La estructura del ADN Proporciona un Mecanismo para la Herencia
Los genes llevan información biológica que debe copiarse con precisión para su transmisión a la siguiente generación cada vez que una célula se divide para formar dos células hijas. De estos requisitos surgen dos preguntas biológicas centrales: ¿cómo se puede transportar la información para especificar un organismo en forma química y cómo se copia con precisión? El descubrimiento de la estructura de la doble hélice del ADN fue un hito en la biología del siglo XX porque inmediatamente sugirió respuestas a ambas preguntas, resolviendo así a nivel molecular el problema de la herencia. Discutimos brevemente las respuestas a estas preguntas en esta sección, y las examinaremos con más detalle en capítulos posteriores.
El ADN codifica la información a través del orden, o secuencia, de los nucleótidos a lo largo de cada hebra. Cada base-A, C, T o G-se puede considerar como una letra en un alfabeto de cuatro letras que deletrea mensajes biológicos en la estructura química del ADN. Como vimos en el Capítulo 1, los organismos difieren entre sí porque sus respectivas moléculas de ADN tienen diferentes secuencias de nucleótidos y, en consecuencia, llevan diferentes mensajes biológicos. Pero, ¿cómo se usa el alfabeto de nucleótidos para crear mensajes, y qué deletrean?
Como se mencionó anteriormente, se sabía mucho antes de que se determinara la estructura del ADN que los genes contienen las instrucciones para producir proteínas. Por lo tanto, los mensajes de ADN deben codificar proteínas de alguna manera (Figura 4-6). Esta relación hace que el problema sea inmediatamente más fácil de entender, debido al carácter químico de las proteínas. Como se discutió en el Capítulo 3, las propiedades de una proteína, que son responsables de su función biológica, están determinadas por su estructura tridimensional, y su estructura está determinada a su vez por la secuencia lineal de los aminoácidos de los que está compuesta. Por lo tanto, la secuencia lineal de nucleótidos en un gen debe explicar de alguna manera la secuencia lineal de aminoácidos en una proteína. La correspondencia exacta entre el alfabeto de nucleótidos de cuatro letras del ADN y el alfabeto de aminoácidos de veinte letras de las proteínas, el código genético, no es obvia a partir de la estructura del ADN, y tomó más de una década después del descubrimiento de la doble hélice antes de que se resolviera. En el Capítulo 6 describimos este código en detalle en el curso de la elaboración del proceso, conocido como expresión génica, a través del cual una célula traduce la secuencia de nucleótidos de un gen en la secuencia de aminoácidos de una proteína.

Figura 4-6
La relación entre la información genética transportada en el ADN y las proteínas.
El conjunto completo de información en el ADN de un organismo se llama su genoma, y lleva la información de todas las proteínas que el organismo sintetizará alguna vez. (El término genoma también se usa para describir el ADN que transporta esta información. La cantidad de información contenida en los genomas es asombrosa: por ejemplo, una célula humana típica contiene 2 metros de ADN. Escrita en el alfabeto de nucleótidos de cuatro letras, la secuencia de nucleótidos de un gen humano muy pequeño ocupa un cuarto de página de texto (Figura 4-7), mientras que la secuencia completa de nucleótidos en el genoma humano llenaría más de mil libros del tamaño de este. Además de otra información crítica, lleva las instrucciones de unas 30.000 proteínas distintas.

Figura 4-7
La secuencia de nucleótidos del gen de la β-globina humana. Este gen transporta la información de la secuencia de aminoácidos de uno de los dos tipos de subunidades de la molécula de hemoglobina, que transporta oxígeno en la sangre. Un gen diferente, la α-globina(más…)
En cada división celular, la célula debe copiar su genoma para pasarlo a ambas células hijas. El descubrimiento de la estructura del ADN también reveló el principio que hace posible esta copia: porque cada hebra de ADN que contiene una secuencia de nucleótidos que es exactamente complementarios a la secuencia de nucleótidos de su pareja hebra, cada hebra puede actuar como una plantilla o molde para la síntesis de una nueva cadena complementaria. En otras palabras, si designamos las dos hebras de ADN como S y S’, strand S puede servir como una plantilla para hacer una nueva hebra S’, mientras que la hebra S » puede servir como una plantilla para hacer una nueva hebra S (Figura 4-8). Por lo tanto, la información genética en el ADN se puede copiar con precisión mediante el proceso bellamente simple en el que la hebra S se separa de la hebra S’, y cada hebra separada sirve como una plantilla para la producción de una nueva hebra complementaria que es idéntica a su antigua pareja.
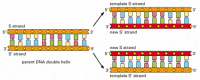
Figura 4-8
ADN como plantilla para su propia duplicación. Como el nucleótido A se empareja con éxito solo con T, y G con C, cada hebra de ADN puede especificar la secuencia de nucleótidos en su hebra complementaria. De esta manera, el ADN de doble hélice se puede copiar con precisión. (mas…)
La capacidad de cada hebra de una molécula de ADN para actuar como una plantilla para producir una hebra complementaria permite a una célula copiar, o replicar, sus genes antes de pasarlos a sus descendientes. En el siguiente capítulo describiremos la elegante maquinaria que utiliza la célula para realizar esta enorme tarea.