- Eh? Ce sunt gruparea SET, CUBE și ROLLUP în SQL?
- De ce mi-ar fi util ROLLUP sau CUBE?
- sunt aceste SQL standard sau sunt un lucru numai Microsoft?
- pot exclude una sau mai multe coloane din pachet?
- ce sunt seturile de grupare atunci? Ar trebui să știu despre ei?
- De ce am vrea să combinăm coloane în orice agregare?
- există mai multe seturi de grupare decât un mod de a face cuburi ‘la carte’?
- De ce sunt furnizate funcțiile Grouping() și Grouping_ID ()?
- Eh? Ce sunt gruparea SET, CUBE și ROLLUP în SQL?
- De ce ar fi ROLLUP sau CUBE util pentru mine?
- sunt aceste SQL standard sau sunt un lucru numai Microsoft?
- pot exclude una sau mai multe coloane din pachet?
- ce sunt seturile de grupare atunci? Ar trebui să știu despre ei?
- De ce am vrea să combinăm coloane în orice agregare?
- există mai multe seturi de grupări decât un mod de a face cuburi ‘la carte’?
- De ce sunt furnizate funcțiile Grouping() și Grouping_ID ()?
Eh? Ce sunt gruparea SET, CUBE și ROLLUP în SQL?
CUBE, ROLLUP și set de grupare sunt operatori opționali ai clauzei GROUP BY din instrucțiunea SELECT pentru a face rapoarte cu cantități mari de informații. Acestea vă permit să faceți mai multe operațiuni de grup într-o singură declarație, economisind potențial mult timp și efort de calcul. Acestea pot furniza toate informațiile necesare pentru raportare, inclusiv totaluri, oferind în același timp performanțe bune pe tabele mari și ajutând Optimizatorul de interogări să elaboreze un plan de execuție bun.
rândurile suplimentare ‘super-agregate’ oferă valori sumare, permițându-vă astfel să aveți mai multe ‘agregări’, cum ar fi SUM() sau MAX() în cadrul unui singur rezultat. Null – urile din aceste rânduri în rezultat sunt destinate să însemne ‘toate’ mai degrabă decât ‘necunoscut’. Vă permite să obțineți toate agregările de care aveți nevoie într-o singură trecere prin tabel. Datorită prezenței unor rânduri suplimentare în rezultate, funcțiile suplimentare GROUPING() și GROUPING_ID() sunt furnizate pentru a indica aceste rânduri suplimentare „super-agregate” și care coloane sunt agregate.
Acest lucru are un mare sens dacă aveți o aplicație care trebuie să ruleze mai multe rapoarte fără calcul suplimentar sau fără a reveni la baza de date: aveți tot ce aveți nevoie într-un singur rezultat.
luați acest exemplu standard de ROLLUP (folosesc AdventureWorks 2012 aici)..
|
1
2
3
4
5
6
|
selectați t. ca regiune, t.name ca teritoriu, suma (TotalDue) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory t pe S. TerritoryID = T. TerritoryID
grup de t., t.nume, datepart(AAAA, OrderDate), datepart(mm, OrderDate)
cu ROLLUP
|
precum și grupul simplu pe rânduri agregate, cu totalul datorat pentru fiecare lună, pe care l-ați obține cu o grupare simplă, veți obține și rânduri subtotale sau super-agregate și, de asemenea, un rând Total Total. (aici este începutul rezultatului)
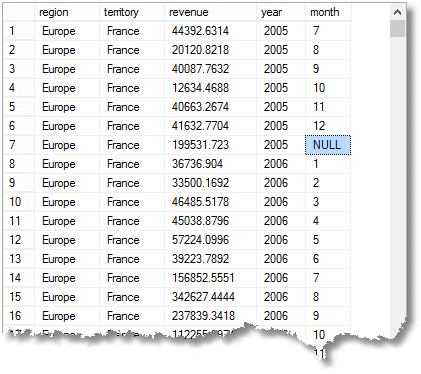
că NULL I ‘ve highlit înseamnă că rândul este un agregat pentru’ toate ‘ lunile anului 2005 în Franța (parte a regiunii Europei)
precum și toate acestea, veți obține totalul datorat pentru fiecare an, pentru fiecare teritoriu și grup teritorial, precum și totalul datorat. (de la sfârșit)
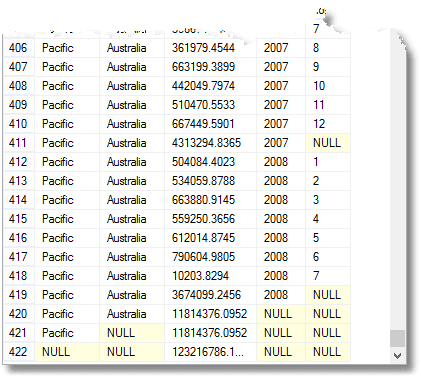
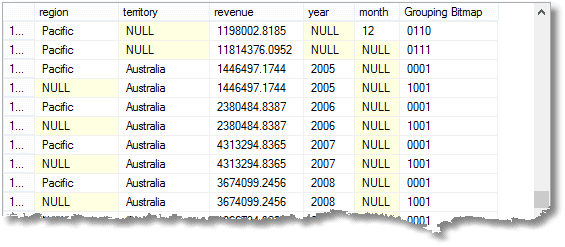
acele nuluri înseamnă ‘toate’, ține minte. Ultimul rând este marele total, iar deasupra acestuia este totalul pentru regiunea Pacificului. Mai presus de aceasta este contribuția Australiei la regiunea Pacificului. Al patrulea rând din partea de jos este contribuția Australiei din 2008. Numărul de grupări care este returnat este unul mai mult decât numărul de expresii din lista de elemente compozite furnizate grupului de declarație.
pentru a obține același efect fără a utiliza pachetul, ar trebui să faceți ceva de genul acesta (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
cu myGrouping (Regiune, teritoriu, totalDue,,)
ca (selectați t., t.name, suma (TotalDue) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.SalesTerritory t pe S. TerritoryID = T. TerritoryID
grup de t.name, T., datepart(AAAA, OrderDate), datepart(mm, OrderDate))
Selectați regiunea, teritoriul, totalDue, ,
din myGrouping
Uniunea toate
Selectați regiunea, teritoriul, suma(totalDue), , NULL
din myGrouping grup de regiune, teritoriu,
Uniunea toate
selectați regiunea, Teritoriul, suma(totaldue), null, null
din grupul mygrouping după regiune, teritoriu
Uniunea toate
Selectați regiunea, null, suma(TOTALDUE), null, null
din grupul mygrouping după regiune
Uniunea toate
selectați null, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.nume, datepart(AAAA,OrderDate),datepart (mm,OrderDate))’
|
această nouă sintaxă vă permite unele funcționalități suplimentare. Amintiți-vă, de asemenea, că ordinea coloanelor afectează grupările de ieșire ale ROLLUP și poate afecta numărul de rânduri din setul de rezultate.
cubul face același lucru general, dar, în loc să ofere o ierarhie a totalurilor în rânduri super-agregate ordonate, oferă toate permutările super-agregate (rânduri super-agregate simetrice), așa-numitele rânduri de tabulare încrucișate. Dacă ați vrut să știți care teritoriu a dat cele mai multe comenzi în martie sau care teritoriu a funcționat cel mai puțin bine în 2006, atunci ați avea nevoie de un cub. Oferiți toate rezumatele posibile în rezultat.
gruparea SET vă permite să reglați fin rezultatul pentru a oferi informații mai specializate de mai sus și dincolo de cub. Acesta poate furniza informații sumare privind combinațiile de dimensiuni. Puteți obține exact același rezultat ca în exemplul nostru de pachet utilizând seturi de grupare, dar cu mult mai multă tastare.
|
1
2
3
4
5
6
7
8
9
10
|
selectați t. ca regiune, t.name ca teritoriu, suma (TotalDue) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory t pe S. TerritoryID = T.TerritoryID
grup de seturi de grupare (
(T., T.name,datepart(AAAA, data comenzii), datepart (ll, data comenzii)),
(T., T.name,data (AAAA, data comenzii)),
(T., T.name),
(T.),
())
|
aceasta este doar pentru a arăta cum se raportează. În realitate, ați recurge la gruparea seturilor pentru a obține rezultate imposibile cu ROLLUP sau CUBE.
aproape toate aceste rezumate pot fi obținute folosind doar grup de, dar numai prin gruparea în mod repetat rezultatul unui grup de, sau de a face mai mult de o trecere prin date.
când utilizați seturi CUBE, ROLLUP sau grupare, nu puteți utiliza cuvântul cheie DISTINCT în expresiile dvs. agregate, cum ar fi AVG (DISTINCT column_name), COUNT (DISTINCT column_name) și SUM (DISTINCT column_name)
De ce ar fi ROLLUP sau CUBE util pentru mine?
ROLLUP și CUBE au avut perioada lor de glorie înainte de SSAS. Au fost utile pentru furnizarea aceluiași tip de facilități oferite de cube în OLAP. Ea are încă utilizările sale, deși. În AdventureWorks, este excesiv, dar dacă gestionați volume mari de date, trebuie să treceți peste datele dvs. o singură dată și să faceți cât mai mult posibil datele care au fost agregate. Evenimentele care au avut loc în trecut nu pot fi schimbate, astfel încât rareori este necesar să se păstreze Date istorice pe un sistem OLTP activ. În schimb, trebuie doar să păstrați datele agregate la nivelul de detaliu (‘granularitate’) necesar pentru toate rapoartele previzibile.
Imaginați-vă că sunteți responsabil pentru raportarea pe un comutator telefonic care are două milioane de apeluri pe zi. Dacă păstrați toate aceste apeluri pe serverul OLTP, în curând veți găsi SQL Server care lucrează peste rapoartele de utilizare. Trebuie să păstrați informațiile originale de apel pentru o perioadă de timp legală, dar determinați din companie că acestea sunt, cel mult, interesate doar de numărul de apeluri într-un minut. Apoi, ați redus cerința de stocare pe serverul OLTP la 1.4% din ceea ce a fost, iar înregistrările de apel pot fi arhivate pe un alt server SQL pentru interogări ad-hoc și declarațiile clientului. Este posibil să fie o economie care merită făcută. Clauzele cub și ROLLUP vă permit să stocați chiar și totalurile rând, totaluri coloană și totaluri mari, fără a fi nevoie să facă un tabel, sau index grupate, scanare a tabelului rezumat.
atâta timp cât modificările nu sunt făcute retrospectiv la aceste date și toate perioadele de timp sunt complete, nu trebuie să repetați sau să modificați agregările pe baza perioadelor de timp anterioare, deși totalurile mari vor trebui să fie supra-scrise!.
să ne prefacem, dar folosind AdventureWorks2012 astfel încât să puteți juca de-a lungul.
În primul rând, vom crea tabelul rezumat gram.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
dacă există (selectați * din tempdb.sys.#AggregationTable%’)
DROP TABLE #aggregationTable –ștergeți tabelul temporar dacă există
GO
selectați
identitate(INT,1,1) ca, – deci putem avea o coloană unică
t. ca regiune, t.name ca teritoriu, suma (TotalDue) ca venit,
datepart(AAAA , data comenzii) ca, datepart(mm, data comenzii) ca,
grupare(t.name) ca isNameGroup ,– aceasta se referă la toate teritoriile
grupare(t.) Ca isGroupGroup,–se referă la toate continentele
grupare(datepart(AAAA, OrderDate)) ca isYearGroup,–se referă la toți anii
grupare(datepart(mm, OrderDate)) ca isMonthGroup,–se referă la toate lunile
Grupare_id (t.name, t.,
datepart(AAAA,OrderDate), datepart(mm, OrderDate)) ca isGroupingRow
-este acesta un rând suplimentar non-date care conține date agregate
în #AggregationTable
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory t pe S. TerritoryID = T.TerritoryID
grup de t.name, t., datepart(AAAA, OrderDate), datepart(mm, OrderDate)
cu ROLLUP
|
observați că adăugăm coloane ” bit ” suplimentare care ne spun ce rânduri conțin rândurile sumare. Dacă le adăugați în mod eronat la alte agregări, veți obține rezultate foarte umflate. Nu puteți utiliza Grouping() sau Grouping_ID pe rezultatul salvat, evident, deci ar trebui să furnizați ceva în locul acestuia.
acum putem produce tabelul pivot foarte rapid
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
– acum putem crea un tabel pivot simplu cu rând și
– totaluri coloană
selectați teritoriul,
sum(caz în care 2005, apoi revenue ELSE 0 END) AS,
sum(caz în care 2006, apoi revenue ELSE 0 END) AS,
sum(caz în care 2007, apoi revenue ELSE 0 END) AS,
sum(caz în care 2008, apoi revenue ELSE 0 END) AS,
sum(venit) ca
din #AggregationTable
unde ISGROUPINGROW =0
grup după teritoriu
Uniune toate
selectați ‘total’, sum(caz în care 2005, apoi venituri else 0 end) as,
sum(caz în care 2006, apoi venituri else 0 end) as,
sum(caz în care 2007, apoi venituri else 0 end) as,
sum (caz în care 2007, apoi venituri else 0 end) as ,
sum(cazul în care 2008, atunci venituri else 0 END) ca,
sum(venituri) ca
din #AggregationTable
unde isYearGroup =0 și isMonthGroup=1
|
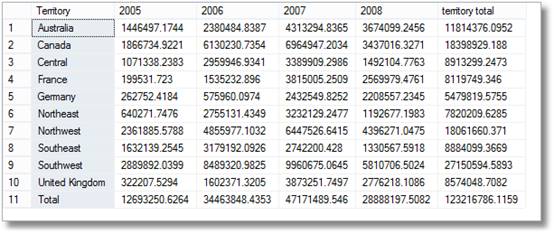
deci, există zâmbete scurte de la manageri care văd acest lucru, dar apoi spun cu strălucire ‘sunt sigur că am cerut și o defalcare pe teritoriu pe lună
cu un chicotit scurt, faceți asta.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SELECT
datename(MONTH,dateadd(MONTH, ,’01 dec 2000′)) AS ,
sum(caz teritoriu când „Australia”, apoi venituri else 0 END) AS,
sum(caz teritoriu când „Canada”, apoi venituri else 0 END) AS,
sum(caz teritoriu când „Canada”, apoi venituri ELSE 0 END) AS,
sum(caz teritoriu când „Canada”, apoi venituri ELSE 0 END) AS,
sum(caz teritoriu când „Canada”, atunci venituri ELSE 0 END) AS,
sum(caz teritoriu când „Canada”, atunci venituri ELSE 0 END) AS,
sum(caz teritoriu 0 end) ca,
sum (teritoriu caz când ‘Franța’, apoi venituri else 0 end) ca,
sum (teritoriu caz când ‘Germania’, apoi venituri else 0 end) ca,
sum (teritoriu caz când ‘nord-est’, apoi venituri else 0 end) ca,
sum (teritoriu caz când ‘nord-est’, apoi venituri else 0 end) ca,
sum (teritoriu Atunci când ‘Nord-Vest’, atunci venituri ELSE 0 END) ca,
sum(teritoriu caz când ‘Sud-Est’, atunci venituri else 0 END) ca,
sum(teritoriu caz când ‘Sud-Vest’, atunci venituri else 0 END) ca,
sum(teritoriu caz când ‘Regatul Unit’, atunci venituri else 0 END) ca,
sum(venit) ca
din #AggregationTable
unde ISGROUPINGROW =0
grup după lună
Uniune toate
selectați
‘total’,
sumă(teritoriu caz când ‘Australia’ atunci venituri altceva 0 sfârșit) ca,
sumă(teritoriu caz când ‘Australia’ atunci venituri altceva 0 sfârșit) ca,
sumă (teritoriu caz Venit ELSE 0 END) ca ,
sum(caz teritoriu când ‘Central’ apoi venituri else 0 END) ca ,
sum(caz teritoriu când ‘Franța’ apoi venituri else 0 END) ca ,
sum(caz teritoriu când ‘Germania’ apoi venituri else 0 END) ca ,
sum(caz teritoriu când ‘Nord-Est’ apoi venituri else 0 END) ca ,
sum(caz teritoriu când ‘Nord-Est’ apoi venituri else 0 END) ca ,
sum(caz teritoriu nord-vest ‘apoi venituri else 0 end) ca ,
sum(caz teritoriu când’ sud-est ‘atunci venituri else 0 end) ca ,
sum (caz teritoriu când’ sud-vest ‘atunci venituri else 0 end) ca,
suma(teritoriul cazului în care”Regatul Unit”, atunci venituri else 0 END) ca,
suma(venituri) ca
din #AggregationTable
unde isGroupingrow =0
|
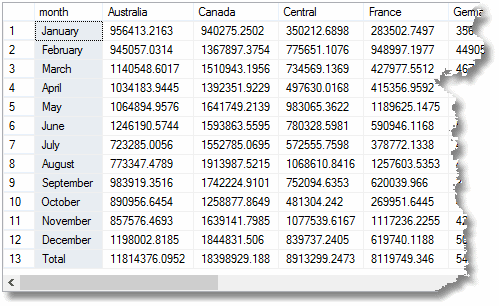
dar dacă ai fi folosit cub în loc de Rollup, ultimul rând ‘total’ ar fi deja calculat. Într-un exemplu real, care ar costa timp pentru a face raportul. Puteți face un cub pe până la zece dimensiuni; deși tind să adune agregarea, nu sunt prea costisitoare.
sunt aceste SQL standard sau sunt un lucru numai Microsoft?
acestea sunt acum Standard ANSI SQL din 1999, deși cu CUBE și cu ROLLUP au fost introduse pentru prima dată de Microsoft. Această includere este oarecum surprinzătoare prin faptul că introduc un al doilea sens, ‘toate’, pentru valoarea nulă în afară de ‘necunoscut’. Când Microsoft a introdus pentru prima dată CUBE și ROLLUP, sintaxa a fost ușor diferită, dar ambele forme sunt permise în SQL Server. Un singur stil de sintaxă poate fi utilizat într-o singură instrucțiune SELECT și ar trebui să utilizați sintaxa compatibilă ISO pentru toate lucrările noi.
pot exclude una sau mai multe coloane din pachet?
Dacă vrei! Imaginați-vă că nu am vrut un total super-agregat pentru toate regiunile (t.)
|
1
2
3
4
5
6
|
selectați t. ca regiune, t.name ca teritoriu, suma (TotalDue) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.SalesTerritory t pe S. TerritoryID = T. TerritoryID
grup de t., ROLLUP (t.name, datepart(AAAA, OrderDate), datepart (mm, OrderDate))
|
aici folosim sintaxa compatibilă ANSI SQL 2006. Puteți face același lucru cu un cub. Nu am găsit niciodată o utilizare practică pentru acest lucru, dar s-ar putea să-l întâlniți
ce sunt seturile de grupare atunci? Ar trebui să știu despre ei?
setul de grupare înseamnă că cereți SQL să grupeze rezultatul de mai multe ori. Puteți utiliza sintaxa seturilor de grupare pentru a specifica exact ce agregări să calculați. Iată un exemplu.
|
1
2
3
4
5
6
|
selectați t. ca regiune, t.name ca teritoriu, suma (TotalDue) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory T pe s.TerritoryID = T. TerritoryID
grup de t., seturi de grupare(ROLLUP(t.name),
ROLLUP(datepart(AAAA, OrderDate), datepart(mm, OrderDate)))
|
aici solicitați defalcarea pe grupuri de teritorii pentru fiecare lună a fiecărui an cu totaluri de luni și ani, urmată de un total rezumat după numele teritoriului, dar fără un total mare. Spre deosebire de pachet, obțineți același rezultat indiferent de ordinea coloanelor din fiecare SET de grupare și de ordinea seturilor de grupare.
seturile de grupare vă pot oferi exact ceea ce vă oferă CUBE și ROLLUP și multe altele. După cum puteți vedea în acest ultim exemplu, puteți utiliza cubul și setul standard ‘table d’ h xvte ‘amestecat împreună cu seturile de grupare ‘hectar la carte’ exprimate direct.
De ce am vrea să combinăm coloane în orice agregare?
În cazul în care două coloane ar trebui combinate în unele rapoarte, este util să se declare o agregare care combină două coloane. În primul exemplu combinăm anul și luna pentru rollup, având ca efect restricționarea totalurilor doar la fiecare teritoriu,
|
1
2
3
4
5
6
7
|
–obține totalurile pentru fiecare teritoriu numai – nu totaluri pentru fiecare regiune sau an
selectați t. ca regiune, t.numele ca teritoriu, suma (suma totală) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory t pe S. TerritoryID = T. TerritoryID
grup de t., t.name, ROLLUP
((datepart(AAAA, OrderDate), datepart(mm, OrderDate)))
|
această paranteză suplimentară din clauza ROLLUP a avut ca efect restricționarea agregărilor doar la teritoriu și la lună / an. Lăsați-le afară și veți obține totaluri pentru fiecare an.
|
1
2
3
4
5
6
7
8
9
10
|
– obțineți totalurile pentru fiecare an în cadrul fiecărui teritoriu, precum și totalurile
–pentru fiecare teritoriu
–nu există totaluri pentru fiecare regiune
selectați t. ca regiune, t.numele ca teritoriu, suma (suma totală) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory t pe S. TerritoryID = T. TerritoryID
grup de t., t.name, ROLLUP
(datepart(AAAA, OrderDate), datepart(mm, OrderDate))
|
Acest lucru poate fi foarte util pentru anumite date. Am evitat să combinăm coloanele aici. Dacă ați face un cub, iar termenii pentru teritorii au folosit cuvinte precum ‘Nord’ sau ‘ Sud ‘pentru a descrie un teritoriu din mai multe regiuni, ați avea câteva agregări bizare care se aplică teritoriilor’ nordice ‘ care nu au legătură. Prin combinarea coloanelor, ați evita acest lucru.
există mai multe seturi de grupări decât un mod de a face cuburi ‘la carte’?
nu sunt sigur că aș fi timid să pun această întrebare. SQL:Seturile de grupare din 1999 oferă o sintaxă recursivă bogată care vă permite să agregați combinații de coloane și să definiți tot felul de rapoarte ezoterice care oferă până la zece dimensiuni. Agregările pot fi imbricate și puteți cuib cuburi în ROLLUPs și ROLLUPs cuib în cuburi. Va trebui să citiți o publicație de specialitate pentru a afla mai multe despre acest lucru.
De ce sunt furnizate funcțiile Grouping() și Grouping_ID ()?
nu este chiar o idee bună să folosiți NULL pentru a semnifica că o coloană este o agregare. Problema este că, dacă o coloană de grupare conține valori nule, toate valorile nule sunt considerate egale și puse într-un singur grup nul care se maschează ca rezumat. Pentru a ocoli dificultatea evidentă a valorilor nule din datele originale, sunt furnizate două funcții: Grouping() și Grouping_ID().
funcțiaGrouping() este transmisă numele unei coloane care a participat la setul de pachete, cub sau grupare. Returnează zero dacă acest rând este un rezumat pentru această coloană cu o valoare nulă care înseamnă ‘toate’ sau dacă conține o valoare.
funcției GROUPING_ID i se transmite o listă care trebuie să corespundă exact expresiei din lista GROUP BY. GROUPING_ID este creat ca un bitmap al coloanelor sumare respective. Dacă, de exemplu, coloana teritoriu are un nul care înseamnă ‘toate’ teritoriile, mai degrabă decât un nume de teritoriu, și este listat ca a doua coloană, atunci al doilea bit din stânga este setat. Acest număr întreg este apoi returnat.
Grouping_ID() este utilizat în general pentru a indica dacă rândul este o agregare primară sau secundară (0 sau>0) și, dacă este secundar, apoi exclus din orice grup ulterior prin manipulare.
de obicei, este considerată o bună practică includerea unei coloane de biți pentru fiecare dimensiune (cum ar fi”teritoriu”sau” regiune „în exemplul nostru) care este setată dacă rândul este un rezumat pentru acea dimensiune, împreună cu o valoareGrouping_ID() pentru a ajuta orice grupare ulterioară a rezultatului.
pentru a ilustra modul în care Grouping_ID funcționează de fapt, aici ajungem să ne uităm la modul în care biții din Grouping_ID sunt setați în funcție de tipul de rezumat. Vom folosi funcția lui Phil Factor ToBinaryString pentru a arăta biții.
|
1
2
3
4
5
6
7
8
9
|
selectați t. ca regiune, t.numele ca teritoriu, suma (suma totală) ca venit,
datepart(AAAA, data comenzii) ca , datepart(mm, data comenzii) ca ,
dreapta (
dbo.ToBinaryString (–listează toate grupurile după elemente așa cum sunt
Grouping_ID(t., t.name, datepart(AAAA, OrderDate),datepart (mm, OrderDate))
),4) Ca –utilizați doar ultimele patru caractere, deoarece avem patru coloane în lista noastră.
din vânzări.SalesOrderHeader s
interior se alăture vânzări.Salesteritory t pe S. TerritoryID = T. TerritoryID
grup de cub(t., t.nume, datepart(AAAA, OrderDate),datepart(mm, OrderDate))
|
Acest lucru dă (doar un eșantion, desigur)…