- co to jest Przechowywanie w chmurze?
- rodzaje pamięci masowej w chmurze
- Jak działa Przechowywanie w chmurze?
- zalety i wady pamięci masowej w chmurze
- zalety
- bezpieczeństwo. Bezpieczeństwo danych jest najczęściej wymienianym czynnikiem, który może sprawić, że firmy będą ostrożne w korzystaniu z publicznej pamięci masowej w chmurze. Obawa polega na tym, że po opuszczeniu siedziby firmy dane nie mają już kontroli nad tym, w jaki sposób są przetwarzane i przechowywane. Problemem jest również przechowywanie regulowanych danych. Dostawcy usług starali się rozwiać te obawy, zwiększając swoje możliwości bezpieczeństwa za pomocą szyfrowania danych, uwierzytelniania wieloczynnikowego (MFA), przechowywania danych w wielu lokalizacjach i poprawy bezpieczeństwa fizycznego. dostęp do danych. Utrzymanie dostępu do danych przechowywanych w chmurze może również stanowić problem i może znacznie zwiększyć koszty korzystania z magazynu w chmurze. Firma może wymagać uaktualnienia połączenia z usługą przechowywania danych w chmurze, aby obsłużyć ilość danych, które zamierza przesłać. Na przykład miesięczny koszt łącza optycznego może sięgać tysięcy dolarów. degradacja wydajności. Firma może napotkać problemy z wydajnością, jeśli jej wewnętrzne aplikacje muszą uzyskać dostęp do danych przechowywanych w chmurze. W takich przypadkach prawdopodobnie będzie to wymagało przeniesienia serwerów i aplikacji do tej samej chmury lub przywrócenia niezbędnych danych do domu. koszt. Jeśli firma wymaga dużej pojemności pamięci masowej w chmurze i często przenosi swoje dane między systemami lokalnymi a chmurą, miesięczne koszty mogą być wysokie. W porównaniu z wdrożeniem pamięci masowej we własnym zakresie koszty bieżące mogą ostatecznie przewyższyć koszty wdrożenia i utrzymania systemu lokalnego. kwestie związane z pamięcią masową w chmurze
- przykłady pamięci masowej w chmurze
co to jest Przechowywanie w chmurze?
cloud storage to model usług, w którym dane są przesyłane i przechowywane w zdalnych systemach pamięci masowej, gdzie są utrzymywane, zarządzane, tworzone kopie zapasowe i udostępniane użytkownikom przez sieć-zazwyczaj internet. Użytkownicy zazwyczaj płacą za przechowywanie danych w chmurze według miesięcznej stawki za zużycie.
pamięć masowa w chmurze jest oparta na zwirtualizowanej infrastrukturze pamięci masowej z dostępnymi interfejsami, niemal natychmiastową elastycznością i skalowalnością, wieloma dzierżawami i liczonymi zasobami. Dane oparte na chmurze są przechowywane w pulach logicznych na różnych serwerach magazynowania towarów zlokalizowanych lokalnie lub w centrum danych zarządzanym przez zewnętrznego dostawcę chmury.
dostawcy usług w chmurze zarządzają i utrzymują dane przesyłane do chmury. Usługi pamięci masowej są świadczone na żądanie w chmurze, a pojemność rośnie i zmniejsza się w razie potrzeby. Organizacje decydujące się na przechowywanie w chmurze eliminują potrzebę kupowania wewnętrznej infrastruktury pamięci masowej, zarządzania nią i jej utrzymywania. Pamięć masowa w chmurze radykalnie obniżyła koszt pamięci masowej w przeliczeniu na gigabajt, ale dostawcy pamięci masowej w chmurze dodali koszty operacyjne, które mogą znacznie zwiększyć koszty tej technologii w zależności od sposobu jej wykorzystania.
rodzaje pamięci masowej w chmurze
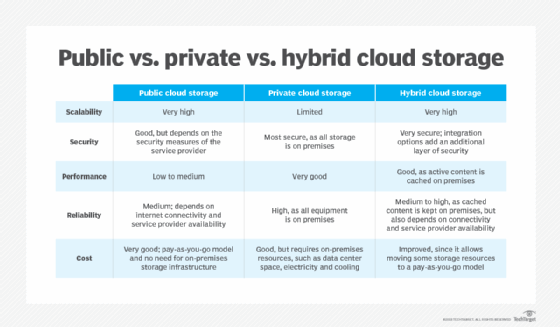
istnieją trzy główne opcje pamięci masowej w chmurze, oparte na różnych modelach dostępu: publicznym, prywatnym i hybrydowym.
Chmura publiczna. Te usługi pamięci masowej zapewniają wielodostępne środowisko pamięci masowej, które najlepiej nadaje się do przechowywania nieustrukturyzowanych danych na zasadzie subskrypcji. Dane są przechowywane w centrach danych usługodawcy, a dane są przechowywane w wielu regionach lub kontynentach. Klienci zazwyczaj płacą za wykorzystanie, podobnie jak model płatności za media. W wielu przypadkach istnieją również opłaty transakcyjne oparte na częstotliwości i ilości dostępnych danych. Ten sektor rynku jest zdominowany przez następujące usługi:
- Amazon Simple Storage Service (S3);
- Amazon Glacier do głębokiej archiwizacji lub przechowywania w chłodni;
- Google Cloud Storage;
- Google Cloud Storage Nearline do przechowywania zimnych danych oraz
- Microsoft Azure.
prywatna chmura. Usługa przechowywania w chmurze prywatnej to wewnętrzny zasób pamięci masowej wdrożony jako dedykowane środowisko chronione za zaporą ogniową. Wewnętrznie hostowane implementacje pamięci masowej w chmurze prywatnej emulują niektóre funkcje komercyjnych usług chmury publicznej, zapewniając łatwy dostęp i alokację zasobów pamięci dla użytkowników biznesowych,a także protokoły pamięci obiektowej. Chmury prywatne są odpowiednie dla użytkowników, którzy potrzebują dostosowania i większej kontroli nad swoimi danymi lub którzy mają rygorystyczne wymagania dotyczące bezpieczeństwa danych lub przepisów.
chmura hybrydowa. Ta opcja przechowywania w chmurze to połączenie prywatnej pamięci masowej w chmurze i usług publicznej pamięci masowej innych firm, z warstwą zarządzania orkiestracją w celu operacyjnej integracji obu platform.
model oferuje elastyczność biznesową i więcej opcji wdrażania danych. Organizacja może na przykład przechowywać aktywnie wykorzystywane i ustrukturyzowane dane w lokalnej chmurze prywatnej oraz nieustrukturyzowane i archiwalne dane w chmurze publicznej. Środowisko hybrydowe ułatwia również obsługę sezonowych lub nieprzewidzianych skoków w tworzeniu danych lub dostępie, dzięki dostępowi do zewnętrznej usługi pamięci masowej w chmurze i unikaniu konieczności dodawania wewnętrznych zasobów pamięci masowej.
W ostatnich latach wzrosła popularność modelu chmury hybrydowej. Pomimo zalet chmury hybrydowej, stanowią one wyzwania techniczne, biznesowe i zarządcze. Na przykład, prywatne obciążenia muszą uzyskiwać dostęp do Dostawców pamięci masowej w chmurze publicznej i współdziałać z nimi, więc kompatybilność oraz niezawodna i szeroka łączność sieciowa są ważnymi czynnikami. System przechowywania danych w chmurze na poziomie przedsiębiorstwa powinien być skalowalny, dostosowany do obecnych i przyszłych potrzeb, dostępny z dowolnego miejsca i niezależny od aplikacji.
Jak działa Przechowywanie w chmurze?
dostawcy usług w chmurze utrzymują duże centra danych w wielu lokalizacjach na całym świecie. Gdy klienci kupują od dostawcy pamięć masową w chmurze, przekazują dostawcy większość aspektów przechowywania danych, w tym Bezpieczeństwo, pojemność, serwery pamięci masowej i zasoby obliczeniowe, dostępność danych i dostarczanie danych przez sieć. Aplikacje klienckie mogą uzyskać dostęp do przechowywanych danych w chmurze za pośrednictwem tradycyjnych protokołów przechowywania lub wskaźników programowania aplikacji (API) lub mogą być również przenoszone do chmury.
sposób działania pamięci masowej w chmurze zależy od rodzaju używanej pamięci masowej. Trzy główne typy to block storage, file storage i object storage:
- Przechowywanie bloków dzieli duże ilości danych na mniejsze jednostki zwane blokami. Każdy blok jest powiązany z unikalnym identyfikatorem i umieszczany na jednym z dysków pamięci masowej systemu. Pamięć masowa blokowa jest szybka, wydajna i zapewnia niskie opóźnienia wymagane przez aplikacje, takie jak bazy danych i wysokowydajne obciążenia.
- File storage porządkuje dane w hierarchicznym systemie plików i folderów; jest powszechnie używany z dyskami pamięci masowej komputerów osobistych i sieciową pamięcią masową (NAS). Dane w systemie przechowywania plików są przechowywane w plikach, a pliki są przechowywane w folderach. Katalogi i podkatalogi są używane do organizowania folderów i lokalizowania plików i danych. Chmura oparta na pamięci plików może ułatwić dostęp do danych i ich pobieranie, a ten hierarchiczny format jest znany użytkownikom i wymagany przez niektóre aplikacje.
- Object storage przechowuje dane jako obiekty, które składają się z trzech składników: danych przechowywanych w pliku, metadanych powiązanych z plikiem danych i unikalnego identyfikatora. Korzystając z interfejsu API RESTful, obiektowy protokół przechowywania przechowuje plik i powiązane z nim metadane jako pojedynczy obiekt i przypisuje mu numer identyfikacyjny (ID). Aby pobrać zawartość, użytkownik przedstawia systemowi IDENTYFIKATOR, a zawartość jest łączona ze wszystkimi metadanymi, uwierzytelnianiem i zabezpieczeniami. Obiektowe systemy pamięci masowej umożliwiają dostosowywanie metadanych, co może usprawnić dostęp do danych i ich analizę. Dzięki obiektowej pamięci masowej dane mogą być przechowywane w natywnym formacie z ogromną skalowalnością.
w ostatnich latach dostawcy object storage dodali funkcje i możliwości systemu plików do swojego oprogramowania i sprzętu object storage głównie dlatego, że obiektowa pamięć masowa nie była wystarczająco szybko wdrażana. Na przykład Brama pamięci masowej w chmurze może zapewnić interfejs emulacji systemu plików do obiektowej pamięci masowej; taki układ często umożliwia aplikacjom dostęp do danych bez obsługi protokołu object storage. Wszystkie aplikacje do tworzenia kopii zapasowych używają protokołu object storage, co jest jednym z powodów, dla których tworzenie kopii zapasowych online w usłudze w chmurze było początkowo pomyślną aplikacją do przechowywania w chmurze.
większość komercyjnych usług przechowywania danych w chmurze korzysta z ogromnej liczby systemów przechowywania dysków twardych zamontowanych w serwerach połączonych architekturą sieci podobną do siatki. Dostawcy usług dodali również wysokowydajne warstwy do swojej oferty wirtualnej pamięci masowej, zazwyczaj składającej się z dysków SSD. Wysokowydajna pamięć masowa w chmurze jest na ogół najbardziej skuteczna, jeśli serwery i aplikacje uzyskujące dostęp do pamięci masowej są również rezydentami w środowisku chmurowym.
Dowiedz się więcej o zaletach i wadach przechowywania bloków, plików i obiektów.
zalety i wady pamięci masowej w chmurze
pamięć masowa w chmurze zapewnia wiele korzyści, które skutkują oszczędnością kosztów i większą wygodą dla użytkowników w porównaniu z tradycyjnymi sieciami pamięci masowej (SAN). Istnieją również niedociągnięcia w pamięci masowej w chmurze-szczególnie w usługach publicznych-które sprawiają, że organizacje wahają się korzystać z tych usług lub ograniczają ich wykorzystanie.
zalety
- Pay as you go. Dzięki usłudze przechowywania w chmurze klienci płacą tylko za używaną pamięć masową, eliminując konieczność dużych wydatków kapitałowych. Chociaż koszty przechowywania w chmurze są powtarzające się, a nie jednorazowy zakup, często są one tak niskie, że nawet jako stały wydatek mogą być nadal niższe niż koszty utrzymania systemu wewnętrznego.
- fakturowanie. Ponieważ klienci płacą tylko za pojemność, z której korzystają, koszty przechowywania w chmurze mogą spadać wraz ze spadkiem zużycia. Jest to w przeciwieństwie do korzystania z wewnętrznego systemu pamięci masowej, który prawdopodobnie będzie nadmiernie skonfigurowany do obsługi przewidywanego wzrostu. Firma zapłaci za więcej niż początkowo potrzebuje, a koszt przechowywania nigdy nie spadnie.
- globalna dostępność. Pamięć masowa w chmurze jest zazwyczaj dostępna z dowolnego systemu, w dowolnym miejscu i czasie; użytkownicy nie muszą się martwić o możliwości systemu operacyjnego (OS) lub złożonych procesów alokacji.
- łatwość obsługi. Dzięki temu programiści, testerzy oprogramowania i użytkownicy biznesowi mogą szybko rozpocząć pracę bez konieczności oczekiwania na przydzielenie i skonfigurowanie zasobów pamięci masowej przez zespół IT (informatyczny).
- Ochrona poza zakładem. Z samej natury usługa public cloud storage umożliwia przenoszenie kopii danych do zdalnej witryny w celu tworzenia kopii zapasowych i bezpieczeństwa. Oznacza to również znaczne oszczędności w porównaniu z utrzymywaniem własnego zdalnego obiektu przez firmę.
wewnętrzny system przechowywania danych w chmurze może oferować niektóre z powyższych funkcji łatwości użycia usługi publicznej w chmurze, ale brakuje mu dużej elastyczności pojemności pamięci masowej w usłudze publicznej. Niektórzy dostawcy sprzętu próbują rozwiązać ten problem, umożliwiając swoim klientom włączanie i wyłączanie pojemności, która została już zainstalowana w ich tablicach.
- bezpieczeństwo. Bezpieczeństwo danych jest najczęściej wymienianym czynnikiem, który może sprawić, że firmy będą ostrożne w korzystaniu z publicznej pamięci masowej w chmurze. Obawa polega na tym, że po opuszczeniu siedziby firmy dane nie mają już kontroli nad tym, w jaki sposób są przetwarzane i przechowywane. Problemem jest również przechowywanie regulowanych danych. Dostawcy usług starali się rozwiać te obawy, zwiększając swoje możliwości bezpieczeństwa za pomocą szyfrowania danych, uwierzytelniania wieloczynnikowego (MFA), przechowywania danych w wielu lokalizacjach i poprawy bezpieczeństwa fizycznego.
- dostęp do danych. Utrzymanie dostępu do danych przechowywanych w chmurze może również stanowić problem i może znacznie zwiększyć koszty korzystania z magazynu w chmurze. Firma może wymagać uaktualnienia połączenia z usługą przechowywania danych w chmurze, aby obsłużyć ilość danych, które zamierza przesłać. Na przykład miesięczny koszt łącza optycznego może sięgać tysięcy dolarów.
- degradacja wydajności. Firma może napotkać problemy z wydajnością, jeśli jej wewnętrzne aplikacje muszą uzyskać dostęp do danych przechowywanych w chmurze. W takich przypadkach prawdopodobnie będzie to wymagało przeniesienia serwerów i aplikacji do tej samej chmury lub przywrócenia niezbędnych danych do domu.
- koszt. Jeśli firma wymaga dużej pojemności pamięci masowej w chmurze i często przenosi swoje dane między systemami lokalnymi a chmurą, miesięczne koszty mogą być wysokie. W porównaniu z wdrożeniem pamięci masowej we własnym zakresie koszty bieżące mogą ostatecznie przewyższyć koszty wdrożenia i utrzymania systemu lokalnego.
kwestie związane z pamięcią masową w chmurze
aby określić, czy korzystanie z pamięci masowej w chmurze przyniesie efektywność operacyjną i będzie opłacalne, firma musi podjąć następujące cztery kroki:
- Porównaj jednorazowe i powtarzające się koszty zakupu i zarządzania pojemnością pamięci masowej we własnym zakresie z bieżącymi kosztami przechowywania i dostępu do danych w chmurze.
- Określ, czy dodatkowe koszty telekomunikacyjne będą wymagane dla odpowiedniego dostępu do usługodawcy.
- zdecyduj, czy usługa przechowywania w chmurze zapewnia odpowiednie bezpieczeństwo i nadzór nad danymi.
- opracowanie wewnętrznej strategii bezpieczeństwa w chmurze, z procedurami dostępu i korzystania z magazynu w chmurze w celu utrzymania efektywnego zarządzania danymi i kontroli wydatków.
przykłady pamięci masowej w chmurze
najczęstsze zastosowania pamięci masowej w chmurze to tworzenie kopii zapasowych w chmurze, odzyskiwanie po awarii (DR) i archiwizacja rzadko dostępnych danych. Coraz więcej firm korzysta z usług przechowywania danych w chmurze dla DevOps jako sposobu na obniżenie kosztów kapitałowych. Programiści mogą wydzielać zasoby obliczeniowe i magazynowe na czas opracowywania i testowania projektu, a następnie wyłączać je po jego zakończeniu.

coraz częściej organizacje przenoszą kluczowe aplikacje do chmury, ponieważ dostawcy usług poprawiają wydajność i zwiększają bezpieczeństwo. Ponadto firmy, które doświadczają znacznych sezonowych wahań ilości tworzonych danych, mogą korzystać z pamięci masowej w chmurze, aby poradzić sobie z tymi cyklami tworzenia danych.
dla małych i średnich firm (SMB) niektóre wyspecjalizowane usługi przechowywania danych w chmurze, takie jak synchronizacja plików i udostępnianie, mogą być przydatne dla poszczególnych serwerów lub użytkowników. Funkcje synchronizacji plików tych usług zapewniają spójność wersji plików przechowywanych lokalnie na kliencie synchronizacji-serwerze lub komputerze użytkownika końcowego-oraz w chmurze. Często są również dostępne funkcje wersjonowania i udostępniania plików.
rynek pamięci masowej w chmurze jest zdominowany przez Amazon Web Services, Google i Microsoft Azure, ale tradycyjni dostawcy pamięci masowej, tacy jak Dell EMC, Hewlett Packard Enterprise, Hitachi Data Systems, IBM i NetApp, również działają w przestrzeni z produktami zarówno dla właścicieli przedsiębiorstw, jak i małych firm, które obejmują samoobsługowe portale chmurowe do udostępniania i monitorowania użytkowania. Niektóre usługi przechowywania plików online, takie jak Box i Dropbox, oferują usługi przechowywania danych w chmurze business-to-consumer (B2C), a także business-to-business (B2B).
organizacje rozważające wykorzystanie pamięci masowej w chmurze powinny być świadome zalet i wad korzystania z technologii przetwarzania w chmurze. Jeśli zdecydujesz się na rozwój chmury, organizacje mogą korzystać z przewodników tematycznych w chmurze, aby określić, które typy pamięci masowej w chmurze i usługi najlepiej odpowiadają ich potrzebom biznesowym.