- 어? SQL 에서 그룹화 세트,큐브 및 롤업이란 무엇입니까?
- 왜 롤업이나 큐브가 나에게 유용할까요?
- 이 표준 SQL 입니까 아니면 Microsoft 전용입니까?
- 롤업에서 하나 이상의 열을 제외 할 수 있습니까?
- 그룹화 세트는 무엇입니까? 나는 그들에 대해 알아야합니까?
- 왜 우리는 어떤 집계에서 열을 결합하고 싶습니까?
- ‘일품 요리’큐브를하는 방법보다 그룹화 세트에 더 많은 것이 있습니까?
- grouping_id()및 grouping_id()함수가 제공되는 이유는 무엇입니까?
- 어? SQL 에서 그룹화 세트,큐브 및 롤업이란 무엇입니까?
- 왜 또는 롤업 큐브에 유용할까?
- 이 표준 SQL 입니까 아니면 Microsoft 전용입니까?
- 롤업에서 하나 이상의 열을 제외 할 수 있습니까?
- 은 무엇을 그룹화 세트는 다음? 나는 그들에 대해 알아야합니까?
- 왜 우리는 어떤 집계에서 열을 결합하고 싶습니까?
- ‘단품’큐브를 수행하는 방법보다 그룹화 세트에 더 많은 것이 있습니까?나는이 질문을하는 것에 대해 부끄러워 할 것이라고 확신하지 못한다. SQL:1999 년의 그룹화 세트를 제공하는 풍부한 구문을 재귀할 수 있는 집계의 조합이 열리고 정의하는 모든 종류의 비전을 제공하는 보고서를 열다. 집계는 중첩될 수 있으며 롤업 내에 큐브를 중첩하고 큐브 내에 롤업을 중첩할 수 있습니다. 이에 대한 자세한 내용을 보려면 전문가 간행물을 읽어야합니다. grouping()및 Grouping_ID()함수가 제공되는 이유는 무엇입니까?
어? SQL 에서 그룹화 세트,큐브 및 롤업이란 무엇입니까?
큐브,롤업 및 그룹화 세트는 많은 양의 정보로 보고서를 수행하기위한 SELECT 문의 GROUP BY 절의 선택적 연산자입니다. 그들은 할 수 있도록 여러 그룹에 의해 운영 중 하나에서 문을 잠재적으로 많은 시간을 절약하고 전산 노력입니다. 들을 제공할 수 있는 데 필요한 모든 정보에 대한 보고를 포함하여 총을 주는 반면,좋은 성능의 대형 테이블 및 돕는 쿼리의 최적화를 고안 좋은 실행 계획을 실행합니다.
추가’슈퍼 aggregate’행 제공 값은 요약하여 할 수 있도록 여러’집’등 SUM()또는 최대()내 하나의 결과입니다. 결과에서 이러한 행 내의 Null 은’알 수 없음’이 아닌’모두’를 의미하기위한 것입니다. 그것은 당신이 테이블을 통해 하나의 패스에 필요한 모든 집계를 얻을 수 있습니다. 의 존재 때문에 추가에서 행한 결과,추가 기능을GROUPING()GROUPING_ID()제을 나타내는 이러한 추가’슈퍼 aggregate’행,그리고 어떤 열은 집계됩니다.
이것은 큰 의미가 있는 경우는 응용 프로그램을 실행하는 데 필요 여러 보고서를 추가하지 않고 계산 또는 거치지 않고 데이터베이스에 다시:당신에 필요한 모든 것을 한 결과입니다.
이 표준 롤업 예제를 사용하십시오(여기 AdventureWorks2012 를 사용하고 있습니다)..
|
1
2
3
4
5
6
|
선택 t. 지역,t.이름로 영토,합계(TotalDue)수익으로,
부분(년,주문일)로,부분(mm,주문일)같
에서 판매합니다.SalesOrderHeader s
INNER JOIN Sales.T.TerritoryID=T.TerritoryID
t 에 의한 그룹.,t.이름 부분(년,주문일),부분(mm,주문일)
와 롤업
|
뿐만 아니라 간단한 그룹에 의해 집계의 행진과 함께로 인해 매달,당신을 얻을 것으로 간단한 그룹화,당신은 또한 소계 또는 슈퍼 aggregate 행 또한 총 합니다. (여기 결과의 시작입니다)
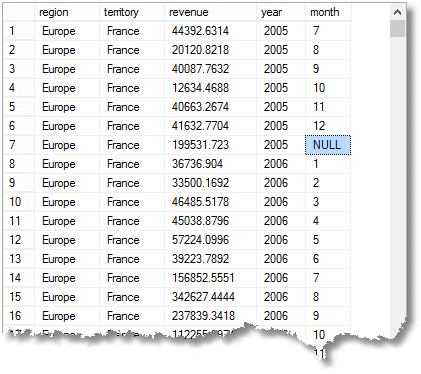
NULL 나 highlit 을 의미하는 행은 집계하는’모든’달의 2005 년 프랑스에서(부분의 유럽 지역)
뿐만 아니라 이 모든,당신은 총으로 인해 각 연도에 대한 각각의 영토 및 영해 뿐만 아니라 그룹 전체 총액입니다. (끝에서)

동일한 효과를 얻으려면 사용하지 않고 롤업에,당신은 뭔가를 해야 합 다음과 같이(AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;이 작업을 수행하려면 다음 작업을 수행 할 수 있습니다.t.name 예를 들어,Datepart(yyyy,OrderDate)는 판매에서 datepart(mm,OrderDate)입니다.SalesOrderHeader s
INNER JOIN Sales.나는 이것이 내가 할 수있는 유일한 방법이라고 생각한다.t.name,티.,부분(년,주문일),부분(mm,주문일))
지역 선택,영토,totalDue,,
에서 myGrouping
UNION ALL
지역 선택,지역,합계(totalDue),NULL
에서 myGrouping 그룹에 의해 지역별,지역,
UNION ALL
지역 선택,지역,합계(totalDue),NULL,NULL
에서 myGrouping 그룹에 의해 지역 영역
UNION ALL
지역 선택,NULL,sum(totalDue),NULL, NULL
에서 myGrouping 그룹에 의해 영역
UNION ALL
선택 NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.이름 부분(년,주문일),부분(mm,주문일))’
|
이 새로운 구문할 수 있는 몇 가지 추가 기능이 있습니다. 열 순서가 롤업의 출력 그룹에 영향을 미치고 결과 집합의 행 수에 영향을 줄 수 있다는 점도 기억하십시오.
큐브는 같은 일반적인 일이지만,대신에 제공하는 계층의 합계에서 주문 슈퍼 집 행을 제공하는 모든’슈퍼 aggregate’순열(‘대칭 슈퍼 aggregate’행),소위 cross-표 행이 있습니다. 지 알고 싶으시다면 어느 영토에게 준 가장 주문에,또는 어느 영토를 수행되는 최소한,2006 년에 그 당신은 필요할 것입니다. 당신은 결과에 가능한 모든 합계를 제공하고 있습니다.
그룹화 세트를 사용하면 결과를 미세 조정하여 큐브 위와 그 이상의보다 전문화 된 정보를 제공 할 수 있습니다. 차원의 조합에 대한 요약 정보를 제공할 수 있습니다. 그룹화 세트를 사용하여 롤업 예제에서와 정확히 동일한 결과를 얻을 수 있지만 더 많은 타이핑을 할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
|
선택 t. 지역,t.이름로 영토,합계(TotalDue)수익으로,
부분(년,주문일)로,부분(mm,주문일)같
에서 판매합니다.SalesOrderHeader s
INNER JOIN Sales.S 에 SalesTerritory T.TerritoryID=T.TerritoryID
그룹으로 그룹화 세트(
(T.T. 름,부분(년,주문일),부분(mm,주문일)),
(T.T. 름,부분(년,주문일)),
(T.T. 름),
(T.),
())
|
이것은 그냥을 표시하는 방법들을 통한 연계가 가능합니다. 실제로는 롤업이나 큐브로는 불가능한 결과를 얻기 위해 그룹화 세트에 의지 할 것입니다.
이러한 거의 모든 요약에서 얻을 수 있를 사용하여 그룹에 의해를 통해서만 반복적으로 그룹화의 결과에 의해 그룹에 의해,또는 보다 더 많이 만들어 하나를 통과 데이터입니다.
할 때 사용하는 큐브,롤업 또는 그룹화 세트,사용할 수 없습니다 뚜렷한 키워드에서 집과 같은 표현균(고유 테),카운트(고유 테),합계(유 테)
왜 또는 롤업 큐브에 유용할까?
롤업과 큐브는 SSAS 전에 전성기를 보냈습니다. 그들은 OLAP 에서 큐브가 제공하는 것과 같은 종류의 시설을 제공하는 데 유용했습니다. 그래도 여전히 그 용도가 있습니다. AdventureWorks,그것이 과잉,그러나 처리하는 경우 다량의 데 필요한 데이터를 통과 데이터를,한 번만하고 가능한 한 많은 일에는 데이터가되었습니다. 과거에 일어난 사건은 변경할 수 없으므로 활성 OLTP 시스템에서 역사적인 데이터를 보관할 필요가 거의 없습니다. 대신 예측 가능한 모든 보고서에 필요한 세부 수준(‘세분성’)으로 집계 된 데이터 만 유지하면됩니다.
하루에 2 백만 정도의 전화가 걸려 오는 전화 스위치에보고 할 책임이 있다고 상상해보십시오. 당신이 당신의 OLTP 서버에 이러한 모든 호출을 유지하는 경우,당신은 곧 사용 보고서를 통해 labouring SQL 서버를 찾을 것입니다. 당신은 유지 원래 부르는 정보에 대한 법적 기간 동안,하지만 당신이 결정하는 비즈니스에서 그들이,대부분에서만 관심이 통화 수니다. 그런 다음 OLTP 서버의 스토리지 요구 사항을 1 로 줄였습니다.그것이 무엇의 4%,그리고 통화 기록은 임시 쿼리 및 고객 문에 대한 다른 SQL 서버에 떨어져 보관할 수 있습니다. 저것은 만들 가치가있는 저축 일 것 같다. 큐브와 롤업에 절을 할 수 있도 저장하는 행 합계,열 합계 총합계를 할 필요없이 테이블이나 인덱스,스캔의 요약이다.
만큼 변경되지 않으므로 소급해 이 데이터를,그리고 모든 기간은 완전하지,당신을 반복해야 또는 변경하거나 집계를 기반으로 지난 시간이 기간 동안만,그랜드 합계가 필요하다해!.
척하자.하지만 AdventureWorks2012 를 사용하면 함께 놀 수 있습니다.
먼저 그램 요약 테이블을 작성하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
존재하는 경우(SELECT*FROM tempdb.시스.테이블과 같은 이름을’#AggregationTable%’)
드롭 테이블#aggregationTable–delete 임시 테이블이 있는 경우
GO
SELECT
id(INT,1,1),-그래서 우리는 할 수 있는 독특한 열
t. 지역,t.이름로 영토,합계(TotalDue)수익으로,
부분(년,주문일)로,부분(mm,주문일)로,
그룹(t.이름)로 isNameGroup,–이와 관련하여 모든 지역
그룹(t. 로)isGroupGroup,–이 모든 대륙
그룹(부분(년,주문일))로 isYearGroup,–이와 관련하여 모든 년
그룹(부분(mm,주문일))로 isMonthGroup,–이와 관련한 모든 개월
Grouping_ID(t.이름,t.,
부분(년,주문일),부분(mm,주문일))로 isGroupingRow
–이 추가 비 데이터가 포함된 행 데이터 집계
로#AggregationTable
에서 판매합니다.SalesOrderHeader s
INNER JOIN Sales.S 에 SalesTerritory T.TerritoryID=T.TerritoryID
그룹 t.이름,t., 부분(년,주문일),부분(mm,주문일)
와 롤업
|
통지 우리가 추가’조’열고있는 우리에게 행함은 요약 행에 표시됩니다. 실수로 더 이상의 집계에 추가하면 심각하게 팽창 된 결과를 얻을 수 있습니다. 분명히 저장된 결과에Grouping()또는 Grouping_ID 를 사용할 수 없으므로 대신 무언가를 제공해야합니다.
이제 우리는 생산할 수 있는 테이블은 매우 빠르
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
–지금 우리가 만들 수 있는 간단한 피벗 테이블과 함께 행하고
–열 합계
선택 영역
sum(는 경우 2005 년 다음 수익 다른 0END)로,
sum(는 경우는 2006 년 다음 수익 다른 0END)로,
sum(는 경우 2007 다음은 수익 다른 0END)로,
sum(는 경우 2008 다음 수익 다른 0END)로,
sum(수익) 로
에서#AggregationTable
어디 isGroupingrow=0
그룹에 의해 영역
UNION ALL
SELECT’총’,합계(케이스 때 2005 다음 수익 다른 0END)로,
sum(는 경우는 2006 년 다음 수익 다른 0END)으로,
sum(는 경우 2007 다음은 수익 다른 0END)로 ,
sum(는 경우 2008 다음 수익 다른 0END)로,
sum(수익) 로
에서#AggregationTable
어디 isYearGroup=0isMonthGroup=1
|
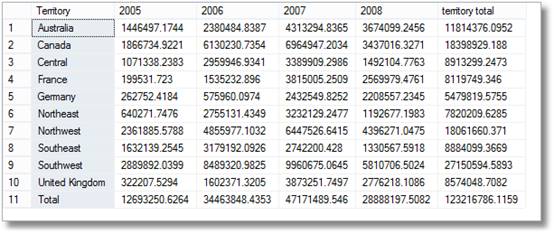
그래서 거기에 간단한 미소에서는 매니저에 보이지만,그들은 밝은 말’나 또한 요청에 대한 분석을 통해 지역별 달
짧은 웃음으로,당신이 이렇.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECT
datename(MONTH,dateadd(한 달,’01dec2000′))로,
합계(케이스 영역을 때’Australia’그런 다음 다른 수익 0END)로,
합계(케이스 영역을 때’캐나다’그런 다음 다른 수익 0END)으로,
합계(케이스 영역을 때’Central’그런 다음 다른 수익 0END)로,
sum(의 경우 지역 경우 프랑스런 수익 다른 0END)로,
합계(케이스 영역을 때’독일은’다음 수익 다른 0END)로,
합계(케이스를’동북’그런 다음 다른 수익 0END)으로,
합계(케이스 영역 면’노스웨스트’다음 수익 다른 0END)로,
합계(케이스를’동남’그런 다음 다른 수익 0END)로,
합계(케이스 영역을 때’남서’그때는 수익이 다른 0END)로,
합계(케이스 영역을 때’미국’그런 다음 다른 수익 0END)로,
sum(수익) 로
에서#AggregationTable
어디 isGroupingrow=0
그룹에 의해 달
UNION ALL
SELECT
‘총’,
합계(케이스 영역을 때’Australia’그런 다음 다른 수익 0END)로,
합계(케이스 영역을 때 ‘캐나다’그런 다음 다른 수익 0END)로,
합계(케이스 영역을 때’Central’그런 다음 다른 수익 0END)로,
sum(의 경우 지역 경우 프랑스런 수익 다른 0END)로,
합계(케이스 영역을 때’독일은’다음 수익 다른 0END)으로,
합계(케이스를’동북’그런 다음 다른 수익 0END)로,
sum(의 경우 지역 경우 노스웨스트’다음 수익 다른 0END)로,
합계(케이스를’동남’그런 다음 다른 수익 0END)로,
합계(케이스 영역을 때’남서’그때는 수익이 다른 0END)로,
합계(케이스 영역을 때’미국’그런 다음 다른 수익 0END)로,
sum(수익) 로
에서#AggregationTable
어디 isGroupingrow=0
|
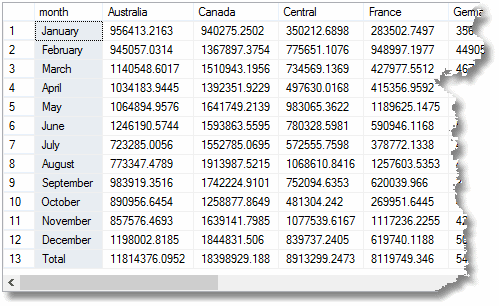
그러나 롤업 대신 큐브를 사용했다면 마지막’총’행은 이미 계산됩니다. 보고서를 수행하는 데 시간이 걸리는 실제 예에서. 당신이 할 수 있는 큐브에서 열까지 차원이 있지만 그들은 대량 집계는 그렇지도 않고 너무 비용이 많이 듭니다.
이 표준 SQL 입니까 아니면 Microsoft 전용입니까?
이들은 이제 1999 년의 표준 ANSI SQL 이지만 CUBE 와 ROLLUP 은 Microsoft 에 의해 처음 소개되었습니다. 이 포함은’알 수 없음’외에 NULL 값에 대해 두 번째 의미 인’모두’를 도입한다는 점에서 다소 놀랍습니다. Microsoft 가 CUBE 와 ROLLUP 을 처음 도입했을 때 구문은 약간 달랐지만 SQL Server 에서는 두 가지 양식이 모두 허용됩니다. 단일 SELECT 문에서 하나의 구문 스타일 만 사용할 수 있으며 모든 새 작업에 ISO 준수 구문을 사용해야합니다.
롤업에서 하나 이상의 열을 제외 할 수 있습니까?
원한다면! 상상하고 싶지 않았 슈퍼의 총 합계가 모든 지역에 대해(t.)
|
1
2
3
4
5
6
|
선택 t. 지역,t.이름로 영토,합계(TotalDue)수익으로,
부분(년,주문일)로,부분(mm,주문일)같
에서 판매합니다.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T s.TerritoryID=T.TerritoryID
그룹 t., 롤업(t.이름 부분(년,주문일),부분(mm,주문일))
|
여기에는 우리가 사용하는 ANSI SQL2006 준수문입니다. 큐브로도 마찬가지입니다. 나는 결코 발견을 위해 실제적인 사용이지만에 걸쳐 올 수도 있습니다.
은 무엇을 그룹화 세트는 다음? 나는 그들에 대해 알아야합니까?
그룹화 세트는 결과를 여러 번 그룹화하도록 SQL 에 요청하고 있음을 의미합니다. 그룹화 집합 구문을 사용하여 계산할 집계를 정확하게 지정할 수 있습니다. 다음은 예입니다.
|
1
2
3
4
5
6
|
선택 t. 지역,t.이름로 영토,합계(TotalDue)수익으로,
부분(년,주문일)로,부분(mm,주문일)같
에서 판매합니다.SalesOrderHeader s
INNER JOIN Sales.S 에 SalesTerritory T.TerritoryID=T.TerritoryID
그룹 t., 그룹화 세트(롤업(t.이름)
롤업(부분(년,주문일),부분(mm,주문일)))
|
여기에서,요구하고 있는 고장에 의해 영역에 대한 그룹의 매월 매년과 달과 년의 합계에 의해 다음,요약을 총에 의해 영토 이름 그러나지 않고는 총합이 있습니다. 롤업과 달리 각 그룹화 세트 내의 열 순서와 그룹화 세트 순서가 무엇이든 동일한 결과를 얻습니다.
그룹화 세트는 큐브와 롤업이 제공하는 것을 정확하게 제공 할 수 있습니다. 당신이 볼 수있는이 마지막 예는 사용할 수 있습니다,표준’른이 정식’큐브와 롤업 혼합과 함께 직접 표현’à la carte’그룹화 세트입니다.
왜 우리는 어떤 집계에서 열을 결합하고 싶습니까?
여기서 두 열을 결합해야하는 일부 보고서에서는 두 열을 결합하는 집계를 선언하는 것이 유용합니다. 첫번째 예에서 우리는 결합년월 롤업의 영향을 제한하는 합계를 다만 각 지역,
|
1
2
3
4
5
6
7
|
–을 얻을 위한 합계 각 영역만 합계 각 지역 또는 올해
선택 t. 지역,t.영토로 이름,수익으로 합계(TotalDue),
datepart(yyyy,OrderDate)AS,Datepart(mm,OrderDate)AS
판매에서.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T s.TerritoryID=T.TerritoryID
그룹 t., t.이름,롤업
((부분(년,주문일),부분(mm,주문일)))
|
는 추가 부류는 롤업에 절을 했다의 영향을 제한하는 집계하여 그 영토와 같습니다. 그(것)들을 밖으로 남겨두고,당신은 각 년 동안 합계를 얻는다.
|
1
2
3
4
5
6
7
8
9
10
|
–을 얻을 각 연도에 대한 합계에서 각각의 영역뿐만 아니라 합계
–각 영역
— 없음에 대한 합계 각 지역
선택 t. 지역,t.영토로 이름,수익으로 합계(TotalDue),
datepart(yyyy,OrderDate)AS,Datepart(mm,OrderDate)AS
판매에서.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T s.TerritoryID=T.TerritoryID
그룹 t., t.이름,롤업
(부분(년,주문일),부분(mm,주문일))
|
이 매우 유용할 수 있습에 대한 특정한 데이터이다. 우리는 여기에 열을 결합 할 필요가 피했다. 을 하는 경우,큐브 및 이 약관을 위해 지역에 사용되는 같은 단어를’북부’또는’남’설명하는 영역에 둘 이상의 지역에서,당신은 몇 가지 이상한 집계에 적용되는’북부의’영토는 관련이 없습니다. 열을 결합하면이를 피할 수 있습니다.
‘단품’큐브를 수행하는 방법보다 그룹화 세트에 더 많은 것이 있습니까?나는이 질문을하는 것에 대해 부끄러워 할 것이라고 확신하지 못한다. SQL:1999 년의 그룹화 세트를 제공하는 풍부한 구문을 재귀할 수 있는 집계의 조합이 열리고 정의하는 모든 종류의 비전을 제공하는 보고서를 열다. 집계는 중첩될 수 있으며 롤업 내에 큐브를 중첩하고 큐브 내에 롤업을 중첩할 수 있습니다. 이에 대한 자세한 내용을 보려면 전문가 간행물을 읽어야합니다.
grouping()및 Grouping_ID()함수가 제공되는 이유는 무엇입니까?
열이 집계임을 나타 내기 위해 NULL 을 사용하는 것은 실제로 좋은 생각이 아닙니다. 문제는 경우,그룹화 열 null 값이 있는 모든 null 값이 동일한 것으로 간주되어 하나의 NULL 그룹의 가장으로 요약입니다. 원본 데이터에서 NULL 값의 명백한 어려움을 해결하기 위해 Grouping()및Grouping_ID()의 두 가지 함수가 제공됩니다.
Grouping()기능이 통과 열의 이름에 참여한 롤업,큐브 또는 그룹을 설정합니다. 이 행이 널 값이’모두’를 의미하는이 열에 대한 요약인지 또는 값이 포함되어 있는지 여부는 0 을 반환합니다.
GROUPING_ID 함수는 GROUP BY list 의 표현식과 정확히 일치해야하는 목록을 전달합니다. GROUPING_ID 는 각각의 요약 열의 비트 맵으로 생성됩니다. 는 경우,예를 들어 영역 열 NULL 의’모든’영토보다는 이름의 영토,그리고 그것으로 나열되어 있는 두 번째 열,그 두 번째 비트에서 왼쪽 설정합니다. 그런 다음이 정수가 반환됩니다.
Grouping_ID()>0)는 경우에,보조,다음을 제외에서 어떠한 추가 그룹으로 조작입니다.
그것은 일반적으로 좋은 것으로 간주하는 연습을 포함한 비트 컬럼에 대한 모든 치수(이러한’영토’또는’지역’우리의 예에서)설정되는 경우 행은 요약하는 차원과 함께Grouping_ID()값을 돕기 위해 어떠한 그룹의 결과입니다.
을 설명하는 방법으로 Grouping_ID 작품을 실제로,우리는 여기 얻을 보는 방법으로는 비트에 Grouping_ID 설정에 따라 형식의 요약. 우리는 비트를 보여주기 위해 Phil Factor 의 함수 ToBinaryString 을 사용할 것입니다.
|
1
2
3
4
5
6
7
8
9
|
선택 t. 지역,t.영토로 이름,수익으로 합계(TotalDue),
datepart(yyyy,OrderDate)AS,datepart(mm,OrderDate)AS,
오른쪽(
dbo.ToBinaryString(–목록은 모든 그룹으로 항목은
Grouping_ID(t., t.이름 부분(년,주문일),부분(mm,주문일))
),4)-그냥 사용하여 마지막 네 캐릭터로 우리는 네 개의 열이 우리의 목록에. 판매에서
.SalesOrderHeader s
INNER JOIN Sales.T.TerritoryID=T.TerritoryID
큐브에 의한 그룹(t.,t.이름 부분(년,주문일),부분(mm,주문일))
|
이 제공(의 샘플론)…
