modelowanie danych to proces dokumentowania złożonego projektu systemu oprogramowania jako łatwo zrozumiałego diagramu, przy użyciu tekstu i symboli do reprezentowania sposobu, w jaki dane muszą przepływać. Diagram może być stosowany w celu zapewnienia efektywnego wykorzystania danych, jako plan budowy nowego oprogramowania lub do przeprojektowania starszej aplikacji.
modelowanie danych jest ważną umiejętnością dla analityków danych lub innych osób zaangażowanych w analizę danych. Tradycyjnie modele danych zostały zbudowane podczas fazy analizy i projektowania projektu, aby zapewnić, że wymagania dotyczące nowej aplikacji są w pełni zrozumiałe. Modele danych mogą być również wywoływane później w cyklu życia danych w celu racjonalizacji projektów danych, które zostały pierwotnie utworzone przez programistów na zasadzie ad hoc.
metody modelowania danych
modelowanie danych może być żmudnym procesem wstępnym i jako takie jest czasami postrzegane jako sprzeczne z metodologiami szybkiego rozwoju. Ponieważ Programowanie zwinne weszło w szersze zastosowanie do przyspieszania projektów programistycznych, po fakcie metody modelowania danych są w niektórych przypadkach dostosowywane. Zazwyczaj model danych można traktować jako schemat blokowy, który ilustruje relacje między danymi. Umożliwia zainteresowanym stronom identyfikowanie błędów i wprowadzanie zmian przed napisaniem kodu programowania. Alternatywnie, modele mogą być wprowadzane w ramach prac inżynierii odwrotnej, które wyodrębniają modele z istniejących systemów, jak widać w danych NoSQL.
modelarze danych często używają wielu modeli, aby wyświetlić te same dane i upewnić się, że wszystkie procesy, jednostki, relacje i przepływy danych zostały zidentyfikowane. Inicjują nowe projekty, zbierając wymagania od interesariuszy biznesowych. Etapy modelowania danych z grubsza dzielą się na tworzenie logicznych modeli danych, które pokazują określone atrybuty, jednostki i relacje między jednostkami i fizycznym modelem danych.
logiczny model danych służy jako podstawa do stworzenia fizycznego modelu danych, który jest specyficzny dla aplikacji i bazy danych, które mają zostać zaimplementowane. Model danych może stać się podstawą do budowy bardziej szczegółowego schematu danych.
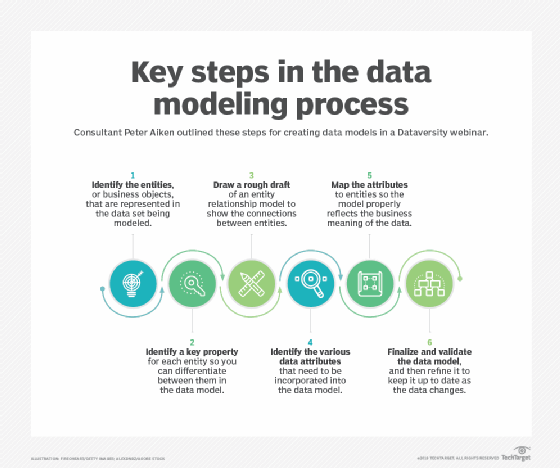
hierarchiczne modelowanie danych
modelowanie danych jako dyscyplina zaczęła powstawać w latach 60.systemów zarządzania bazami danych (dbmses). Modelowanie danych umożliwiło organizacjom zapewnienie spójności, powtarzalności i uporządkowanego rozwoju przetwarzania danych. Użytkownicy końcowi aplikacji i programiści mogli wykorzystać model danych jako punkt odniesienia w komunikacji z projektantami danych.
hierarchiczne modele danych, które układają dane w podobny sposób, układ jeden do wielu, oznaczały te wczesne wysiłki i zastąpiły systemy oparte na plikach w wielu popularnych przypadkach użycia. IBM Information Management System (IMS) jest podstawowym przykładem hierarchicznego podejścia, które znalazło szerokie zastosowanie w przedsiębiorstwach, zwłaszcza w bankowości. Chociaż hierarchiczne modele danych zostały w dużej mierze zastąpione-począwszy od lat 80-tych-relacyjnymi modelami danych, metoda hierarchiczna jest nadal powszechna w XML (Extensible Markup Language) i systemach informacji geograficznej (gises) dzisiaj. Sieciowe modele danych powstały również we wczesnych dniach DBMSes jako sposób na zapewnienie projektantom danych szerokiego koncepcyjnego spojrzenia na ich systemy. Jednym z takich przykładów jest konferencja na temat języków Systemów danych (CODASYL), która powstała pod koniec lat 50., aby poprowadzić rozwój standardowego języka programowania, który mógłby być używany na różnych typach komputerów.
relacyjne modelowanie danych
chociaż zmniejszyło to złożoność programu w porównaniu do systemów opartych na plikach, model hierarchiczny nadal wymagał szczegółowego zrozumienia konkretnego fizycznego przechowywania danych. Proponowany jako alternatywa dla hierarchicznego modelu danych, relacyjny model danych nie wymaga od programistów definiowania ścieżek danych. Relacyjne modelowanie danych zostało po raz pierwszy opisane w artykule technicznym z 1970 roku przez badacza IBM E. F. Codda. Model relacyjny Codd stworzył scenę dla przemysłowego wykorzystania relacyjnych baz danych, w których segmenty danych są jawnie łączone za pomocą tabel, w porównaniu z modelem hierarchicznym, w którym dane są niejawnie łączone. Wkrótce po jego powstaniu relacyjny model danych został połączony z ustrukturyzowanym językiem zapytań (SQL) i zaczął zdobywać coraz większe przyczółki w komputerach korporacyjnych jako skuteczny sposób przetwarzania danych.
model relacji jednostek
relacyjne modelowanie danych zrobiło kolejny krok naprzód, począwszy od połowy lat 70., gdy modele relacji jednostek (er) stały się bardziej powszechne. Modele ER, ściśle zintegrowane z relacyjnymi modelami danych, wykorzystują diagramy do graficznego przedstawienia elementów w bazie danych i ułatwiają zrozumienie podstawowych modeli.
dzięki modelowaniu relacyjnemu typy danych są określane i rzadko zmieniane w czasie. Jednostki obejmują atrybuty; na przykład atrybuty jednostki pracowniczej mogą obejmować nazwisko, imię, rok zatrudnienia i tak dalej. Relacje są wizualnie mapowane, zapewniając gotowy sposób komunikowania celów projektowania danych różnym uczestnikom w rozwoju i utrzymaniu danych. Z biegiem czasu Narzędzia do modelowania, w tym ER/Studio Idery, Erwin Data Modeler i SAP PowerDesigner, zyskały szerokie zastosowanie wśród architektów danych do projektowania systemów.
wraz z pojawieniem się programowania obiektowego w latach 90., modelowanie obiektowe zyskało na popularności jako kolejny sposób projektowania systemów. Przy pewnym podobieństwie do metod ER, podejścia zorientowane obiektowo różnią się tym, że koncentrują się na obiektowych abstrakcjach Bytów świata rzeczywistego. Obiekty są grupowane w hierarchiach klas, a obiekty w takich hierarchiach klas mogą dziedziczyć atrybuty i metody z klas nadrzędnych. Ze względu na tę cechę dziedziczenia, obiektowe modele danych mają pewne zalety w porównaniu z modelowaniem ER, pod względem zapewnienia integralności danych i obsługi bardziej złożonych relacji danych. W latach 90. pojawiły się również modele danych specjalnie zorientowane na potrzeby hurtowni danych. Godnymi uwagi przykładami są schematy płatków śniegu i modele wymiarowe schematu Gwiazdy.
Modele danych Wykresowych
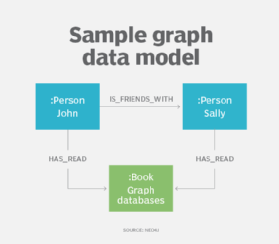
pochodną hierarchicznego i sieciowego modelowania danych jest property graph model, który wraz z grafowymi bazami danych znalazł coraz większe zastosowanie do opisywania złożonych relacji w ramach zestawów danych, szczególnie w mediach społecznościowych, aplikacjach polecających i wykrywających oszustwa.
korzystając z modelu danych grafu, projektanci opisują swój system jako połączony Wykres węzłów i relacji, podobnie jak w przypadku ER lub modelowania danych obiektowych. Wykresowe modele danych mogą być używane do analizy tekstu, tworząc modele, które odkrywają relacje między punktami danych w dokumentach.