
Ese es un punto importante a entender. No solo el uso del método incorrecto a veces conduce a que las páginas no se eliminen del índice como se pretendía, sino que también puede tener un efecto negativo en el SEO.
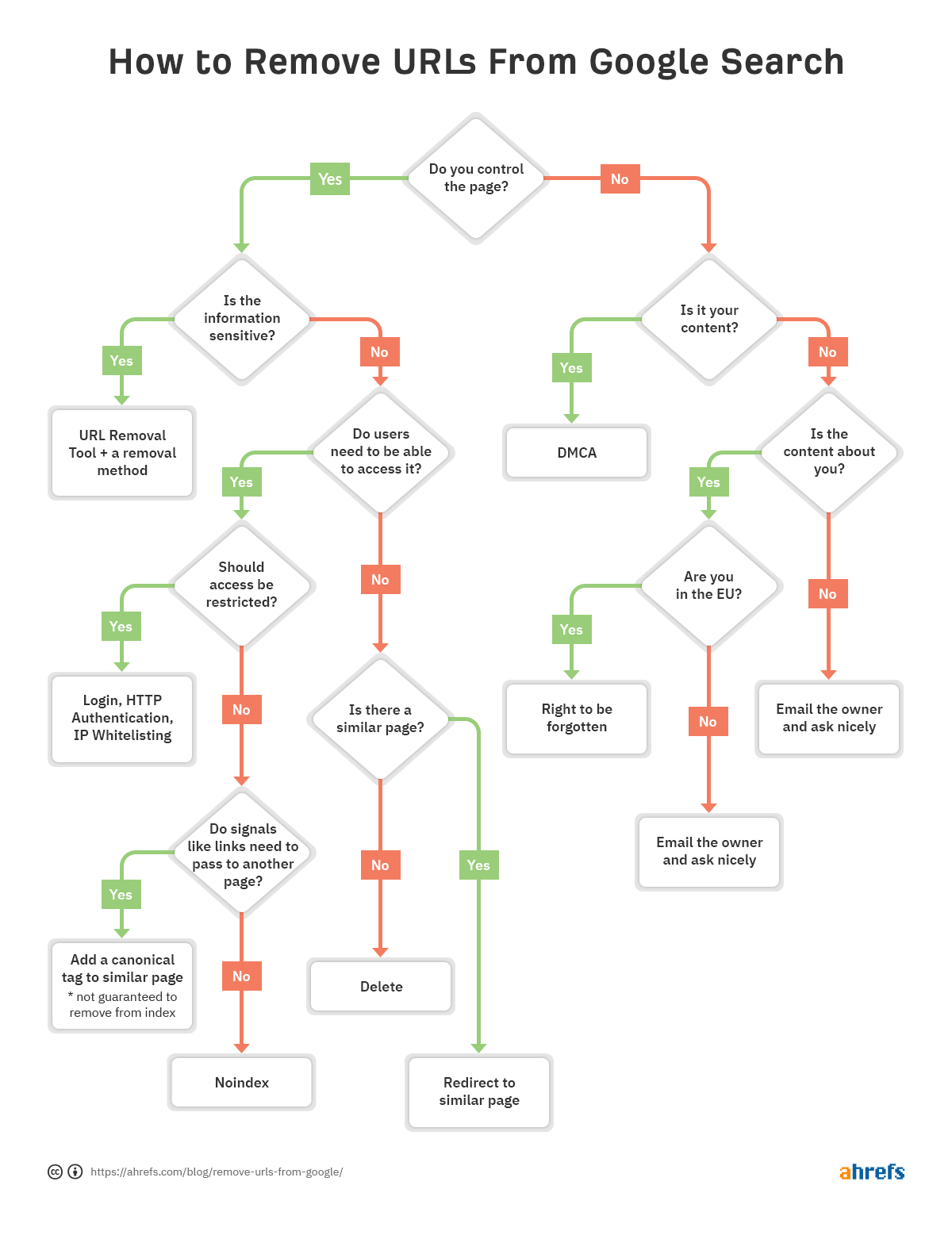
Para ayudarlo a decidir rápidamente qué método de eliminación es el mejor para usted, creamos un diagrama de flujo para que pueda saltar a la sección relevante del artículo.
En esta publicación, aprenderás:
- Cómo comprobar si una URL está indexada
- Cinco formas de eliminar URL de Google
- Cómo priorizar las eliminaciones
- Errores comunes de eliminación para evitar
- Cómo eliminar contenido que no está en tu sitio
- Cómo eliminar imágenes
Lo que normalmente veo que hacen los SEO para comprobar si el contenido está indexado es usar un sitio: buscar en Google (por ejemplo,https://ahrefs.com). Mientras que el sitio: las búsquedas pueden ser útiles para identificar las páginas o secciones de un sitio web que pueden ser problemáticas si se muestran en los resultados de búsqueda, debes tener cuidado porque no son consultas normales y en realidad no te dirán si una página está indexada. Pueden mostrar páginas conocidas por Google, pero eso no significa que sean elegibles para mostrarlas en los resultados de búsqueda normales sin el operador site:.
Por ejemplo, las búsquedas en el sitio todavía pueden mostrar páginas que redirigen o que están canonizadas a otra página. Cuando solicitas un sitio específico, Google puede mostrar una página de ese dominio con el contenido, el título y la descripción de otro dominio. Tomemos por ejemplo moz.com que solía ser seomoz.org. Cualquier consulta de usuario regular que lleve a páginas en moz.com se mostrará moz.com en las SERPs, mientras site:seomoz.org se mostrará seomoz.org en los resultados de búsqueda como se muestra a continuación.
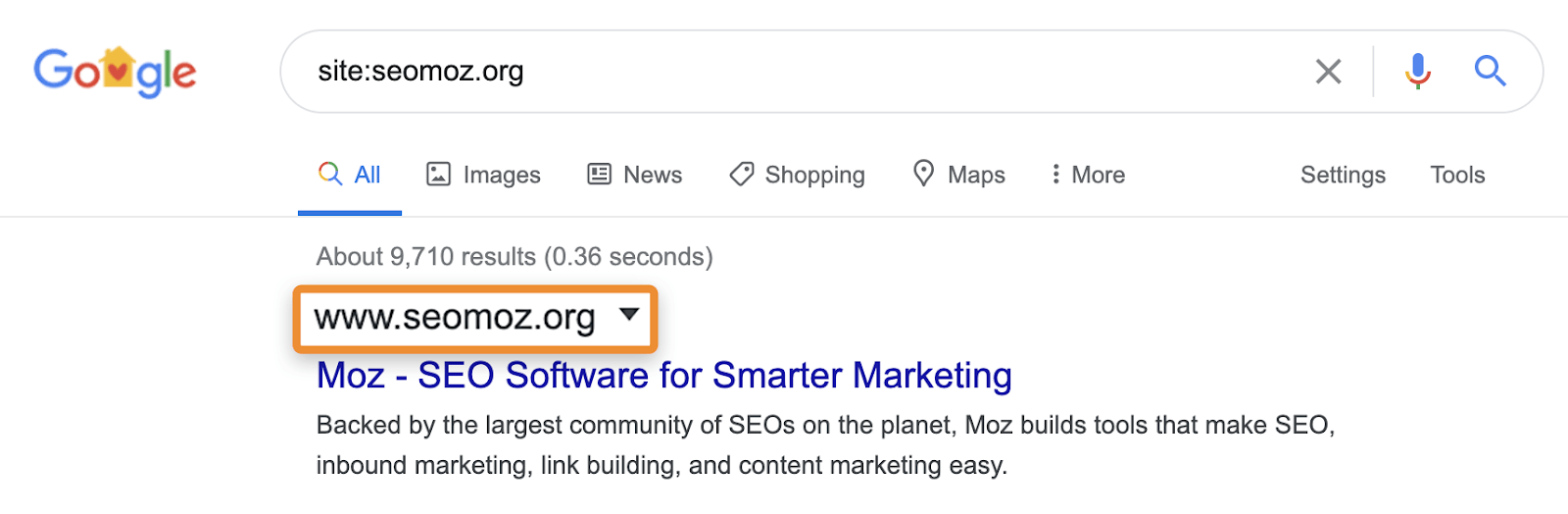
La razón por la que esta distinción es importante es que puede llevar a los SEO a cometer errores, como bloquear o eliminar activamente las URL del índice del dominio antiguo, lo que evita la consolidación de señales como PageRank. He visto muchos casos con migraciones de dominios en los que la gente piensa que cometió un error durante la migración porque estas páginas todavía se muestran para site:old-domain.com busca y termina dañando activamente su sitio web mientras intenta «solucionar» el problema.
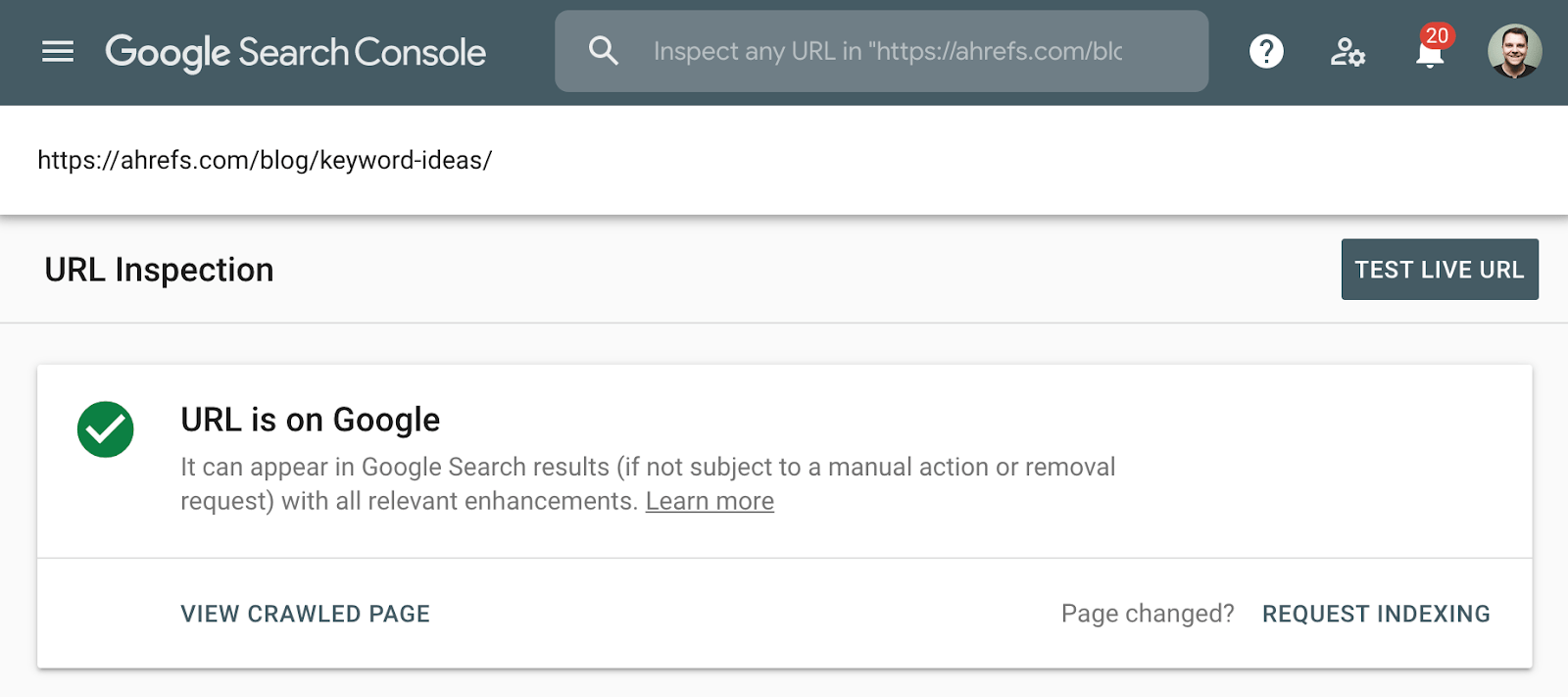
El mejor método para comprobar la indexación es usar el informe de cobertura de índices en Google Search Console o la herramienta de inspección de URL para una URL individual. Estas herramientas te indican si una página está indexada y proporcionan información adicional sobre cómo Google está tratando la página. Si no tienes acceso a esto, simplemente busca en Google la URL completa de tu página.
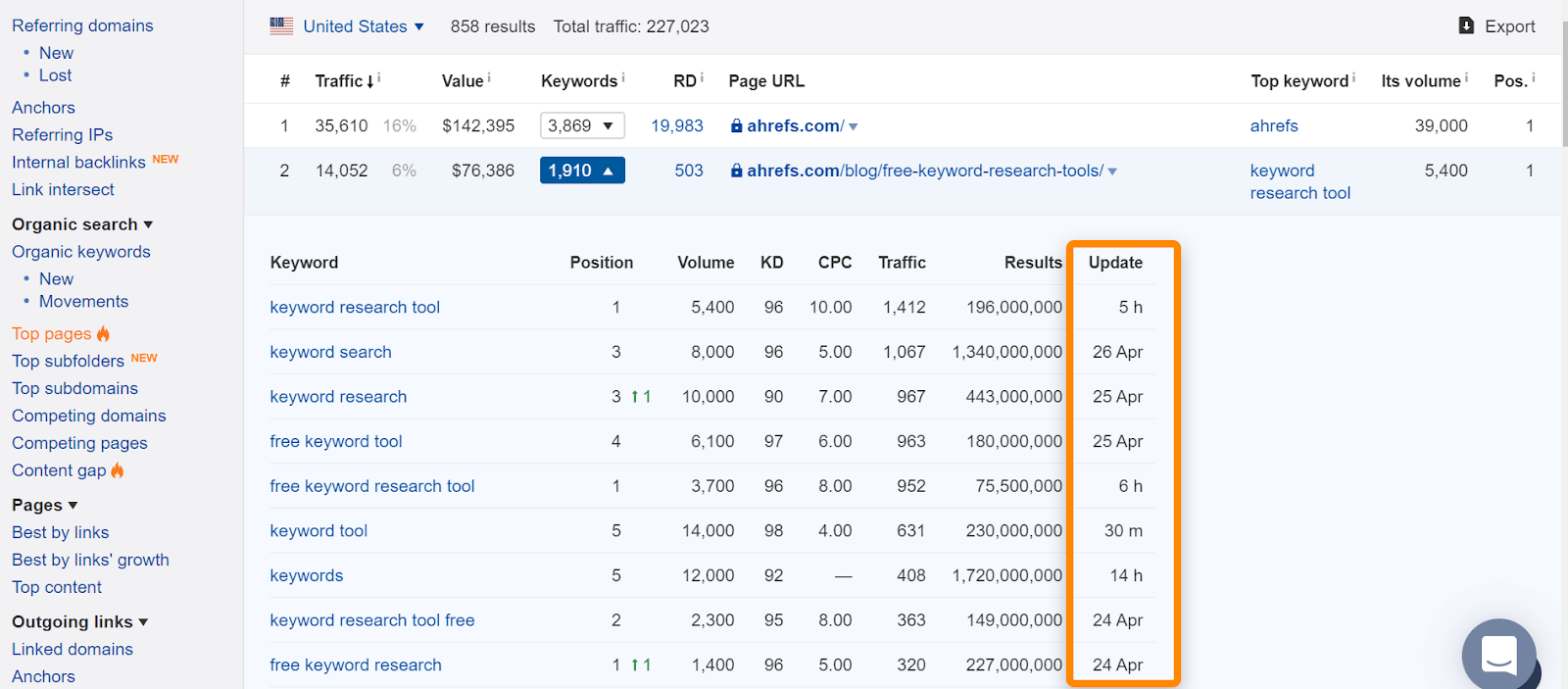
En Ahrefs, si encuentra la página en nuestro informe de «Páginas principales» o en la clasificación de palabras clave orgánicas, generalmente significa que la vimos en la clasificación de consultas de búsqueda normales y es una buena indicación de que la página fue indexada. Tenga en cuenta que las páginas estaban indexadas cuando las vimos, pero eso puede haber cambiado. Compruebe la fecha de la última vez que vimos la página para una consulta.
Si hay un problema con una URL en particular y necesita eliminarse del índice, siga el diagrama de flujo al principio del artículo para encontrar la opción de eliminación correcta, luego vaya a la sección apropiada a continuación.
Si elimina la página y muestra un código de estado 404 (no encontrado) o 410 (desaparecido), la página se eliminará del índice poco después de que se vuelva a rastrear la página. Hasta que se elimine, la página puede seguir apareciendo en los resultados de búsqueda. E incluso si la página en sí ya no está disponible, una versión en caché de la página puede estar disponible temporalmente.
Cuando necesite una opción diferente:
- Necesito una eliminación más inmediata. Consulte la sección Herramienta de eliminación de URL.
- Necesito consolidar señales como enlaces. Consulte la sección de canonicalización.
- Necesito la página disponible para los usuarios. Vea si las secciones noindex o acceso restringido se ajustan a su situación.
- Opción de eliminación 2: Noindex
- Opción de eliminación 3: Restringir el acceso
- Opción de eliminación 4: Herramienta de eliminación de URL
- Opción de eliminación 5: Canonicalización
- Noindex en robots.txt
- Bloquear el rastreo en robots.txt
- Nofollow
- Noindex y canónicos a otra URL
- Noindex, espere a que Google rastree, luego bloquee el rastreo
- ¿Qué pasa si es contenido sobre ti, pero no en un sitio de tu propiedad?
- conclusión
Opción de eliminación 2: Noindex
Una etiqueta de meta robots noindex o una respuesta de encabezado x-robots indicarán a los motores de búsqueda que eliminen una página del índice. La etiqueta meta robots funciona para páginas donde la respuesta de x-robots funciona para páginas y tipos de archivos adicionales como archivos PDF. Para que se vean estas etiquetas, un motor de búsqueda debe poder rastrear las páginas, así que asegúrese de que no estén bloqueadas en los robots.txt. Además, tenga en cuenta que la eliminación de páginas del índice puede impedir la consolidación de enlaces y otras señales.
Ejemplo de noindex de meta robots:
<meta name="robots" content="noindex">
Ejemplo de etiqueta noindex de x‑robots en la respuesta del encabezado:
HTTP/1.1 200 OKX-Robots-Tag: noindex
Cuando necesite una opción diferente:
- No quiero que los usuarios accedan a estas páginas. Consulte la sección restricción de acceso.
- Necesito consolidar señales como enlaces. Consulte la sección de canonicalización.
Opción de eliminación 3: Restringir el acceso
Si desea que la página sea accesible para algunos usuarios pero no para los motores de búsqueda, lo que probablemente desee es una de estas tres opciones:
- algún tipo de sistema de inicio de sesión;
- Autenticación HTTP (donde se requiere una contraseña para el acceso);
- Lista blanca de IP (que solo permite que direcciones IP específicas accedan a las páginas)
Este tipo de configuración es mejor para cosas como redes internas, contenido exclusivo para miembros o para sitios de preparación, prueba o desarrollo. Permite que un grupo de usuarios acceda a la página, pero los motores de búsqueda no podrán acceder a ellos y no indexarán las páginas.
Cuando necesite una opción diferente:
- Necesito una eliminación más inmediata. Consulte la sección Herramienta de eliminación de URL. En este caso en particular, es posible que desee una eliminación más inmediata si el contenido que está tratando de ocultar se ha almacenado en caché y debe evitar que los usuarios vean ese contenido.
Opción de eliminación 4: Herramienta de eliminación de URL
El nombre de esta herramienta de Google es ligeramente engañoso, ya que la forma en que funciona es que ocultará temporalmente el contenido. Google seguirá viendo y rastreando este contenido, pero las páginas no aparecerán para los usuarios. Este efecto temporal dura seis meses en Google, mientras que Bing tiene una herramienta similar que dura tres meses. Estas herramientas deben usarse en los casos más extremos para cosas como problemas de seguridad, fugas de datos, información de identificación personal (PII), etc. Para Google, usa la herramienta de eliminación y para Bing, consulta cómo bloquear URL.
Todavía necesita aplicar otro método junto con el uso de la herramienta de eliminación para eliminar realmente las páginas por un período más largo (noindex o eliminar) o evitar que los usuarios accedan al contenido si aún tienen los enlaces (eliminar o restringir el acceso). Esto solo le da una forma más rápida de ocultar las páginas mientras la eliminación tiene tiempo para procesarse. La solicitud puede tardar hasta un día en procesarse.
Opción de eliminación 5: Canonicalización
Cuando tiene varias versiones de una página y desea consolidar señales como enlaces a una sola versión, lo que desea hacer es alguna forma de canonicalización. Esto es principalmente para evitar contenido duplicado mientras se consolidan varias versiones de una página en una sola URL indexada.
Tiene varias opciones de canonización:
- Etiqueta canónica. Esto especifica otra URL como la versión canónica o la versión que desea que se muestre. Si las páginas son duplicadas o muy similares, esto debería estar bien. Cuando las páginas son demasiado diferentes, lo canónico puede ser ignorado, ya que es una sugerencia y no una directiva.
- Redirige. Una redirección lleva a un usuario y a un bot de búsqueda de una página a otra. 301 es el redireccionamiento más utilizado por SEOs, y le dice a los motores de búsqueda que desea que la URL final sea la que se muestra en los resultados de búsqueda y donde se consolidan las señales. Un redireccionamiento 302 o temporal le dice a los motores de búsqueda que desea que la URL original sea la que permanezca en el índice y consolide las señales allí.
- Manejo de parámetros de URL. Se añade un parámetro al final de la URL y normalmente incluye un signo de interrogación, como ahrefs.com?this=parameter. Esta herramienta de Google le permite indicarles cómo tratar las URL con parámetros específicos. Por ejemplo, puede especificar si el parámetro cambia el contenido de la página o si solo está destinado a realizar un seguimiento del uso.
Si tiene varias páginas para eliminar del índice de Google, debe priorizarlas en consecuencia.
Máxima prioridad: Estas páginas suelen estar relacionadas con la seguridad o con datos confidenciales. Esto incluye contenido que contiene datos personales (PII), datos de clientes o información de propiedad.
Prioridad media: Normalmente se trata de contenido destinado a un grupo específico de usuarios. Intranets de la empresa o portales para empleados, contenido solo para miembros y entornos de preparación, prueba o desarrollo.
Baja prioridad: Estas páginas suelen incluir contenido duplicado de algún tipo. Algunos ejemplos de esto incluirían páginas servidas desde múltiples URL, URL con parámetros y, de nuevo, podrían incluir entornos de preparación, prueba o desarrollo.
Quiero cubrir algunas de las formas en que generalmente veo que las eliminaciones se hacen incorrectamente y lo que sucede en cada escenario para ayudar a las personas a comprender por qué no funcionan.
Noindex en robots.txt
Mientras que Google solía admitir de forma no oficial noindex en robots.txt, nunca fue un estándar oficial y ahora han eliminado formalmente el soporte. Muchos de los sitios que hacían esto lo hacían incorrectamente y se dañaban a sí mismos.
Bloquear el rastreo en robots.txt
El rastreo no es lo mismo que la indexación. Incluso si Google está bloqueado para rastrear páginas, si hay enlaces internos o externos a una página, aún pueden indexarla. Google no sabrá qué hay en la página porque no la rastreará, pero sabe que existe una página e incluso escribirá un título para mostrar en los resultados de búsqueda basado en señales como el texto de anclaje de los enlaces a la página.
Nofollow
Esto comúnmente se confunde con noindex, y algunas personas lo usarán a nivel de página esperando que la página no se indexe. Nofollow es una pista, y aunque originalmente impidió que se rastrearan los enlaces de la página y los enlaces individuales con el atributo nofollow, ese ya no es el caso. Google ahora puede rastrear estos enlaces si así lo desea. Nofollow también se usó en enlaces individuales para tratar de evitar que Google rastreara páginas específicas y para esculpir PageRank. De nuevo, esto ya no funciona, ya que nofollow es una pista. En el pasado, si la página tenía otro enlace a ella, entonces Google aún podía descubrir desde este camino de rastreo alternativo.
Tenga en cuenta que puede encontrar páginas nofollow de forma masiva utilizando este filtro en el Explorador de páginas en la Auditoría del sitio de Ahrefs.
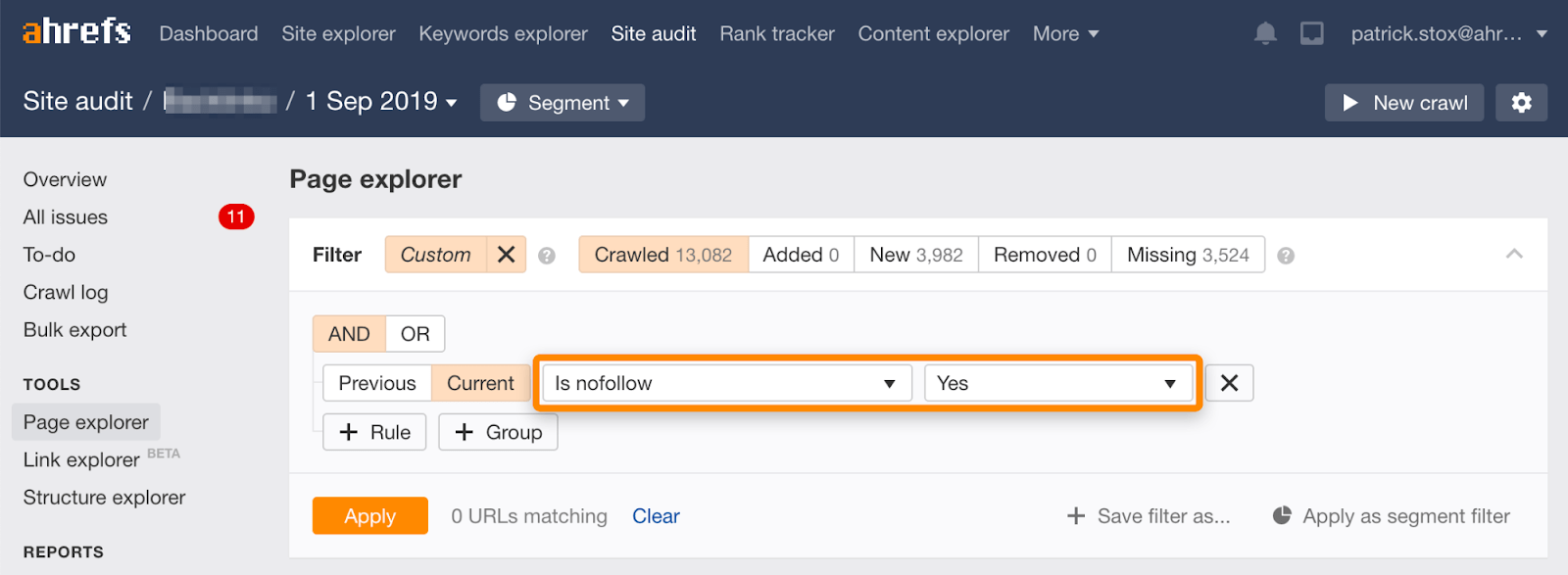
Como rara vez tiene sentido nofollow todos los enlaces de una página, el número de resultados debe ser cero o cercano a cero. Si hay resultados coincidentes, le insto a que compruebe si la directiva nofollow se añadió accidentalmente en lugar de noindex y a que elija un método de eliminación más adecuado si es necesario.
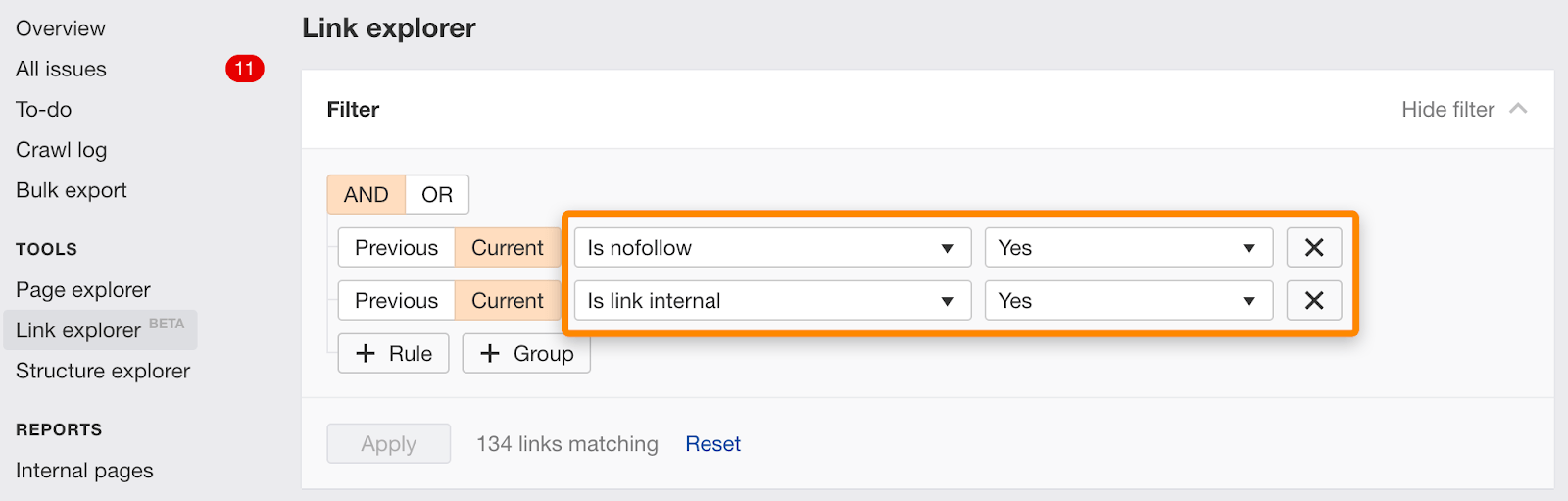
También puede encontrar enlaces individuales marcados como nofollow utilizando este filtro en el Explorador de enlaces.
Noindex y canónicos a otra URL
Estas señales están en conflicto. Noindex dice que se elimine la página del índice, y canonical dice que otra página es la versión que debe indexarse. En realidad, esto puede funcionar para la consolidación, ya que Google generalmente elegirá ignorar el noindex y, en su lugar, usar el canónico como señal principal. Sin embargo, este no es un comportamiento absoluto. Hay un algoritmo involucrado y existe el riesgo de que la etiqueta noindex sea la señal contada. Si ese es el caso, las páginas no se consolidarán correctamente.
Tenga en cuenta que puede encontrar páginas no indexadas con canónicos no autorreferenciales utilizando este conjunto de filtros en el Explorador de páginas en la Auditoría del sitio:
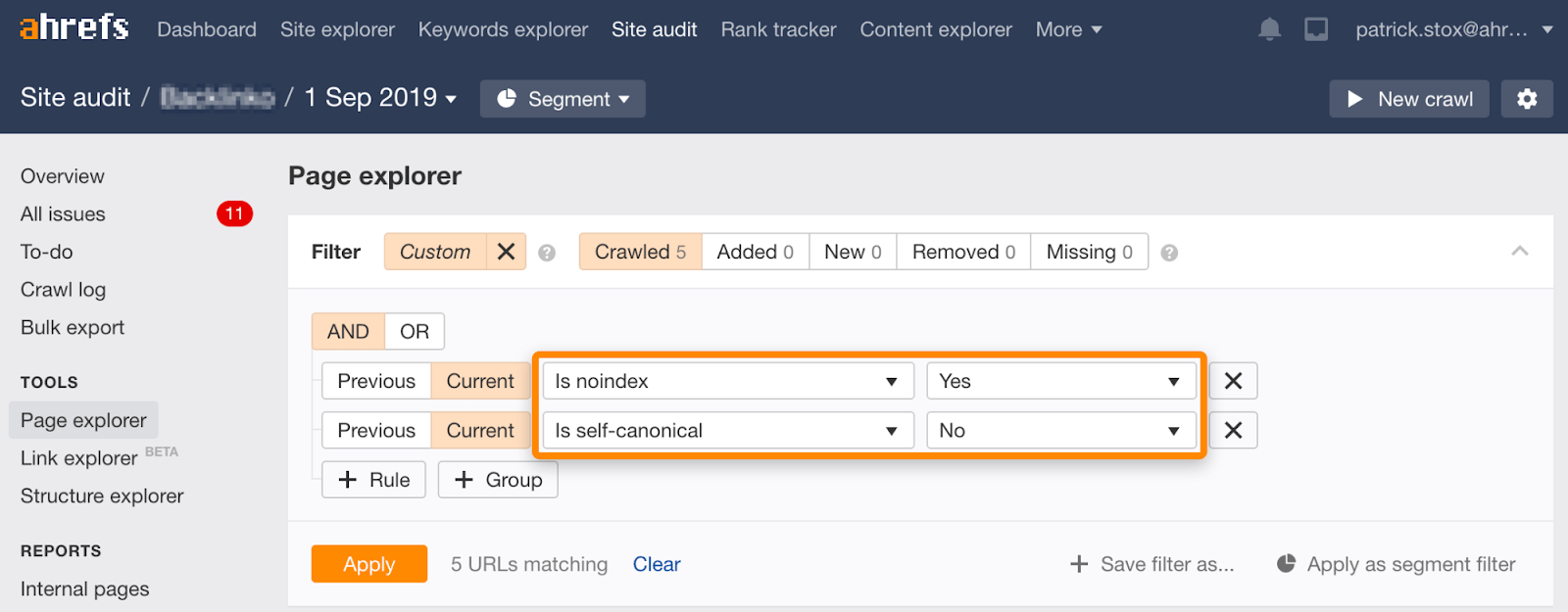
Noindex, espere a que Google rastree, luego bloquee el rastreo
Hay un par de formas en que esto suele ocurrir:
- Las páginas ya están bloqueadas pero están indexados, la gente agrega noindex y desbloquea para que Google pueda rastrear y ver el noindex, luego bloquea las páginas para que no se rastreen de nuevo.
- Las personas agregan etiquetas noindex para las páginas que desean eliminar y, después de que Google haya rastreado y procesado la etiqueta noindex, bloquean el rastreo de las páginas.
De cualquier manera, el estado final se bloquea para que no se rastree. Si recuerdas, antes hablamos de que rastrear no es lo mismo que indexar. A pesar de que estas páginas están bloqueadas, todavía pueden terminar en el índice.
Si es el propietario del contenido que se está utilizando en otro sitio web, es posible que pueda presentar una reclamación basada en la Ley de Derechos de Autor del Milenio Digital (DMCA). Puedes usar la herramienta de eliminación de derechos de autor de Google para hacer lo que se llama eliminación de DMCA, que solicita la eliminación de cualquier material con derechos de autor.
¿Qué pasa si es contenido sobre ti, pero no en un sitio de tu propiedad?
Si estás en la UE, puedes eliminar contenido que contenga información sobre ti gracias a una orden judicial por el derecho al olvido. Puede solicitar que se elimine su información personal utilizando el formulario de Eliminación de Privacidad de la UE.
Para eliminar imágenes de Google, la forma más fácil es con robots.txt. Mientras que el soporte no oficial para eliminar páginas se eliminó de los robots.txt como mencionamos anteriormente, simplemente no permitir el rastreo de imágenes es la forma correcta de eliminar imágenes.
Para una sola imagen:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
en todas las imágenes:
User-agent: Googlebot-ImageDisallow: /
conclusión
Cómo quitar Url es bastante situacional. Hemos hablado de varias opciones, pero si aún está confundido sobre cuál es el adecuado para usted, consulte el diagrama de flujo al principio.
También puedes consultar el solucionador de problemas legales proporcionado por Google para eliminar contenido.
¿Tiene preguntas? Házmelo saber en Twitter.