A DNS szerkezete mechanizmust biztosít az öröklődéshez
a gének olyan biológiai információkat hordoznak, amelyeket pontosan át kell másolni a következő generációra minden alkalommal, amikor egy sejt két lánysejtet képez. Két központi biológiai kérdés merül fel ezekből a követelményekből: hogyan lehet a szervezet meghatározására szolgáló információkat kémiai formában szállítani, és hogyan lehet pontosan lemásolni? A huszadik századi biológiában mérföldkő volt a DNS-kettős spirál szerkezetének felfedezése, mivel azonnal mindkét kérdésre választ adott, ezáltal molekuláris szinten megoldva az öröklődés problémáját. Röviden tárgyaljuk e kérdésekre adott válaszokat ebben a szakaszban, és részletesebben megvizsgáljuk azokat a következő fejezetekben.
A DNS az egyes szálak mentén a nukleotidok sorrendjén vagy szekvenciáján keresztül kódolja az információkat. Minden bázis-A, C, T vagy G—egy négybetűs ábécé betűjének tekinthető, amely biológiai üzeneteket fogalmaz meg a DNS kémiai szerkezetében. Amint azt az 1. fejezetben láttuk, az organizmusok különböznek egymástól, mivel DNS-molekuláik különböző nukleotidszekvenciákkal rendelkeznek, következésképpen különböző biológiai üzeneteket hordoznak. De hogyan használják a nukleotid ábécét üzenetek készítéséhez,és mit írnak ki?
amint azt fentebb tárgyaltuk, jól ismert volt, mielőtt a DNS szerkezetét meghatározták, hogy a gének tartalmazzák a fehérjék előállítására vonatkozó utasításokat. A DNS-üzeneteknek ezért valahogy kódolniuk kell a fehérjéket (4-6.ábra). Ez a kapcsolat azonnal megkönnyíti a probléma megértését, a fehérjék kémiai jellege miatt. Amint azt a 3. fejezet tárgyalja, a biológiai funkcióért felelős fehérje tulajdonságait háromdimenziós szerkezete határozza meg, szerkezetét pedig azon aminosavak lineáris szekvenciája határozza meg, amelyekből áll. Ezért a gén nukleotidjainak lineáris szekvenciájának valamilyen módon meg kell határoznia az aminosavak lineáris szekvenciáját egy fehérjében. A DNS négybetűs nukleotid ábécéje és a fehérjék húszbetűs aminosav ábécéje-a genetikai kód-közötti pontos összefüggés nem egyértelmű a DNS szerkezetéből, és több mint egy évtizedet vett igénybe a kettős hélix felfedezése előtt. A 6. fejezetben részletesen leírjuk ezt a kódot a génexpresszió néven ismert folyamat kidolgozása során,amelyen keresztül egy sejt egy gén nukleotidszekvenciáját egy fehérje aminosavszekvenciájába fordítja.

4-6. ábra
a DNS-ben és a fehérjékben tárolt genetikai információk közötti összefüggés.
a szervezet DNS-ében található teljes információkészletet genomjának nevezik, és az összes olyan fehérje információját hordozza, amelyet a szervezet valaha szintetizál. (A genom kifejezést az információt hordozó DNS leírására is használják.) A genomokban található információk mennyisége megdöbbentő: például egy tipikus emberi sejt 2 méter DNS-t tartalmaz. A négybetűs nukleotid ábécében leírtak szerint egy nagyon kicsi emberi gén nukleotidszekvenciája egy negyed oldalnyi szöveget foglal el (4-7. ábra), míg az emberi genomban lévő nukleotidok teljes szekvenciája több mint ezer könyvet töltene be. Más kritikus információk mellett körülbelül 30 000 különálló fehérjére vonatkozó utasításokat is tartalmaz.

4-7. ábra
a humán β-globin gén nukleotidszekvenciája. Ez a gén hordozza a hemoglobin molekula két alegységének egyikének aminosav-szekvenciáját, amely oxigént hordoz a vérben. Egy másik gén, az α-globin (több…)
minden sejtosztódásnál a sejtnek át kell másolnia a genomját, hogy mindkét lánysejtre átadja. A DNS szerkezetének felfedezése feltárta azt az elvet is, amely lehetővé teszi ezt a másolást: mivel a DNS minden egyes szála olyan nukleotidszekvenciát tartalmaz, amely pontosan kiegészíti a partnerszál nukleotidszekvenciáját, minden szál sablonként vagy formaként működhet egy új kiegészítő szál szintéziséhez. Más szavakkal, ha a két DNS-szálat S-nek és S-nek jelöljük, az S-szál sablonként szolgálhat egy új S-szál készítéséhez, míg az S-szál sablonként szolgálhat egy új S-szál készítéséhez (4-8.ábra). Így a DNS genetikai információit pontosan lemásolhatjuk azzal a gyönyörűen egyszerű folyamattal, amelyben az S szál elválik az S száltól, és minden elválasztott szál sablonként szolgál egy új kiegészítő partnerszál előállításához, amely megegyezik a korábbi partnerével.
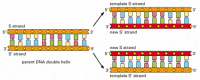
4-8. ábra
DNS mint sablon a saját duplikációjához. Mivel a nukleotid a sikeresen csak T-vel párosul, G pedig C-vel, a DNS minden egyes szála meghatározhatja a nukleotidok szekvenciáját a komplementer szálában. Ily módon a kettős spirális DNS pontosan másolható. (több…)
a DNS-molekula egyes szálainak azon képessége, hogy sablonként működjenek egy kiegészítő szál előállításához, lehetővé teszi a sejt számára, hogy génjeit lemásolja vagy reprodukálja, mielőtt továbbadná leszármazottainak. A következő fejezetben leírjuk az elegáns gépeket, amelyeket a cella használ ennek a hatalmas feladatnak a végrehajtásához.