- Eh? Cosa sono il RAGGRUPPAMENTO SET, CUBO e ROLLUP in SQL?
- Perché ROLLUP o CUBE mi sarebbero utili?
- Sono questi SQL standard o sono una cosa solo Microsoft?
- Posso escludere una o più colonne dal ROLLUP?
- Quali sono i gruppi di GRUPPI allora? Dovrei sapere di loro?
- Perché dovremmo voler combinare le colonne in qualsiasi aggregazione?
- C’è di più nel RAGGRUPPARE I SET che un modo di fare cubi ‘à la carte’?
- Perché sono fornite le funzioni Grouping () e Grouping_ID ()?
- Eh? Cosa sono il RAGGRUPPAMENTO SET, CUBO e ROLLUP in SQL?
- Perché ROLLUP o CUBE mi sarebbero utili?
- Sono questi SQL standard o sono solo una cosa di Microsoft?
- Posso escludere una o più colonne dal ROLLUP?
- Quali sono i gruppi di RAGGRUPPAMENTO? Dovrei sapere di loro?
- Perché dovremmo voler combinare le colonne in qualsiasi aggregazione?
- C’è più per RAGGRUPPARE I SET che un modo di fare cubi’ à la carte’?
- Perché sono fornite le funzioni Grouping () e Grouping_ID ()?
Eh? Cosa sono il RAGGRUPPAMENTO SET, CUBO e ROLLUP in SQL?
CUBE, ROLLUP e GROUPING SET sono operatori opzionali della clausola GROUP BY dell’istruzione SELECT per eseguire report con grandi quantità di informazioni. Consentono di eseguire diverse operazioni di GRUPPO in un’unica istruzione, risparmiando potenzialmente molto tempo e sforzi computazionali. Possono fornire tutte le informazioni necessarie per il reporting, inclusi i totali, fornendo buone prestazioni su tabelle di grandi dimensioni e aiutando l’ottimizzatore di query a elaborare un buon piano di esecuzione.
Le righe extra ‘super-aggregate’ forniscono valori di riepilogo, consentendo in tal modo di avere diverse ‘aggregazioni’ come SUM() o MAX() all’interno di un risultato. I NULL all’interno di queste righe nel risultato sono intesi a significare “tutti” piuttosto che “sconosciuti”. Ti consente di ottenere tutte le aggregazioni di cui hai bisogno in un passaggio attraverso la tabella. A causa della presenza di righe extra nei risultati, vengono fornite funzioni extra GROUPING() e GROUPING_ID() per indicare queste righe extra ‘super-aggregate’ e quali colonne vengono aggregate.
Questo ha molto senso se si dispone di un’applicazione che deve eseguire diversi report senza calcoli aggiuntivi o senza tornare al database: si ha tutto il necessario in un unico risultato.
Prendi questo esempio standard di un ROLLUP (sto usando AdventureWorks 2012 qui)..
|
1
2
3
4
5
6
|
SELEZIONARE t. COME regione, t.nome del territorio, sum(TotalDue) COME entrate,
datepart (“yyyy, Dataordine) COME , datepart(mm, Dataordine) COME
DALLE Vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T. TerritoryID
GRUPPO PER t., t.nome, datepart (“yyyy, Dataordine), datepart(mm, Dataordine)
CON CUMULATIVO
|
così Come semplice GRUPPO di righe di aggregazione, con il totale dovuto per ogni mese, che si potrebbe ottenere con un semplice raggruppamento, si ottiene anche parziale o super-righe di aggregazione, e anche una riga del totale complessivo. (ecco l’inizio del risultato)
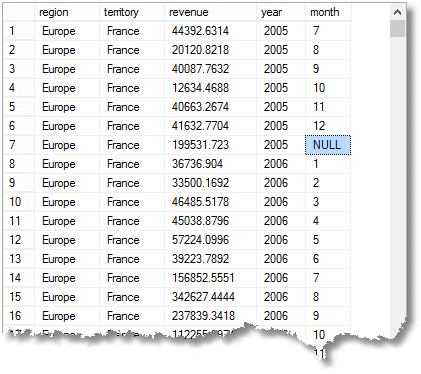
Quel NULL che ho evidenziato significa che la riga è un aggregato per “tutti” i mesi del 2005 in Francia (parte della regione Europea)
Oltre a tutto questo, ottieni il totale dovuto per ogni anno, per ogni territorio e gruppo territoriale, così come il totale totale dovuto. (dalla fine)
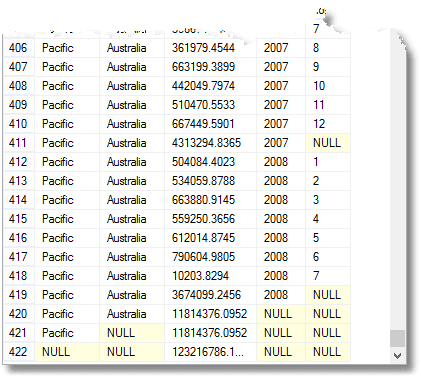
Quei NULL significano “Tutti”, ricorda. L’ultima riga è il totale generale, e sopra di esso è il totale per la regione del Pacifico. Sopra questo è il contributo dell’Australia alla regione del Pacifico. La quarta fila dal basso è il contributo 2008 dell’Australia. Il numero di raggruppamenti restituito è superiore al numero di espressioni nell’elenco degli elementi compositi fornito all’istruzione GROUP BY.
Per ottenere lo stesso effetto senza l’uso cumulativo, si avrebbe bisogno di fare qualcosa di simile a questo (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
CON myGrouping (region, territory, totalDue,,)
COME ( SELEZIONA t., t.name, somma (TotalDue) COME entrate,
datepart(aaaa, OrderDate) COME , datepart(mm, OrderDate) COME
DALLE vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T. TerritoryID
GRUPPO PER t.name, t. datepart (“yyyy, Dataordine), datepart(mm, Dataordine))
SELEZIONARE una Regione, di un territorio, totalDue, ,
DA myGrouping
UNIONE
SELEZIONARE una Regione, di un territorio, sum(totalDue), NULL
DA myGrouping GRUPPO DA regione a Regione, territorio,
UNIONE
SELEZIONARE una Regione, di un territorio, sum(totalDue), NULL, NULL
DA myGrouping GRUPPO DA regione a Regione, territorio
UNIONE
SELEZIONARE una Regione, NULL, sum(totalDue), NULL, NULL
DA myGrouping GRUPPO DA regione a Regione
UNIONE
SELECT NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.name, datepart(aaaa,OrderDate),datepart (mm,OrderDate))’
|
Questa nuova sintassi consente alcune funzionalità extra. Ricorda anche che l’ordine delle colonne influisce sui raggruppamenti di output del ROLLUP e può influire sul numero di righe nel set di risultati.
Il CUBO fa la stessa cosa generale ma, invece di fornire una gerarchia di totali in righe super-aggregate ordinate, fornisce tutte le permutazioni “super-aggregate” (righe “simmetriche super-aggregate”), le cosiddette righe di tabulazione incrociata. Se volessi sapere quale territorio ha dato il maggior numero di ordini a marzo o quale territorio ha eseguito meno bene nel 2006, allora avresti bisogno di un CUBO. Stai fornendo tutte le possibili sommatorie nel risultato.
Il SET DI RAGGRUPPAMENTO consente di ottimizzare il risultato per fornire informazioni più specializzate al di là del CUBO. Può fornire informazioni di riepilogo sulle combinazioni di dimensioni. Potresti ottenere esattamente lo stesso risultato del nostro esempio di ROLLUP usando I SET DI RAGGRUPPAMENTO, ma con molta più digitazione.
|
1
2
3
4
5
6
7
8
9
10
|
SELEZIONARE t. COME regione, t.nome del territorio, sum(TotalDue) COME entrate,
datepart (“yyyy, Dataordine) COME , datepart(mm, Dataordine) COME
DALLE Vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T.TerritoryID
GRUPPO DA INSIEMI di RAGGRUPPAMENTO(
(T. T. nome,datepart (“yyyy, Dataordine), datepart(mm, Dataordine)),
(T. T. nome,datepart (“yyyy, Dataordine) ),
(T. T. nome),
(T.),
())
|
Questo è solo per mostrare come essi si riferiscono. In realtà, si ricorrerebbe a GRUPPI DI GRUPPI per ottenere risultati impossibili con ROLLUP o CUBE.
Quasi tutti questi riepiloghi possono essere ottenuti usando solo GROUP BY, ma solo raggruppando ripetutamente il risultato di un GROUP BY o facendo più di un passaggio attraverso i dati.
Quando si utilizzano SET CUBO, ROLLUP o RAGGRUPPAMENTO, non è possibile utilizzare la parola chiave DISTINCT nelle espressioni aggregate, come AVG (DISTINCT column_name), COUNT (DISTINCT column_name) e SUM (DISTINCT column_name)
Perché ROLLUP o CUBE mi sarebbero utili?
ROLLUP e CUBE hanno avuto il loro periodo di massimo splendore prima di SSAS. Erano utili per fornire lo stesso tipo di servizi offerti dal cubo in OLAP. Ha ancora i suoi usi però. In AdventureWorks, è eccessivo, ma se si gestiscono grandi volumi di dati è necessario passare i dati solo una volta e fare il più possibile sui dati che sono stati aggregati. Gli eventi accaduti in passato non possono essere modificati, quindi è raramente necessario conservare i dati storici su un sistema OLTP attivo. Invece, è sufficiente conservare i dati aggregati al livello di dettaglio (’granularità’) richiesto per tutti i report prevedibili.
Immagina di essere responsabile della segnalazione su un interruttore telefonico che ha due milioni di chiamate al giorno. Se si mantengono tutte queste chiamate sul server OLTP, si troverà presto SQL Server che lavora sui report di utilizzo. È necessario conservare le informazioni di chiamata originale per un periodo di tempo legale, ma si determina dal business che sono, al massimo, solo interessati al numero di chiamate in un minuto. Quindi è stato ridotto il requisito di archiviazione sul server OLTP a 1.4% di quello che era e i record delle chiamate possono essere archiviati su un altro server SQL per query ad hoc e dichiarazioni del cliente. Che è probabile che sia un risparmio vale la pena fare. Le clausole CUBE e ROLLUP consentono di memorizzare anche i totali di riga, i totali di colonna e i totali generali senza dover eseguire una scansione della tabella o dell’indice cluster della tabella di riepilogo.
Finché le modifiche non vengono apportate retrospettivamente a questi dati e tutti i periodi di tempo sono completi, non è mai necessario ripetere o modificare le aggregazioni in base ai periodi di tempo passati, anche se i totali generali dovranno essere sovrascritti!.
Facciamo finta, ma usando AdventureWorks2012 in modo da poter giocare insieme.
In primo luogo, creeremo la tabella riassuntiva gram.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
IF EXISTS (SELECT * FROM tempdb.sys.le tabelle di CUI il nome COME ‘#AggregationTable%’)
DROP TABLE #aggregationTable –eliminare la tabella temporanea (se esiste)
ANDARE
SELEZIONA
identità(INT,1,1), – in modo da poter avere un unica colonna
t. COME regione, t.nome del territorio, sum(TotalDue) COME entrate,
datepart (“yyyy, Dataordine) COME , datepart(mm, Dataordine), COME:
il raggruppamento(t.nome isNameGroup, –questo si riferisce a TUTTI i territori
il raggruppamento(t.) COME isGroupGroup,–questo si riferisce a TUTTI i continenti
il raggruppamento(datepart (“yyyy, Dataordine)) COME isYearGroup,–questo si riferisce a TUTTI gli anni
il raggruppamento(datepart(mm, Dataordine)) COME isMonthGroup,–questo si riferisce a TUTTI i mesi
Grouping_ID (t.nome,t.,
datepart (“yyyy, Dataordine),datepart(mm, Dataordine)) COME isGroupingRow
– questo è un extra non riga di dati contenente i dati aggregati
IN #AggregationTable
DALLE Vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T.TerritoryID
RAGGRUPPA PER t.name, t., datepart(aaaa, OrderDate), datepart (mm, OrderDate)
CON ROLLUP
|
Si noti che stiamo aggiungendo colonne ‘bit’ aggiuntive che ci dicono quali righe contengono le righe di riepilogo. Se li aggiungi erroneamente a qualsiasi ulteriore aggregazione, otterrai risultati seriamente gonfiati. Non è possibile utilizzare Grouping() o Grouping_ID sul risultato salvato, ovviamente, quindi è necessario fornire qualcosa al suo posto.
Ora siamo in grado di produrre la tabella pivot molto veloce
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
— ora siamo in grado di creare una semplice tabella pivot con riga e
— i totali delle colonne
SELEZIONARE Territorio,
sum(CASE when 2005, POI entrate ELSE 0 END), COME:
sum(CASE QUANDO il 2006, e QUINDI entrate ELSE 0 END), COME:
sum(CASO 2007 QUANDO POI entrate ELSE 0 END), COME:
sum(CASE QUANDO il 2008 POI entrate ELSE 0 END), COME:
sum(entrate) COME
DA #AggregationTable
DOVE isGroupingrow =0
GROUP BY territorio
UNIONE
SELEZIONARE ‘Totale’, sum(CASE when 2005, POI entrate ELSE 0 END), COME:
sum(CASE QUANDO il 2006, e QUINDI entrate ELSE 0 END) COME ,
sum(CASO 2007 QUANDO POI entrate ELSE 0 END) COME ,
sum(CASE QUANDO il 2008 POI entrate ELSE 0 END), COME:
sum(entrate) COME
DA #AggregationTable
DOVE isYearGroup =0 E isMonthGroup=1
|
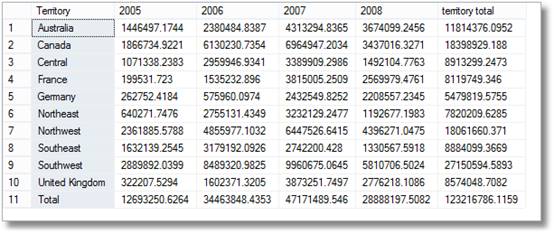
Quindi ci sono brevi sorrisi da parte dei manager nel vedere questo, ma poi dicono brillantemente ‘Sono sicuro che ho anche chiesto una ripartizione per territorio al mese
Con una breve risatina, fai questo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELEZIONA
datename(MESE,dateadd(MESE, ,’01 dec 2000′)), COME:
sum(CASE territorio, QUANDO ‘Australia’, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Canada’ QUINDI entrate ELSE 0 END) COME ,
sum(CASE territorio, QUANDO ‘Centrale’, POI entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Francia’, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Germania’, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘nord-est’, ALLORA entrate ELSE 0 END) COME ,
sum(CASE territorio QUANDO “nord-ovest”, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO la “sud-est”, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO la “sud-ovest”, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Regno Unito’, ALLORA entrate ELSE 0 END), COME:
sum(entrate) COME
DA #AggregationTable
DOVE isGroupingrow =0
GRUPPO per mese
UNIONE
SELEZIONA
‘Totale’,
sum(CASE territorio, QUANDO ‘Australia’, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio ‘Canada’ QUINDI entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Centrale’, POI entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Francia’, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Germania’, ALLORA entrate ELSE 0 END) COME ,
sum(CASE territorio, QUANDO ‘nord-est’, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO la “nord-ovest”, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO la “sud-est”, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO la “sud-ovest”, ALLORA entrate ELSE 0 END), COME:
sum(CASE territorio, QUANDO ‘Regno Unito’, ALLORA entrate ELSE 0 END), COME:
sum(entrate) COME
DA #AggregationTable
DOVE isGroupingrow =0
|
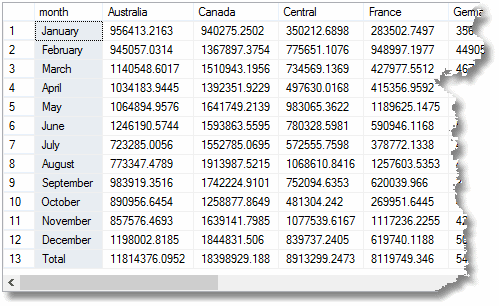
Ma se avessi usato CUBE invece di Rollup, quell’ultima riga “totale” sarebbe già stata calcolata. In un esempio reale che costerebbe tempo facendo il rapporto. Si può fare un CUBO su un massimo di dieci dimensioni; anche se tendono ad irrobustire l’aggregazione, non sono troppo costosi.
Sono questi SQL standard o sono solo una cosa di Microsoft?
Questi sono ora standard ANSI SQL dal 1999, anche se CON CUBE e CON ROLLUP sono stati introdotti per la prima volta da Microsoft. Questa inclusione è alquanto sorprendente in quanto introducono un secondo significato, ‘all‘, per il valore NULL oltre a’unknown’. Quando Microsoft ha introdotto per la prima volta CUBE e ROLLUP, la sintassi era leggermente diversa, ma entrambe le forme sono consentite in SQL Server. Solo uno stile di sintassi può essere utilizzato in una singola istruzione SELECT, e si dovrebbe usare la sintassi conforme ISO per tutti i nuovi lavori.
Posso escludere una o più colonne dal ROLLUP?
Se vuoi! Immaginate che io non voglio un super-totale aggregato per tutte le regioni (t.)
|
1
2
3
4
5
6
|
SELEZIONARE t. COME regione, t.nome del territorio, sum(TotalDue) COME entrate,
datepart (“yyyy, Dataordine) COME , datepart(mm, Dataordine) COME
DALLE Vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T. TerritoryID
GRUPPO PER t., ROLLUP (t.name, datepart (aaaa, OrderDate), datepart(mm, OrderDate))
|
Qui stiamo usando la sintassi conforme ANSI SQL 2006. Puoi fare la stessa cosa con un cubo. Non ho mai trovato un uso pratico per questo, ma potresti incontrarlo
Quali sono i gruppi di RAGGRUPPAMENTO? Dovrei sapere di loro?
SET DI RAGGRUPPAMENTO significa che stai chiedendo a SQL di raggruppare il risultato più volte. È possibile utilizzare la sintassi dei GRUPPI per specificare con precisione quali aggregazioni calcolare. Ecco un esempio.
|
1
2
3
4
5
6
|
SELEZIONARE t. COME regione, t.nome del territorio, sum(TotalDue) COME entrate,
datepart (“yyyy, Dataordine) COME , datepart(mm, Dataordine) COME
DALLE Vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s.TerritoryID = T. TerritoryID
GROUP BY t., INSIEMI di RAGGRUPPAMENTO(CUMULATIVO(t.nome),
CUMULATIVO(datepart (“yyyy, Dataordine), datepart(mm, Dataordine)))
|
Qui si sta chiedendo per la ripartizione in base al territorio di gruppo per ogni mese di ogni anno, il mese e l’anno totali, seguita da una sintesi totale dal nome del territorio, ma senza un gran totale. A differenza del ROLLUP, si ottiene lo stesso risultato indipendentemente dall’ordine delle colonne all’interno di ciascun SET di RAGGRUPPAMENTO e dall’ordine dei SET di RAGGRUPPAMENTO.
I SET DI RAGGRUPPAMENTO possono darti esattamente ciò che CUBE e ROLLUP ti danno e molto altro ancora. Come puoi vedere con questo ultimo esempio, puoi usare il CUBO standard’ table d’hôte ‘e il ROLLUP mescolati insieme a SET di RAGGRUPPAMENTO ‘à la carte ‘ espressi direttamente.
Perché dovremmo voler combinare le colonne in qualsiasi aggregazione?
Dove due colonne devono essere combinate in alcuni report, è utile dichiarare un’aggregazione che combina due colonne. Nel primo esempio abbiamo combinare anno e il mese per il rollup, avendo l’effetto di limitare i totali per il proprio territorio,
|
1
2
3
4
5
6
7
|
–ottenere i totali per ogni territorio, non solo i totali per ogni regione o anno
SELEZIONARE t. COME regione, t.nome COME territorio, somma (TotalDue) COME entrate,
datepart(aaaa, OrderDate) COME , datepart(mm, OrderDate) COME
DALLE vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.SalesTerritory T A s.TerritoryID = T. TerritoryID
GROUP BY t., t.nome, ROLLUP
((datepart (“yyyy, Dataordine), datepart(mm, Dataordine)))
|
Che extra staffa nel CUMULATIVO clausola ha avuto l’effetto di limitare le aggregazioni al proprio territorio e mese/anno. Lasciarli fuori, e si ottiene totali per ogni anno.
|
1
2
3
4
5
6
7
8
9
10
|
–ottenere i totali per ogni anno all’interno di ogni territorio e i totali
–per ogni territorio
— no i totali per ogni regione
SELEZIONARE t. COME regione, t.nome COME territorio, somma (TotalDue) COME entrate,
datepart(aaaa, OrderDate) COME , datepart(mm, OrderDate) COME
DALLE vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T. TerritoryID
GRUPPO PER t., t.name, ROLLUP
(datepart(aaaa, OrderDate), datepart(mm, OrderDate))
|
Questo può essere molto utile per alcuni dati. Abbiamo evitato di dover combinare le colonne qui. Se dovessi fare un CUBO e i termini per i territori usassero parole come “Nord” o ” Sud “per descrivere un territorio in più di una regione, avresti alcune bizzarre aggregazioni che si applicano ai territori “settentrionali” che non sono correlati. Combinando le colonne, eviteresti questo.
C’è più per RAGGRUPPARE I SET che un modo di fare cubi’ à la carte’?
Non sono sicuro che sarei timido nel fare questa domanda. SQL:I SET DI RAGGRUPPAMENTO del 1999 forniscono una ricca sintassi ricorsiva che consente di aggregare combinazioni di colonne e definire tutti i tipi di report esoterici che forniscono fino a dieci dimensioni. Le aggregazioni possono essere nidificate ed è possibile nidificare CUBI all’interno ROLLUP e ROLLUP nido all’interno cubi. Avrai bisogno di leggere una pubblicazione specialistica per saperne di più su questo.
Perché sono fornite le funzioni Grouping () e Grouping_ID ()?
Non è davvero una buona idea usare NULL per significare che una colonna è un’aggregazione. Il problema è che, se una colonna di raggruppamento contiene valori null, tutti i valori null sono considerati uguali e inseriti in un singolo gruppo NULL che si maschera come un riepilogo. Per aggirare l’ovvia difficoltà dei valori NULL nei dati originali, vengono fornite due funzioni: Raggruppamento () e Grouping_ID().
Alla funzione Grouping() viene passato il nome di una colonna che ha partecipato al ROLLUP, al CUBO o al SET di RAGGRUPPAMENTO. Restituisce zero se questa riga è un riepilogo per questa colonna con un valore NULL che significa ‘ all ‘ o se contiene un valore.
Alla funzione GROUPING_ID viene passato un elenco che deve corrispondere esattamente all’espressione nell’elenco GROUP BY. GROUPING_ID viene creato come bitmap delle rispettive colonne di riepilogo. Se, ad esempio, la colonna territory ha un valore NULL che significa “tutti” territori anziché un nome di un territorio ed è elencata come seconda colonna, viene impostato il secondo bit da sinistra. Questo intero viene quindi restituito.
Grouping_ID()viene generalmente utilizzato per indicare se la riga è un’aggregazione primaria o secondaria (0 o > 0) e, se secondaria, quindi esclusa da qualsiasi ulteriore GRUPPO TRAMITE manipolazione.
Di solito è considerata una buona pratica includere una colonna di bit per ogni dimensione (come ‘Territory’ o ‘Region’ nel nostro esempio) impostata se la riga è un riepilogo per quella dimensione, insieme a un valoreGrouping_ID() per aiutare qualsiasi ulteriore raggruppamento del risultato.
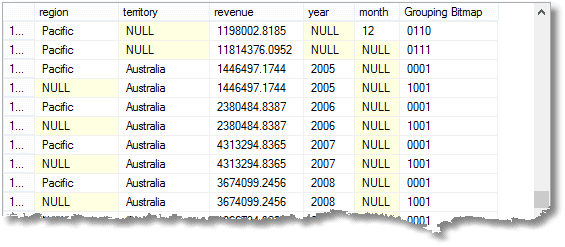
Per illustrare il modo in cui Grouping_ID funziona effettivamente, qui possiamo osservare il modo in cui i bit nel Grouping_ID sono impostati in base al tipo di riepilogo. Useremo la funzione ToBinaryString di Phil Factor per mostrare i bit.
|
1
2
3
4
5
6
7
8
9
|
SELEZIONARE t. COME regione, t.nome COME territorio, somma (TotalDue) COME entrate,
datepart(aaaa, OrderDate) COME , datepart(mm, OrderDate) COME ,
destra (
dbo.ToBinaryString (list elenca tutti i gruppi per elementi così come sono
Grouping_ID(t., t.name, datepart(aaaa, OrderDate),datepart (mm, OrderDate))
),4) AS use basta usare gli ultimi quattro caratteri come abbiamo quattro colonne nella nostra lista.
DALLE vendite.SalesOrderHeader s
INTERNO UNIRE le vendite.Salesterritorio T SU s. TerritoryID = T. TerritoryID
GRUPPO PER CUBO(t., t.name, datepart(aaaa, OrderDate),datepart(mm, OrderDate))
|
Questo dà (solo un esempio ovviamente)