- え? SQLでSET、CUBE、ROLLUPをグループ化するとは何ですか?なぜROLLUPやCUBEが私にとって役に立つのでしょうか?
- これらの標準SQLはありますか、それともMicrosoft専用のものですか?
- ロールアップから1つ以上の列を除外できますか?
- グループ化セットとは何ですか? 私はそれらについて知っておくべきですか?
- なぜ集計で列を結合したいのですか?
- グループ化セットには、”アラカルト”キューブを行う方法よりも多くのものがありますか?
- 関数Grouping()とGrouping_Id()が提供されているのはなぜですか?
- え? SQLでSET、CUBE、ROLLUPをグループ化するとは何ですか?
- ROLLUPまたはCUBEは私に役立ロールアップとキューブは、SSASの前に全盛期を持っていました。
- グループ化セットは何ですか? 私はそれらについて知っておくべきですか?グループ化セットは、結果を数回グループ化するようにSQLに要求していることを意味します。 GROUPING SETS構文を使用すると、計算する集計を正確に指定できます。 ここに例があります。 1 2 3 4 5 となっています。div>6 を選択。 として地域。名として領域内にて、和(TotalDue)として収益、 datepart(yyyy,OrderDate)としては、datepart(mm、OrderDateとして からの販売です。SalesOrderHeader s 内部結合売上高。Sの販売代理店T.TerritoryID=T.TerritoryID Tによるグループ化。,グループ化セット(ROLLUP(t.nameここでは、毎月のテリトリーグループ別の内訳を求めています月と年の合計、その後にテリトリー名による要約合計が続きますが、総計はありません。 ロールアップとは異なり、各グループ化セット内の列の順序とグループ化セットの順序にかかわらず、同じ結果が得られます。 グループ化セットは、CUBEとROLLUPがあなたに与えるものを正確に与えることができます。 この最後の例でわかるように、標準の’table d’hôte’CUBEとROLLUPを直接表現した’à la carte’グループ化セットと一緒に混合して使用することができます。 なぜ集計で列を結合したいのですか?
- グループ化セットには、”アラカルト”キューブを行う方法よりも多くのものがありますか?私はこの質問をすることについて恥ずかしがり屋であるかどうかはわかりません。
え? SQLでSET、CUBE、ROLLUPをグループ化するとは何ですか?
CUBE、ROLLUP、およびGROUPING SETは、大量の情報を含むレポートを実行するためのSELECTステートメントのGROUP BY句のオプションの演算子です。 これにより、1つの文で複数のGROUP BY操作を実行できるため、多くの時間と計算労力を節約できます。 合計を含むレポートに必要なすべての情報を提供しながら、大きなテーブルに対して優れたパフォーマンスを提供し、クエリオプティマイザが適切な実行余分な’super-aggregate’行は要約値を提供するため、1つの結果の中にSUM()やMAX()などのいくつかの’集計’を含めることができます。 結果のこれらの行内のNullは、’unknown’ではなく’all’を意味することを意図しています。 これにより、テーブルを1回のパスで必要なすべての集計を取得できます。 結果に余分な行が存在するため、余分な関数GROUPING()GROUPING_ID()は、これらの余分な”スーパー集計”行と集計されている列を示すために提供され
余分な計算をせずに、またはデータベースに戻らずに複数のレポートを実行する必要があるアプリケーションがある場合、これは非常に意味があります。この標準的なロールアップの例を取ります(ここではAdventureWorks2012を使用しています)。.
|
1
2
3
4
5
となっています。div>6 |
を選択。 として地域。名として領域内にて、和(TotalDue)として収益、
datepart(yyyy,OrderDate)としては、datepart(mm、OrderDateとして
からの販売です。SalesOrderHeader s
内部結合売上高。SalesTerritory T ON S.TerritoryID=T.TerritoryID
Tによるグループ化。,t.name,datepart(yyyy,OrderDate),datepart(mm,OrderDate)
WITH ROLLUP
|
単純なグループ化で得られる毎月の合計期日を持つ単純なGROUP BY aggregate行と同様に、小計または超集約行、およ (ここでは結果の始まりです)

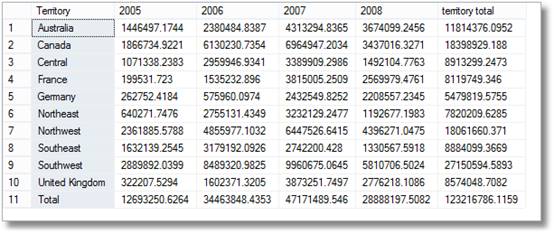
私が強調したNULLは、行がフランス(ヨーロッパ地域の一部)の2005年の”すべての”月の集計であることを意味します
これだけでなく、各年の合計、各テリ (最後から)

これらのNullは’すべて’を意味します。 最後の行は総計であり、その上には太平洋地域の合計があります。 その上には、太平洋地域へのオーストラリアの貢献があります。 下から4番目の列はオーストラリアの2008年の貢献です。 返されるグループ化の数は、GROUP BY文に指定された複合要素リスト内の式の数よりも1つ多くなります。 ロールアップを使用せずに同じ効果を得るには、次のようなことを行う必要があります(Adventureworks2012)
|
|
|
|
|
|
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
19
19
19
19
19
19
19
19
19
19
19
19>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ;
|
とmyGrouping(region,territory,totalDue,,)
として(tを選択します。,t.name、合計(TotalDue)収益として、
datepart(yyyy、OrderDate)として、Datepart(mm、OrderDate)として
売上高から。SalesOrderHeader s
内部結合売上高。SalesTerritory T ON s.TerritoryID=T.TerritoryID
グループ化t.name,t.、datepart(yyyy,OrderDate)、datepart(mm,OrderDate))
地域、領土、合計(totalDue)を選択します,,
MYGROUPINGから
すべての連合
地域、領土、合計(totalDue)を選択します,,NULL
myGroupingから地域、領土、合計(totalDue)を選択します,,NULL
地域、領土、合計(totalDue)を選択します
すべての連合
地域、領土、合計(totalDue)を選択します
null、null
からMygrouping地域別グループ、テリトリー
union ALL
select region,null,sum(totaldue),null,null
from mygrouping地域別グループ
union all
nullを選択します, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.
|
この新しい構文を使用すると、いくつかの追加機能が可能になります。 列の順序はROLLUPの出力グループに影響し、結果セット内の行数に影響する可能性があることにも注意してください。
キューブは同じ一般的なことを行いますが、順序付けられた超集約行に合計の階層を提供する代わりに、すべての’超集約’順列(’対称超集約’行)、いわゆる あなたは月に最も注文を与えた領土、または2006年に最もうまく機能しなかった領土を知りたい場合は、キューブが必要になります。 あなたは結果にすべての可能な合計を提供しています。
GROUPING SETを使用すると、結果を微調整して、CUBEを超えてより専門的な情報を提供することができます。 これは、寸法の組み合わせに関する要約情報を提供することができます。 グループ化セットを使用することで、ロールアップの例とまったく同じ結果を得ることができますが、より多くの入力を行うことができます。
|
1
2
3
4
5
となっています。div>6 7
8
9
10
|
を選択。 として地域。名として領域内にて、和(TotalDue)として収益、
datepart(yyyy,OrderDate)としては、datepart(mm、OrderDateとして
からの販売です。SalesOrderHeader s
内部結合売上高。S.TerritoryID=TのSalesTerritory T。TerritoryID
グループ化セットによるグループ化(
(T.,T.nameこれを行うには、次の手順を実行します。T.nameこれを行うには、次の手順を実行します。T.nameこれは、それらがどのように関連しているかを示すためだけです。 実際には、ROLLUPまたはCUBEでは不可能な結果を得るためにセットをグループ化することに頼っています。
ほとんどすべてのこれらの要約は、GROUP BYだけを使用することから得ることができますが、GROUP BYの結果を繰り返しグループ化するか、データを複数回通過させることによってのみ得ることができます。CUBE、ROLLUP、またはGROUPING SETSを使用している場合、AVG(DISTINCT column_name)、COUNT(DISTINCT column_name)、SUM(DISTINCT column_name)などの集計式でDISTINCTキーワードを使用することはできません。 ROLLUPまたはCUBEは私に役立ロールアップとキューブは、SSASの前に全盛期を持っていました。それらはOLAPの立方体によって提供される同じ種類の設備を提供するために有用だった。 それはまだその用途を持っています。 AdventureWorksでは、やりすぎですが、大量のデータを処理する場合は、データを一度だけ渡し、集計されたデータに対して可能な限り処理する必要があります。 過去に発生したイベントは変更できないため、アクティブなOLTPシステムに履歴データを保持する必要はほとんどありません。 代わりに、すべての予測可能なレポートに必要な詳細レベル(”粒度”)で集計データを保持する必要があります。 あなたが一日に二百万かそこらの呼び出しを持っている電話スイッチに報告する責任があると想像してみてください。 OLTPサーバーでこれらの呼び出しをすべて保持すると、すぐに使用状況レポートを処理するSQL Serverが見つかります。 あなたは法定期間のために元のコール情報を保持する必要がありますが、あなたは彼らが、せいぜい、分でのコールの数にのみ興味を持っていることをビ 次に、OLTPサーバーのストレージ要件を1に減らしました。それが何であったかの4%、およびコールレコードは、アドホッククエリと顧客ステートメントのために別のSQL Serverにアーカイブすることができます。 それは価値のある節約になる可能性があります。 CUBE句とROLLUP句を使用すると、集計テーブルのテーブルまたはクラスター化インデックスのスキャンを実行せずに、行の合計、列の合計、および総計を格納する このデータに遡及的に変更が加えられず、すべての期間が完了している限り、過去の期間に基づいて集計を繰り返したり変更したりする必要はあ. ふりをしましょうが、Adventureworks2012を使用して遊ぶことができます。 まず、gram summaryテーブルを作成します。
要約行を含む行を示す余分な”ビット”列を追加していることに注意してください。 あなたが誤ってそれ以上の集計にそれらを追加すると、いくつかの真剣に膨張した結果が得られます。 保存された結果に
あなたがしたい場合は! 私はすべての地域のための超集約合計を望んでいなかったことを想像してみてください(t。)
|
 2303-CLIP_IMAGE004.jpg
2303-CLIP_IMAGE004.jpg

