structura ADN-ului oferă un mecanism pentru ereditate
genele poartă informații biologice care trebuie copiate cu precizie pentru transmiterea către următoarea generație de fiecare dată când o celulă se divide pentru a forma două celule fiice. Două întrebări biologice centrale apar din aceste cerințe: cum pot fi transportate informațiile pentru specificarea unui organism sub formă chimică și cum sunt copiate cu exactitate? Descoperirea structurii helixului dublu ADN a fost un punct de reper în biologia secolului al XX-lea, deoarece a sugerat imediat răspunsuri la ambele întrebări, rezolvând astfel la nivel molecular problema eredității. Vom discuta pe scurt răspunsurile la aceste întrebări în această secțiune și le vom examina mai detaliat în capitolele următoare.
ADN-ul codifică informații prin ordinea sau secvența nucleotidelor de-a lungul fiecărei catene. Fiecare bază-A, C, T sau G—poate fi considerată ca o literă dintr-un alfabet din patru litere care descrie mesaje biologice în structura chimică a ADN-ului. După cum am văzut în Capitolul 1, organismele diferă unele de altele, deoarece moleculele lor de ADN respective au secvențe nucleotidice diferite și, în consecință, poartă mesaje biologice diferite. Dar cum se folosește alfabetul nucleotidic pentru a face mesaje și ce precizează?
după cum s-a discutat mai sus, se știa cu mult înainte ca structura ADN-ului să fie determinată că genele conțin instrucțiunile pentru producerea proteinelor. Prin urmare, mesajele ADN trebuie să codifice cumva proteinele (figura 4-6). Această relație face imediat problema mai ușor de înțeles, din cauza caracterului chimic al proteinelor. După cum sa discutat în Capitolul 3, proprietățile unei proteine, care sunt responsabile pentru funcția sa biologică, sunt determinate de structura sa tridimensională, iar structura sa este determinată la rândul său de secvența liniară a aminoacizilor din care este compusă. Secvența liniară a nucleotidelor dintr-o genă trebuie, prin urmare, să precizeze cumva secvența liniară a aminoacizilor dintr-o proteină. Corespondența exactă dintre alfabetul nucleotidic de patru litere al ADN-ului și alfabetul aminoacid de douăzeci de Litere al proteinelor—codul genetic—nu este evidentă din structura ADN-ului și a durat peste un deceniu după descoperirea helixului dublu înainte de a fi elaborat. În Capitolul 6 descriem acest cod în detaliu în cursul elaborării procesului, cunoscut sub numele de Expresie genică, prin care o celulă traduce secvența nucleotidică a unei gene în secvența de aminoacizi a unei proteine.

figura 4-6
relația dintre informațiile genetice transportate în ADN și proteine.
setul complet de informații din ADN-ul unui organism se numește genomul său și poartă informațiile pentru toate proteinele pe care organismul le va sintetiza vreodată. (Termenul genom este, de asemenea, utilizat pentru a descrie ADN-ul care poartă aceste informații.) Cantitatea de informații conținute în genomi este uimitoare: de exemplu, o celulă umană tipică conține 2 metri de ADN. Scrisă în alfabetul nucleotidic din patru litere, secvența nucleotidică a unei gene umane foarte mici ocupă un sfert de pagină de text (figura 4-7), în timp ce secvența completă de nucleotide din genomul uman ar umple mai mult de o mie de cărți de dimensiunea acesteia. În plus față de alte informații critice, acesta poartă instrucțiunile pentru aproximativ 30.000 de proteine distincte.

figura 4-7
secvența nucleotidică a genei umane-globină. Această genă poartă informația pentru secvența de aminoacizi a unuia dintre cele două tipuri de subunități ale moleculei de hemoglobină, care transportă oxigen în sânge. O genă diferită, globina-globină (mai mult…)
la fiecare diviziune celulară, celula trebuie să-și copieze genomul pentru a-l transmite ambelor celule fiice. Descoperirea structurii ADN-ului a dezvăluit, de asemenea, principiul care face posibilă această copiere: deoarece fiecare catenă de ADN conține o secvență de nucleotide care este exact complementară secvenței nucleotidice a catenei sale partenere, fiecare catenă poate acționa ca un șablon sau mucegai pentru sinteza unei noi catene complementare. Cu alte cuvinte, dacă desemnăm cele două catene ADN ca S și S’, Catena S poate servi ca șablon pentru realizarea unei noi catene S’, în timp ce Catena S’ poate servi ca șablon pentru realizarea unei noi catene s (figura 4-8). Astfel, informațiile genetice din ADN pot fi copiate cu exactitate prin procesul frumos simplu în care firul S se separă de firul S’ și fiecare fir separat servește apoi ca șablon pentru producerea unui nou fir partener complementar care este identic cu fostul său partener.
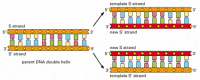
figura 4-8
ADN-ul ca șablon pentru propria duplicare. Deoarece nucleotida a se împerechează cu succes numai cu T și G Cu C, fiecare catenă de ADN poate specifica secvența nucleotidelor în catena sa complementară. În acest fel, ADN-ul dublu-elicoidal poate fi copiat cu precizie. (mai mult…)
capacitatea fiecărei catene a unei molecule de ADN de a acționa ca un șablon pentru producerea unei catene complementare permite unei celule să copieze sau să reproducă genele sale înainte de a le transmite descendenților săi. În capitolul următor vom descrie mașinăria elegantă pe care celula o folosește pentru a îndeplini această sarcină enormă.