- Eh? HVA ER GRUPPERING SETT, KUBE OG SAMLEOPPDATERING I SQL?
- Hvorfor VILLE ROLLUP eller CUBE være nyttig for meg?
- Er disse standard SQL eller Er De En Microsoft-eneste ting?
- kan jeg ekskludere en eller flere kolonner fra SAMLEOPPDATERINGEN?
- Hva ER GRUPPERINGSSETT da? Bør jeg vite om dem?
- Hvorfor skulle vi ønske å kombinere kolonner i noen aggregering?
- ER DET mer Å GRUPPERE SETT enn en måte å gjøre ‘à la carte’ Kuber?
- Hvorfor er funksjonene Gruppering() og Grouping_ID() gitt?
- Eh? HVA ER GRUPPERING SETT, KUBE OG SAMLEOPPDATERING I SQL?
- Hvorfor SKULLE SAMLEOBJEKT eller KUBE være nyttig for meg?
- Er disse standard SQL eller Er De En Microsoft-eneste ting?
- kan jeg ekskludere en eller flere kolonner fra SAMLEOPPDATERINGEN?
- Hva ER GRUPPERINGSSETT da? Bør jeg vite om dem?
- Hvorfor vil Vi kombinere kolonner i noen aggregering?
- ER DET mer Å GRUPPERE SETT enn en måte å gjøre ‘à la carte’ Kuber?
- hvorfor er funksjonene Gruppering() Og Grouping_ID() gitt?
Eh? HVA ER GRUPPERING SETT, KUBE OG SAMLEOPPDATERING I SQL?
KUBE, SAMLEOPPDATERING og GRUPPERINGSSETT er valgfrie operatorer AV GROUP BY-setningsdelen I SELECT-setningen for å gjøre rapporter med store mengder informasjon. De lar deg gjøre flere GRUPPER etter operasjoner i en setning, noe som potensielt sparer mye tid og beregningsarbeid. De kan gi all den informasjonen som trengs for rapportering, inkludert totaler, samtidig som de gir god ytelse over store tabeller, og hjelper Spørringsoptimereren til å utarbeide en god utførelsesplan.
de ekstra ‘superaggregat’-radene gir sammendragsverdier, slik at du kan ha flere ‘aggregeringer’ som SUM() eller MAX() i det ene resultatet. Nullene i disse radene i resultatet er ment å bety ‘alle’ i stedet for ‘ukjent’. Det lar deg få alle aggregatene du trenger i ett pass gjennom bordet. På grunn av tilstedeværelsen av ekstra rader i resultatene, leveres ekstra funksjoner GROUPING() og GROUPING_ID() for å indikere disse ekstra «superaggregat» – radene, og hvilke kolonner som aggregeres.Dette gir mye mening hvis du har et program som må kjøre flere rapporter uten ekstra beregning eller uten å gå tilbake til databasen: Du har alt du trenger i ett resultat.
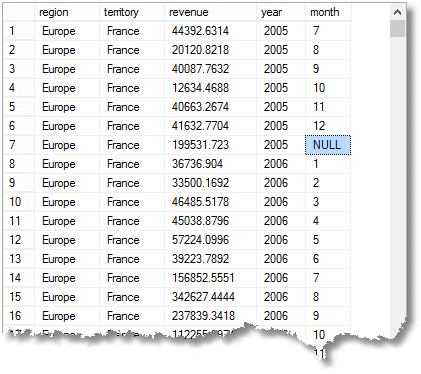
Ta dette standardeksemplet PÅ EN ROLLUP (jeg bruker AdventureWorks 2012 her)..
|
1
2
3
4
5
6
|
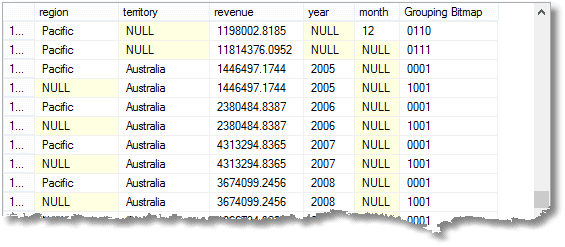
super-aggregerte rader, og også en total total rad. (her er begynnelsen på resultatet)
DET NULL JEG har highlit betyr at raden er et aggregat for ‘alle’ måneder i 2005 I Frankrike (en Del Av Europa-regionen)
I tillegg til alt dette får du totalt forfalt for hvert år, for hvert territorium og territorial gruppe, samt hele summen forfalt. (fra slutten)
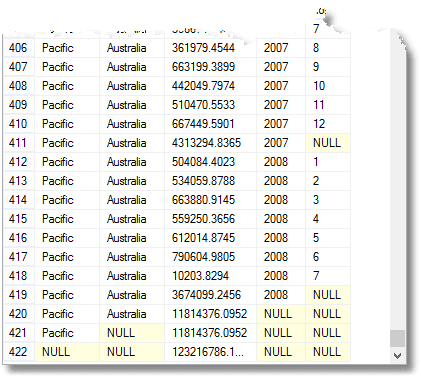
Disse Nullene betyr ‘Alle’, husk. Den siste raden er totalsummen, og over den er summen for stillehavsregionen. Over Det Er Australias bidrag til stillehavsregionen. Den fjerde raden fra bunnen er Australias 2008-bidrag. Antall grupperinger som returneres er en mer enn antall uttrykk i listen sammensatt element gitt TIL GRUPPEN av setningen.
for å få samme effekt uten å bruke samleoppdateringen, må du gjøre noe slikt (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.(mm, OrderDate)) ‘
|
denne nye syntaksen gir deg litt ekstra funksjonalitet. Husk også at kolonnerekkefølgen påvirker utdatagrupperinger AV SAMLEOPPDATERING og kan påvirke antall rader i resultatsettet.
KUBEN gjør det samme generelle, men i stedet for å gi et hierarki av totaler i bestilte superaggregatrader, gir DEN alle’ superaggregat ‘ permutasjoner (‘symmetriske superaggregat’ rader), de såkalte tverrtabuleringsrader. Hvis du ønsket å vite hvilket territorium som ga flest ordrer i mars, eller hvilket territorium som fungerte minst bra i 2006, ville du trenge EN TERNING. Du gir alle mulige summasjoner i resultatet.
GRUPPERINGSSETT lar deg finjustere resultatet for å gi mer spesialisert informasjon utover CUBE. Det kan gi sammendragsinformasjon om kombinasjoner av dimensjoner. Du kan få nøyaktig samme resultat som I SAMLEEKSEMPLET vårt ved Å BRUKE GRUPPERINGSSETT, men med mye mer skriving.
|
1
2
3
4
5
6
7
8
9
10
|
Dette er bare for å vise hvordan de forholder seg. I virkeligheten vil DU ty TIL GRUPPERINGSSETT for å få resultater som er umulige med SAMLEOPPDATERING eller KUBE.
Nesten alle disse oppsummeringene kan oppnås ved Å BRUKE BARE GRUPPE AV, men bare gjennom gjentatte Grupperinger av RESULTATET AV EN GRUPPE AV, eller ved å gjøre mer enn ett pass gjennom dataene.
når DU bruker KUBE -, SAMLEOBJEKT-ELLER GRUPPERINGSSETT, kan du ikke bruke DET DISTINKTE nøkkelordet i de samlede uttrykkene, for EKSEMPEL GJ. SN (DISTINKT kolonnenavn), ANTALL (DISTINKT kolonnenavn) og SUM (DISTINKT kolonnenavn)
Hvorfor SKULLE SAMLEOBJEKT eller KUBE være nyttig for meg?
ROLLUP og CUBE hadde sin storhetstid før SSAS. De var nyttige for å gi samme type fasiliteter som kuben i OLAP. Det har fortsatt sin bruk skjønt. I AdventureWorks er det overkill, men hvis du håndterer store datamengder, må du bare overføre dataene dine en gang, og gjøre så mye som mulig på data som er samlet. Hendelser som har skjedd tidligere kan ikke endres, så det er sjelden nødvendig å beholde historiske data på et aktivt OLTP-system. I stedet trenger du bare å beholde de samlede dataene på detaljnivået (‘granularitet’) som kreves for alle forutsigbare rapporter.Tenk Deg at du er ansvarlig for å rapportere på en telefonbryter som har to millioner eller så samtaler om dagen. Hvis DU beholder alle disse anropene PÅ OLTP-serveren din, vil DU snart finne SQL Server som arbeider over bruksrapporter. Du må beholde den opprinnelige samtaleinformasjonen for en lovbestemt tidsperiode, men du bestemmer fra virksomheten at de er, på det meste, bare interessert i antall samtaler i et minutt. Da har du redusert lagringsbehovet på OLTP-serveren til 1.4% av hva det var, og anropspostene kan arkiveres til en ANNEN SQL Server for ad hoc-spørringer og kundeuttalelser. Det er sannsynligvis en besparelse verdt å gjøre. KUBEN og SAMLEELEMENTER kan du selv lagre rad totaler, kolonnetotaler og totalsummer uten å måtte gjøre en tabell, eller gruppert indeks, skanning av sammendragstabellen.
Så lenge endringer ikke gjøres i ettertid til disse dataene, og alle tidsperioder er fullført, trenger du aldri å gjenta eller endre aggregeringer basert på tidligere tidsperioder, selv om totalsummer må være overskrevet!.
La oss late som, men bruk AdventureWorks2012 slik at du kan spille sammen.
For det Første lager vi gram sammendragstabellen.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
Legg Merke til at vi legger til ekstra ‘bit’ kolonner som forteller oss hvilke rader som inneholder sammendragsradene. Hvis du feilaktig legger dem til ytterligere aggregeringer, får du noen alvorlige oppblåste resultater. Du kan ikke bruke Grouping() eller Grouping_ID på det lagrede resultatet, selvsagt, så du burde gi noe i stedet.
nå kan vi produsere pivottabellen veldig fort
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
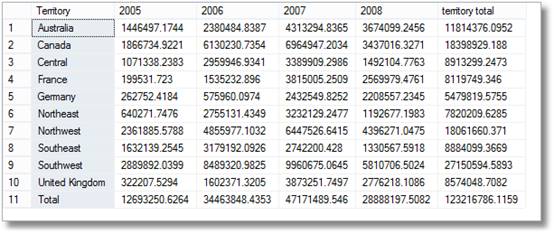
så det er korte smil fra lederne på å se dette, men da sier de klart ‘jeg er sikker på at jeg også ba om en sammenbrudd etter territorium per måned
Med en kort latter, gjør du dette.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
VELG
datanavn(MÅNED,dateadd(MÅNED, ,’01 desember 2000′)) SOM,
sum(TILFELLE territorium NÅR ‘Australia’ så inntekter ANNET 0 SLUTT) SOM,
sum(TILFELLE territorium NÅR ‘Canada’ så inntekter ANNET 0 SLUTT) SOM,
sum(TILFELLE territorium når ‘Sentral sum(sak territorium når’ FRANKRIKE ‘så inntekter annet 0 ende) som,
sum(sak territorium når’ nordøst ‘SÅ INNTEKTER annet 0 ENDE) SOM, sum(sak TERRITORIUM når’ nordøst ‘SÅ INNTEKTER annet 0 ENDE) SOM,
sum(sak TERRITORIUM Sum(SAK territorium NÅR ‘Sørøst’ da inntekter ANNET 0 ENDE) som ,
sum(SAK territorium NÅR ‘Sørøst’ da inntekter ANNET 0 ENDE) SOM ,
sum(SAK territorium når ‘Sørvest’ da inntekter ANNET 0 ENDE) SOM ,
sum(sak territorium når ‘Storbritannia’ da inntekter ANNET 0 ENDE) SOM ,
sum(inntekter) SOM
FRA #AggregationTable
HVOR ISGROUPINGROW =0
gruppe etter måned
union ALLE
velg
‘TOTAL’,
sum(case territorium NÅR ‘australia’ deretter inntekter annet 0 slutt) som ,
sum (case territorium NÅR ‘australia’ så inntekter annet 0 slutt) som,
sum (case territorium når Sum(SAK territorium NÅR ‘Sentral’ da inntekter ANNET 0 ENDE) SOM ,
sum(SAK territorium NÅR ‘Sentral’ da inntekter ANNET 0 ENDE) SOM, sum(SAK territorium NÅR ‘Nordøst’ da inntekter ANNET 0 ENDE) SOM,
sum(SAK territorium NÅR ‘Nordøst’ da inntekter ANNET 0 ENDE) SOM,
sum(SAK territorium NÅR ‘Nordøst’ da inntekter ANNET 0 ENDE) SOM,
sum(SAK territorium når ‘Nordøst’ da inntekter ANNET 0 ENDE) SOM,
0 ENDE) som, sum(tilfelle TERRITORIUM når ‘sørøst’ SÅ INNTEKTER annet 0 ENDE) SOM,
sum (tilfelle TERRITORIUM NÅR ‘sørvest’ SÅ INNTEKTER annet 0 ENDE) SOM,
sum(TILFELLE territorium NÅR ‘Storbritannia’ deretter inntekter ANNET 0 SLUTT) som ,
sum(inntekter) SOM
FRA #AggregationTable
HVOR isGroupingrow =0
|
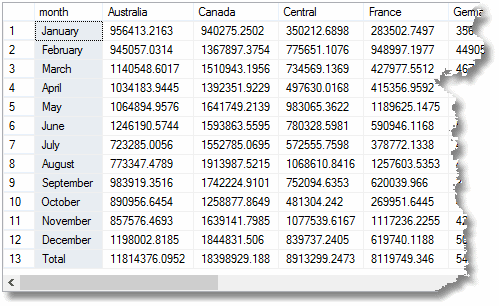
Men hvis DU hadde brukt KUBE i stedet For Samleoppdatering, ville den siste totale raden allerede bli beregnet. I et reelt eksempel som ville koste tid å gjøre rapporten. Du kan gjøre EN KUBE på opptil ti dimensjoner; selv om de pleier å bulk opp aggregering, de er ikke for kostbart.
Er disse standard SQL eller Er De En Microsoft-eneste ting?
Disse er nå standard ANSI SQL fra 1999, men MED CUBE og MED SAMLEOPPDATERING ble Først introdusert Av Microsoft. Denne inkluderingen er noe overraskende ved at de introduserer en annen betydning, ‘alle’, FOR NULLVERDIEN i tillegg til ‘ukjent’. Da Microsoft først introduserte KUBE og SAMLEOPPDATERING, var syntaksen litt annerledes, men begge skjemaene er tillatt I SQL Server. Bare en syntaksstil kan brukes i en ENKELT SELECT-setning, og DU bør bruke ISO-kompatibel syntaks for alt nytt arbeid.
kan jeg ekskludere en eller flere kolonner fra SAMLEOPPDATERINGEN?
hvis du vil! Tenk deg at jeg ikke ville ha en super-samlet total for alle regionene (t.)
|
1
2
3
4
5
6
|
her bruker vi ANSI SQL 2006-kompatibel syntaks. Du kan gjøre det samme med en terning. Jeg har aldri funnet en praktisk bruk for dette, men du kan komme over det
Hva ER GRUPPERINGSSETT da? Bør jeg vite om dem?
GRUPPERINGSSETT betyr at DU ber SQL om å gruppere resultatet flere ganger. Du kan bruke GRUPPERINGSSETT-syntaksen til å angi nøyaktig hvilke aggregeringer som skal beregnes. Her er et eksempel.
|
1
2
3
4
5
6
|
her ber du om oppdeling etter territoriumgruppe for hver måned i hvert år med måneds-og årstotaler, etterfulgt av et sammendrag totalt etter territorium navn, men uten totalsum. I motsetning TIL SAMLEOPPDATERINGEN får du det samme resultatet uansett rekkefølgen på kolonnene i HVERT GRUPPERINGSSETT og rekkefølgen PÅ GRUPPERINGSSETTENE.
GRUPPERINGSSETT kan gi deg nøyaktig HVA KUBE og ROLLUP gir deg og mye mer dessuten. Som du kan se med dette siste eksemplet, kan du bruke STANDARD’ table d’ô ‘ KUBE og SAMLEOPPDATERING blandet sammen med DIREKTE uttrykte ‘à la carte ‘GRUPPERINGSSETT.
Hvorfor vil Vi kombinere kolonner i noen aggregering?
der to kolonner skal kombineres i enkelte rapporter, er det nyttig å erklære en aggregering som kombinerer to kolonner. I det første eksemplet kombinerer vi år og måned for samleoppdateringen, med effekten av å begrense totalene til bare hvert område,
|
1
2
3
4
5
6
7
|
den ekstra braketten i samleobjektet har hatt effekten av å begrense aggregeringene til bare området og måneden / året. La dem ut, og du får totaler for hvert år.
|
1
2
3
4
5
6
7
8
9
10
|
Dette kan være svært nyttig for visse data. Vi har unngått å måtte kombinere kolonner her. Hvis du skulle gjøre EN KUBE, og vilkårene for territorier brukte ordene Som ‘Nord’ eller ‘Sør’ for å beskrive et territorium i mer enn en region, ville du ha noen bisarre aggregasjoner som gjelder for ‘nordlige’ territorier som ikke er relatert. Ved å kombinere kolonner, ville du unngå dette.
ER DET mer Å GRUPPERE SETT enn en måte å gjøre ‘à la carte’ Kuber?
jeg er ikke sikker på at jeg ville være sjenert om å stille dette spørsmålet. SQL:1999S GRUPPESETT gir en rik rekursiv syntaks som lar deg samle kombinasjoner av kolonner og definere alle slags esoteriske rapporter som gir opptil ti dimensjoner. Aggregeringene kan nestes, og Du kan neste Kuber i Samleobjekter og nest Samleobjekter i Kuber. Du må lese en spesialistpublikasjon for å finne ut mer om dette.
hvorfor er funksjonene Gruppering() Og Grouping_ID() gitt?
DET er egentlig ikke en god ide å bruke NULL for å betegne at en kolonne er en aggregering. Problemet er at hvis en grupperingskolonne inneholder nullverdier, anses alle nullverdier som like, og settes inn i en ENKELT NULLGRUPPE som maskerer som et sammendrag. For å omgå den åpenbare vanskeligheten MED NULLVERDIER i de opprinnelige dataene, er to funksjoner gitt: Gruppering () og Grouping_ID().
Grouping() – funksjonen er bestått navnet på en kolonne som deltok I SAMLEOPPDATERINGEN, KUBEN ELLER GRUPPERINGSSETTET. Den returnerer null hvis denne raden er et sammendrag for denne kolonnen MED EN NULLVERDI som betyr ‘alle’ eller om den inneholder en verdi.
GRUPPE_ID-funksjonen sendes en liste som må samsvare nøyaktig med uttrykket I GRUPPE etter-listen. GROUPING_ID er opprettet som en bitmap av de respektive sammendragskolonnene. Hvis for EKSEMPEL områdekolonnen HAR EN NULL som betyr’ alle ‘ territorier i stedet for et navn på et område, og det er oppført som den andre kolonnen, er den andre biten fra venstre angitt. Dette heltallet returneres deretter.
Grouping_ID() brukes vanligvis til å indikere om raden er en primær eller sekundær aggregering (0 eller > 0) og, hvis sekundær, deretter ekskludert FRA ytterligere GRUPPE ved manipulering.
det anses vanligvis som god praksis å inkludere en bitkolonne for hver dimensjon (for eksempel «Territorium» eller «Region» i vårt eksempel) som er angitt hvis raden er et sammendrag for den dimensjonen, sammen med enGrouping_ID() – verdi for å hjelpe til med videre gruppering av resultatet.
for å illustrere Hvordan Grouping_ID faktisk fungerer, får vi se på hvordan bitene I Grouping_ID er satt i henhold til typen sammendrag. Vi bruker Phil Factors funksjon ToBinaryString for å vise biter.
|
1
2
3
4
5
6
7
8
9
|
dette gir (bare et eksempel selvfølgelig)…