Nella mitologia greca, il Titano Prometeo era incatenato a una roccia. Ogni giorno, un’aquila volava giù e mangiava parte del suo fegato. L’organo si è rigenerato durante la notte, reintegrando la fonte di cibo. Il fegato è uno dei pochi organi del corpo umano che può rigenerarsi spontaneamente. Ancora più impressionante, è il fatto che mentre il fegato si rigenera e si fissa, è ancora funzionale. Gli antichi greci sapevano di questa capacità e lo incorporarono nella loro mitologia quasi 3000 anni fa.
Funzionalità continua
Quando progettiamo reti, vogliamo che siano funzionali, anche quando c’è un’interruzione del sistema. Guasti hardware, tagli di fibre, glitch software e persino scoiattoli che masticano i cavi si verificano. Siamo preoccupati per come la consegna delle applicazioni e l’infrastruttura di rete risponde a questi problemi. Progettiamo tecnologie nella nostra infrastruttura IT per ridurre al minimo l’impatto del danno.

Come i nostri fegati, la rete deve funzionare anche quando guarisce i danni causati ad essa. Le applicazioni devono essere consegnate e le aziende hanno ancora del lavoro da fare. All’inizio, abbiamo sviluppato protocolli di rete dinamici come spanning tree Protocol (STP) per topologie di livello 2 e routing Information protocol (RIP) per topologie di livello 3. Nel corso del tempo abbiamo avanzato questi protocolli per includere layer 2-based rapid spanning tree protocol (RSTP) e layer 3 protocolli di routing tra cui OSPF, ISIS, e BGP.
Passando allo stack O
Abbiamo ancora bisogno di fornire meccanismi per la disponibilità delle applicazioni e la consegna delle applicazioni attraverso l’infrastruttura di rete. È qui che abbiamo introdotto il bilanciamento del carico del server (SLB) e la manipolazione del DNS dinamico attraverso il bilanciamento del carico del server globale (GSLB). Forniscono i meccanismi per rilevare gli errori del server delle applicazioni e completare gli errori del datacenter.
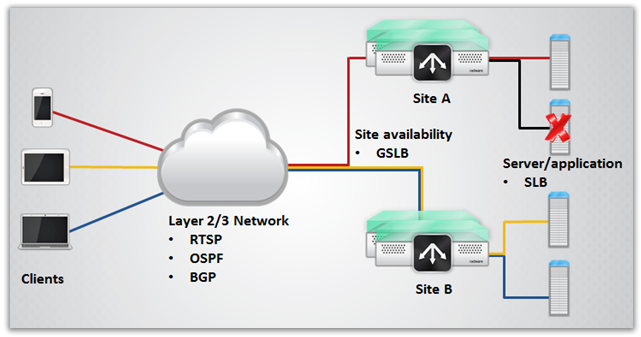
La mia rete ideale (Tipo)
Se dovessi progettare una rete oggi, ad un livello elevato, assomiglierebbe molto al diagramma sopra. La ridondanza è integrata in ogni aspetto dell’architettura. Esistono più server, siti geograficamente diversi e più percorsi di rete per i diversi componenti. Non c’è un singolo punto di fallimento. Se un aspetto fallisce, le tecnologie dinamiche si riconvertiranno automaticamente per determinare un nuovo percorso migliore tra client e application server.
Ci sono molti dettagli fini che non sto coprendo in questo articolo. La progettazione effettiva della rete layer 2/3 e della connettività dei dispositivi dipende dal fatto che i diversi requisiti di distribuzione delle applicazioni siano soddisfatti per garantire l’Application Service Level Assurance (SLA) per tutte le applicazioni. Poiché non sappiamo quali siano le domande, non possiamo fare questa determinazione. L’altra ragione è che avrei bisogno di scrivere un libro per discutere tutti gli aspetti necessari per costruire questa rete.
I punti chiave da ricordare quando si progetta il proprio auto-guarigione, rigenerante infrastruttura IT sono:
- Creare ridondanza nell’architettura
- Sfruttare tecnologie dinamiche che si adattano automaticamente alle condizioni mutevoli
- Ricordate che il critico obiettivo finale è quello di garantire l’applicazione di SLA
Avanti, prenderemo questa rete e interruzione di vari componenti per vedere come influenzano la consegna della domanda e ciò che l’utente finale percepisce.

Leggi ” Mantienilo semplice; Rendilo scalabile: 6 Caratteristiche del bilanciatore di carico Futureproof ” per saperne di più.
Scarica ora