
acesta este un punct important de înțeles. Nu numai că utilizarea unei metode greșite duce uneori la eliminarea paginilor din index așa cum se intenționează, dar poate avea și un efect negativ asupra SEO.
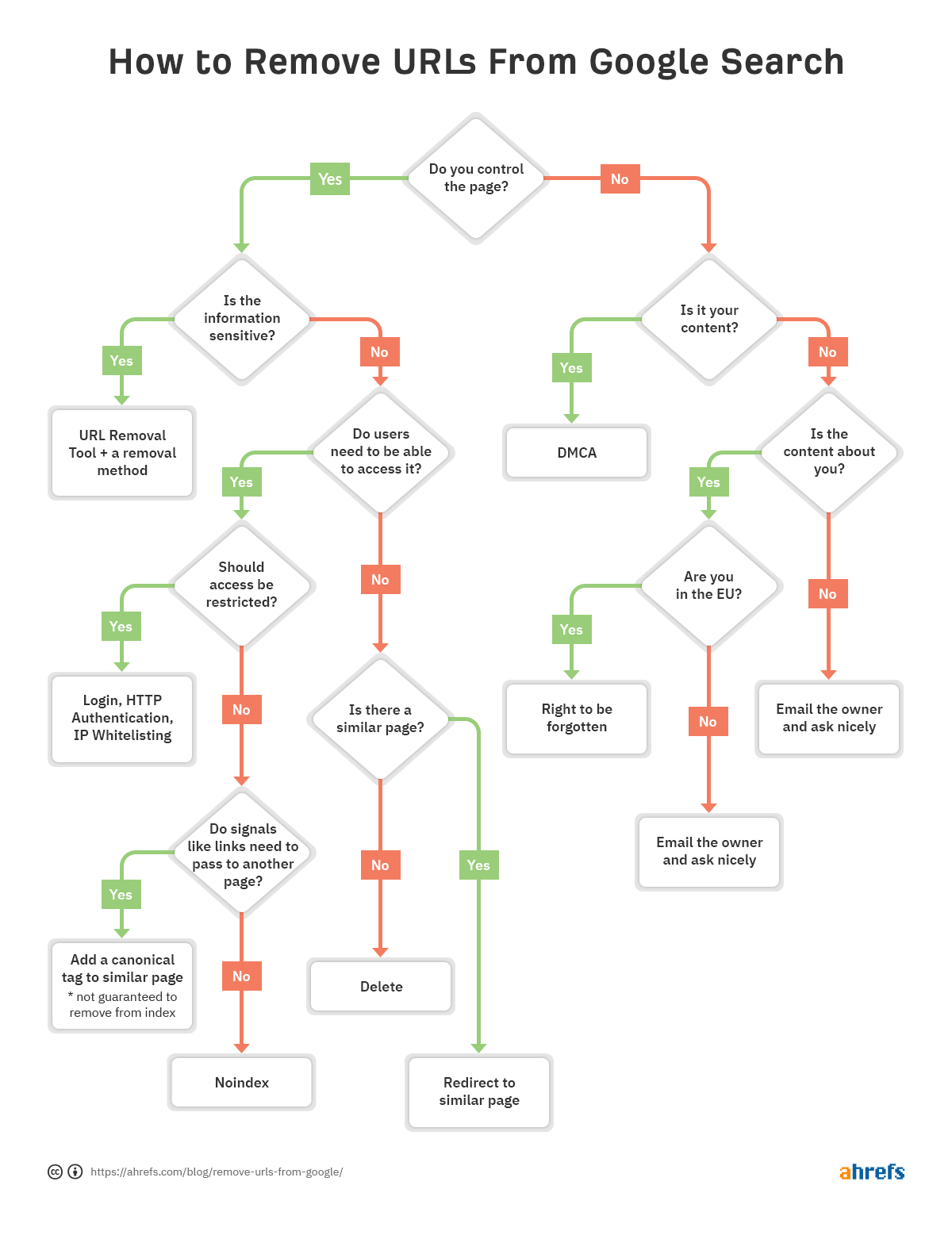
pentru a vă ajuta să decideți rapid ce metodă de eliminare este cea mai potrivită pentru dvs., am realizat o diagramă de flux, astfel încât să puteți trece la secțiunea relevantă a articolului.
În acest post, veți afla:
- cum de a verifica dacă un URL este indexat
- cinci moduri de a elimina URL-uri de la Google
- cum să acorde prioritate mutări
- greșeli comune de eliminare pentru a evita
- Cum de a elimina conținut care nu este pe site-ul
- Cum de a elimina imagini
ceea ce văd de obicei SEO face pentru a verifica dacă conținutul este indexat este utilizarea unui site: căutare în Google (de exemplu, site-ul:https://ahrefs.com). În timp ce site-ul: căutările pot fi utile pentru identificarea paginilor sau secțiunilor unui site web care pot fi problematice dacă se afișează în rezultatele căutării, trebuie să fiți atenți, deoarece nu sunt interogări normale și nu vă vor spune de fapt dacă o pagină este indexată. Acestea pot afișa pagini cunoscute de Google, dar asta nu înseamnă că sunt eligibile să apară în rezultatele normale ale căutării fără site: operator.
de exemplu, căutările site: pot afișa în continuare pagini care redirecționează sau sunt canonicalizate către o altă pagină. Când solicitați un anumit site, Google poate afișa o pagină din acel domeniu cu conținutul, titlul și descrierea dintr-un alt domeniu. Luați de exemplu moz.com care a fost seomoz.org. orice întrebări obișnuite ale utilizatorilor care duc la pagini pe moz.com va arăta moz.com în SERP, în timp ce site:seomoz.org va arăta seomoz.org în rezultatele căutării așa cum se arată mai jos.
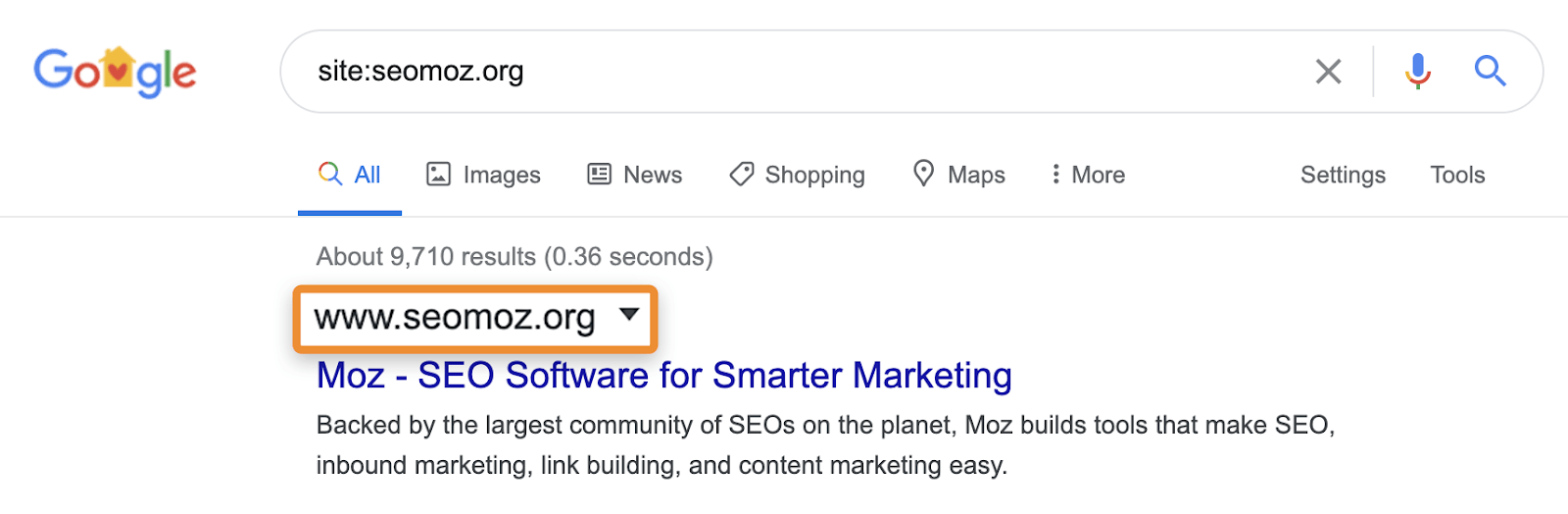
motivul pentru care aceasta este o distincție importantă este că poate determina SEO-urile să facă greșeli, cum ar fi blocarea activă sau eliminarea URL-urilor din index pentru vechiul domeniu, ceea ce împiedică consolidarea semnalelor precum PageRank. Am văzut multe cazuri cu migrații domeniu în cazul în care oamenii cred că au făcut o greșeală în timpul migrației, deoarece aceste pagini arată încă pentru site:old-domain.com caută și sfârșesc prin a afecta în mod activ site-ul lor în timp ce încearcă să „remedieze” problema.
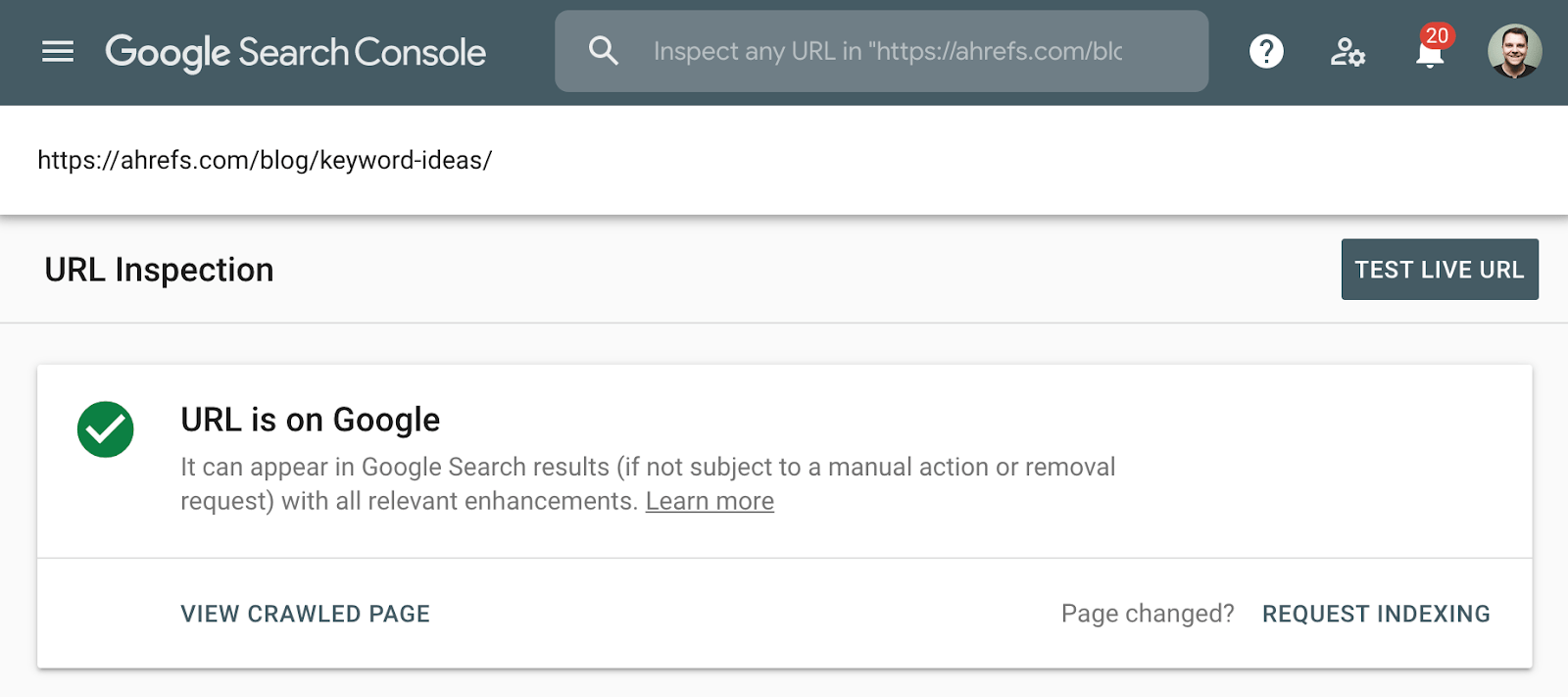
cea mai bună metodă pentru a verifica indexarea este să utilizați raportul de acoperire a indexului din Google Search Console sau instrumentul de inspecție URL pentru o adresă URL individuală. Aceste instrumente vă spun dacă o pagină este indexată și oferă informații suplimentare despre modul în care Google tratează pagina. Dacă nu aveți acces la acest lucru, pur și simplu căutați pe Google adresa URL completă a paginii dvs.
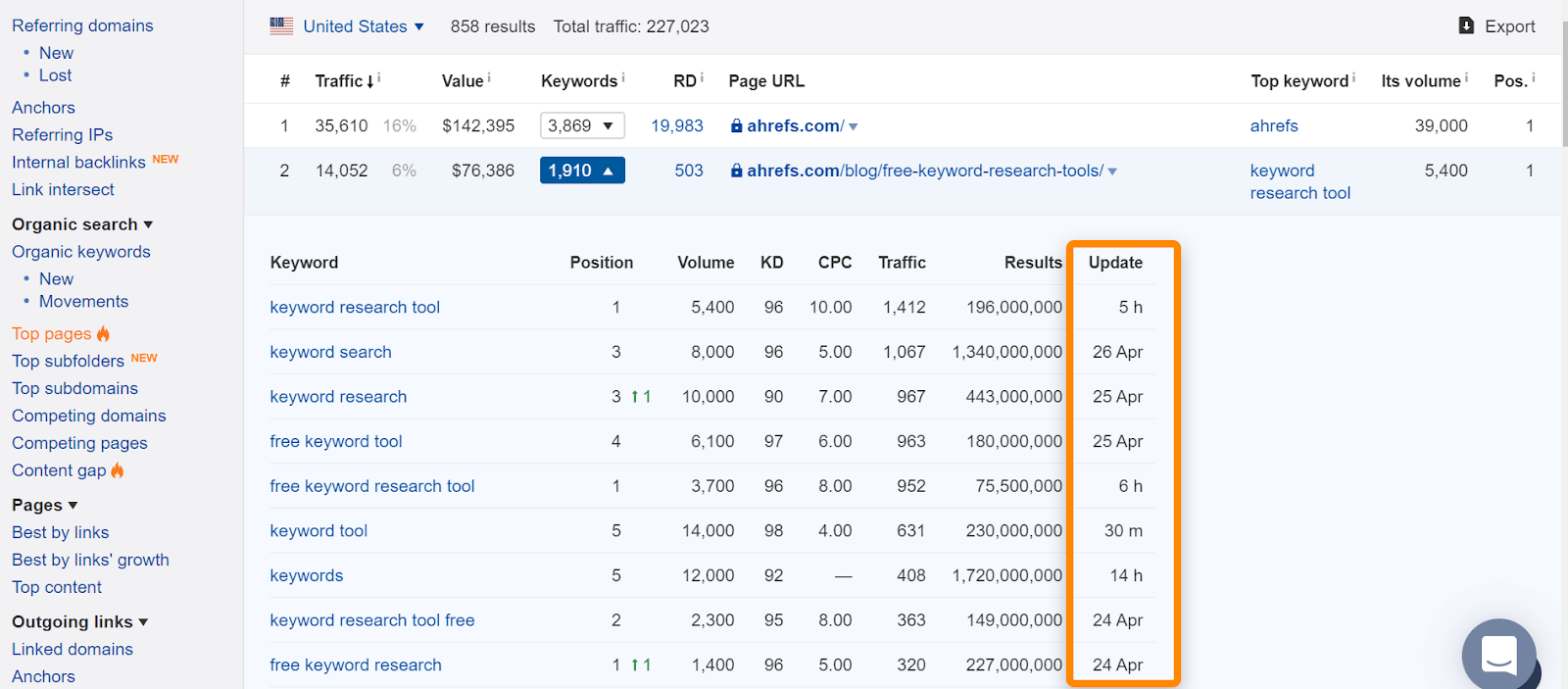
în Ahrefs, dacă găsiți pagina în raportul nostru „pagini de Top” sau în clasamentul cuvintelor cheie organice, înseamnă că am văzut-o clasându-se pentru interogările normale de căutare și este un bun indiciu că pagina a fost indexată. Rețineți că paginile au fost indexate când le-am văzut, dar este posibil să se fi schimbat. Verificați data la care am văzut ultima dată pagina pentru o interogare.
dacă există o problemă cu o anumită adresă URL și trebuie eliminată din index, urmați diagrama de la începutul articolului pentru a găsi opțiunea corectă de eliminare, apoi treceți la secțiunea corespunzătoare de mai jos.
dacă eliminați pagina și difuzați fie un cod de stare 404 (not found), fie 410 (gone), atunci pagina va fi eliminată din index la scurt timp după ce pagina este re-accesată cu crawlere. Până când este eliminată, pagina poate apărea în continuare în rezultatele căutării. Și chiar dacă pagina în sine nu mai este disponibilă, o versiune cache a paginii poate fi disponibilă temporar.
când este posibil să aveți nevoie de o altă opțiune:
- am nevoie de o eliminare mai imediată. Consultați secțiunea instrument de eliminare URL.
- am nevoie pentru a consolida semnale cum ar fi link-uri. Vezi secțiunea canonicalizare.
- am nevoie de pagina disponibilă pentru utilizatori. Vedeți dacă secțiunile noindex sau restricționarea accesului se potrivesc situației dvs.
- opțiunea de eliminare 2: Noindex
- opțiunea de eliminare 3: restricționarea accesului
- opțiunea de eliminare 4: instrumentul de eliminare URL
- opțiunea de eliminare 5: Canonicalizare
- Noindex în roboți.txt
- blocarea de la crawling în roboți.Txt
- Nofollow
- Noindex și canonical la un alt URL
- Noindex, așteptați ca Google să acceseze cu crawlere, apoi blocați accesarea cu crawlere
- ce se întâmplă dacă este conținut despre tine, dar nu pe un site pe care îl dețineți?
- Gânduri finale
opțiunea de eliminare 2: Noindex
o etichetă noindex meta robots sau răspunsul antetului x‑robots va spune motoarelor de căutare să elimine o pagină din index. Eticheta meta robots funcționează pentru paginile în care răspunsul x-robots funcționează pentru pagini și tipuri de fișiere suplimentare, cum ar fi PDF-uri. Pentru ca aceste etichete să fie văzute, un motor de căutare trebuie să poată accesa cu crawlere paginile—deci asigurați-vă că nu sunt blocate în roboți.txt. De asemenea, rețineți că eliminarea paginilor din index poate împiedica consolidarea legăturii și a altor semnale.
exemplu de meta roboți noindex:
<meta name="robots" content="noindex">
exemplu de etichetă x‑robots noindex în răspunsul antetului:
HTTP/1.1 200 OKX-Robots-Tag: noindex
când este posibil să aveți nevoie de o altă opțiune:
- Nu vreau ca utilizatorii să acceseze aceste pagini. Consultați secțiunea restricționarea accesului.
- am nevoie pentru a consolida semnale cum ar fi link-uri. Vezi secțiunea canonicalizare.
opțiunea de eliminare 3: restricționarea accesului
Dacă doriți ca pagina să fie accesibilă unor utilizatori, dar nu motoarelor de căutare, atunci ceea ce probabil doriți este una dintre aceste trei opțiuni:
- un fel de sistem de conectare;
- autentificare HTTP (unde este necesară o parolă pentru acces);
- IP Whitelisting (care permite doar adrese IP specifice pentru a accesa paginile)
Acest tip de configurare este cel mai bun pentru lucruri cum ar fi rețele interne, conținut numai membru, sau pentru stadializare, testare, sau site-uri de dezvoltare. Permite unui grup de utilizatori să acceseze pagina, dar motoarele de căutare nu le vor putea accesa și nu vor indexa paginile.
când este posibil să aveți nevoie de o altă opțiune:
- am nevoie de o eliminare mai imediată. Consultați secțiunea instrument de eliminare URL. În acest caz particular, este posibil să doriți o eliminare mai imediată dacă conținutul pe care încercați să îl ascundeți a fost memorat în cache și trebuie să împiedicați utilizatorii să vadă acel conținut.
opțiunea de eliminare 4: instrumentul de eliminare URL
numele acestui instrument de la Google este ușor înșelător, deoarece modul în care funcționează este că va ascunde temporar conținutul. Google va vedea și va accesa cu crawlere acest conținut, dar paginile nu vor apărea pentru utilizatori. Acest efect temporar durează șase luni în Google, în timp ce Bing are un instrument similar care durează trei luni. Aceste instrumente ar trebui utilizate în cele mai extreme cazuri pentru lucruri precum probleme de securitate, scurgeri de date, informații de identificare personală (PII) etc. Pentru Google, Utilizați instrumentul de eliminare și pentru Bing, consultați Cum să blocați adresele URL.
trebuie totuși să aplicați o altă metodă împreună cu utilizarea instrumentului de eliminare pentru a elimina efectiv paginile pentru o perioadă mai lungă (noindex sau ștergere) sau pentru a împiedica utilizatorii să acceseze conținutul dacă mai au linkurile (ștergeți sau restricționați accesul). Acest lucru vă oferă doar o modalitate mai rapidă de a ascunde paginile în timp ce eliminarea are timp să proceseze. Solicitarea poate dura până la o zi pentru procesare.
opțiunea de eliminare 5: Canonicalizare
când aveți mai multe versiuni ale unei pagini și doriți să consolidați semnale precum linkuri către o singură versiune, ceea ce doriți să faceți este o formă de canonicalizare. Acest lucru este în mare parte pentru a preveni conținutul duplicat, consolidând în același timp mai multe versiuni ale unei pagini la o singură adresă URL indexată.
aveți mai multe opțiuni de canonizare:
- etichetă canonică. Aceasta specifică o altă adresă URL ca versiune canonică sau versiunea pe care doriți să o afișați. Dacă paginile sunt duplicate sau foarte similare, acest lucru ar trebui să fie bine. Când paginile sunt prea diferite, canonicul poate fi ignorat, deoarece este un indiciu și nu o directivă.
- redirecționări. O redirecționare duce un utilizator și un bot de căutare de la o pagină la alta. 301 este cea mai frecvent utilizată redirecționare de către SEO și spune motoarelor de căutare că doriți ca adresa URL finală să fie cea afișată în rezultatele căutării și unde semnalele sunt consolidate. O redirecționare 302 sau temporară spune motoarelor de căutare că doriți ca adresa URL originală să rămână în index și să consolideze semnalele acolo.
- manipularea parametrilor URL. Un parametru este adăugat la sfârșitul URL-ului și include de obicei un semn de întrebare, cum ar fi ahrefs.com?this=parameter. acest instrument de la Google vă permite să le spuneți cum să trateze adresele URL cu parametri specifici. De exemplu, puteți specifica dacă parametrul modifică conținutul paginii sau dacă este doar menit să urmărească utilizarea.
Dacă aveți mai multe pagini de eliminat din indexul Google, atunci acestea ar trebui să fie prioritizate în consecință.
prioritate maximă: aceste pagini sunt de obicei legate de securitate sau legate de date confidențiale. Aceasta include conținut care conține date personale( PII), date despre clienți sau informații proprietare.
prioritate medie: aceasta implică de obicei conținut destinat unui anumit grup de utilizatori. Intranet-urile companiei sau portalurile angajaților, conținutul destinat numai membrilor și mediile de stadializare, testare sau dezvoltare.
prioritate scăzută: aceste pagini implică de obicei conținut duplicat de un fel. Câteva exemple în acest sens ar include pagini difuzate din mai multe adrese URL, adrese URL cu parametri și, din nou, ar putea include medii de intermediere, testare sau dezvoltare.
vreau să acopăr câteva dintre modurile în care văd de obicei eliminările făcute incorect și ce se întâmplă în fiecare scenariu pentru a ajuta oamenii să înțeleagă de ce nu funcționează.
Noindex în roboți.txt
în timp ce Google obișnuia să sprijine neoficial noindex în roboți.txt, nu a fost niciodată un standard oficial și acum au eliminat oficial sprijinul. Multe dintre site-urile care făceau acest lucru făceau acest lucru incorect și se răneau.
blocarea de la crawling în roboți.Txt
Crawling nu este același lucru cu indexarea. Chiar dacă Google este blocat de accesarea cu crawlere a paginilor, dacă există linkuri interne sau externe către o pagină, acestea o pot indexa în continuare. Google nu va ști ce este pe pagină, deoarece nu o va accesa cu crawlere, dar știu că există o pagină și chiar va scrie un titlu pentru a fi afișat în rezultatele căutării pe baza semnalelor precum textul ancoră al linkurilor către pagină.
Nofollow
Acest lucru devine frecvent confuz pentru noindex, iar unii oameni îl vor folosi la nivel de pagină așteptând ca pagina să nu fie indexată. Nofollow este un indiciu și, deși inițial a oprit linkurile de pe pagină și linkurile individuale cu atributul nofollow să fie accesate cu crawlere, nu mai este cazul. Google poate accesa cu crawlere aceste link-uri dacă doresc. Nofollow a fost, de asemenea, utilizat pe link-uri individuale pentru a încerca să oprească Google să acceseze cu crawlere anumite pagini și pentru sculptura PageRank. Din nou, acest lucru nu mai funcționează, deoarece nofollow este un indiciu. În trecut, dacă pagina avea un alt link către aceasta, atunci Google ar putea descoperi în continuare din această cale alternativă de accesare cu crawlere.
rețineți că puteți găsi pagini nofollowed în bloc folosind acest filtru în Exploratorul de pagini din auditul site-ului Ahrefs.
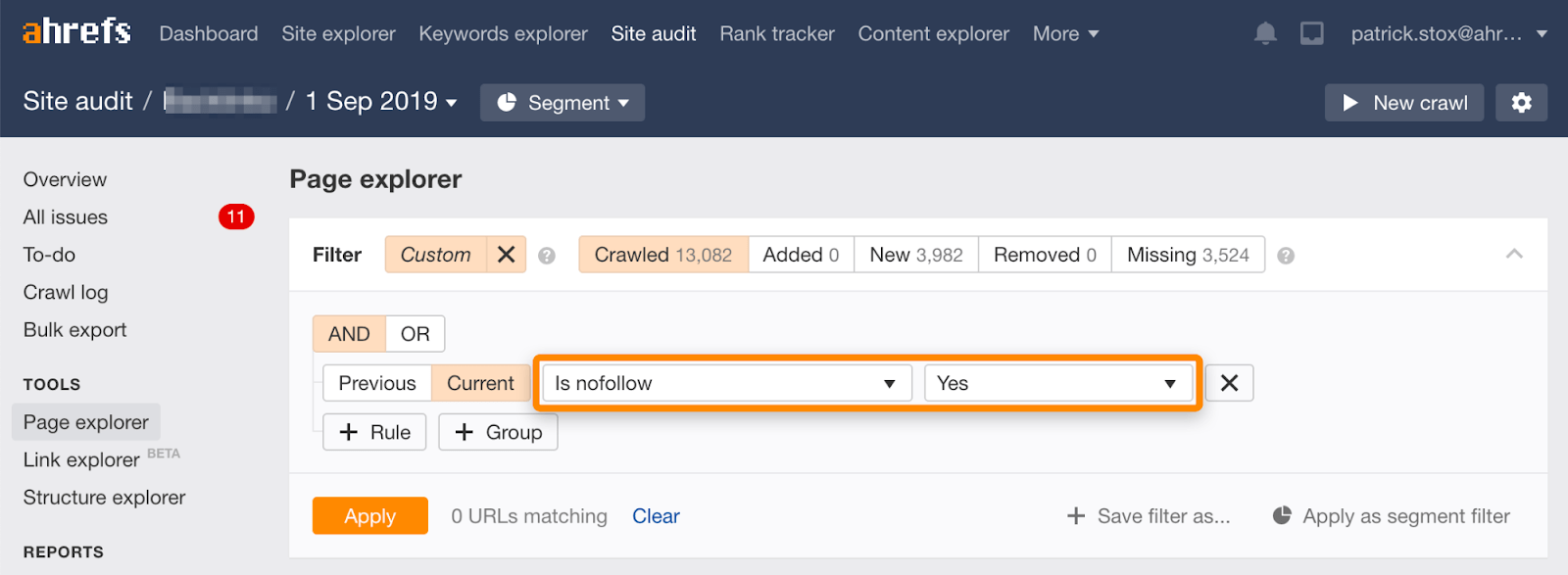
deoarece rareori are sens să nofollow toate linkurile de pe o pagină, Numărul de rezultate ar trebui să fie zero sau aproape de zero. Dacă există rezultate potrivite, vă îndemn să verificați dacă Directiva nofollow a fost adăugată accidental în locul noindex și să alegeți o metodă mai adecvată de Eliminare, dacă este necesar.
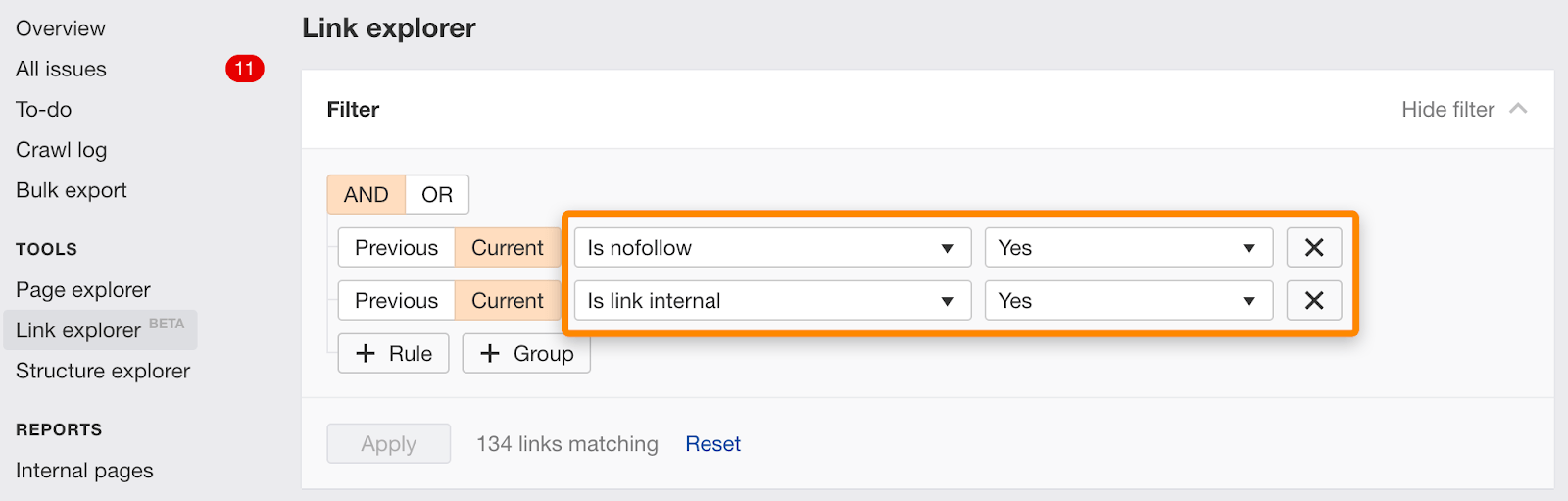
puteți găsi, de asemenea, link-uri individuale marcate nofollow folosind acest filtru în link Explorer.
Noindex și canonical la un alt URL
aceste semnale sunt contradictorii. Noindex spune să elimine pagina din index, iar canonical spune că o altă pagină este versiunea care ar trebui indexată. Acest lucru poate funcționa de fapt pentru consolidare, deoarece Google va alege de obicei să ignore noindex și, în schimb, să utilizeze canonicul ca semnal principal. Totuși, acesta nu este un comportament absolut. Există un algoritm implicat și există riscul ca eticheta noindex să fie semnalul numărat. Dacă acesta este cazul, atunci paginile nu se vor consolida corect.
rețineți că puteți găsi pagini noindexed cu canonice non-auto-referențiale folosind acest set de filtre în Exploratorul de pagini din Site Audit:
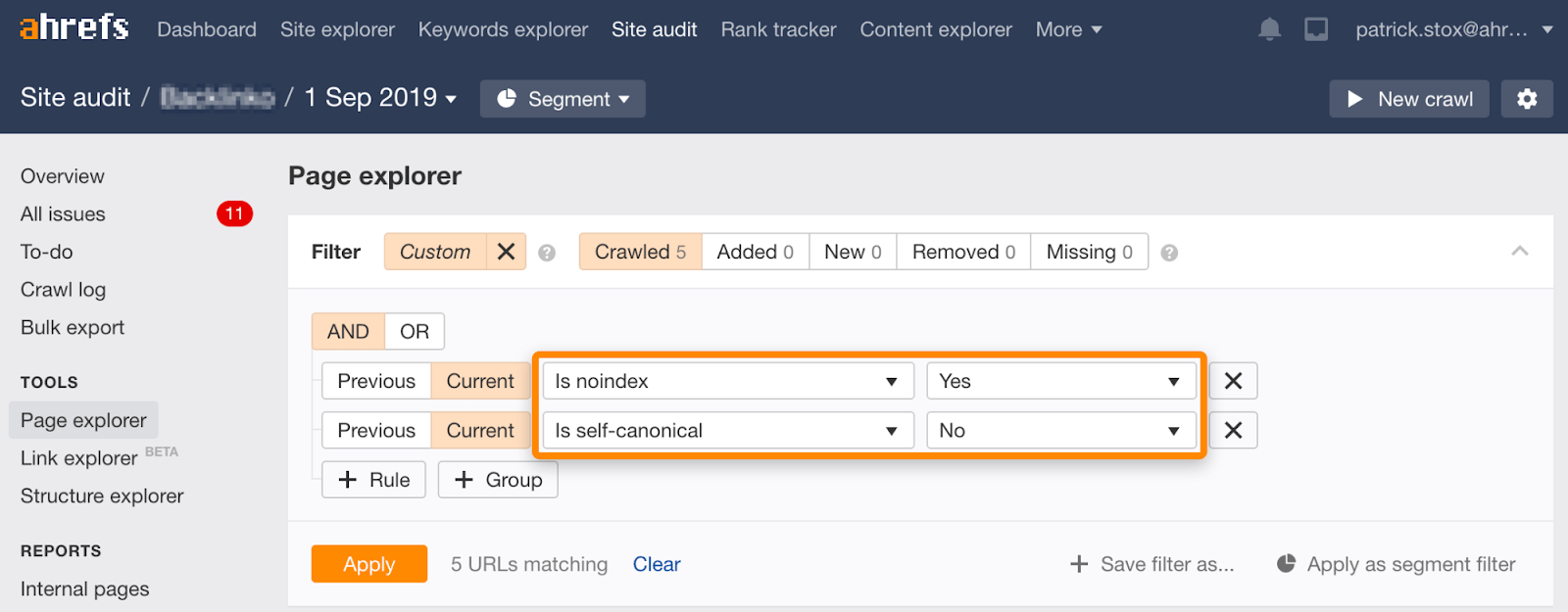
Noindex, așteptați ca Google să acceseze cu crawlere, apoi blocați accesarea cu crawlere
există câteva moduri în care acest lucru se întâmplă de obicei:
- indexate, oamenii adaugă noindex și deblochează astfel încât Google să poată accesa cu crawlere și să vadă noindex, apoi să blocheze din nou paginile.
- oamenii adaugă etichete noindex pentru paginile pe care doresc să le elimine și după ce Google a accesat cu crawlere și a procesat eticheta noindex, blochează accesarea cu crawlere a paginilor.
oricum, starea finală este blocată de crawling. Dacă vă amintiți, mai devreme, am vorbit despre modul în care accesarea cu crawlere nu este același lucru cu indexarea. Chiar dacă aceste pagini sunt blocate, ele pot ajunge în continuare în index.
dacă dețineți conținutul care este utilizat pe un alt site web, este posibil să puteți depune o reclamație pe baza Digital Millennium Copyright Act (DMCA). Puteți utiliza instrumentul Google de eliminare a drepturilor de autor pentru a face ceea ce se numește eliminare DMCA, care solicită eliminarea oricărui material protejat prin drepturi de autor.
ce se întâmplă dacă este conținut despre tine, dar nu pe un site pe care îl dețineți?
dacă vă aflați în UE, puteți elimina conținutul care conține informații despre dvs. datorită unei hotărâri judecătorești pentru dreptul de a fi uitat. Puteți solicita eliminarea informațiilor personale utilizând formularul de eliminare a confidențialității UE.
pentru a elimina imaginile de pe Google, cea mai ușoară cale este cu roboții.txt. În timp ce suportul neoficial pentru eliminarea paginilor a fost eliminat de la roboți.txt așa cum am menționat mai devreme, pur și simplu interzicerea accesării cu crawlere a imaginilor este modalitatea corectă de a elimina imaginile.
pentru o singură imagine:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
pentru toate imaginile:
User-agent: Googlebot-ImageDisallow: /
Gânduri finale
modul în care eliminați adresele URL este destul de situațional. Am vorbit despre mai multe opțiuni, dar dacă sunteți încă confuz, ceea ce este potrivit pentru dvs., consultați diagrama de la început.
De asemenea, puteți parcurge depanatorul legal furnizat de Google pentru eliminarea conținutului.
aveți întrebări? Anunță-mă pe Twitter.