- ¿Eh? ¿Qué son el CONJUNTO DE AGRUPACIÓN, el CUBO y el AGRUPAMIENTO en SQL?
- ¿Por qué me sería útil el ROLLUP o el CUBO?
- ¿Son SQL estándar o son algo exclusivo de Microsoft?
- ¿Puedo excluir una o más columnas del RESUMEN?
- ¿Qué son los conjuntos DE AGRUPACIÓN entonces? ¿Debería saber de ellos?
- ¿Por qué querríamos combinar columnas en cualquier agregación?
- ¿Hay más en los CONJUNTOS de AGRUPACIÓN que una forma de hacer cubos ‘a la carta’?
- ¿Por qué se proporcionan las funciones Grouping() y Grouping_ID ()?
- Eh? ¿Qué son el CONJUNTO DE AGRUPACIÓN, el CUBO y el AGRUPAMIENTO en SQL?
- ¿por Qué ROLLUP o CUBE ser útil para mí?
- ¿Son SQL estándar o son algo exclusivo de Microsoft?
- ¿Puedo excluir una o más columnas del ACUMULADOR?
- ¿Qué son los conjuntos de AGRUPACIÓN, entonces? ¿Debería saber de ellos?
- ¿Por qué querríamos combinar columnas en cualquier agregación?
- ¿Hay más en los CONJUNTOS de AGRUPACIÓN que una forma de hacer cubos ‘a la carta’?
- ¿Por qué se proporcionan las funciones Grouping() y Grouping_ID ()?
Eh? ¿Qué son el CONJUNTO DE AGRUPACIÓN, el CUBO y el AGRUPAMIENTO en SQL?
CUBE, ROLLUP y GROUPING SET son operadores opcionales de la cláusula GROUP BY de la instrucción SELECT para hacer informes con grandes cantidades de información. Le permiten realizar varias operaciones grupales en una sola instrucción, lo que potencialmente ahorra mucho tiempo y esfuerzo computacional. Pueden proporcionar toda la información necesaria para generar informes, incluidos los totales, a la vez que ofrecen un buen rendimiento en tablas grandes y ayudan al Optimizador de consultas a diseñar un buen plan de ejecución.
Las filas ‘superagregadas’ adicionales proporcionan valores de resumen, lo que le permite tener varias ‘agregaciones’ como SUM() o MAX() dentro de un solo resultado. Los nulos dentro de estas filas en el resultado pretenden significar «todo» en lugar de «desconocido». Le permite obtener todas las agregaciones que necesita en un solo paso a través de la tabla. Debido a la presencia de filas adicionales en los resultados, se proporcionan funciones adicionales GROUPING() y GROUPING_ID() para indicar estas filas ‘superagregadas’ adicionales y qué columnas se están agregando.
Esto tiene mucho sentido si tiene una aplicación que necesita ejecutar varios informes sin cálculos adicionales o sin volver a la base de datos: Tiene todo lo que necesita en un solo resultado.
Tome este ejemplo estándar de un ROLLUP (estoy usando AdventureWorks 2012 aquí)..
|
1
2
3
4
5
6
|
SELECCIONE t. COMO región, t.nombre de territorio, sum(TotalDue) COMO de los ingresos,
datepart(aaaa, Fechapedido) COMO , datepart(mm, Fechapedido) COMO
DE las Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GRUPO POR t., t.nombre, datepart(aaaa, Fecha de pedido), datepart(mm, fecha de pedido)
CON un CONJUNTO ACUMULATIVO
|
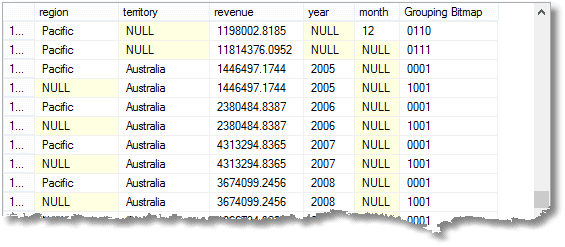
Así como el GRUPO simple POR filas agregadas, con el total adeudado para cada mes, que obtendría con una agrupación simple, también obtendrá subtotal o filas de súper agregados, y también una fila de gran total. (aquí está el principio del resultado)
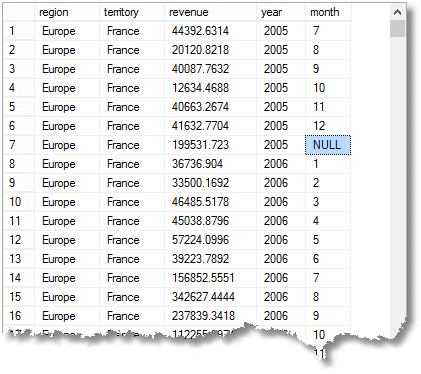
Que he resaltado significa que la fila es un agregado para ‘todos’ meses de 2005 en Francia (parte de la región de Europa)
Además de todo esto, obtienes el total adeudado para cada año, para cada territorio y grupo territorial, así como el total adeudado total. (desde el final)
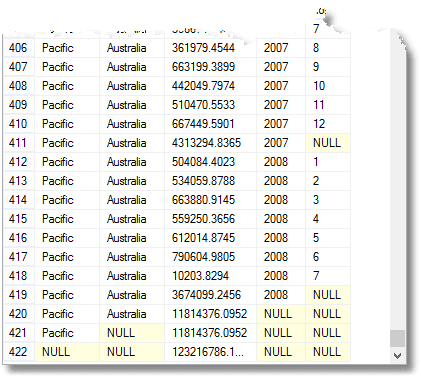
Esos valores nulos significan «Todos», recuerda. La última fila es el total general, y encima está el total para la región del pacífico. Por encima de eso está la contribución de Australia a la región del Pacífico. La cuarta fila de abajo es la contribución de Australia en 2008. El número de agrupaciones que se devuelve es uno más que el número de expresiones de la lista de elementos compuestos que se proporciona a la instrucción GROUP BY.
Para conseguir el mismo efecto sin necesidad de utilizar el paquete acumulativo de actualizaciones, usted tendría que hacer algo como esto (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
CON myGrouping ( región, territorio, totalDue, , )
as ( SELECT t., t.nombre, sum(TotalDue) COMO de los ingresos,
datepart(aaaa, Fechapedido) COMO , datepart(mm, Fechapedido) COMO
DE las Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GRUPO POR t.name, t. datepart(aaaa, Fechapedido), datepart(mm, Fechapedido))
SELECCIONE Región, territorio, totalDue, ,
DE myGrouping
UNIÓN
SELECCIONE la Región, el territorio, la suma(totalDue), , NULL
DE myGrouping GRUPO POR Región, territorio,
UNIÓN
SELECCIONE la Región, el territorio, la suma(totalDue), NULL, NULL
DE myGrouping GRUPO POR Región, territorio
UNIÓN
SELECCIONE la Región, NULL, sum(totalDue), NULL, NULL
DE myGrouping GRUPO de la Región
UNIÓN
SELECT NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.nombre,datepart(aaaa,Fechapedido),datepart(mm,Fechapedido))’
|
Esta nueva sintaxis permite algunas funciones extra. Recuerde también que el orden de las columnas afecta a las agrupaciones de salida de ROLLUP y puede afectar al número de filas del conjunto de resultados.
El CUBO hace la misma cosa, pero, en lugar de proporcionar una jerarquía de los totales en ordenadas super-agregado filas, ofrece toda la ‘super-agregado’ permutaciones (‘simétrica super-agregado’ filas), el llamado cruce de filas. Si quieres saber qué territorio dio la mayor cantidad de pedidos en marzo, o qué territorio tuvo un desempeño menos bueno en 2006, entonces necesitarás un CUBO. Usted está proporcionando todos los resúmenes posibles en el resultado.
CONJUNTO DE AGRUPACIÓN le permite ajustar su resultado para proporcionar información más especializada por encima y más allá del CUBO. Puede proporcionar información resumida sobre combinaciones de dimensiones. Puede obtener exactamente el mismo resultado que en nuestro ejemplo de AGRUPAMIENTO utilizando CONJUNTOS DE AGRUPACIÓN, pero con mucho más tipeo.
|
1
2
3
4
5
6
7
8
9
10
|
SELECCIONE t. COMO región, t.nombre de territorio, sum(TotalDue) COMO de los ingresos,
datepart(aaaa, Fechapedido) COMO , datepart(mm, Fechapedido) COMO
DE las Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.Territorio de venta T EN territorio s. Id = T.TerritoryID
GRUPO MEDIANTE la AGRUPACIÓN de CONJUNTOS(
(T., T. nombre,datepart(aaaa, Fechapedido), datepart(mm, Fechapedido)),
(T., T. nombre,datepart(aaaa, Fechapedido) ),
(T., T. nombre),
(T.),
())
|
Esto es sólo para mostrar cómo se relacionan. En realidad, recurrirías a CONJUNTOS DE AGRUPACIÓN para obtener resultados que son imposibles con ROLLUP o CUBE.
Casi todos estos resúmenes se pueden obtener usando solo AGRUPAR POR, pero solo agrupando repetidamente el resultado de un GRUPO POR, o haciendo más de una pasada a través de los datos.
Cuando usted está utilizando el CUBO, paquete ACUMULATIVO de actualizaciones o CONJUNTOS de AGRUPACIÓN, no se puede utilizar la palabra clave DISTINCT en la suma de las expresiones, tales como AVG (DISTINTOS column_name), COUNT (DISTINCT column_name), y la SUMA (DISTINTOS column_name)
¿por Qué ROLLUP o CUBE ser útil para mí?
ROLLUP y CUBE tuvieron su apogeo antes de los SSAS. Fueron útiles para proporcionar el mismo tipo de instalaciones que ofrece el cubo en OLAP. Sin embargo, todavía tiene sus usos. En AdventureWorks, es excesivo, pero si está manejando grandes volúmenes de datos, necesita pasar sus datos solo una vez y hacer todo lo posible con los datos que se han agregado. Los eventos que ocurrieron en el pasado no se pueden cambiar, por lo que rara vez es necesario retener datos históricos en un sistema OLTP activo. En su lugar, solo necesita conservar los datos agregados en el nivel de detalle («granularidad») requerido para todos los informes previsibles.
Imagine que es responsable de informar en un conmutador telefónico que tiene aproximadamente dos millones de llamadas al día. Si conserva todas estas llamadas en su servidor OLTP, pronto encontrará que el servidor SQL está trabajando en los informes de uso. Tiene que conservar la información de la llamada original durante un período de tiempo legal, pero determina a partir de la empresa que, a lo sumo, solo están interesados en el número de llamadas en un minuto. Entonces ha reducido su requisito de almacenamiento en el servidor OLTP a 1.el 4% de lo que era, y los registros de llamadas se pueden archivar en otro servidor SQL para consultas ad hoc y declaraciones de clientes. Es probable que valga la pena ahorrar. Las cláusulas CUBE y ROLLUP le permiten incluso almacenar los totales de fila, totales de columna y totales generales sin tener que hacer una exploración de tabla o índice agrupado de la tabla de resumen.
Mientras no se realicen cambios retrospectivos en estos datos, y todos los períodos de tiempo estén completos, nunca tendrá que repetir o alterar las agregaciones basadas en períodos de tiempo pasados, ¡aunque los totales generales deberán estar sobreescritos!.
Vamos a fingir, pero usando AdventureWorks2012 para que puedas seguir el juego.
En primer lugar, crearemos la tabla de resumen de gramos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
IF EXISTS (SELECT * FROM tempdb.sys.tablas DONDE el nombre COMO ‘ # AggregationTable%’)
DROP TABLE #aggregationTable delete elimina la tabla temporal si existe
GO
SELECT
identity (INT, 1, 1) AS, so para que podamos tener una columna única
t. COMO región, t.name COMO territorio, suma (TotalDue) COMO ingresos,
datepart (aaaa, OrderDate) AS , datepart (mm, OrderDate) AS,
agrupación(t.name) COMO isNameGroup ,Does Se relaciona con TODOS los territorios
agrupamiento (t.) COMO isGroupGroup, Does Se relaciona con TODOS los continentes
agrupamiento(datepart(aaaa, OrderDate)) COMO isYearGroup, e relaciona con TODOS los años
agrupamiento(datepart(mm, OrderDate)) COMO isMonthGroup, e relaciona con TODOS los meses
Grouping_ID (t.name, t.,
datepart(aaaa,Fecha de pedido), datepart (mm, fecha de pedido)) COMO isGroupingRow
is es esta una fila extra sin datos que contiene datos agregados
EN #agregación de mesa
DE Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.Territorio de venta T EN territorio s. Id = T.TerritoryID
GRUPO POR t.name, t., datepart(aaaa, Fecha de pedido), datepart (mm, fecha de pedido)
CON un resumen
|
Observe que estamos agregando columnas de ‘bits’ adicionales que nos indican qué filas contienen las filas de resumen. Si los agregas por error a otras agregaciones, obtendrás algunos resultados seriamente inflados. Obviamente, no puede usar Grouping() o Grouping_ID en el resultado guardado, por lo que debe proporcionar algo en su lugar.
Ahora podemos producir la tabla dinámica muy rápida
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
– ahora podemos crear una sencilla tabla dinámica con la fila y
— columna de totales
SELECCIONE Territorio,
suma(CASO CUANDO 2005, LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO CUANDO 2006, LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO CUANDO 2007, LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO CUANDO 2008, LUEGO ingresos ELSE 0 FIN) COMO,
suma(ingresos) COMO
DE #Agregación div>
DONDE isGroupingrow =0
AGRUPAR POR territorio
UNIR TODO
SELECCIONE ‘Total’, suma(CASO CUANDO 2005, LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO CUANDO 2006, LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO CUANDO 2007, LUEGO ingresos ELSE 0 FIN) COMO ,
sum(CASO CUANDO 2008, LUEGO EL FIN DE LOS ingresos ELSE 0) COMO,
sum(ingresos) COMO
DE #AggregationTable
DONDE isYearGroup =0 E isMonthGroup=1
|
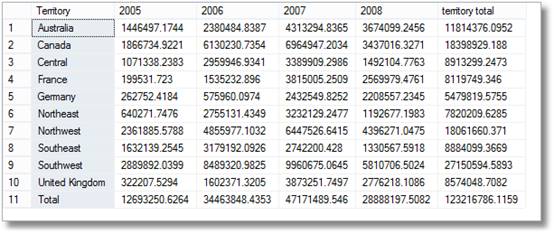
Así que hay breves sonrisas de los gerentes al ver esto, pero luego dicen brillantemente ‘ Estoy seguro de que también pedí un desglose por territorio por mes
Con una breve risa, haz esto.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECT
datename(MONTH,dateadd(MONTH, ,’01 de diciembre de 2000′)) AS ,
sum(territorio DE CASO CUANDO ‘Australia’, LUEGO FIN DE ingreso ELSE 0) AS,
sum(territorio DE caso CUANDO ‘Canadá’, LUEGO FIN DE ingreso ELSE 0) AS,
sum(territorio de caso CUANDO ‘Central’ LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO territorio CUANDO ‘Francia’ LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO territorio CUANDO ‘Alemania’ LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO territorio CUANDO ‘Noreste’ LUEGO ingresos ELSE 0 FIN) COMO,
suma(CASO territorio CUANDO ‘Noreste’ LUEGO ingresos ELSE 0 FIN) COMO,
suma (CASO territorio CUANDO ‘Noroeste’, ENTONCES ingresos ELSE 0 FIN) COMO,
sum(TERRITORIO DE CASO CUANDO ‘Sureste’, LUEGO ingresos ELSE 0 FIN) COMO,
sum(territorio DE CASO CUANDO ‘Suroeste’, LUEGO ingresos ELSE 0 FIN) COMO,
sum(territorio DE CASO CUANDO ‘Reino Unido’, LUEGO ingresos ELSE 0 FIN) COMO,
sum(ingresos) COMO
DE #Agregación Tabla
DONDE isGroupingrow =0
GROUP BY month
UNION ALL
SELECCIONE
‘Total’,
sum(territorio DE CASO CUANDO ‘Australia’, LUEGO revenue ELSE 0 END) COMO,
sum(territorio de CASO CUANDO ‘Canadá’, LOS ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio CUANDO ‘Central’, a CONTINUACIÓN, los ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio CUANDO ‘Francia’, a CONTINUACIÓN, los ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio CUANDO ‘Alemania’, a CONTINUACIÓN, los ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio CUANDO «Noreste», a CONTINUACIÓN, los ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio AL Noroeste, a CONTINUACIÓN, los ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio CUANDO ‘Sureste’, LOS ingresos ELSE 0 END) COMO ,
sum(el CASO de territorio CUANDO ‘Suroeste’, LOS ingresos ELSE 0 END) COMO ,
sum(TERRITORIO DE CASO CUANDO ‘Reino Unido’, LUEGO revenue ELSE 0 END) COMO,
sum(revenue) COMO
DE #agregación de tabla
DONDE isGroupingrow =0
|
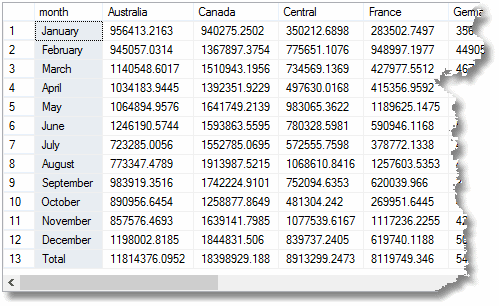
Pero si hubiera utilizado CUBO en lugar de acumulador, la última fila’ total ‘ ya se calcularía. En un ejemplo real que costaría tiempo hacer el informe. Puede hacer un CUBO en hasta diez dimensiones; aunque tienden a aumentar la agregación, no son demasiado costosos.
¿Son SQL estándar o son algo exclusivo de Microsoft?
Estos ahora son SQL ANSI estándar de 1999, aunque CON CUBE y CON ROLLUP fueron introducidos por primera vez por Microsoft. Esta inclusión es algo sorprendente, ya que introduce un segundo significado, ‘todo’, para el valor NULO además de ‘desconocido’. Cuando Microsoft introdujo por primera vez CUBE y ROLLUP, la sintaxis era ligeramente diferente, pero ambos formularios están permitidos en SQL Server. Solo se puede usar un estilo de sintaxis en una sola instrucción SELECT, y debe usar la sintaxis compatible con ISO para todo el trabajo nuevo.
¿Puedo excluir una o más columnas del ACUMULADOR?
¡Si quieres! Imaginemos que yo no quiero un super-agregado total para todas las regiones (t.)
|
1
2
3
4
5
6
|
SELECCIONE t. COMO región, t.nombre de territorio, sum(TotalDue) COMO de los ingresos,
datepart(aaaa, Fechapedido) COMO , datepart(mm, Fechapedido) COMO
DE las Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GRUPO POR t., GRUPO ACUMULATIVO (t.name, datepart(aaaa, Fecha de pedido), datepart (mm, fecha de pedido))
|
Aquí estamos utilizando la sintaxis compatible con ANSI SQL 2006. Puedes hacer lo mismo con un cubo. Nunca he encontrado un uso práctico para esto, pero puede que lo encuentre
¿Qué son los conjuntos de AGRUPACIÓN, entonces? ¿Debería saber de ellos?
CONJUNTO DE AGRUPACIÓN significa que está pidiendo a SQL que agrupe el resultado varias veces. Puede usar la sintaxis de CONJUNTOS de AGRUPACIÓN para especificar con precisión qué agregaciones calcular. He aquí un ejemplo.
|
1
2
3
4
5
6
|
SELECCIONE t. COMO región, t.nombre de territorio, sum(TotalDue) COMO de los ingresos,
datepart(aaaa, Fechapedido) COMO , datepart(mm, Fechapedido) COMO
DE las Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T ON s.TerritoryID = T. TerritoryID
GRUPO POR t., CONJUNTOS DE AGRUPACIÓN (ROLLUP(t.name),
ROLLUP(datepart(aaaa, Fecha de pedido), datepart(mm, fecha de pedido)))
|
Aquí, está solicitando el desglose por grupo de territorios para cada mes de cada año con totales mensuales y anuales, seguidos de un total resumido por nombre del territorio, pero sin un total general. A diferencia del ACUMULADOR, se obtiene el mismo resultado, sea cual sea el orden de las columnas dentro de cada CONJUNTO de AGRUPACIÓN y el orden de los CONJUNTOS de AGRUPACIÓN.
Los conjuntos DE agrupación pueden darte exactamente lo que el CUBO y el ACUMULADOR te dan y mucho más. Como puede ver en este último ejemplo, puede usar un CUBO y un ACUMULADOR estándar de ‘table d’hôte’ mezclados con conjuntos de agrupación «a la carta» expresados directamente.
¿Por qué querríamos combinar columnas en cualquier agregación?
Cuando se deben combinar dos columnas en algunos informes, es útil declarar una agregación que combine dos columnas. En el primer ejemplo que hemos combinar el año y el mes para el paquete acumulativo de actualizaciones, tener el efecto de restringir los totales sólo cada territorio,
|
1
2
3
4
5
6
7
|
–obtener el total de cada territorio – no los totales de cada región o año
SELECCIONE t. COMO región, t.nombre COMO territorio, suma (TotalDue) COMO ingresos,
datepart(aaaa, Fecha de pedido) COMO , datepart(mm, fecha de pedido) COMO
DE Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GRUPO POR t., t.name, ROLLUP
((datepart(aaaa, OrderDate), datepart(mm, OrderDate)))
|
Ese corchete adicional en la cláusula ROLLUP ha tenido el efecto de restringir las agregaciones solo al territorio y al mes / año. Déjalos fuera, y obtendrás los totales de cada año.
|
1
2
3
4
5
6
7
8
9
10
|
–obtener los totales para cada año dentro de cada territorio, así como los totales
–para cada territorio
— no los totales de cada región
SELECCIONE t. COMO región, t.nombre COMO territorio, suma (TotalDue) COMO ingresos,
datepart(aaaa, Fecha de pedido) COMO , datepart(mm, fecha de pedido) COMO
DE Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T A s.TerritoryID = T. TerritoryID
GRUPO de t., t.nombre de paquete ACUMULATIVO de actualizaciones
(datepart(aaaa, Fechapedido), datepart(mm, Fechapedido))
|
Esto puede ser muy útil para ciertos datos. Hemos evitado la necesidad de combinar columnas aquí. Si tuvieras que hacer un CUBO, y los términos para territorios usaran palabras como ‘Norte’ o ‘Sur’ para describir un territorio en más de una región, tendrías algunas agregaciones extrañas que se aplican a los territorios ‘norte’ que no están relacionados. Al combinar columnas, evitarías esto.
¿Hay más en los CONJUNTOS de AGRUPACIÓN que una forma de hacer cubos ‘a la carta’?
No estoy seguro de que sea tímido al hacer esta pregunta. SQL:Los CONJUNTOS DE AGRUPACIÓN DE 1999 proporcionan una rica sintaxis recursiva que le permite agregar combinaciones de columnas y definir todo tipo de informes esotéricos que proporcionan hasta diez dimensiones. Las agregaciones se pueden anidar y puedes anidar cubos dentro de cubos y anidar cubos dentro de cubos. Tendrá que leer una publicación especializada para obtener más información sobre esto.
¿Por qué se proporcionan las funciones Grouping() y Grouping_ID ()?
No es realmente una buena idea usar NULL para indicar que una columna es una agregación. El problema es que, si una columna de agrupación contiene valores nulos, todos los valores nulos se consideran iguales y se colocan en un solo grupo NULO que se disfraza como un resumen. Para evitar la obvia dificultad de los valores NULOS en los datos originales, se proporcionan dos funciones: Grouping() y Grouping_ID().
A la función Grouping() se le pasa el nombre de una columna que participó en el CONJUNTO ACUMULADOR, CUBO o AGRUPACIÓN. Devuelve cero si esta fila es un resumen para esta columna con un valor NULO que significa ‘todo’ o si contiene un valor.
A la función GROUPING_ID se le pasa una lista que debe coincidir exactamente con la expresión de la lista AGRUPAR POR. GROUPING_ID se crea como un mapa de bits de las columnas de resumen respectivas. Si, por ejemplo, la columna territorio tiene un valor NULO que significa «todos» territorios en lugar del nombre de un territorio, y aparece como la segunda columna, se establece el segundo bit de la izquierda. A continuación, se devuelve este entero.
Grouping_ID() se utiliza generalmente para indicar si la fila es una agregación primaria o secundaria (0 o >0) y, si es secundaria, se excluye de cualquier otro GRUPO MEDIANTE manipulación.
Generalmente se considera una buena práctica incluir una columna de bits para cada dimensión (como ‘Territorio’ o ‘Región’ en nuestro ejemplo) que se establece si la fila es un resumen para esa dimensión, junto con un valor Grouping_ID() para ayudar a cualquier agrupación posterior del resultado.
Para ilustrar la forma en que funciona realmente Grouping_ID, aquí veremos la forma en que se establecen los bits en el Grouping_ID de acuerdo con el tipo de resumen. Usaremos la función de Factor Phil para mostrar los bits.
|
1
2
3
4
5
6
7
8
9
|
SELECCIONE t. COMO región, t.nombre COMO territorio, suma (TotalDue) COMO ingresos,
datepart(aaaa, Fecha de pedido) COMO , datepart(mm, fecha de pedido) COMO ,
derecho (
dbo.ToBinaryString (list listar todos los elementos del grupo como son
Grouping_ID (t., t.name, datepart(aaaa, Fecha de pedido),datepart (mm, fecha de pedido))
),4) AS use simplemente use los últimos cuatro caracteres, ya que tenemos cuatro columnas en nuestra lista.
DE Ventas.SalesOrderHeader s
Ventas DE UNIÓN INTERNA.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GRUPO POR CUBO (t., t.nombre, datepart(aaaa, Fechapedido),datepart(mm, Fechapedido))
|
Esto le da (sólo una muestra de curso)…