- Eh? Czym są grupowanie SET, CUBE i ROLLUP w SQL?
- Po co mi ROLLUP lub CUBE?
- to są standardowe SQL czy tylko Microsoft?
- Czy mogę wykluczyć jedną lub więcej kolumn z ROLLUP?
- co to są zestawy grupujące? Powinienem o nich wiedzieć?
- dlaczego mielibyśmy chcieć łączyć kolumny w dowolnej agregacji?
- czy jest coś więcej do grupowania zestawów niż sposób robienia kostek „à la carte”?
- dlaczego podano funkcje Grouping () i Grouping_ID ()?
- Eh? Czym są grupowanie SET, CUBE i ROLLUP w SQL?
- dlaczego ROLLUP lub CUBE byłyby dla mnie przydatne?
- to są standardowe SQL czy tylko Microsoft?
- Czy mogę wykluczyć jedną lub więcej kolumn z ROLLUP?
- Co to są zestawy grupujące? Powinienem o nich wiedzieć?
- dlaczego mielibyśmy chcieć łączyć kolumny w dowolnej agregacji?
- czy istnieje coś więcej do grupowania zestawów niż sposób robienia kostek „à la carte”?
- dlaczego dostarczane są funkcje Grouping() i Grouping_ID ()?
Eh? Czym są grupowanie SET, CUBE i ROLLUP w SQL?
CUBE, ROLLUP i GROUPING SET są opcjonalnymi operatorami klauzuli GROUP BY instrukcji SELECT do wykonywania raportów z dużą ilością informacji. Pozwalają one wykonać kilka operacji grupowych w jednej instrukcji, potencjalnie oszczędzając dużo czasu i wysiłku obliczeniowego. Mogą dostarczyć wszystkie informacje potrzebne do raportowania, w tym sumy, zapewniając dobrą wydajność w dużych tabelach i pomagając optymalizatorowi zapytań opracować dobry plan wykonania.
dodatkowe wiersze „super-agregacji” dostarczają wartości podsumowania, dzięki czemu możesz mieć kilka „agregacji”, takich jak SUM() lub MAX() w jednym wyniku. Wartości Null w tych wierszach w wyniku mają oznaczać „wszystkie”, a nie „nieznane”. Pozwala uzyskać wszystkie potrzebne agregacje w jednym przejściu przez stół. Ze względu na obecność dodatkowych wierszy w wynikach, dodatkowe funkcje GROUPING() I GROUPING_ID() są dostarczane do wskazania tych dodatkowych wierszy „super-agregacji” i które kolumny są agregowane.
To ma duży sens, jeśli masz aplikację, która musi uruchomić kilka raportów bez dodatkowych obliczeń lub bez powrotu do bazy danych: masz wszystko, czego potrzebujesz w jednym wyniku.
weź ten standardowy przykład ROLLUPA (używam tutaj AdventureWorks 2012)..
|
1
2
3
4
5
6
|
WYBIERZ t. JAK region, t.name JAK teren, kwota (suma) JAK przychody,
część datę (rrrr, data zamówienia) JAKO część datę (mm, data zamówienia) JAK
OD sprzedaży.SalesOrderHeader s
wewnętrzny dołączyć do sprzedaży.Terytorium handlowe T NA s. TerritoryID = T. TerritoryID
Grupuj według T., T.nazwa, datepart(yyyy, OrderDate), datepart(mm, OrderDate)
z ROLLUPEM
|
a także proste Grupowanie według zbiorczych wierszy, z sumą należną za każdy miesiąc, które można uzyskać za pomocą prostego grupowania, otrzymasz również subtotal lub super-zagregowane wiersze, a także wielki wiersz całkowity. (tutaj jest początek wyniku)
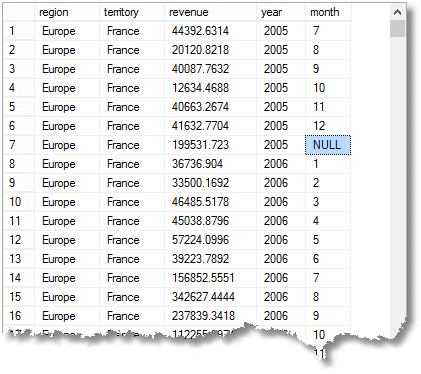
że NULL mam highlit oznacza, że wiersz jest zbiorem dla 'wszystkich’ miesięcy 2005 we Francji (część regionu Europa)
jak również to wszystko, dostajesz całkowitą należność za każdy rok, dla każdego terytorium i grupy terytorialnej, jak również pełną należność. (od końca)
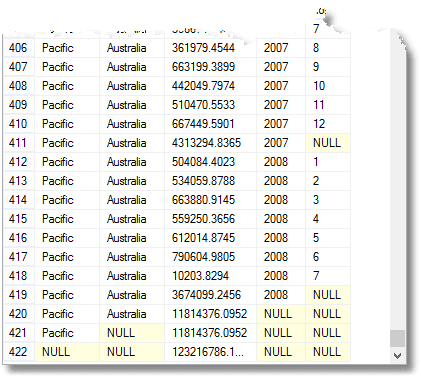
te nulle oznaczają 'wszystkie’, pamiętaj. Ostatni rząd jest sumą całkowitą, a powyżej jest sumą dla regionu Pacyfiku. Powyżej jest wkład Australii w region Pacyfiku. Czwarty rząd od dołu to wkład Australii z 2008 roku. Liczba grup, która jest zwracana jest o jedno więcej niż liczba wyrażeń na liście elementów złożonych dostarczanych grupie przez polecenie.
aby uzyskać ten sam efekt bez użycia pakietu zbiorczego aktualizacji, musisz zrobić coś takiego (danych adventureworks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
z myGrouping (region, territory, totalDue, , )
AS (Wybierz t., t.name, sum (TotalDue) jako przychód,
datepart(yyyy, OrderDate) jako , datepart(mm, OrderDate) jako
ze sprzedaży.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GROUP BY t.name, t., datepart(yyyy, OrderDate), datepart(mm, OrderDate))
SELECT Region, territory, totalDue, ,
FROM myGrouping
UNION ALL
SELECT Region, territory, sum(totalDue), , NULL
FROM MYGROUP GROUP BY Region, territory,
UNION ALL
select region, Territory, Sum(totaldue), null, null
from mygrouping group by region, Territory
UNION ALL
select region, null, Sum(totaldue), null, null
from mygroup group by region
Union all
SELECT NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
'GROUPBY ROLLUP (t.,t.nazwa,datepart(YYYY,OrderDate), datepart(mm, OrderDate))’
|
Ta nowa składnia pozwala na dodatkową funkcjonalność. Pamiętaj również, że kolejność kolumn wpływa na grupy wyjściowe ROLLUP i może wpływać na liczbę wierszy w zestawie wynikowym.
sześcian robi to samo ogólne, ale zamiast dostarczać hierarchię sumów w uporządkowanych rzędach super-agregacji, dostarcza wszystkie permutacje „super-agregacji” („symetryczne wiersze super-agregacji”), tak zwane wiersze tabulacji krzyżowej. Jeśli chcesz wiedzieć, które terytorium wydało najwięcej zamówień w marcu, lub które terytorium wykonało najmniej dobrze w 2006 roku, potrzebujesz sześcianu. Podajesz wszystkie możliwe podsumowania w wyniku.
grupowanie zestaw pozwala dostroić wynik, aby dostarczyć bardziej wyspecjalizowanych informacji poza kostką. Może dostarczyć informacji podsumowujących na temat kombinacji wymiarów. Możesz uzyskać dokładnie taki sam wynik jak w naszym przykładzie ROLLUP, używając grupowania zestawów, ale z dużo większą ilością pisania.
|
1
2
3
4
5
6
7
8
9
10
|
WYBIERZ t. JAK region, t.name JAK teren, kwota (suma) JAK przychody,
część datę (rrrr, data zamówienia) JAKO część datę (mm, data zamówienia) JAK
OD sprzedaży.SalesOrderHeader s
wewnętrzny dołączyć do sprzedaży.Terytorium handlowe T NA s. TerritoryID = T.TerritoryID
grupowanie zestawów (
(T., T.name, datepart (yyyy, OrderDate), datepart (mm, OrderDate)),
(T., T.name, datepart (yyyy, OrderDate)),
(T., T.name),
(T.),
())
|
To jest tylko po to, aby pokazać, jak się odnoszą. W rzeczywistości, można uciec się do grupowania zestawów, aby uzyskać wyniki, które są niemożliwe z ROLLUP lub CUBE.
prawie wszystkie te podsumowania można uzyskać za pomocą just GROUP BY, ale tylko poprzez wielokrotne grupowanie wyniku grupy BY lub poprzez wykonanie więcej niż jednego przejścia przez dane.
gdy używasz zestawów CUBE, ROLLUP lub grupowania, nie możesz używać słowa kluczowego DISTINCT w wyrażeniach agregowanych, takich jak AVG (DISTINCT column_name), COUNT (DISTINCT column_name) i SUM (DISTINCT column_name)
dlaczego ROLLUP lub CUBE byłyby dla mnie przydatne?
ROLLUP i CUBE miały swój rozkwit przed SSAS. Były one przydatne do zapewnienia tego samego rodzaju urządzeń oferowanych przez cube w OLAP. Nadal jednak ma swoje zastosowania. W AdventureWorks jest to przesada, ale jeśli obsługujesz duże ilości danych, musisz przekazać swoje dane tylko raz i zrobić jak najwięcej na danych, które zostały zagregowane. Zdarzenia, które miały miejsce w przeszłości, nie mogą być zmienione, dlatego rzadko jest konieczne przechowywanie danych historycznych w aktywnym systemie OLTP. Zamiast tego wystarczy zachować zagregowane dane na poziomie szczegółowości („szczegółowości”) wymaganym dla wszystkich przewidywalnych raportów.
wyobraź sobie, że jesteś odpowiedzialny za raportowanie na przełączniku telefonicznym, który ma dwa miliony połączeń dziennie. Jeśli zachowasz wszystkie te połączenia na serwerze OLTP, wkrótce znajdziesz SQL Server pracujący nad raportami użycia. Musisz zachować oryginalne informacje o połączeniu przez ustawowy okres czasu, ale ustalasz z firmy, że są co najwyżej zainteresowani liczbą połączeń w ciągu minuty. Następnie zmniejszono zapotrzebowanie na pamięć masową na serwerze OLTP do 1.4% tego, co to było, a rekordy połączeń można zarchiwizować na innym serwerze SQL w celu uzyskania zapytań ad-hoc i wyciągów klientów. To może być warte oszczędzania. Klauzule CUBE i ROLLUP pozwalają nawet przechowywać sumy wierszy, sumy kolumn i wielkie sumy bez konieczności skanowania tabeli lub grupowego indeksu tabeli podsumowującej.
dopóki zmiany nie zostaną wprowadzone retrospektywnie do tych danych, a wszystkie okresy są kompletne, nigdy nie musisz powtarzać ani zmieniać agregacji na podstawie przeszłych okresów, chociaż wielkie sumy będą musiały być nadpisane!.
udawajmy, ale korzystajmy z AdventureWorks2012, abyś mógł grać razem.
najpierw utworzymy tabelę przestawną gram.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
JEŚLI ISTNIEJE (WYBIERZ * Z bazy DANYCH tempdb.sys.tabele o nazwie ’ # AggregationTable%’)
upuść tabelę #aggregationTable –Usuń tymczasową tabelę,jeśli istnieje
idź
wybierz
identity(INT,1, 1) AS, — więc możemy mieć unikalną kolumnę
t. jako region, t.name as territory, sum (TotalDue) AS revenue,
datepart (yyyy, OrderDate) AS, datepart (mm, OrderDate) AS,
grupowanie(t.name) AS isNameGroup, — does this relating to ALL territories
grouping(t.) AS isgroup, — czy odnosi się to do wszystkich kontynentów
grupowanie(datepart(yyyy, OrderDate)) AS isyeargroup,–czy odnosi się to do wszystkich lat
grupowanie(datepart(mm, OrderDate)) AS isMonthGroup,–czy odnosi się to do wszystkich miesięcy
Grupowanie_id (t.name, t.,
datepart (yyyy, OrderDate), datepart(mm, OrderDate)) AS isGroupingRow
–czy jest to dodatkowy wiersz bez danych zawierający zagregowane dane
do #AggregationTable
ze sprzedaży.SalesOrderHeader s
INNER JOIN Sales.Salestritory T ON s. TerritoryID = T.TerritoryID
GROUP BY t.name, t., datepart(yyyy, OrderDate), datepart(mm, OrderDate)
z ROLLUPEM
|
zauważ, że dodajemy dodatkowe kolumny 'bit’, które mówią nam, które wiersze zawierają wiersze podsumowania. Jeśli błędnie dodasz je do dalszych agregacji, otrzymasz poważnie zawyżone wyniki. Nie możesz użyć Grouping() lub Grouping_ID na zapisanym wyniku, oczywiście, więc powinieneś podać coś zamiast niego.
Teraz możemy bardzo szybko stworzyć tabelę przestawną
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
– teraz możemy utworzyć prostą tabelę przestawną z wierszami i
– podsumowanie kolumn
WYBIERZ terytorium,
sum(przypadek, gdy 2005 to przychód ELSE 0 koniec) AS,
sum(przypadek, gdy 2006 to przychód ELSE 0 koniec) AS,
sum(przypadek, gdy 2007 to przychód ELSE 0 koniec) AS,
sum(przypadek, gdy 2008 to przychód ELSE 0 koniec) AS,
sum(przychód) AS
z #AggregationTable
where ISGROUPINGROW =0
Grupuj według terytorium
Unia wszystkie
wybierz 'total’, sum(przypadek, gdy 2005 to przychód else 0 koniec) as,
Sum(przypadek, gdy 2006 to przychód else 0 koniec) as,
Sum(przypadek, gdy 2007 to przychód else 0 koniec) as,
Sum (przypadek, gdy 2007 to przychód else 0 koniec) as ,
sum(przypadek, gdy 2008 to przychód ELSE 0 END) AS,
sum(przychód) AS
z #AggregationTable
gdzie isYearGroup =0 i isMonthGroup=1
|
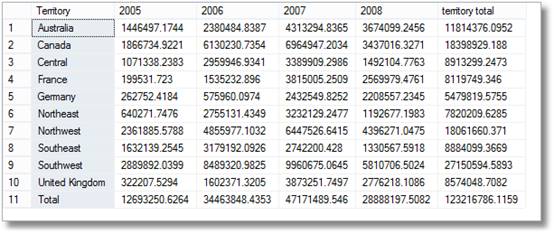
więc są krótkie uśmiechy od menedżerów, którzy to widzą, ale potem jasno mówią ” jestem pewien, że prosiłem również o podział według terytorium na miesiąc
z krótkim chichotem, zrób to.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
wybierz
datename(MONTH,dateadd(MONTH, ,’01 dec 2000′)) AS ,
sum(Case territory WHEN 'Australia’ then revenue ELSE 0 END) AS ,
sum(Case territory WHEN 'Canada’ THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN 'Central’ następnie revenue else 0 end) as ,
Sum(terytorium przypadku, gdy „Francja”, a przychód else 0 end) as,
Sum(terytorium przypadku, gdy „Niemcy”, a przychód else 0 end) as,
Sum(terytorium przypadku, gdy „północny wschód”, a przychód else 0 end) as,
Sum(terytorium przypadku Gdy 'Northwest’ to przychód ELSE 0 koniec) AS ,
sum(terytorium przypadku, gdy 'Southwest’ to przychód else 0 koniec) AS,
sum(terytorium przypadku, gdy 'Southwest’ to przychód ELSE 0 koniec) as,
sum(przychód) AS
z #AggregationTable
gdzie ISGROUPINGROW =0
Grupuj według miesiąca
UNION ALL
Select
'Total’,
Sum(terytorium przypadku, gdy 'Australia’, wtedy przychód else 0 end) as,
Sum(terytorium przypadku, gdy „Kanada” wtedy przychód ELSE 0 koniec) AS ,
sum(terytorium przypadku, gdy „centralny” wtedy przychód else 0 koniec) AS,
sum(terytorium przypadku, gdy „Francja” wtedy przychód ELSE 0 koniec) AS,
sum(terytorium przypadku, gdy „Niemcy” wtedy przychód ELSE 0 koniec) AS,
sum(terytorium przypadku, gdy „północny wschód” wtedy przychód ELSE 0 koniec) AS,
sum(terytorium przypadku, gdy „północny wschód” wtedy przychód ELSE 0 koniec) AS,
sum(terytorium przypadku, gdy ” Northwest 'wtedy revenue else 0 end) as,
Sum(terytorium przypadku, gdy’ Southwest 'wtedy revenue else 0 end) as,
Sum (terytorium przypadku, gdy’ Southwest 'wtedy revenue else 0 end) as,
sum(terytorium przypadku, gdy 'Wielka Brytania’ to przychód na koniec 0) AS,
sum(przychód) AS
FROM #AggregationTable
WHERE isGroupingrow =0
|

ale jeśli użyłbyś CUBE zamiast Rollup, ten ostatni’ total ’ wiersz byłby już obliczony. W prawdziwym przykładzie, który kosztowałby czas na sporządzenie raportu. Możesz zrobić sześcian na maksymalnie dziesięciu wymiarach; chociaż mają tendencję do zwiększania agregacji, nie są zbyt kosztowne.
to są standardowe SQL czy tylko Microsoft?
są to obecnie standardowe ANSI SQL z 1999 roku, choć z CUBE i z ROLLUP zostały po raz pierwszy wprowadzone przez Microsoft. Włączenie to jest nieco zaskakujące, ponieważ wprowadzają one drugie znaczenie, „wszystko”, dla wartości zerowej oprócz „nieznany”. Kiedy Microsoft po raz pierwszy wprowadził CUBE i ROLLUP, składnia była nieco inna, ale obie formy są dozwolone w SQL Server. Tylko jeden styl składni może być użyty w pojedynczej instrukcji SELECT i powinieneś używać składni zgodnej z ISO dla wszystkich nowych prac.
Czy mogę wykluczyć jedną lub więcej kolumn z ROLLUP?
Jeśli chcesz! Wyobraź sobie, że nie chciałem сверхагрегатную sumę dla wszystkich regionów (t)
|
1
2
3
4
5
6
|
WYBIERZ tak JAK region, t.name JAK teren, kwota (suma) JAK przychody,
część datę (rrrr, data zamówienia) JAKO część datę (mm, data zamówienia) JAK
OD sprzedaży.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GROUP BY T., ROLLUP (t.name, datepart(yyyy, OrderDate), datepart (mm, OrderDate))
|
tutaj używamy składni zgodnej z ANSI SQL 2006. Możesz zrobić to samo z sześcianem. Nigdy nie znalazłem praktycznego zastosowania do tego, ale możesz się natknąć
Co to są zestawy grupujące? Powinienem o nich wiedzieć?
GROUPING SET oznacza, że prosisz SQL o grupowanie wyniku kilka razy. Możesz użyć składni zestawów grup, aby precyzyjnie określić, które agregacje należy obliczyć. Oto przykład.
|
1
2
3
4
5
6
|
wybierz T. jako region, t.name jako terytorium, sum (TotalDue) jako przychód,
datepart(yyyy, OrderDate) jako , datepart(mm, OrderDate) jako
ze sprzedaży.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON s.TerritoryID = T. TerritoryID
Grupuj według t., Grupuj zestawy(ROLLUP(t.name),
ROLLUP(datepart(yyyy, OrderDate), datepart(mm, OrderDate)))
|
tutaj prosisz o podział na grupy terytorialne dla każdego miesiąca każdego roku z sumami miesięcy i lat, a następnie sumą całkowitą według nazwy terytorium, ale bez Wielkiej sumy. W przeciwieństwie do ROLLUP, otrzymujesz ten sam wynik niezależnie od kolejności kolumn w każdym zestawie grupowania i kolejności zestawów grupowania.
zestawy grupujące mogą dać ci dokładnie to, co daje CUBE i ROLLUP i wiele więcej poza tym. Jak widać w tym ostatnim przykładzie, można użyć standardowego sześcianu „table d’ hôte „i ROLLUPU zmieszanego z bezpośrednio wyrażonymi zestawami grup „à la carte”.
dlaczego mielibyśmy chcieć łączyć kolumny w dowolnej agregacji?
W przypadku gdy w niektórych raportach należy połączyć dwie kolumny, przydatne jest zadeklarowanie agregacji, która łączy dwie kolumny. W pierwszym przykładzie łączymy rok i miesiąc dla rollupu, co skutkuje ograniczeniem sumy do każdego terytorium,
|
1
2
3
4
5
6
7
|
–pobieraj sumy tylko dla każdego terytorium – brak sumów dla Każdy region lub rok
wybierz T. jako region, t.nazwa jako terytorium, suma (TotalDue) jako przychód,
datepart(yyyy, OrderDate) jako , datepart(mm, OrderDate) jako
ze sprzedaży.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON s. TerritoryID = T. TerritoryID
GROUP BY T., t.name, ROLLUP
((datepart(yyyy, OrderDate), datepart(mm, OrderDate)))
|
ten dodatkowy nawias w klauzuli ROLLUP spowodował ograniczenie agregacji tylko do terytorium i miesiąca/roku. Zostaw je, a dostaniesz sumy za każdy rok.
|
1
2
3
4
5
6
7
8
9
10
|
może to być bardzo przydatne dla niektórych danych. Uniknęliśmy konieczności łączenia kolumn. Jeśli mielibyśmy zrobić sześcian, a w terminach terytorialnych użyto słów „północny” lub „Południowy” do opisania terytorium w więcej niż jednym regionie, mielibyśmy dziwne agregacje, które odnoszą się do terytoriów „północnych”, które nie są ze sobą powiązane. Łącząc kolumny, unikniesz tego.
czy istnieje coś więcej do grupowania zestawów niż sposób robienia kostek „à la carte”?
nie jestem pewien, czy wstydziłbym się zadać to pytanie. SQL:1999 ’ S GROUPING SETS provide a rich recursive syntax that allows you to agregate combinations of columns and define all sorts of ezoteric reports providing up to ten dimensions. Agregacje można zagnieżdżać i można zagnieżdżać kostki w Rollupach i zagnieżdżać rollupy w kostkach. Będziesz musiał przeczytać specjalistyczną publikację, aby dowiedzieć się więcej na ten temat.
dlaczego dostarczane są funkcje Grouping() i Grouping_ID ()?
używanie NULL do oznaczania, że kolumna jest agregacją nie jest dobrym pomysłem. Problem polega na tym, że jeśli kolumna grupująca zawiera wartości null, wszystkie wartości null są uważane za równe i umieszczane w jednej grupie NULL, która maskuje się jako podsumowanie. Aby ominąć oczywistą trudność wartości NULL w oryginalnych danych, dostępne są dwie funkcje: Grouping() i Grouping_ID().
funkcja Grouping() przekazuje nazwę kolumny, która uczestniczyła w zestawie ROLLUP, CUBE lub grupowania. Zwraca zero, jeśli ten wiersz jest podsumowaniem dla tej kolumny z wartością NULL oznaczającą 'wszystkie’ lub jeśli zawiera wartość.
funkcja GROUPING_ID jest przekazywana do listy, która musi dokładnie pasować do wyrażenia z listy GROUP BY. GROUPING_ID jest tworzony jako bitmapa odpowiednich kolumn podsumowania. Jeśli, na przykład, kolumna territory ma wartość NULL oznaczającą 'wszystkie’ terytoria, a nie nazwę terytorium i jest wymieniona jako druga kolumna, to ustawiany jest drugi bit od lewej. Następnie zwracana jest ta liczba całkowita.
Grouping_ID() jest zwykle używany do wskazania, czy wiersz jest agregacją pierwotną, czy wtórną (0 lub>0), a jeśli jest wtórny, to wyłączony z jakiejkolwiek dalszej grupy przez manipulację.
zwykle za dobrą praktykę uważa się dołączanie kolumny bitowej dla każdego wymiaru (np.”terytorium”lub” Region „w naszym przykładzie), która jest ustawiana, jeśli wiersz jest podsumowaniem dla tego wymiaru, wraz z wartościąGrouping_ID(), aby pomóc w dalszym grupowaniu wyniku.
aby zilustrować sposób, w jaki Grouping_ID faktycznie działa, tutaj przyjrzymy się sposobowi, w jaki bity w Grouping_ID są ustawiane zgodnie z typem podsumowania. Użyjemy funkcji Phila Factor ’ a ToBinaryString do pokazania bitów.
|
1
2
3 celu uzyskania bardziej szczegółowych informacji, prosimy o kontakt z działem obsługi klienta pod numerem telefonu: + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00, + 48 22 232 50 00nazwa jako terytorium, suma (TotalDue) jako przychód,
datepart(yyyy, OrderDate) jako , datepart(mm, OrderDate) jako ,
prawo (
dbo.ToBinaryString (–lista wszystkich pozycji grupy wg
Grouping_ID (t., t.name, datepart(yyyy, OrderDate),datepart (mm, OrderDate))
),4) As –po prostu użyj ostatnich czterech znaków, ponieważ mamy cztery kolumny na naszej liście.
ze sprzedaży.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T NA s. TerritoryID = T. TerritoryID
Grupuj według sześcianu (t., t.nazwa, datepart(yyyy, OrderDate),datepart(mm, OrderDate))
|
to daje (oczywiście tylko próbkę)…
