datamodellering er prosessen med å dokumentere en kompleks programvaresystemdesign som et lettforståelig diagram, ved hjelp av tekst og symboler for å representere måten dataene må flyte på. Diagrammet kan brukes til å sikre effektiv bruk av data, som en blåkopi for bygging av ny programvare eller for ombygging av en eldre applikasjon.
datamodellering er en viktig ferdighet for dataforskere eller andre som er involvert i dataanalyse. Tradisjonelt har datamodeller blitt bygget under analyse – og designfasen av et prosjekt for å sikre at kravene til en ny søknad er fullt ut forstått. Datamodeller kan også påberopes senere i datasyklusen for å rasjonalisere datadesign som opprinnelig ble opprettet av programmerere på ad hoc-basis.
datamodellering tilnærminger
datamodellering kan være en møysommelig forhånd prosess og, som sådan, er noen ganger sett på som å være på kant med raske utviklingsmetoder. Som Agile programmering har kommet i bredere bruk for å få fart på utviklingsprosjekter, er etter-det-faktum metoder for datamodellering blir tilpasset i noen tilfeller. En datamodell kan vanligvis betraktes som et flytskjema som illustrerer forholdet mellom data. Det gjør det mulig for interessenter å identifisere feil og gjøre endringer før noen programmeringskode er skrevet. Alternativt kan modeller innføres som en del av reverse engineering innsats som trekker ut modeller fra eksisterende systemer, som sett Med NoSQL data.
datamodellører bruker ofte flere modeller for å vise de samme dataene og sikre at alle prosesser, enheter, relasjoner og datastrømmer er identifisert. De initierer nye prosjekter ved å samle krav fra forretningsinteressenter. Datamodellering stadier grovt bryte ned i etableringen av logiske datamodeller som viser bestemte attributter, enheter og relasjoner mellom enheter og den fysiske datamodellen.den logiske datamodellen tjener som grunnlag for opprettelse av en fysisk datamodell, som er spesifikk for applikasjonen og databasen som skal implementeres. En datamodell kan bli grunnlaget for å bygge et mer detaljert dataskjema.
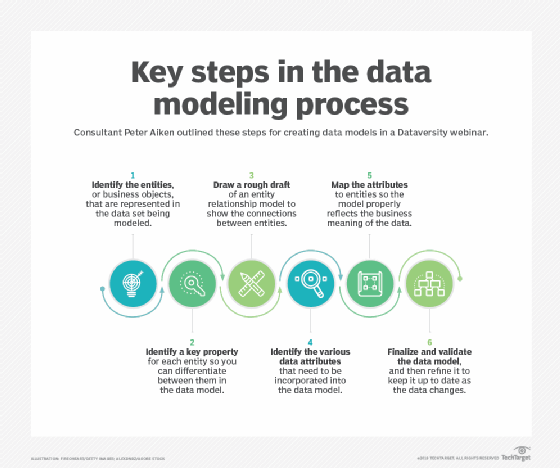
Hierarkisk datamodellering
datamodellering som en disiplin begynte å oppstå på 1960-tallet, som følge av oppgangen i bruk databasehåndteringssystemer (dbms). Datamodellering gjorde det mulig for organisasjoner å bringe konsistens, repeterbarhet og velordnet utvikling til databehandling. Applikasjons sluttbrukere og programmerere kunne bruke datamodellen som referanse i kommunikasjon med datadesignere.Hierarkiske datamodeller som matriser data i treelike, en-til-mange-ordninger markerte disse tidlige anstrengelsene og erstattet filbaserte systemer i mange populære brukstilfeller. IBMS Information Management System (IMS) er et primært eksempel på den hierarkiske tilnærmingen, som fant bred bruk i bedrifter, spesielt innen bank. Selv om hierarkiske datamodeller i stor grad ble erstattet-begynnelsen på 1980-tallet-av relasjonsdatamodeller, er den hierarkiske metoden vanlig fortsatt I XML (Extensible Markup Language) og geografiske informasjonssystemer (GISes) i dag. Nettverksdatamodeller oppsto også i DBMSes tidlige dager som et middel til å gi datadesignere et bredt konseptuelt syn på sine systemer. ET slikt eksempel er Conference on Data Systems Languages (CODASYL), som ble dannet på slutten av 1950-tallet for å veilede utviklingen av et standard programmeringsspråk som kunne brukes på tvers av ulike typer datamaskiner.
Relasjonsdatamodellering
Mens det reduserte programkompleksitet versus filbaserte systemer, krevde den hierarkiske modellen fortsatt detaljert forståelse av den spesifikke fysiske datalagringen som ble brukt. Foreslått som et alternativ til den hierarkiske datamodellen, krever ikke relasjonsdatamodellen at utviklere definerer databaner. Relasjonsdatamodellering ble først beskrevet i EN teknisk artikkel fra 1970 av IBM-forsker E. F. Codd. Codds relasjonsmodell satte scenen for industriens bruk av relasjonsdatabaser der datasegmenter eksplisitt sammenføyes ved bruk av tabeller, sammenlignet med den hierarkiske modellen der data implisitt sammenføyes. Kort tid etter oppstarten ble relasjonsdatamodellen kombinert Med Structured Query Language (SQL) og begynte å få et stadig større fotfeste i enterprise computing som et effektivt middel til å behandle data.
entity relationship model
relasjonsdatamodellering tok et nytt skritt fremover fra midten av 1970-tallet da bruk av entity relationship (ER) modeller ble mer utbredt. ER-modeller er tett integrert med relasjonsdatamodeller, og bruker diagrammer for å skildre elementene i en database grafisk og for å lette forståelsen av underliggende modeller.
med relasjonsmodellering bestemmes datatyper og endres sjelden over tid. Enheter omfatter attributter; for eksempel kan en ansatt enhetens attributter inkludere etternavn, fornavn, år ansatt og så videre. Relasjoner er visuelt kartlagt, og gir en klar måte å kommunisere data design mål til ulike deltakere i data utvikling og vedlikehold. Over tid har modelleringsverktøy, inkludert ideras Er/Studio, ERWIN Data Modeler og SAP PowerDesigner, fått bred bruk blant dataarkitekter for å designe systemer.
som objektorientert programmering fikk grunnlag på 1990-tallet, fikk objektorientert modellering trekkraft som enda en måte å designe systemer på. Mens bærer noen likhet MED ER metoder, objektorienterte tilnærminger varierer i at de fokuserer på objekt abstraksjoner av virkelige enheter. Objekter grupperes i klassehierarkier, og objektene i slike klassehierarkier kan arve attributter og metoder fra overordnede klasser. På grunn av denne arvegenskapen har objektorienterte datamodeller noen fordeler i forhold til ER-modellering, når det gjelder å sikre dataintegritet og støtte mer komplekse datarelasjoner. Også på 1990-tallet var datamodeller spesielt orientert mot datavarehusbehov. Kjente eksempler er snowflake schema og star schema dimensjonale modeller.
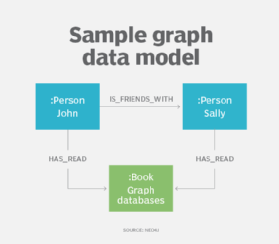
Grafdatamodeller
en avlegger av hierarkisk og nettverksdatamodellering er egenskapsgrafmodellen, som sammen med grafdatabaser har funnet økt bruk for å beskrive komplekse relasjoner innen datasett, spesielt i sosiale medier, anbefalings-og svindeloppdagingsprogrammer.ved hjelp av grafdatamodellen beskriver designere deres system som en tilkoblet graf av noder og relasjoner, mye som de kan gjøre med ER eller objektdatamodellering. Grafdatamodeller kan brukes til tekstanalyse, og skaper modeller som avdekker relasjoner mellom datapunkter i dokumenter.