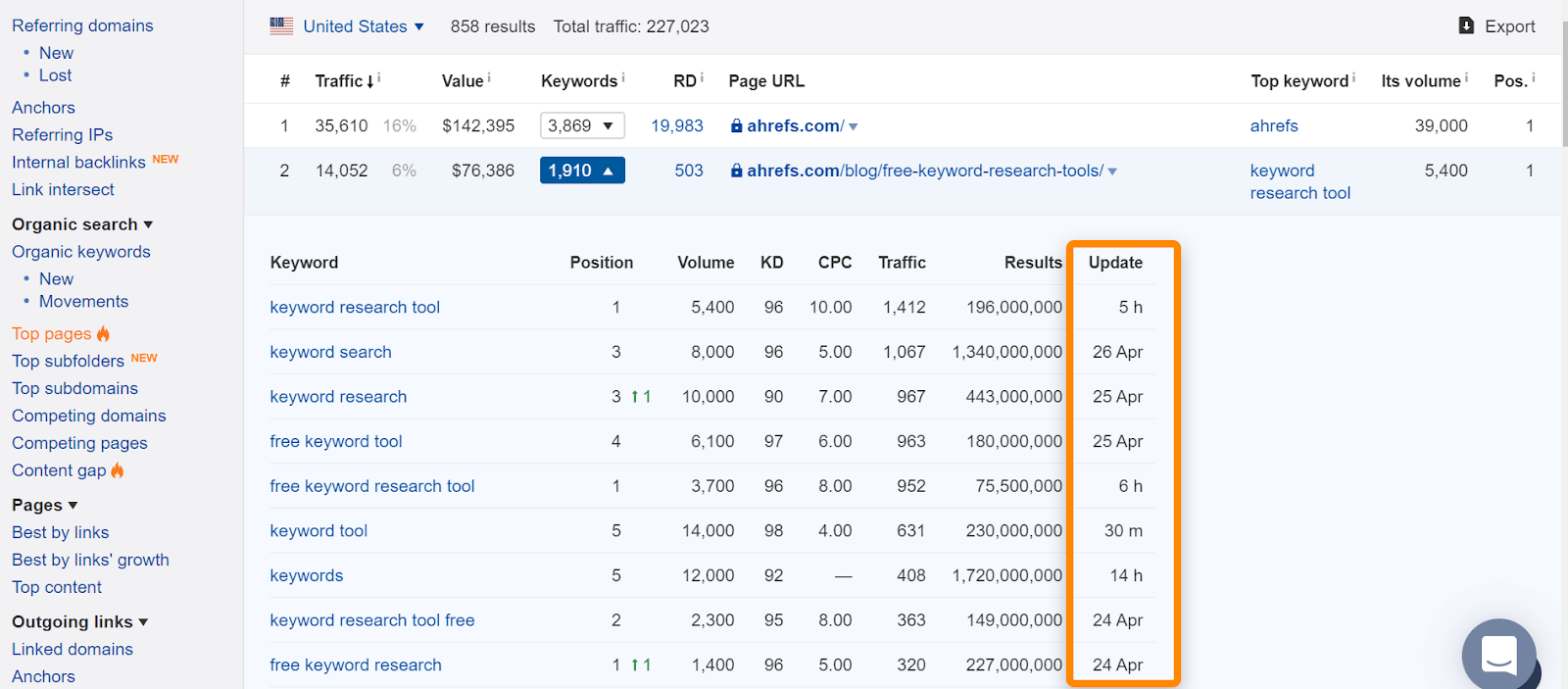
에 Ahrefs 는 경우에,당신은 페이지를 찾을에서 우리의”정상”페이지를 보고서 또는 순위를 유기 키워드로,그것은 일반적으로 의미는 우리가 그것을 보는 순위를 정상 검색 결과가 표시가 좋은 페이지를 인덱싱됩니다. 페이지를 보았을 때 색인이 생성되었지만 변경되었을 수 있습니다. 쿼리를 위해 페이지를 마지막으로 본 날짜를 확인하십시오.
문제가 있을 경우 특정 URL 을 요구에서 제거하는 인덱스에 따라 흐름도의 시작 부분에서 기사는 올바른 것을 찾기 위해 제거 옵션은 다음을 적절한다.
제거하는 경우 페이지고 봉사하거나 404(not found)또는 410(gone)상태 코드,다음 페이지에서 제거됩니다 지수는 조금 후에 페이지를 다시 크롤링됩니다. 제거 될 때까지 페이지가 여전히 검색 결과에 표시 될 수 있습니다. 그리고 페이지 자체를 더 이상 사용할 수 없더라도 캐시 된 버전의 페이지를 일시적으로 사용할 수 있습니다.
다른 옵션이 필요할 수도 있습니다.
- 더 즉각적인 제거가 필요합니다. URL 제거 도구 섹션을 참조하십시오.
- 링크와 같은 신호를 통합해야합니다. 정식화 섹션을 참조하십시오.
- 사용자가 사용할 수있는 페이지가 필요합니다. Noindex 또는 액세스 제한 섹션이 상황에 맞는지 확인하십시오.
제거 옵션 2: Noindex
a noindex meta robots 태그 또는 x-robots 헤더 응답은 검색 엔진에 색인에서 페이지를 제거하도록 알려줍니다. Meta robots 태그는 x-robots 응답이 페이지 및 Pdf 와 같은 추가 파일 형식에 대해 작동하는 페이지에서 작동합니다. 이러한 태그를 볼 수 있고,검색 엔진의 필요를 크롤링할 수 있도록 페이지에서 확인하지 않을 차단에서 로봇입니다.txt. 또한 색인에서 페이지를 제거하면 링크 및 기타 신호가 통합되지 않을 수 있습니다.
메타 로봇 noindex 의 예:
<meta name="robots" content="noindex">
의 예 x‑로봇 색인 태그에 헤더를 응답:
HTTP/1.1 200 OKX-Robots-Tag: noindex
필요할 때 다른 옵션:
- 나는 원하지 않는 사용자가 액세스하는 이러한 페이지입니다. 액세스 제한 섹션을 참조하십시오.
- 링크와 같은 신호를 통합해야합니다. 정식화 섹션을 참조하십시오.
제거 옵션 3:에 대한 액세스 제한
하려면 페이지에 액세스 할 수 있고 어떤 사용자는지 검색 엔진 다음,어떤 당신은 아마 당신이 원하는 것은 다음 세 가지 옵션 중 하나이다:
- 어떤 종류의 로그인 시스템;
- HTTP 인증(는 암호가 필요한에 대한 액세스);
- IP 화(만 특정 IP 주소에 액세스하는 페이지)
이 유형의 설치가 최고의 같은 것들에 대한 내부 네트워크 회원 전용 콘텐츠 또는 위한 준비,테스트,또는 개발 사이트입니다. 사용자 그룹이 페이지에 액세스 할 수는 있지만 검색 엔진은 액세스 할 수 없으며 페이지의 색인을 생성하지 않습니다.
다른 옵션이 필요할 수도 있습니다.
- 더 즉각적인 제거가 필요합니다. URL 제거 도구 섹션을 참조하십시오. 이 특정한 경우,당신은 더 많은 것을 할 수 있습니다 즉각적인 제거하는 경우 컨텐츠는 숨기려고가 캐시에 저장된,그리고 당신이 필요하지 못하도록 사용자를 보고하는 내용입니다.
제거 옵션 4:URL 을 제거 도구
이름에 대한 이 도구는 구글에서는 약간의 오해의 소지가대로 작동하는 방법입니다 그것은 일시적으로 숨기 내용입니다. 구글은 여전히이 콘텐츠를보고 크롤링하지만 페이지는 사용자를 위해 표시되지 않습니다. 빙 3 개월 동안 지속되는 유사한 도구를 가지고있는 동안이 임시 효과는 구글에서 6 개월 동안 지속됩니다. 이러한 도구를 사용해야에서 가장 극단적인 경우 같은 것들에 대한 보안 문제,데이터가 누출,개인 식별 정보(PII),등등. Google 의 경우 제거 도구를 사용하고 Bing 의 경우 Url 을 차단하는 방법을 참조하십시오.
당신은 여전히 필요를 적용하는 다른 방법과 함께 사용하여 제거 도구하기 위해서 실제적으로 페이지를 제거를 위한 더 긴 기간(색인 또는 삭제)또는 사용자가 콘텐츠에 액세스하는 경우 그들은 여전히 링크(삭제 또는 액세스 제한). 이것은 단지 제거가 처리 할 시간이있는 동안 페이지를 숨기는 더 빠른 방법을 제공합니다. 요청을 처리하는 데 최대 하루가 걸릴 수 있습니다.
제거 옵션 5:정형화
이 여러 개 있는 경우 버전의 페이지와 통합하려는 신호는 다음과 같이 링크하는 하나의 버전에,당신이 무엇을 하고 싶은 일부 형태의 표준화. 이는 주로 여러 버전의 페이지를 단일 색인 URL 에 통합하면서 중복 콘텐츠를 방지하는 것입니다.
몇 가지 canonicalization 옵션이 있습니다.
- Canonical tag. 이 정식 버전 또는 표시 할 버전으로 다른 URL 을 지정합니다. 페이지가 중복되거나 매우 유사한 경우 이는 잘되어야합니다. 페이지가 너무 다를 때,캐 노니 컬은 지시문이 아닌 힌트이기 때문에 무시 될 수 있습니다.
- 리디렉션합니다. 리디렉션은 한 페이지에서 다른 페이지로 사용자와 검색 봇을 가져옵니다. 301 는 가장 일반적으로 사용되는 리디렉션에 의해 SEOs,그리고 그것을 검색 엔진을 알려줍니다 당신이 원하는 최종 URL 하나 검색결과에 표시되고 신호가 통합됩니다. 302 또는 임시 리디렉션은 검색 엔진에 원래 URL 이 인덱스에 남아 있고 거기에 신호를 통합 할 수 있기를 원한다고 알려줍니다.
- URL 매개 변수 처리. 매개 변수에 추가되는 URL 끝 일반적으로 질문을 포함 mark,다음과 같 ahrefs.com?이러=매개 변수입니다. 이 도구는 구글에서 수 있습니 당신은 그들에게 말을 치료하는 방법으로 Url 을 특정한 매개 변수입니다. 예를 들어 매개 변수가 페이지 내용을 변경하는지 아니면 그냥 사용을 추적하기위한 것인지 지정할 수 있습니다.
Google 의 색인에서 제거 할 페이지가 여러 개인 경우 그에 따라 우선 순위를 지정해야합니다.
가장 높은 우선순위:이 페이지는 일반적으로 보안과 관련되거나 관련된 기밀 데이터입니다. 여기에는 개인 데이터(PII),고객 데이터 또는 독점 정보가 포함 된 콘텐츠가 포함됩니다.
중간 우선 순위:이것은 일반적으로 사용자의 특정 그룹에 대한 의미 콘텐츠를 포함한다. 회사 인트라넷 또는 직원 포털 콘텐츠에 대한 의미 멤버이며,준비,테스트,또는 개발 환경입니다.
낮은 우선 순위:이 페이지에는 일반적으로 어떤 종류의 중복 콘텐츠가 포함됩니다. 의 몇 가지 예는 이 포함되는 페이지에서 여러 Url 을,Url 을 매개변수,그리고 다시 포함할 수 있습 준비,테스트,또는 개발 환경입니다.
고 싶은 몇 가지의 방법으로 나는 일반적으로 보는 제거 잘못 수행하고 무엇에서 일어나는 각 시나리오 사람들이 이해할 것을 돕기 위한 것이 왜 그들은 작동하지 않습니다.
로봇의 Noindex.Txt
구글은 비공식적으로 로봇의 noindex 를 지원하는 데 사용되는 동안.txt,그것은 결코 공식적인 표준이 아니었고 그들은 이제 공식적으로 지원을 제거했습니다. 이 작업을 수행 한 사이트의 대부분은 잘못하고 자신을 해치고 있었다.
로봇의 크롤링을 차단합니다.Txt
크롤링은 인덱싱과 같은 것이 아닙니다. 는 경우에도 Google 은 크롤링을 차단 페이지가 있는 경우,어떤 내부 또는 외부 링크하는 페이지들인다. 구글 무엇을 알 수 없는 페이지에 있기 때문에 그들은 크롤링하지 않습니다 그것은,그러나 그들은 알고 있는 페이지가 존재하고 심지어 작성 제목 검색결과에 표시에 따라 신호음의 앵커 텍스트 링크하는 페이지입니다.
Nofollow
이것은 일반적으로 혼란을 가져옵에 대한 색인,그리고 어떤 사람들은 그것을 사용하에 페이지 수준을 기대하지 않는 페이지 색인이 붙어야 한다. Nofollow 는 힌트이며,원래 페이지의 링크와 nofollow 특성을 가진 개별 링크가 크롤링되는 것을 중지했지만 더 이상 그렇지 않습니다. 그들이 원하는 경우 구글은 이제 이러한 링크를 크롤링 할 수 있습니다. Nofollow 는 또한 특정 페이지를 통해 크롤링에서 구글을 중지하려고 페이지 랭크 조각을 위해 개별 링크에 사용되었다. 다시 말하지만,이것은 nofollow 가 힌트이기 때문에 더 이상 작동하지 않습니다. 페이지에 다른 링크가 있다면 과거에는,다음 구글은 여전히이 대체 크롤링 경로에서 발견 할 수있다.
Ahrefs 의 사이트 감사에서 페이지 탐색기에서이 필터를 사용하여 nofollowed 페이지를 대량으로 찾을 수 있습니다.
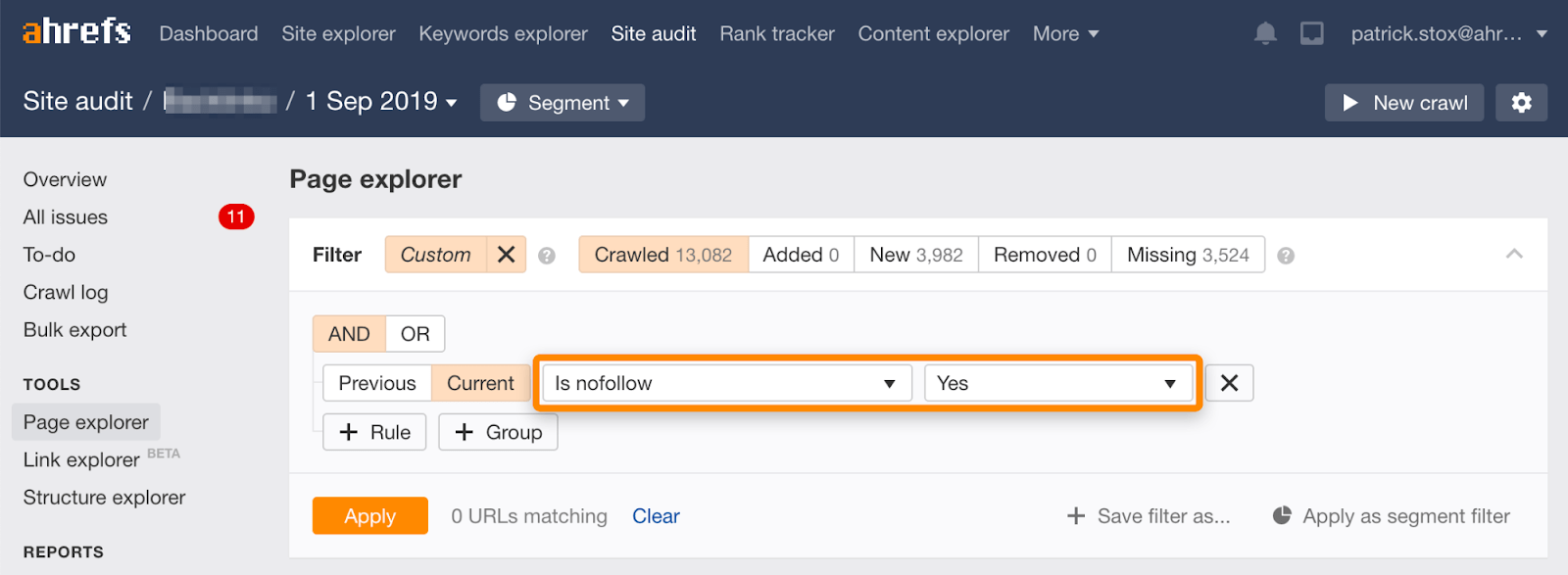
그것이 거의 의미가를 따르지 모든 페이지의 링크의 숫자는 결과해야로는 제로에 가깝습니다. 이 있는 경우에 일치하는 결과,나는 당신을 촉구하는지 여부를 확인 nofollow directive 실수로 추가되는 장소의 색인을 선택할 수가 더 적절한 방법을 제거 할 필요가있는 경우.
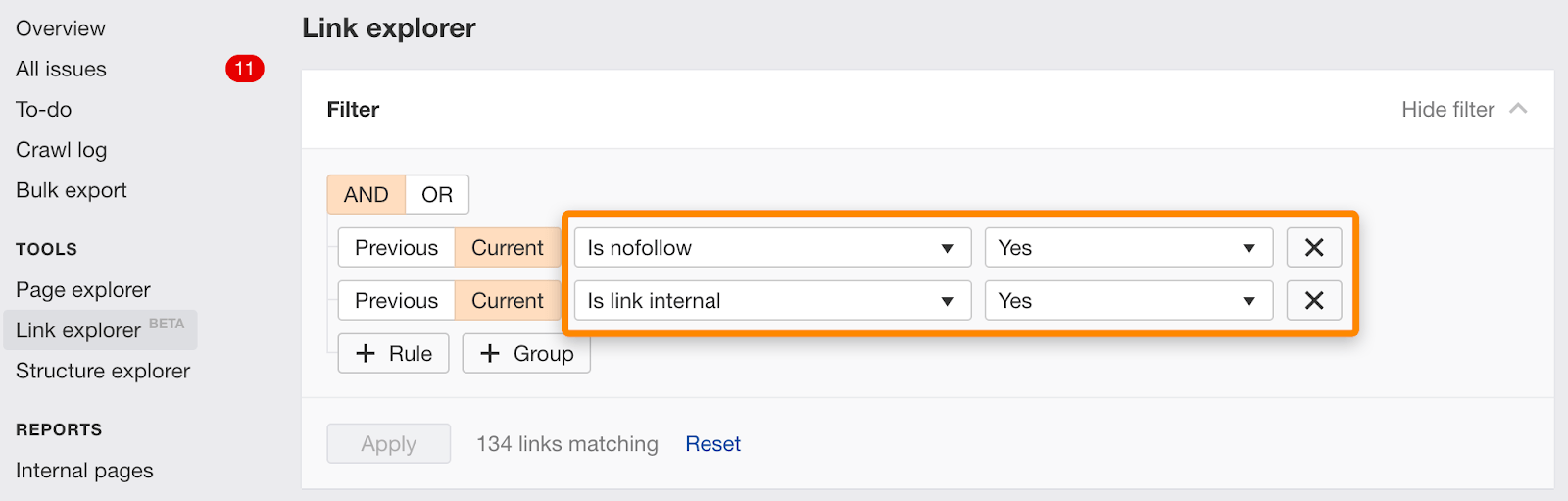
링크 탐색기에서이 필터를 사용하여 nofollow 로 표시된 개별 링크를 찾을 수도 있습니다.
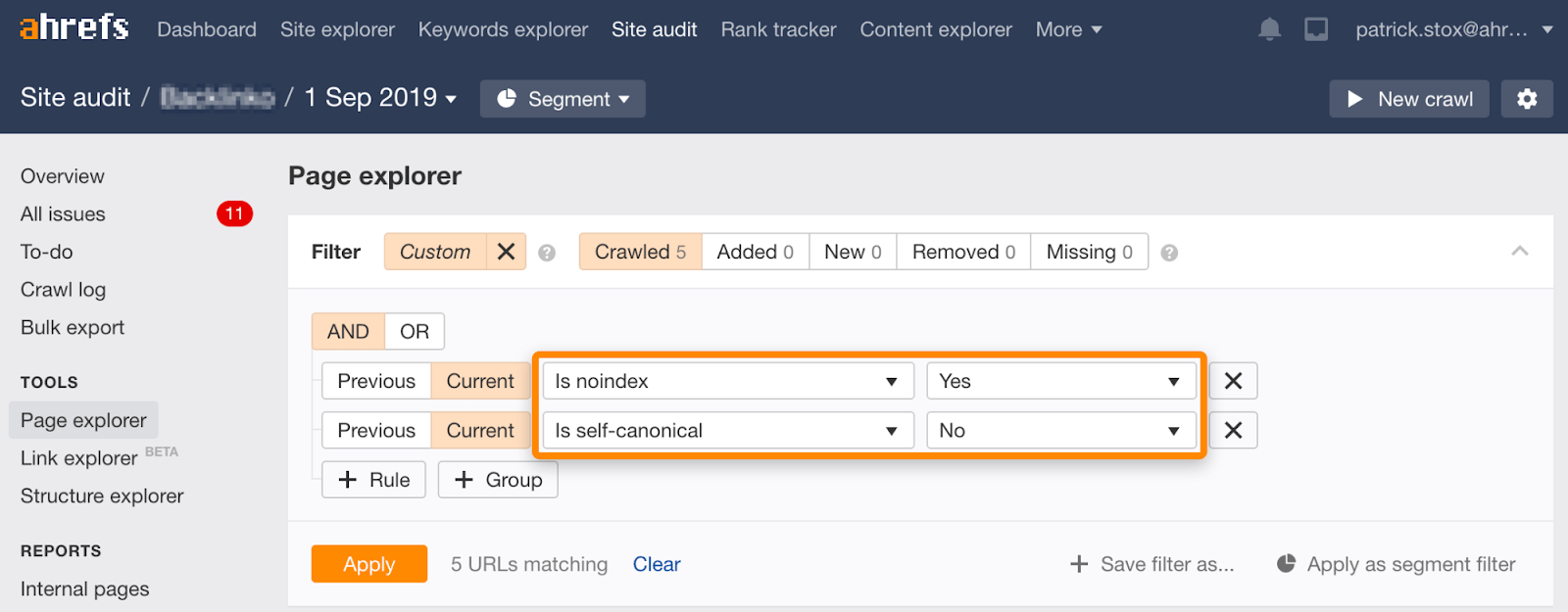
Noindex 및 canonical to another URL
이러한 신호는 충돌합니다. Noindex 는 색인에서 페이지를 제거하라고 말하면서 canonical 은 다른 페이지가 색인을 생성해야하는 버전이라고 말합니다. Google 은 일반적으로 noindex 를 무시하고 대신 canonical 을 주요 신호로 사용하도록 선택할 것이므로 실제로 통합을 위해 작동 할 수 있습니다. 그러나 이것은 절대적인 행동이 아닙니다. 관련된 알고리즘이 있으며 noindex 태그가 신호가 계산 될 수있는 위험이 있습니다. 그럴 경우 페이지가 제대로 통합되지 않습니다.
주는 것을 찾을 수 있습 noindexed 페이지와 비-자기참조 canonicals 의 세트를 사용하여 필터 페이지에서 탐색기에서 현장 감사:
색인,구글 기다리를 크롤링,다음 블록 크롤링
있는 몇 가지 방법이 일반적으로 발생:
- 페이지를 이미를 차단하지만 색인,사람들이 추가 비색 및 차단하도록 Google 크롤링할 수 있고 색인,다음을 차단 페이지에서 크롤 다시합니다.
- 사람들은 제거하려는 페이지에 대해 noindex 태그를 추가하고 Google 이 noindex 태그를 크롤링하고 처리 한 후 페이지가 크롤링되는 것을 차단합니다.
어느 쪽이든 최종 상태가 크롤링되지 않도록 차단됩니다. 당신이 기억한다면,이전에,우리는 크롤링이 인덱싱과 동일하지 않은 방법에 대해 이야기했습니다. 이러한 페이지가 차단 되더라도 여전히 색인으로 끝날 수 있습니다.
다른 웹 사이트에서 사용중인 콘텐츠를 소유하고 있다면 DMCA(Digital Millennium Copyright Act)에 따라 클레임을 제기 할 수 있습니다. 당신이 사용할 수 있는 구글의 저작권거 도구를 무엇이라고 제가 각는 요청의 제거든 저작권이 있는 소재입니다.
그것이 당신에 관한 내용이지만 소유하고있는 사이트에 없다면 어떨까요?
당신이 EU 에 있다면,당신은 잊혀 질 권리에 대한 법원 명령 덕분에 당신에 대한 정보가 포함 된 콘텐츠를 제거 할 수 있습니다. EU 개인 정보 제거 양식을 사용하여 개인 정보를 제거하도록 요청할 수 있습니다.
구글에서 이미지를 제거하려면,가장 쉬운 방법은 로봇입니다.txt. 페이지 제거에 대한 비공식 지원이 로봇에서 제거되었지만.txt 앞서 언급했듯이 단순히 이미지 크롤링을 허용하지 않는 것이 이미지를 제거하는 올바른 방법입니다.
에 대한 하나의 이미지:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
에 대한 모든 이미지가:
User-agent: Googlebot-ImageDisallow: /
최종 생각
제거 방법은 Url 을 매우 상황. 우리는 몇 가지 옵션에 대해 이야기했지만,여전히 당신에게 적합한 혼란 스럽다면 시작시 순서도를 다시 참조하십시오.
콘텐츠 제거를 위해 Google 에서 제공하는 법적 문제 해결사를 통해 갈 수도 있습니다.
질문이 있으십니까? 트위터에 알려주세요.