
Det er et viktig poeng å forstå. Ikke bare vil bruk av feil metode noen ganger føre til at sider ikke blir fjernet fra indeksen som beregnet, men det kan også ha en negativ effekt PÅ SEO.
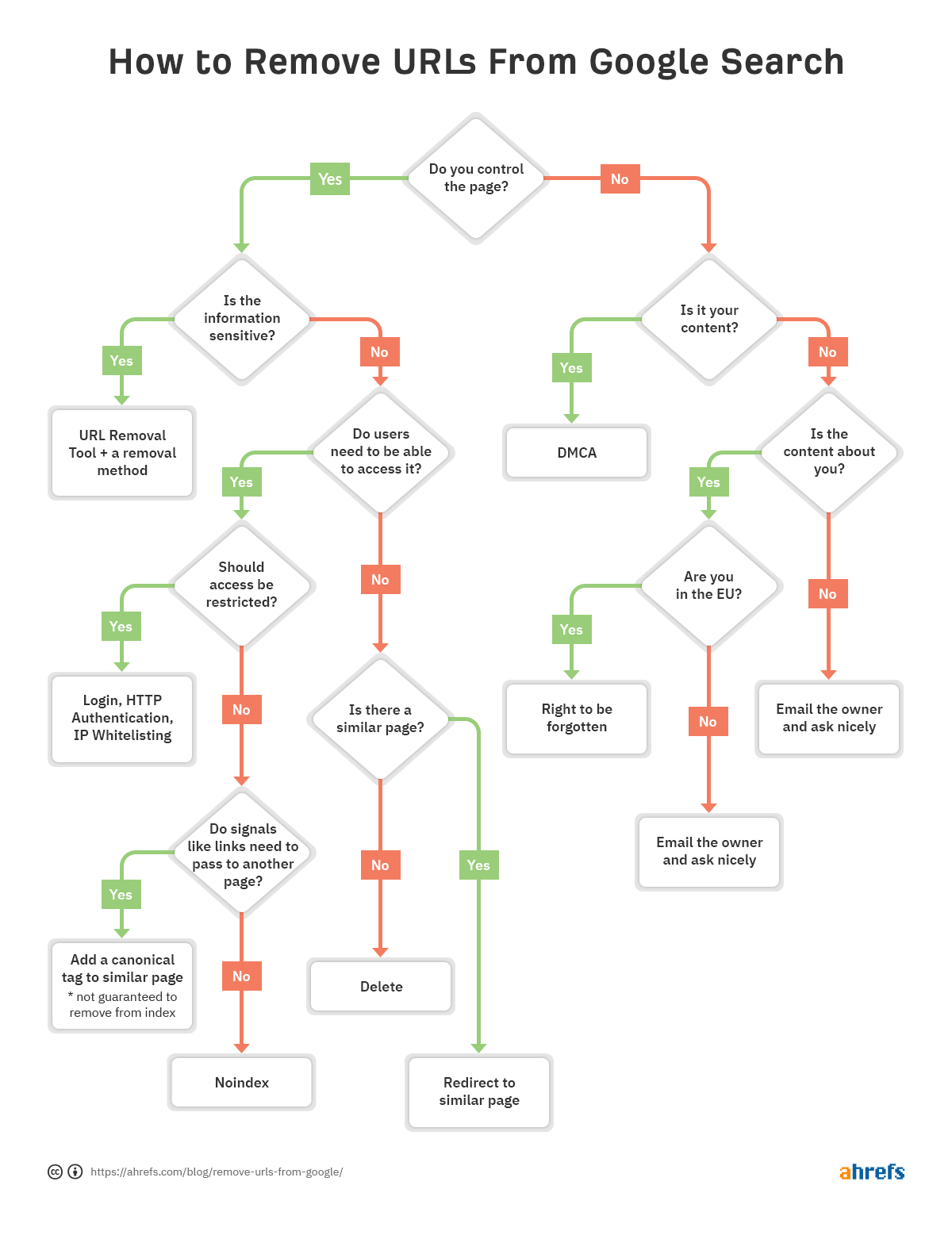
for å hjelpe deg med å raskt bestemme hvilken metode for fjerning som er best for deg, har vi laget et flytskjema slik at du kan hoppe til den aktuelle delen av artikkelen.
I dette innlegget lærer du:
det jeg vanligvis ser Seo gjøre for å sjekke om innholdet er indeksert, er å bruke et nettsted: søk I Google (f.eks. nettsted: https://ahrefs.com). Mens nettstedet: søk kan være nyttig for å identifisere sider eller deler av et nettsted som kan være problematisk hvis de vises i søkeresultatene, må du være forsiktig fordi de ikke er vanlige spørringer og vil faktisk ikke fortelle deg om en side er indeksert. De kan vise sider Som Er Kjent For Google, men det betyr ikke at De er kvalifisert til å vises i vanlige søkeresultater uten områdeoperatøren.
for eksempel kan nettsted: søk fortsatt vise sider som omdirigerer eller kanoniseres til en annen side. Når Du ber Om et bestemt nettsted, Kan Google vise en side fra det domenet med innholdet, tittelen og beskrivelsen fra et annet domene. Ta for eksempel moz.com som pleide å være seomoz.org. eventuelle vanlige brukerforespørsler som fører til sider på moz.com vil vise moz.com I SERPs, mens site:seomoz.org vil vise seomoz.org i søkeresultatene som vist nedenfor.
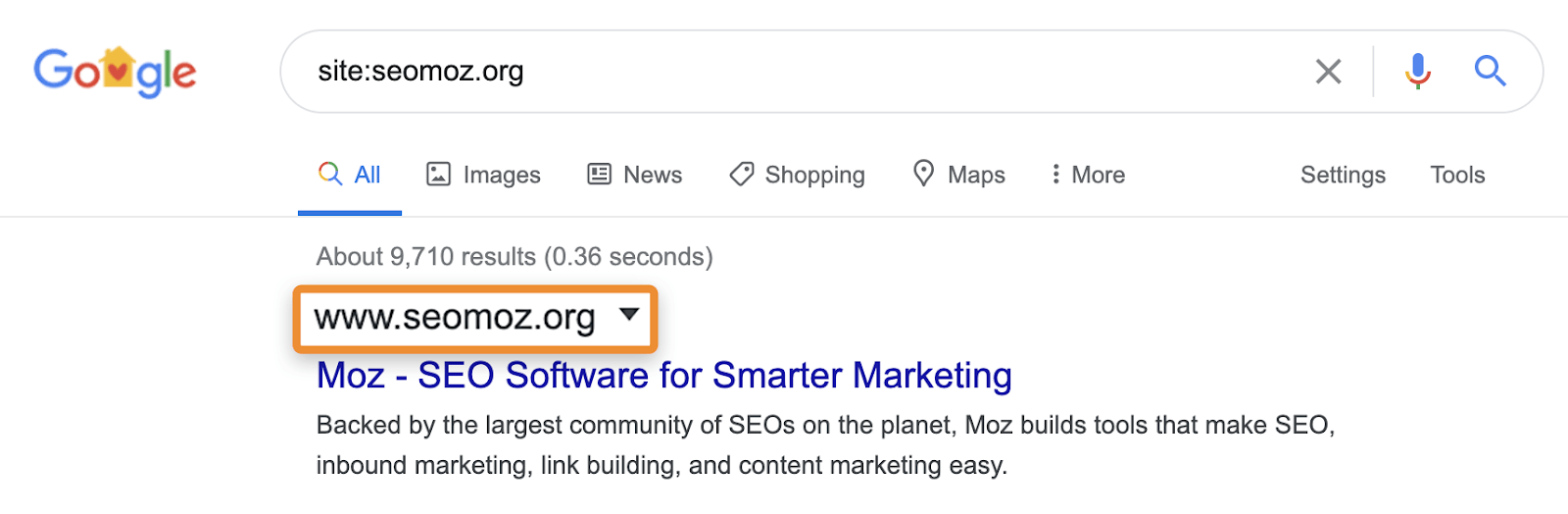
grunnen til at Dette er et viktig skille er at det kan føre Seo å gjøre feil som aktivt blokkere Eller fjerne Nettadresser fra indeksen for det gamle domenet, som hindrer konsolidering av signaler Som PageRank. Jeg har sett mange tilfeller med domeneoverføringer der folk tror de gjorde en feil under overføringen fordi disse sidene fortsatt viser for site:old-domain.com søker og ende opp aktivt skade deres hjemmeside mens du prøver å «fikse» problemet.
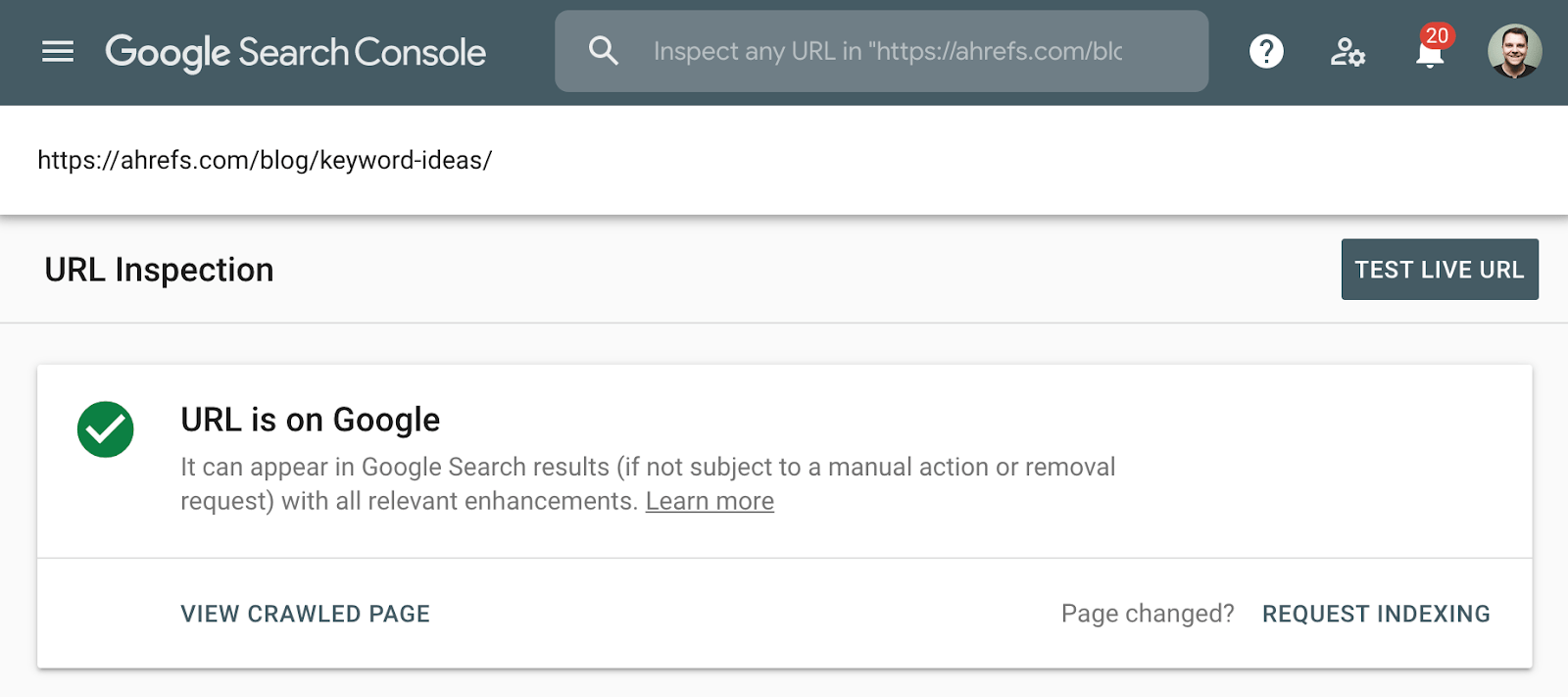
Den beste metoden for å sjekke indeksering er Å bruke Indeksdekningsrapporten I Google Search Console, Eller Url-Inspeksjonsverktøyet for en ENKELT URL. Disse verktøyene forteller deg om en side er indeksert og gir ytterligere informasjon om Hvordan Google behandler siden. Hvis du ikke har tilgang til dette, bare søk På Google for hele NETTADRESSEN til siden din.
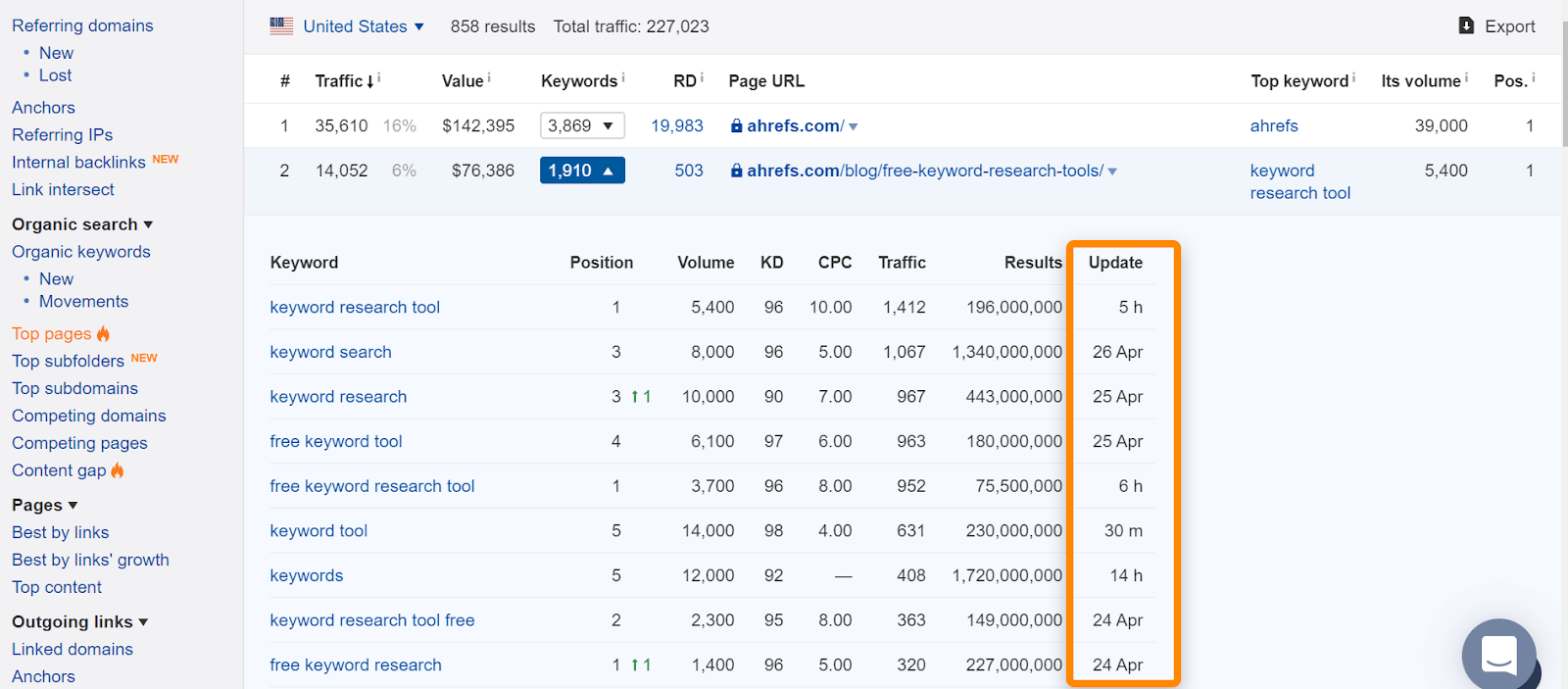
I Ahrefs, hvis du finner siden i vår «Toppsider» rapport eller rangering for organiske søkeord, betyr det vanligvis at vi så det rangering for normale søk og er en god indikasjon på at siden ble indeksert. Merk at sidene ble indeksert da vi så dem, men det kan ha endret seg. Sjekk datoen vi sist så siden for en spørring.
hvis det er et problem med EN BESTEMT URL og den må fjernes fra indeksen, følg flytskjemaet i begynnelsen av artikkelen for å finne riktig alternativ for fjerning, og hopp deretter til den aktuelle delen nedenfor.
hvis du fjerner siden og serverer enten en 404 (ikke funnet) eller 410 (borte) statuskode, blir siden fjernet fra indeksen kort tid etter at siden er gjennomgått på nytt. Inntil den er fjernet, kan siden fortsatt vises i søkeresultatene. Og selv om selve siden ikke lenger er tilgjengelig, kan en bufret versjon av siden være midlertidig tilgjengelig.
når du trenger et annet alternativ:
- jeg trenger mer umiddelbar fjerning. Se DELEN url removal tool.
- jeg trenger å konsolidere signaler som lenker. Se avsnittet kanonisering.
- jeg trenger siden tilgjengelig for brukere. Se om noindex eller begrense tilgang seksjoner passer din situasjon.
- Alternativ 2 Fjerning: Noindex
- Fjerningsalternativ 3: Begrense tilgang
- Alternativ 4: URL Removal Tool
- Alternativ 5: Canonicalization
- Noindex i roboter.txt
- Blokkering fra kravlesøk i roboter.Txt
- Nofollow
- Noindex Og canonical til en ANNEN URL
- Noindex, vent På At Google skal gjennomgå, og blokker deretter fra gjennomsøking
- Hva om det er innhold om deg, men ikke på et nettsted du eier?
- Final thoughts
Alternativ 2 Fjerning: Noindex
en noindex meta robots tag eller x-robots header respons vil fortelle søkemotorer å fjerne en side fra indeksen. Meta robots-taggen fungerer for sider der x-robots-responsen fungerer for sider og flere filtyper som Pdf-Filer. For at disse kodene skal bli sett, må en søkemotor kunne gjennomsøke sidene – så sørg for at de ikke er blokkert i roboter.txt. Vær også oppmerksom på at fjerning av sider fra indeksen kan forhindre konsolidering av lenke og andre signaler.
Eksempel på en meta robots noindex:
<meta name="robots" content="noindex">
Eksempel på x‑robots noindex-tag i header-svaret:
HTTP/1.1 200 OKX-Robots-Tag: noindex
når du kanskje trenger et annet alternativ:
- jeg vil ikke at brukerne skal få tilgang til disse sidene. Se delen begrense tilgang.
- jeg trenger å konsolidere signaler som lenker. Se avsnittet kanonisering.
Fjerningsalternativ 3: Begrense tilgang
hvis du vil at siden skal være tilgjengelig for noen brukere, men ikke søkemotorer, så er det sannsynligvis et av disse tre alternativene:
- en slags påloggingssystem;
- HTTP-Autentisering (hvor et passord kreves for tilgang);
- Ip-Hvitelisting (som bare tillater spesifikke IP-adresser å få tilgang til sidene)
denne typen oppsett er best for ting som interne nettverk, medlemsinnhold eller for oppstart, test eller utviklingssteder. Det tillater en gruppe brukere å få tilgang til siden, men søkemotorer vil ikke kunne få tilgang til dem og vil ikke indeksere sidene.
når du trenger et annet alternativ:
- jeg trenger mer umiddelbar fjerning. Se DELEN url removal tool. I dette tilfellet vil du kanskje ha mer umiddelbar fjerning hvis innholdet du prøver å skjule, er bufret, og du må forhindre at brukere ser innholdet.
Alternativ 4: URL Removal Tool
navnet På dette verktøyet Fra Google er litt misvisende som måten det fungerer er at det vil midlertidig skjule innholdet. Google vil fortsatt se og gjennomgå dette innholdet, men sidene vises ikke for brukere. Denne midlertidige effekten varer i seks måneder I Google, Mens Bing har et lignende verktøy som varer i tre måneder. Disse verktøyene bør brukes i de mest ekstreme tilfeller for ting som sikkerhetsproblemer, datalekkasjer, personlig identifiserbar informasjon (PII), etc. For Google, bruk Verktøyet For Fjerning og For Bing, se slik blokkerer Du Nettadresser.
du må fortsatt bruke en annen metode sammen med å bruke verktøyet for fjerning for å faktisk ha sidene fjernet for en lengre periode (noindex eller slette) eller hindre brukere fra å få tilgang til innholdet hvis de fortsatt har koblinger (slette eller begrense tilgang). Dette gir deg bare en raskere måte å skjule sidene mens fjerningen har tid til å behandle. Forespørselen kan ta opptil en dag å behandle.
Alternativ 5: Canonicalization
når du har flere versjoner av en side og ønsker å konsolidere signaler som lenker til en enkelt versjon, hva du ønsker å gjøre er noen form for kanonisering. Dette er for det meste for å forhindre duplikatinnhold mens du konsoliderer flere versjoner av en side til en enkelt indeksert URL.
du har flere kanoniseringsalternativer:
- Canonical tag. Dette angir en ANNEN URL som den kanoniske versjonen eller versjonen du vil bli vist. Hvis sidene er like eller like, bør dette være greit. Når sidene er for forskjellige, kan den kanoniske bli ignorert som det er et hint og ikke et direktiv.
- Omdirigeringer. En omdirigering tar en bruker og en søkebot fra en side til en annen. 301 er den mest brukte omdirigeringen av Seo, og den forteller søkemotorene at du vil at den endelige NETTADRESSEN skal være den som vises i søkeresultatene og hvor signaler konsolideres. En 302 eller midlertidig omdirigering forteller søkemotorer at du vil at den opprinnelige NETTADRESSEN skal være den som skal forbli i indeksen og konsolidere signaler der.
- URL-parameterhåndtering. En parameter legges til slutten AV NETTADRESSEN og inneholder vanligvis et spørsmålstegn, som ahrefs. com?this = parameter. Dette verktøyet Fra Google lar deg fortelle Dem hvordan De skal behandle Nettadresser med bestemte parametere. Du kan for eksempel angi om parameteren endrer sideinnholdet, eller om det bare er ment å spore bruken.
hvis du har flere sider å fjerne Fra Googles indeks, bør de prioriteres tilsvarende.
Høyeste prioritet: disse sidene er vanligvis sikkerhetsrelaterte eller relatert til konfidensielle data. Dette inkluderer innhold som inneholder personopplysninger (PII), kundedata eller proprietær informasjon.
middels prioritet: dette innebærer vanligvis innhold ment for en bestemt gruppe brukere. Selskapets intranett eller ansattes portaler, innhold ment for medlemmer, og iscenesettelse, test, eller utviklingsmiljøer.
Lav prioritet: disse sidene involverer vanligvis duplikat innhold av noe slag. Noen eksempler på dette vil inkludere sider som serveres fra flere Nettadresser, Nettadresser med parametere, og igjen kan inkludere staging, test eller utviklingsmiljøer.
jeg vil dekke noen av måtene jeg vanligvis ser fjerning gjort feil og hva som skjer i hvert scenario for å hjelpe folk å forstå hvorfor de ikke fungerer.
Noindex i roboter.txt
Mens Google pleide å uoffisielt støtte noindex i roboter.txt, det var aldri en offisiell standard, og de har nå formelt fjernet støtte. Mange av nettstedene som gjorde dette gjorde det feil og skadet seg selv.
Blokkering fra kravlesøk i roboter.Txt
Crawling er ikke det samme som indeksering. Selv Om Google er blokkert fra å gjennomsøke sider, hvis det er noen interne eller eksterne lenker til en side, kan de fortsatt indeksere den. Google vil ikke vite hva som er på siden fordi de ikke vil gjennomgå det, men de vet at en side eksisterer og vil til og med skrive en tittel som skal vises i søkeresultatene basert på signaler som ankerteksten til koblinger til siden.
Nofollow
Dette blir ofte forvirret for noindex, og noen vil bruke det på et sidenivå og forventer at siden ikke skal indekseres. Nofollow er et hint, og mens det opprinnelig stoppet koblinger på siden og individuelle koblinger med nofollow-attributtet fra å bli gjennomsøkt, er det ikke lenger tilfelle. Google kan nå gjennomgå disse koblingene hvis de vil. Nofollow ble også brukt på individuelle lenker for å prøve Å stoppe Google fra å krype gjennom til bestemte sider og For PageRank sculpting. Igjen, dette fungerer ikke lenger siden nofollow er et hint. Tidligere, Hvis siden hadde en annen lenke til Den, Kunne Google fortsatt oppdage fra denne alternative gjennomsøkingsbanen.
Merk at du kan finne nofollowed sider i bulk ved hjelp av dette filteret I Sideutforskeren I Ahrefs ‘ Områderevisjon.
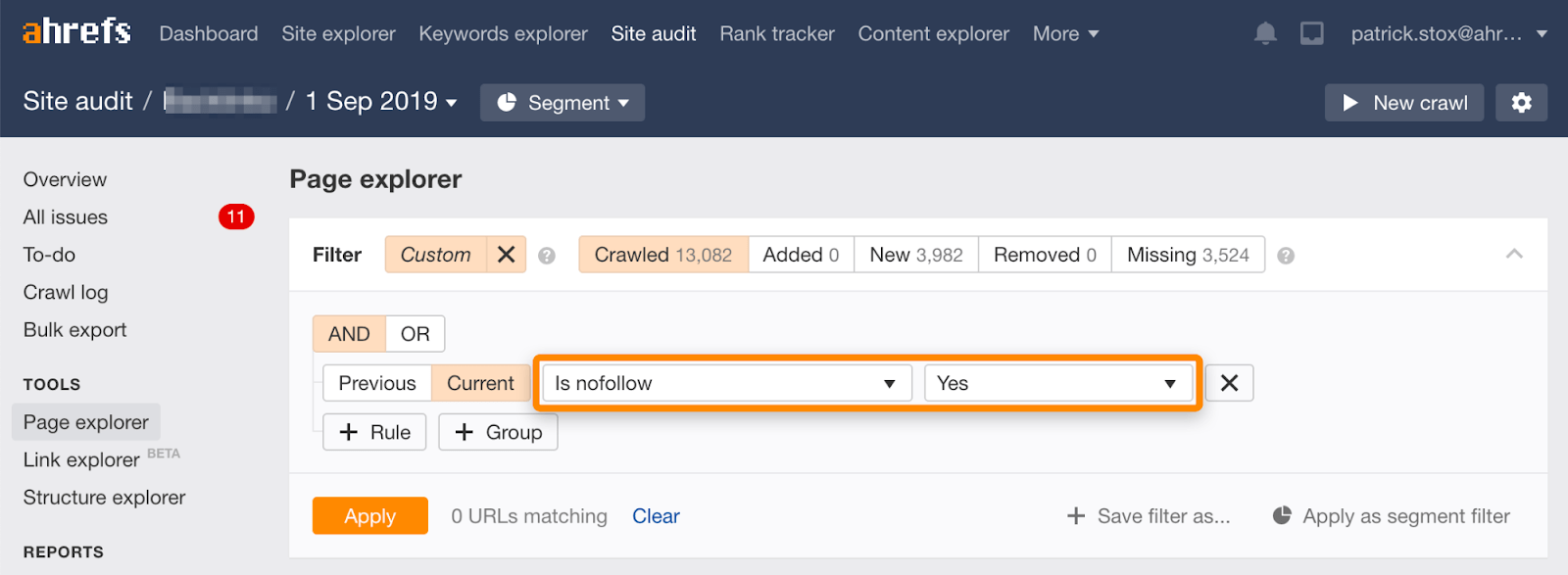
da det sjelden er fornuftig å nofollow alle lenker på en side, bør antall resultater være null eller nær null. Hvis det er matchende resultater, oppfordrer jeg deg til å sjekke om nofollow-direktivet ved et uhell ble lagt til i stedet for noindex og å velge en mer passende metode for fjerning hvis det er nødvendig.
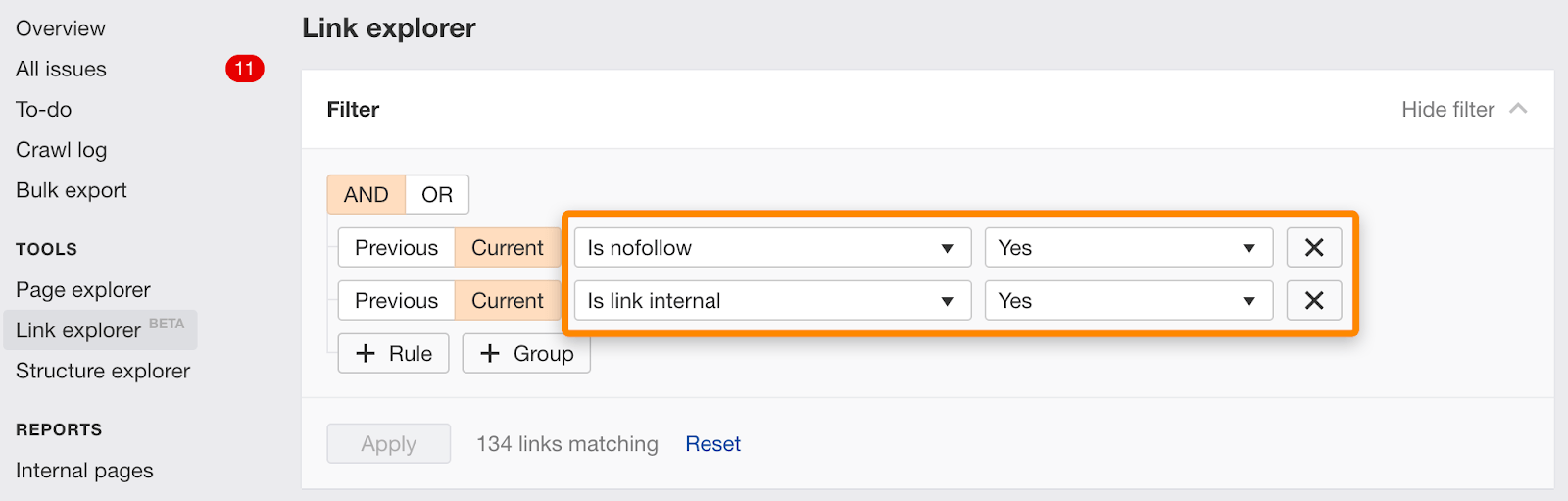
du kan også finne enkeltlenker merket nofollow ved hjelp av dette filteret i Link Explorer.
Noindex Og canonical til en ANNEN URL
disse signalene er motstridende. Noindex sier å fjerne siden fra indeksen, og canonical sier at en annen side er den versjonen som skal indekseres. Dette kan faktisk fungere for konsolidering Som Google vil vanligvis velge å ignorere noindex og i stedet bruke kanonisk som hovedsignal. Dette er imidlertid ikke en absolutt oppførsel. Det er en algoritme involvert, og det er en risiko for at noindex-taggen kan telles. Hvis det er tilfelle, vil sidene ikke konsolidere riktig.
Merk at du kan finne noindexed sider med ikke-selvrefererende kanonikaler ved hjelp av dette settet med filtre i Sideutforskeren i Site Audit:
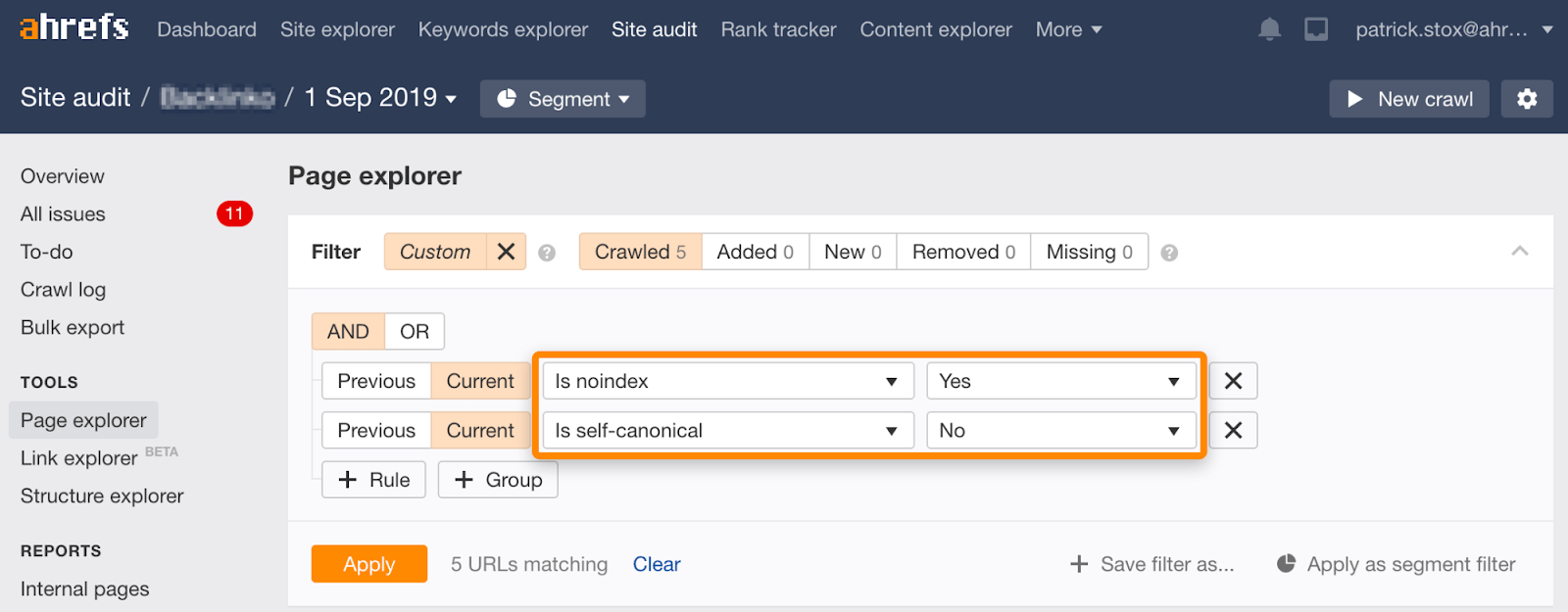
Noindex, vent På At Google skal gjennomgå, og blokker deretter fra gjennomsøking
Det er et par måter dette vanligvis skjer på:
- Sider er allerede blokkert, men er indeksert, folk legger noindex og oppheve blokkeringen slik at google kan gjennomgå og se noindex, deretter blokkere sidene fra kravlesøk igjen.
- folk legger til noindex-koder for sidene de vil ha fjernet, og Etter At Google har gjennomsøkt og behandlet noindex-taggen, blokkerer de sidene fra gjennomsøking.
uansett er den endelige tilstanden blokkert fra kravlesøk. Hvis du husker, tidligere snakket vi om hvordan gjennomsøking ikke er det samme som indeksering. Selv om disse sidene er blokkert, kan de fortsatt ende opp i indeksen.
hvis du eier innholdet som brukes på et annet nettsted, kan Du kanskje sende inn et krav basert På Digital Millennium Copyright Act (DMCA). Du kan bruke Googles Verktøy For Fjerning Av Opphavsrett til Å gjøre det som kalles EN DMCA-takedown, som ber om fjerning av opphavsrettsbeskyttet materiale.
Hva om det er innhold om deg, men ikke på et nettsted du eier?
hvis DU er I EU, kan du få fjernet innhold som inneholder informasjon om deg, takket være en rettskjennelse for retten til å bli glemt. Du kan be om å få personlig informasjon fjernet ved HJELP AV EU Privacy Removal form.
for å fjerne bilder Fra Google, er den enkleste måten med roboter.txt. Mens den uoffisielle støtten for fjerning av sider ble fjernet fra roboter.txt som vi nevnte tidligere, er det bare å avvise gjennomsøking av bilder den riktige måten å fjerne bilder på.
For et enkelt bilde:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
for alle bilder:
User-agent: Googlebot-ImageDisallow: /
Final thoughts
Hvordan du fjerner Nettadresser er ganske situasjonell. Vi har snakket om flere alternativer, men hvis du fortsatt er forvirret som passer for deg, se tilbake til flytskjemaet i starten.
du kan også gå gjennom juridisk feilsøking levert Av Google for fjerning av innhold.
Har du spørsmål? Gi meg beskjed på Twitter.