La struttura del DNA fornisce un meccanismo per l’ereditarietà
I geni trasportano informazioni biologiche che devono essere copiate con precisione per la trasmissione alla generazione successiva ogni volta che una cellula si divide per formare due cellule figlie. Due domande biologiche centrali sorgono da questi requisiti: come possono le informazioni per specificare un organismo essere trasportate in forma chimica e come vengono copiate accuratamente? La scoperta della struttura della doppia elica del DNA è stata un punto di riferimento nella biologia del ventesimo secolo perché ha immediatamente suggerito risposte a entrambe le domande, risolvendo così a livello molecolare il problema dell’ereditarietà. Discutiamo brevemente le risposte a queste domande in questa sezione, e li esamineremo in modo più dettagliato nei capitoli successivi.
Il DNA codifica le informazioni attraverso l’ordine, o la sequenza, dei nucleotidi lungo ciascun filamento. Ogni base-A, C, T o G—può essere considerata come una lettera in un alfabeto di quattro lettere che enuncia messaggi biologici nella struttura chimica del DNA. Come abbiamo visto nel Capitolo 1, gli organismi differiscono l’uno dall’altro perché le rispettive molecole di DNA hanno diverse sequenze nucleotidiche e, di conseguenza, portano diversi messaggi biologici. Ma come viene utilizzato l’alfabeto nucleotidico per creare messaggi, e cosa spiegano?
Come discusso sopra, era noto ben prima che la struttura del DNA fosse determinata che i geni contengono le istruzioni per la produzione di proteine. I messaggi di DNA devono quindi codificare in qualche modo le proteine (Figura 4-6). Questa relazione rende immediatamente il problema più facile da capire, a causa del carattere chimico delle proteine. Come discusso nel capitolo 3, le proprietà di una proteina, che sono responsabili della sua funzione biologica, sono determinate dalla sua struttura tridimensionale e la sua struttura è determinata a sua volta dalla sequenza lineare degli amminoacidi di cui è composta. La sequenza lineare di nucleotidi in un gene deve quindi in qualche modo precisare la sequenza lineare di aminoacidi in una proteina. L’esatta corrispondenza tra l’alfabeto nucleotidico di quattro lettere del DNA e l’alfabeto aminoacidico di venti lettere delle proteine-il codice genetico—non è evidente dalla struttura del DNA, e ci sono voluti più di un decennio dopo la scoperta della doppia elica prima che fosse elaborata. Nel capitolo 6 descriviamo questo codice in dettaglio nel corso dell’elaborazione del processo, noto come espressione genica, attraverso il quale una cellula traduce la sequenza nucleotidica di un gene nella sequenza amminoacidica di una proteina.

Figura 4-6
La relazione tra le informazioni genetiche trasportate nel DNA e nelle proteine.
L’insieme completo di informazioni nel DNA di un organismo è chiamato il suo genoma, e porta le informazioni per tutte le proteine che l’organismo potrà mai sintetizzare. (Il termine genoma è anche usato per descrivere il DNA che trasporta queste informazioni.) La quantità di informazioni contenute nei genomi è sconcertante: ad esempio, una tipica cellula umana contiene 2 metri di DNA. Scritto nell’alfabeto nucleotidico di quattro lettere, la sequenza nucleotidica di un gene umano molto piccolo occupa un quarto di una pagina di testo (Figura 4-7), mentre la sequenza completa di nucleotidi nel genoma umano riempirebbe più di mille libri delle dimensioni di questo. Oltre ad altre informazioni critiche, porta le istruzioni per circa 30.000 proteine distinte.

Figura 4-7
La sequenza nucleotidica del gene β-globina umano. Questo gene trasporta le informazioni per la sequenza aminoacidica di uno dei due tipi di subunità della molecola dell’emoglobina, che trasporta l’ossigeno nel sangue. Un gene diverso, l’α-globina (altro…)
Ad ogni divisione cellulare, la cellula deve copiare il suo genoma per passarlo a entrambe le cellule figlie. La scoperta della struttura del DNA ha anche rivelato il principio che rende possibile questa copia: poiché ogni filamento di DNA contiene una sequenza di nucleotidi che è esattamente complementare alla sequenza nucleotidica del suo filamento partner, ogni filamento può fungere da modello, o stampo, per la sintesi di un nuovo filamento complementare. In altre parole, se designiamo i due filamenti di DNA come S e S’, il filo S può servire come modello per creare un nuovo filo S’, mentre il filo S’ può servire come modello per creare un nuovo filo S (Figura 4-8). Pertanto, le informazioni genetiche nel DNA possono essere copiate con precisione dal processo meravigliosamente semplice in cui il filamento S si separa dal filamento S’, e ogni filamento separato funge quindi da modello per la produzione di un nuovo filamento partner complementare identico al suo precedente partner.
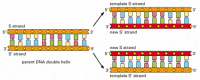
Figura 4-8
DNA come modello per la propria duplicazione. Poiché il nucleotide A si accoppia con successo solo con T e G con C, ogni filamento di DNA può specificare la sequenza di nucleotidi nel suo filamento complementare. In questo modo, il DNA a doppia elica può essere copiato con precisione. (piu…)
La capacità di ogni filamento di una molecola di DNA di agire come modello per la produzione di un filamento complementare consente a una cellula di copiare, o replicare, i suoi geni prima di trasmetterli ai suoi discendenti. Nel prossimo capitolo descriviamo l’elegante macchinario che la cella utilizza per svolgere questo enorme compito.