w mitologii greckiej Tytan Prometeusz był przykuty do skały. Każdego dnia Orzeł przyleciał i zjadł część jego wątroby. Narząd regeneruje się w nocy, uzupełniając źródło pożywienia. Wątroba jest jednym z niewielu narządów w ludzkim ciele, które mogą spontanicznie się regenerować. Jeszcze bardziej imponujący jest fakt, że podczas gdy wątroba się regeneruje i naprawia, nadal jest funkcjonalna. Starożytni Grecy wiedzieli o tej zdolności i włączyli ją do swojej mitologii prawie 3000 lat temu.
ciągła funkcjonalność
Kiedy projektujemy sieci, chcemy, aby były funkcjonalne, nawet gdy występuje zakłócenie w systemie. Zdarzają się awarie sprzętu, przecięcia włókien, usterki oprogramowania, a nawet wiewiórki przeżuwające Kable. Jesteśmy zaniepokojeni tym, w jaki sposób dostawa aplikacji i infrastruktura sieciowa reagują na te problemy. Projektujemy technologie w naszej infrastrukturze IT, aby zminimalizować skutki szkód.

podobnie jak nasze wątroby, sieć musi działać nawet wtedy, gdy leczy wyrządzone jej szkody. Aplikacje muszą zostać dostarczone, a firmy nadal mają pracę do wykonania. Na początku opracowaliśmy dynamiczne protokoły sieciowe, takie jak spanning tree protocol (STP) dla topologii warstwy 2 i routing information protocol (RIP) dla topologii warstwy 3. Z biegiem czasu rozszerzyliśmy te protokoły o protokół rapid spanning tree protocol (RSTP) oparty na warstwie 2 i protokoły routingu warstwy 3, w tym OSPF, ISIS i BGP.
idąc w górę stosu OSI
nadal musimy zapewnić mechanizmy dostępności aplikacji i dostarczania aplikacji w całej infrastrukturze sieciowej. W tym miejscu wprowadziliśmy równoważenie obciążenia serwera (SLB) i dynamiczną manipulację DNS poprzez globalne równoważenie obciążenia serwera (gslb). Zapewniają mechanizmy wykrywania awarii serwera aplikacji i kompletnych awarii centrów danych.
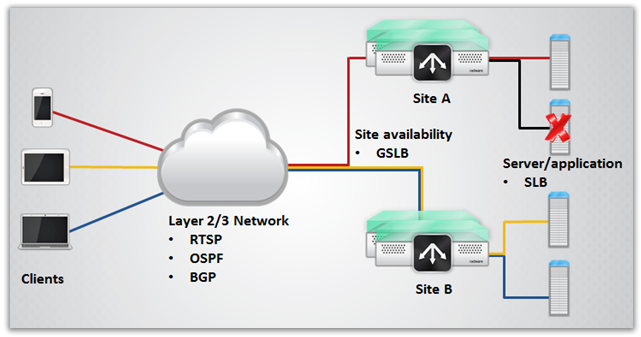
Moja idealna sieć (swego rodzaju)
gdybym miał zaprojektować sieć dzisiaj, na wysokim poziomie, wyglądałaby bardzo podobnie do powyższego diagramu. Redundancja jest wbudowana w każdy aspekt architektury. Istnieje wiele serwerów, zróżnicowanych geograficznie witryn i wiele ścieżek sieciowych do różnych komponentów. Nie ma jednego punktu niepowodzenia. Jeśli jeden z aspektów nie powiedzie się, technologie dynamiczne automatycznie przekażą się, aby określić nową najlepszą ścieżkę między Klientem a serwerem aplikacji.
jest wiele drobnych szczegółów, których nie omawiam w tym artykule. Rzeczywisty projekt sieci warstwy 2/3 i łączności urządzenia zależy od zapewnienia spełnienia różnych wymagań dostarczania aplikacji w celu zapewnienia zapewnienia poziomu usług aplikacji (SLA) dla wszystkich aplikacji. Ponieważ nie wiemy, jakie są zastosowania, nie możemy tego ustalić. Innym powodem jest to, że musiałbym napisać książkę, aby omówić wszystkie aspekty niezbędne do budowy tej sieci.
kluczowe punkty, o których należy pamiętać projektując własną samouzdrawiającą się, regenerującą infrastrukturę IT, to:
- budowanie redundancji w architekturze
- wykorzystanie dynamicznych technologii, które automatycznie dostosowują się do zmieniających się warunków
- pamiętaj, że krytycznym celem końcowym jest zapewnienie SLA aplikacji
następnie weźmiemy tę sieć i złamiemy różne komponenty, aby zobaczyć, jak wpływają one na dostarczanie aplikacji i co postrzega użytkownik końcowy.

Czytaj ” zachowaj prostotę; spraw, aby była skalowalna: 6 charakterystyka balansera obciążenia Futureproof”, aby dowiedzieć się więcej.
Pobierz teraz