- Eh? Mik csoportosítás SET, CUBE and ROLLUP az SQL?
- miért lenne hasznos számomra a ROLLUP vagy a CUBE?
- ezek a szabványos SQL vagy csak Microsoft-dolog?
- kizárhatok egy vagy több oszlopot a ROLLUPBÓL?
- mik azok a csoportosítási készletek? Tudnom kellene róluk?
- Miért szeretnénk oszlopokat kombinálni bármilyen összesítésben?
- van több csoportosítás készletek, mint egy módja ennek “à la carte” kockák?
- miért vannak megadva a függvények csoportosítása() és Grouping_ID ()?
- Eh? Mik csoportosítás SET, CUBE and ROLLUP az SQL?
- miért lenne hasznos számomra a ROLLUP vagy a CUBE?
- ezek a szabványos SQL vagy csak Microsoft-dolog?
- kizárhatok egy vagy több oszlopot a ROLLUPBÓL?
- mik azok a csoportosítási készletek? Tudnom kellene róluk?
- Miért szeretnénk oszlopokat kombinálni bármilyen összesítésben?
- van-e több csoportosítás, mint az “à la carte” kockák készítésének módja?
- miért vannak megadva a függvények csoportosítása() és Grouping_ID ()?
Eh? Mik csoportosítás SET, CUBE and ROLLUP az SQL?
CUBE, ROLLUP and GROUPING SET are optional operator of the GROUP BY clause of the SELECT statement for doing reports with large amount information. Ezek lehetővé teszik, hogy több csoport műveletek egy nyilatkozatot, potenciálisan megtakarítás sok időt, számítási erőfeszítést. A jelentéstételhez szükséges összes információt megadhatják, beleértve az összesített adatokat is, miközben jó teljesítményt nyújtanak a nagy táblázatok felett, valamint segítenek a Lekérdezésoptimalizálónak egy jó végrehajtási terv kidolgozásában.
Az extra szuper-összesített’ sorok nyújt összefoglaló értékeket, ezáltal lehetővé teszi, hogy több ‘kombinációjának’ mint például a SUM (), vagy MAX() belül az egyik eredmény. Az eredmény ezen sorain belüli nullák célja, hogy “mindent” jelentsenek, nem pedig “ismeretlent”. Ez lehetővé teszi, hogy az összes szükséges aggregációt egy lépésben az asztalon keresztül kapja meg. Mivel az eredményekben extra sorok vannak, az extra függvények GROUPING() és GROUPING_ID() jelzik ezeket az extra “szuper-aggregált” sorokat, és mely oszlopokat összesítik.
Ez nagyon sok értelme van, ha van olyan alkalmazása, amelynek több jelentést kell futtatnia extra számítás nélkül vagy anélkül, hogy visszatérne az adatbázisba: mindent megtalál, amire szüksége van egy eredményben.
Vegyük ezt a standard példát egy ROLLUP (én használ AdventureWorks 2012 itt)..
|
1
2
3
/div>
4
5
6
|
t.name területként sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) mint
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T ON S. TerritoryID = T. TerritoryID
GROUP BY t., t.név, datepart(éééé, Rendelve), datepart(mm Rendelve)
– VAL ÖSSZESÍTŐ
|
valamint az egyszerű CSOPORT ÁLTAL összesített sorok, a teljes esedékes havonta, hogy egy egyszerű csoportosítása, akkor is kap részösszeg vagy a super-összesített sorok, továbbá egy nagy, összesen sor. (itt van az eredmény kezdete)
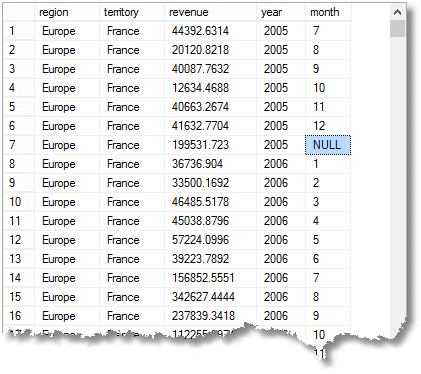
NULL, Hogy már highlit azt jelenti, hogy a sor egy összesített minden hónap 2005-ben Franciaországban (Európa része régió)
valamint az egész, a teljes következtében minden évben, minden egyes területre területi csoport, valamint a teljes összesen miatt. (a végén)
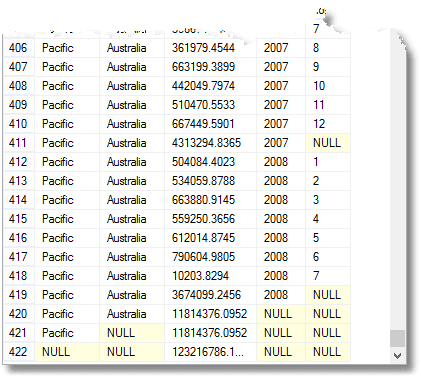
ezek a koponyák “mindent” jelentenek, emlékezz. Az utolsó sor a nagy teljes, felett pedig a csendes-óceáni régió teljes összege. Ezen felül Ausztrália hozzájárulása a csendes-óceáni régióhoz. Az alsó negyedik sor Ausztrália 2008-as hozzájárulása. A visszaadott csoportosítások száma Egy több, mint az összetett elemek listájában szereplő kifejezések száma, amelyeket a csoport nyilatkozattal szolgáltat.
ahhoz, Hogy ugyanaz a hatása, használata nélkül a rollup, hogy tennie kell valamit, mint ez (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
myGrouping (régió, terület, totalDue, ,)
AS (válassza a t., t.name, sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) mint
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T ON S. TerritoryID = T. TerritoryID
csoport t.name, t., datepart(ÉÉÉÉ, OrderDate), datepart(mm, OrderDate)))
válasszon régiót, területet, totalDue-t ,
MYGROUPING
UNION ALL
válasszon régiót, területet, összeget(totalDue), NULL
a Mygrouping csoportból régió , terület,
UNION ALL
UNION ALL válasszon régiót, területet, összeget(totaldue), null, null
a mygrouping csoportból régió szerint, terület
Union all
válassza ki a régiót, null, sum(TOTALDUE), null, null
a MYGROUPING csoport régió szerint
Union all
, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.name, datepart(yyyy,OrderDate),datepart (mm,OrderDate)))’
|
Ez az új szintaxis lehetővé teszi néhány extra funkciót. Ne feledje továbbá, hogy az oszlopsorrend befolyásolja a tekercselés kimeneti csoportjait, és befolyásolhatja az eredményhalmazban lévő sorok számát.
A kocka ugyanazt az Általános dolgot teszi, de ahelyett, hogy a rendezett szuper-aggregált sorokban az összes “szuper-aggregátum” permutációt (“szimmetrikus szuper-aggregátum” sorok) biztosítaná, az úgynevezett kereszt-tabulációs sorokat. Ha szeretné tudni, hogy melyik terület adta a legtöbb megrendelést márciusban, vagy melyik terület teljesített legkevésbé jól 2006-ban, akkor szüksége lenne egy kockára. Ön biztosítja az összes lehetséges összegzést az eredményben.
csoportosítás SET lehetővé teszi, hogy finomhangolása az eredmény, hogy több speciális információ felett és túl CUBE. Összefoglaló információkat nyújthat a méretek kombinációiról. Lehet kapni pontosan ugyanazt az eredményt, mint a mi ROLLUP példa segítségével csoportosítás készletek, de sokkal több gépelés.
|
1
2
3
4
5
6
7
8
9
10
|
VÁLASSZA t. MINT a régió t.a neve, MINT területén, sum(TotalDue), MINT a bevétel,
datepart(éééé, Rendelve), MINT , datepart(mm Rendelve), MINT a
A Értékesítés.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T S. TerritoryID = T.TerritoryID
CSOPORT CSOPORTOSÍTÁSA KÉSZLETEK(
(T. T. nevét,datepart(éééé, Rendelve), datepart(mm Rendelve)),
(T. T. nevét,datepart(éééé, Rendelve) ),
(T. T. neve),
(T.),
())
|
Ez csak megmutatni, hogy ők is vonatkoznak. A valóságban, akkor igénybe csoportosítása készletek, hogy az eredmények, amelyek lehetetlen a ROLLUP vagy kocka.
szinte az összes ilyen összefoglalók nyerhető segítségével csak csoport által, de csak többször csoportosítása az eredmény egy csoport által, vagy azáltal, hogy egynél több át az adatokat.
Ha kocka, ROLLUP vagy csoportosítási készleteket használ, akkor nem használhatja a különálló kulcsszót az összesített kifejezésekben, például AVG (különálló oszlop_név), COUNT (különálló oszlop_name), and SUM (különálló oszlop_name)
miért lenne hasznos számomra a ROLLUP vagy a CUBE?
ROLLUP and CUBE volt a fénykorát előtt SSAS. Hasznosak voltak az OLAP-I kocka által kínált hasonló létesítmények biztosításához. Még mindig megvannak a maga Felhasználási bár. Az AdventureWorks-ben ez túlzás, de ha nagy mennyiségű adatot kezel, akkor csak egyszer kell átadnia az adatait, és a lehető legtöbbet kell tennie az összesített adatokon. A múltban bekövetkezett eseményeket nem lehet megváltoztatni, ezért ritkán szükséges történelmi adatokat megőrizni egy aktív OLTP rendszeren. Ehelyett az összesített adatokat csak az összes előrelátható jelentéshez szükséges részletesség (“részletesség”) szintjén kell megőriznie.
képzelje el, hogy felelős a napi kétmillió hívással rendelkező telefonkapcsolón történő jelentésért. Ha megtartja ezeket a hívásokat az OLTP szerveren, hamarosan megtalálja az SQL Server-t, amely a használati jelentések alapján dolgozik. Meg kell őriznie az eredeti hívásinformációkat törvényes időtartamra, de az üzletből meghatározza, hogy legfeljebb egy perc alatt csak a hívások száma érdekli őket. Ezután csökkentette a tárolási követelmény az OLTP szerver 1.4% – A annak, ami volt, és a hívásrekordok archiválhatók egy másik SQL szerverre ad-hoc lekérdezésekhez és ügyfélnyilatkozatokhoz. Ez valószínűleg megtakarítást jelent, amit érdemes megtenni. A CUBE and ROLLUP záradékok lehetővé teszik, hogy a sorösszegeket, oszlopösszegeket és nagyösszegeket is tárolja anélkül, hogy táblázatot vagy fürtözött indexet kellene tennie, az összefoglaló táblázat beolvasása.
mindaddig, amíg ezen adatok visszamenőleges módosítása nem történik meg, és minden időtartam teljes, soha nem kell megismételnie vagy módosítania az aggregációkat a múltbeli időszakok alapján, bár a nagy összegeket túl kell írni!.
tegyünk úgy, mintha, de a AdventureWorks2012 segítségével játszhatsz együtt.
először létrehozzuk a gram összefoglaló táblázatot.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
HA LÉTEZIK (SELECT * FROM tempdb.sys.táblázatok, ahol a név, mint a ” #AggregationTable%”)
DROP TABLE # aggregationTable — törölje az ideiglenes tábla, ha létezik
GO
válassza
identity(INT,1,1) mint , –így lehet egy egyedi oszlop
t. mint Régió, t.name területként sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) as,
csoportosítás(t.name) mint isNameGroup, –ez vonatkozik minden területre
csoportosítás (t.), MINT isGroupGroup,–kapcsolódik ez az ÖSSZES kontinensen
csoportosítás(datepart(éééé, Rendelve)), MINT isYearGroup,–ez vonatkozik MINDEN év
csoportosítás(datepart(mm Rendelve)), MINT isMonthGroup,–ez vonatkozik MINDEN hónap
Grouping_ID (t.név,t.,
datepart(éééé, Rendelve),datepart(mm Rendelve)), MINT isGroupingRow
–ez egy plusz, nem adatokat tartalmazó sor összesített adatok
A #AggregationTable
A Értékesítés.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T S. TerritoryID = T.TerritoryID
csoport t.name, t., datepart(yyyy, OrderDate), datepart(mm, OrderDate)
|
vegye figyelembe, hogy extra ” bit ” oszlopokat adunk hozzá, amelyek megmondják, hogy mely sorok tartalmazzák az összefoglaló sorokat. Ha tévesen hozzá őket további aggregációk kapsz néhány komolyan felfújt eredményeket. Nem használhatja a Grouping() vagy a Grouping_ID fájlt a mentett eredményen, nyilvánvalóan, ezért valamit meg kell adnia helyette.
Most tudunk előállítani a kimutatástábla nagyon gyorsan
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
— most már készíthetünk egy egyszerű pivot tábla sor
— oszlop összesen
VÁLASSZA ki a Terület,
sum(ESET, AMIKOR 2005-BEN, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ESET, AMIKOR 2006 AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ESET, AMIKOR 2007 AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ESET, AMIKOR 2008-BAN, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(bevétel) MINT a
A #AggregationTable
HOL isGroupingrow =0
CSOPORT ÁLTAL a területén
UNION ALL
VÁLASSZA ki a “Teljes”, sum(ESET, AMIKOR 2005-BEN, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ESET, AMIKOR 2006 AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ESET, AMIKOR 2007 AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(abban az esetben, ha 2008 akkor bevétel ELSE 0 vége), mint,
sum(bevétel) mint
a #AggregationTable
ahol isYearGroup =0 és isMonthGroup=1
|
div >
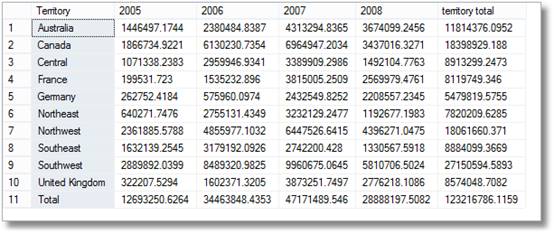
tehát a vezetők rövid mosollyal látják ezt, de aztán fényesen azt mondják: “biztos vagyok benne, hogy havonta területi bontást is kértem
egy rövid kuncogással, ezt csinálod.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
VÁLASSZA ki a
datename(HÓNAP,dateadd(HÓNAP, ,’01 dec 2000′)), MINT a ,
sum(AZ területe, AMIKOR ‘Ausztrália’, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Kanada” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Központi” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Franciaország” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Németország”, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Észak’, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe AMIKOR ‘Északnyugati, MAJD a bevételt MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Délkelet’, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Délnyugati, MAJD a bevételt MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Egyesült Királyság” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(bevétel) MINT a
A #AggregationTable
HOL isGroupingrow =0
CSOPORT ÁLTAL hónap
UNION ALL
VÁLASSZA ki a
‘Összes’,
sum(AZ területe, AMIKOR ‘Ausztrália’, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(az ESETBEN, AMIKOR területén “Kanada” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Központi” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Franciaország” AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(ÜGY területén, AMIKOR a “Németország”, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Észak’, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Északnyugati, MAJD a bevételt MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Délkelet’, AKKOR a bevétel MÁS, 0 VÉGÉN), MINT ,
sum(AZ területe, AMIKOR ‘Délnyugati, MAJD a bevételt MÁS, 0 VÉGÉN), MINT ,
sum(CASE territory WHEN ‘United Kingdom’ THEN revenue ELSE 0 END) AS ,
sum(revenue) AS
FROM #AggregationTable
WHERE isGroupingrow =0
|
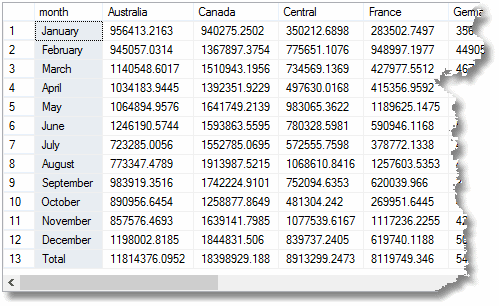
de ha a Cube-ot használta volna a Rollup helyett, akkor az utolsó “teljes” sor már kiszámításra kerül. Egy igazi példában, amely időt vesz igénybe a jelentés elkészítésében. Meg tudod csinálni egy kocka legfeljebb tíz dimenzióban; bár hajlamosak ömleszteni fel az aggregáció, nem túl költséges.
ezek a szabványos SQL vagy csak Microsoft-dolog?
ezek ma már szabványos ANSI SQL 1999-től, bár a CUBE and ROLLUP először vezették be a Microsoft. Ez a felvétel némileg meglepő, mivel egy második jelentést, ” all “- t vezetnek be az “ismeretlen” NULL érték mellett. Amikor a Microsoft először mutatta be a CUBE and ROLLUP-ot, a szintaxis kissé eltérő volt, de mindkét forma megengedett az SQL Serverben. Csak egy szintaxis stílus használható egyetlen SELECT utasítás, és akkor használja az ISO-kompatibilis szintaxis minden új munkát.
kizárhatok egy vagy több oszlopot a ROLLUPBÓL?
ha akarod! Képzelje el, hogy nem akartam szuper-aggregált összeget az összes régióra (t.)
|
1
div> 2
3
4
5
6
|
t.name területként sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) mint
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T A s.TerritoryID = T. TerritoryID
CSOPORT ÁLTAL t., ÖSSZESÍTŐ (t.név, datepart(éééé, Rendelve), datepart(mm Rendelve))
|
Itt használjuk az ANSI SQL 2006 megfelelő szintaxist. Ugyanezt teheti egy kockával. Még soha nem találtam gyakorlati felhasználást erre, de előfordulhat, hogy találkozik vele
mik azok a csoportosítási készletek? Tudnom kellene róluk?
a csoportosítási készlet azt jelenti, hogy az SQL-t többször kéri az eredmény csoportosítására. Használhatja a csoportosítás beállítja szintaxis pontosan meghatározni, hogy mely aggregációk kiszámításához. Íme egy példa.
|
1
2
3
/div>
4
5
6
|
t.name területként sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) mint
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T s.TerritoryID = T. TerritoryID
CSOPORT ÁLTAL t., CSOPORTOSÍTÁS KÉSZLETEK(ÖSSZESÍTŐ(t.neve),
ÖSSZESÍTŐ(datepart(éééé, Rendelve), datepart(mm Rendelve)))
|
Itt kérik a bontás területén csoport minden hónapban, minden évben hónap, év összesen, majd egy összefoglaló összesen terület neve, de anélkül, hogy összesen. A csoportosítással ellentétben ugyanazt az eredményt kapja, függetlenül az egyes csoportosítási halmazokon belüli oszlopok sorrendjétől és a csoportosítási halmazok sorrendjétől.
csoportosítás készletek adhat pontosan milyen kocka ROLLUP ad, és sokkal több mellett. Mint látható, az utolsó példa, akkor a standard “table d’ hôte “kocka ROLLUP összekeverjük közvetlenül kifejezett” à la carte ” csoportosítás készletek.
Miért szeretnénk oszlopokat kombinálni bármilyen összesítésben?
ahol egyes jelentésekben két oszlopot kell kombinálni, célszerű két oszlopot egyesítő aggregációt deklarálni. Az első példa kombináljuk év, hónap, az összegző, hogy a korlátozó hatása a végösszeg, hogy csak minden területén,
|
1
2
3
4
5
6
7
|
–a végösszeg minden területén csak – nem összegek az egyes régiók, illetve évi
VÁLASSZA t. MINT a régió t.név területként, sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) mint
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T A s.TerritoryID = T. TerritoryID
CSOPORT ÁLTAL t., t.név, ÖSSZEGZŐ
((datepart(éééé, Rendelve), datepart(mm Rendelve)))
|
Az extra konzol az ÖSSZESÍTŐ kikötés volt, hogy a korlátozó hatása a összesítések, hogy csak a terület, majd a hónap/év. Hagyd ki őket, és minden évben kapsz összeget.
|
1
2
3
4
5
6
7
8
9
10
|
–kap az összegek évente belül minden területén, valamint az összegek
–minden területén
— nem összegek minden régióban
VÁLASSZA t. MINT a régió t.név területként, sum(TotalDue) bevételként,
datepart(yyyy, OrderDate) as , datepart (mm, OrderDate) mint
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T ON S. TerritoryID = T. TerritoryID
GROUP BY t., t.name, ROLLUP
(datepart(yyyy, OrderDate), datepart (mm, OrderDate)))
|
Ez nagyon hasznos lehet bizonyos adatok esetében. Elkerültük, hogy itt oszlopokat kombináljunk. Ha kockát csinálna, és a területek kifejezései olyan szavakat használtak, mint az “északi” vagy a “Déli”, hogy egynél több régió területét leírják, akkor lenne néhány bizarr aggregáció, amelyek az “északi” területekre vonatkoznak, amelyek nem kapcsolódnak egymáshoz. Az oszlopok kombinálásával elkerülné ezt.
van-e több csoportosítás, mint az “à la carte” kockák készítésének módja?
nem vagyok biztos benne, hogy félénk lennék, ha feltenném ezt a kérdést. SQL:Az 1999-es csoportosítási készletek gazdag rekurzív szintaxist biztosítanak, amely lehetővé teszi az oszlopok kombinációinak összesítését, valamint mindenféle ezoterikus jelentés meghatározását, amely akár tíz dimenziót is biztosít. Az aggregátumok egymásba ágyazhatók, a kockák a tekercsekben, a fészek pedig a kockákon belül helyezhetők el. El kell olvasnia egy speciális kiadványt, hogy többet megtudjon erről.
miért vannak megadva a függvények csoportosítása() és Grouping_ID ()?
nem igazán jó ötlet A NULL használata annak jelzésére, hogy egy oszlop aggregáció. A probléma az, hogy ha egy csoportosítási oszlop null értékeket tartalmaz, akkor az összes null érték egyenlőnek tekinthető, és egyetlen NULL csoportba kerül, amely összefoglalóként álcázza magát. Az eredeti adatokban a NULL értékek nyilvánvaló nehézségének megkerüléséhez két funkció áll rendelkezésre: csoportosítás() és Grouping_ID().
a Grouping() függvény átadja a név egy oszlop, amely részt vett a ROLLUP, kocka vagy csoportosítás készlet. Nullát ad vissza, ha ez a sor egy összefoglaló ehhez az oszlophoz, amelynek NULL értéke “all”, vagy tartalmaz egy értéket.
a GROUPING_ID függvény egy listát ad át, amelynek pontosan meg kell egyeznie a csoportonkénti kifejezéssel. GROUPING_ID jön létre, mint egy bitmap a megfelelő összefoglaló oszlopok. Ha például a terület oszlopnak NULL jelentése van “minden” terület, nem pedig egy terület neve, és a második oszlopként szerepel, akkor a bal oldali második bit be van állítva. Ezt az egész számot ezután visszaadják.
Grouping_ID()általában annak jelzésére használják, hogy a sor elsődleges vagy másodlagos aggregáció (0 vagy > 0), és ha másodlagos, akkor manipulációval kizárják bármely további csoportból.
általában helyes gyakorlatnak tekintik, hogy minden dimenzióhoz (például”terület”vagy” régió “a példánkban) tartalmaz egy bitoszlopot, amely akkor van beállítva, ha a sor az adott dimenzió összefoglalója, valamint egy Grouping_ID() érték, amely segít az eredmény további csoportosításában.
annak illusztrálására, hogy a Grouping_ID valóban működik, itt megnézhetjük, hogy a Grouping_ID bitjei hogyan vannak beállítva az összefoglaló típusának megfelelően. A Phil Factor funkcióját fogjuk használni, hogy megmutassuk a biteket.
|
1
2
3
/div>
4
5
6
7
8 9
|
válassza ki a t. as régiót, t.név területként, összegként(TotalDue) bevételként,
datepart(yyyyy, OrderDate) as , datepart (mm, OrderDate) as ,
jobb (
dbo.ToBinaryString (–sorolja fel az összes csoportot elemek szerint, mivel azok
Grouping_ID (t., t.name, datepart(yyyy, OrderDate),datepart (mm, OrderDate)))
), 4) mivel-csak használja az utolsó négy karaktert, mivel négy oszlop van a listánkban.
az értékesítésből.SalesOrderHeader s
belső csatlakozás értékesítés.SalesTerritory T ON S. TerritoryID = T. TerritoryID
GROUP BY CUBE (T., t.name, datepart(yyyy, OrderDate),datepart(mm, OrderDate)))
|
Ez ad (csak egy mintát természetesen)…
