CPUは、マイクロプロセッサとも呼ばれ、コンピュータの心臓および/または脳です。 コンピュータのコアに深く潜り、私たちは効率的にコンピュータプログラムを書くのに役立ちますどのようにCPUの仕事を理解することができます。
ツールは、通常、機械よりもシンプルです。
-Charles Babbage
コンピュータは主に電気で駆動される機械ですが、その柔軟性とプログラミング性は、ツールのシンプルさを達成す
CPUは、コンピュータの心臓および/または脳です。 それは彼らに提供された命令を実行します。 その主な仕事は、算術演算と論理演算を実行し、命令を一緒に編成することです。 主要な部分に飛び込む前に、CPUの主要なコンポーネントとその役割を見てみましょう:
CPU(プロセッサ)の二つの主要なコンポーネント
- 制御ユニット—CU
- 算術および論理ユニット—ALU
制御ユニット—CU
制御ユニットCUは、命令 それは何をすべきかを伝えます。 指示に従って、それはALUを含むコンピュータの異なった他の部分にCPUを接続するワイヤーを活動化させるのを助けます。 制御ユニットは、処理のための命令を受信するためのCPUの最初の構成要素である。
制御ユニットには二つのタイプがあります。
- ハードワイヤード制御ユニット。
- マイクロプログラマブル(マイクロプログラム)制御ユニット。
ハードワイヤード制御ユニットは、ハードウェアであり、マイクロプログラマブル制御ユニットは、その動作を変更するようにプログラムすることがで 配線されたCUは処理命令が高速であるのに対し,マイクロプログラマブルはより柔軟である。
算術および論理ユニット—ALU
算術および論理ユニットALUは、名前が示すように、すべての算術および論理計算を行います。 ALUは加算、減算などの操作を実行します。 ALUは、これらの動作を実行する論理回路または論理ゲートで構成されています。
ほとんどの論理ゲートは、二つの入力を取り、一つの出力を生成します
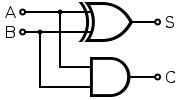
以下は、二つの入力を取り、結果を出力する半加算器回路の例です。 ここで、AとBは入力、Sは出力、Cはキャリーです。
ストレージ—レジスタとメモリ
CPUの主な仕事は、それに提供された命令を実行することです。 ほとんどの場合、これらの命令を処理するには、データが必要です。 いくつかのデータは中間データであり、そのうちのいくつかは入力であり、他は出力である。 これらのデータは、命令とともに次のストレージに格納されます。
Registers
レジスタは、データを格納できる小さな場所のセットです。 レジスタはラッチの組み合わせです。 フリップフロップとも呼ばれるラッチは、1ビットの情報を格納する論理ゲートの組み合わせです。
ラッチには、書き込みと入力の2つの入力ワイヤと1つの出力ワイヤがあります。 書き込みワイヤが保存されたデータを変更できるようにすることができます。 書き込みワイヤがディスエーブルされている場合、出力は常に同じままです。
CPUは、出力のデータを格納するためのレジスタを持っています。 メインメモリ(RAM)への送信は、中間データであるため遅くなります。 このデータは、バスで接続されている他のレジスタに送信されます。 レジスタには、命令、出力データ、ストレージアドレス、または任意の種類のデータを格納できます。Ramは、より多くのデータを格納できるように、最適化された方法で一緒に配置され、コンパクトなレジスタのコレクションです。
メモリ(RAM)
Ramは、より多くのデータを格納できるように、最適化された方法で一緒に配置され、コンパクトなレジスタのコレクションです。 RAM(ランダムアクセスメモリ)は揮発性であり、電源を切るとデータが失われます。 RAMはデータを読み書きするためのレジスタの集合であるため、RAMは8ビットアドレスの入力を取り、実際のデータを格納するためのデータ入力を行い、最終的にはラッチ用のものと同じように動作するイネーブラを読み書きする。
命令とは何ですか
命令は、コンピュータが実行できる粒状レベルの計算です。 CPUが処理できる命令にはさまざまな種類があります。
命令には次のものが含まれます:
- 加算と減算などの算術
- and、or、notなどの論理命令
- Move、input、output、load、storeなどのデータ命令
- goto、if…goto、call and returnなどの制御フロー命令
- プログラムが停止したことをCPUに通知
命令は、アセンブリ言語を使用してコンピュータに提供されるか、コンパイラによって生成されるか、またはいくつかの高レベルで解釈される。言語。
これらの命令はCPU内部で配線されています。 ALUは算術および論理を含み、一方、制御フローはCUによって管理される。
一つのクロックサイクルでは、コンピュータは一つの命令を実行できますが、現代のコンピュータは複数の命令を実行できます。
コンピュータが実行できる命令のグループは、命令セットと呼ばれます。
CPUクロック
クロックサイクル
コンピュータの速度は、そのクロックサイクルによって決定されます。 これは、コンピュータが動作する秒あたりのクロック周期の数です。 単一のクロックサイクルは、周りのように非常に小さいです250 * 10 *-12 秒。クロックサイクルが高いほど、プロセッサは速くなります。
CPUクロックサイクルはGHz(ギガヘルツ)単位で測定されます。 1ghzは10½Hz(ヘルツ)に等しいです。 ヘルツは秒を意味します。 つまり、1ギガヘルツは毎秒10½サイクルを意味します。
クロックサイクルが速いほど、CPUが実行できる命令が多くなります。 Clock cycle=1/clock rate CPU Time=clock cycle/clock rateの数
これは、CPU時間を改善するために、CPUに提供する命令を最適化することによって、クロックレートを増加させたり、クロックサイク いくつかのプロセッサは、クロックサイクルを増加させる機能を提供しますが、それは物理的な変化であるため、過熱し、さらには煙/火災がある可
命令はどのように実行されますか
命令は連続した順序でRAMに格納されます。 仮想的なCPUの場合、命令はOPコード(操作コード)とメモリまたはレジスタアドレスで構成されます。
内部には、命令のOPコードをロードする制御ユニット命令レジスタ(IR)と、現在実行中の命令のアドレスをロードする命令アドレスレジスタがあります。 命令の最後の4ビットのアドレスに格納された値を格納するCPU内の他のレジスタがあります。
二つの数字を追加する命令のセットの例を見てみましょう。 以下は、その説明と一緒に指示されています。 CPUは次の命令を実行して動作します。
ステップ1—LOAD_A8:
命令は、最初に<>と言うようにRAMに保存されます。 最初の4ビットはオペコードです。 これにより命令が決定されます。 この命令は、制御ユニットのIRにフェッチされます。 命令はload_aにデコードされ、aを登録する命令の最後の4ビットであるアドレス1000にデータをロードする必要があることを意味します。
ステップ2—LOAD_B2
上記と同様に、メモリアドレス2(0010)のデータをCPUレジスタBにロードします。
ステップ3—ADD B A
次の命令は、これら二つの数値を追加することです。 ここで、CUはALUにadd操作を実行し、結果をレジスタAに保存するように指示します。ステップ4—STORE_A23
これは、二つの数字を追加するのに役立ちます命令の非常に単純なセットです。
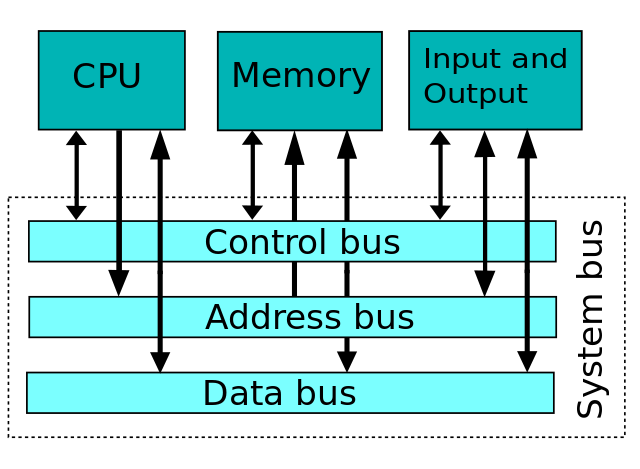
二つの数字を正常に追加しました!CPU、レジスタ、メモリ、IOデバイス間のすべてのデータは、バスを介して転送されます。 追加したばかりのメモリにデータをロードするために、CPUはメモリアドレスをアドレスバスに、合計の結果をデータバスに配置し、制御バス内の適切な信号 このようにして、データはバスの助けを借りてメモリにロードされます。P>
キャッシュ
CPUには、キャッシュされた命令にプリフェッチするメカニズムもあります。 私たちが知っているように、プロセッサが秒以内に完了できる数百万の命令があります。 これは、命令を実行するよりもRAMから命令を取得するのに費やされる時間が長くなることを意味します。 そのため、CPUキャッシュは命令の一部とデータをプリフェッチし、実行が高速になるようにします。
キャッシュ内のデータと動作メモリが異なる場合、データはダーティビットとしてマークされます。
命令パイプライン
現代のCPUは、命令実行の並列化のために命令パイプラインを使用しています。 フェッチ、デコード、実行。 ある命令がデコードフェーズにあるとき、CPUはフェッチフェーズの別の命令を処理することができます。P>
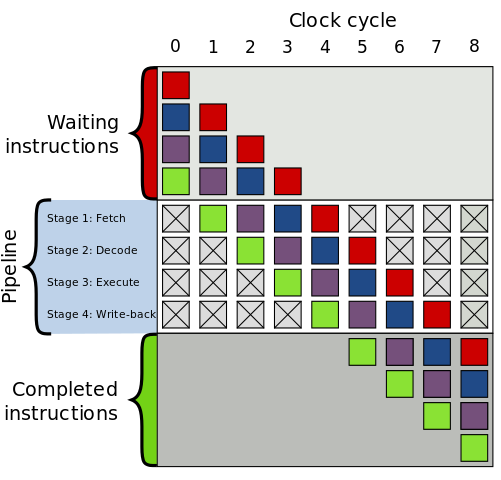
ある命令が別の命令に依存しているとき、これは一つの問題があります。 したがって、プロセッサは依存しない命令を別の順序で実行します。
マルチコアコンピュータ
それは基本的に異なるCPUですが、キャッシュのようないくつかの共有リソースを持っています。
パフォーマンス
CPUのパフォーマンスは、実行時間によって決まります。 Performance=1/execution time
プログラムが実行されるのに20msかかるとしましょう。 CPUの性能は1/20=0です。05msrelative performance=実行時間1/実行時間2
CPU性能について考慮される要因は、命令実行時間とCPUクロック速度です。 したがって、プログラムのパフォーマンスを向上させるには、クロック速度を上げるか、プログラム内の命令数を減らす必要があります。 プロセッサの速度は限られており、マルチコアを搭載した現代のコンピュータは、毎秒数百万の命令をサポートすることができます。 しかし、私たちが書いたプログラムに多くの指示がある場合、これは全体的なパフォーマンスを低下させます。
ビッグO記法は、パフォーマンスがどのように影響するかについて、指定された入力で決定します。
CPUには、できるだけ高速にして実行するための最適化がたくさんあります。 任意のプログラムを書いている間、我々はCPUに提供する命令の数を減らすことは、コンピュータプログラムのパフォーマンスを向上させる方法を検討す
データベースの最適化に興味がありますか? ここでそれについて学ぶ:https://milapneupane.com.np/2019/07/06/how-to-work-optimally-with-relational-databases/