Ultimo aggiornamento il luglio 5, 2019
Il riconoscimento facciale è il problema di identificare e verificare le persone in una fotografia dal loro volto.
È un compito che viene banalmente eseguito dagli esseri umani, anche sotto luce variabile e quando i volti vengono cambiati per età o ostruiti con accessori e peli sul viso. Tuttavia, è rimasto un problema di computer vision impegnativo per decenni fino a poco tempo.
I metodi di deep learning sono in grado di sfruttare set di dati molto grandi di volti e apprendere rappresentazioni ricche e compatte di volti, consentendo ai modelli moderni di eseguire prima altrettanto bene e in seguito di sovraperformare le capacità di riconoscimento facciale degli esseri umani.
In questo post, scoprirai il problema del riconoscimento facciale e di come i metodi di apprendimento profondo possano raggiungere prestazioni sovrumane.
Dopo aver letto questo post, saprai:
- Il riconoscimento facciale è un ampio problema di identificare o verificare le persone in fotografie e video.
- Il riconoscimento facciale è un processo composto da rilevamento, allineamento, estrazione di funzionalità e un’attività di riconoscimento
- I modelli di apprendimento profondo prima si sono avvicinati e poi hanno superato le prestazioni umane per le attività di riconoscimento facciale.
Avvia il tuo progetto con il mio nuovo libro Deep Learning for Computer Vision, inclusi tutorial passo-passo e i file di codice sorgente Python per tutti gli esempi.
Iniziamo.

Una delicata introduzione al Deep Learning per il riconoscimento facciale
Foto di Susanne Nilsson, alcuni diritti riservati.
- Panoramica
- Faces in Photographs
- Vuoi risultati con il Deep Learning per la visione artificiale?
- Processo di riconoscimento facciale automatico
- Face Detection Task
- Compiti di riconoscimento facciale
- Deep Learning per il riconoscimento facciale
- Ulteriori letture
- Libri
- Face Recognition Papers
- Carte di riconoscimento facciale di apprendimento profondo
- Articoli
- Riepilogo
- Sviluppare modelli di apprendimento profondo per la visione di oggi!
- Sviluppa i tuoi modelli di visione in pochi minuti
- Finalmente portare l’apprendimento profondo per i vostri progetti di visione
Panoramica
Questo tutorial è diviso in cinque parti; sono:
- Faces in Photographs
- Processo di riconoscimento automatico del volto
- Face Detection Task
- Face Recognition Tasks
- Deep Learning for Face Recognition
Faces in Photographs
C’è spesso la necessità di riconoscere automaticamente le persone in una fotografia.
Ci sono molte ragioni per cui potremmo voler riconoscere automaticamente una persona in una fotografia.
Ad esempio:
- Potremmo voler limitare l’accesso a una risorsa a una sola persona, chiamata face authentication.
- Potremmo confermare che la persona corrisponde al proprio ID, chiamato face verification.
- Potremmo voler assegnare un nome a una faccia, chiamata identificazione faccia.
Generalmente, ci riferiamo a questo come il problema del “riconoscimento facciale” automatico e può applicarsi sia alle fotografie fisse che ai volti nei flussi di video.
Gli esseri umani possono eseguire questo compito molto facilmente.
Possiamo trovare i volti in un’immagine e commentare chi sono le persone, se sono conosciute. Possiamo farlo molto bene, come quando le persone sono invecchiate, indossano occhiali da sole, hanno capelli di colore diverso, guardano in direzioni diverse e così via. Possiamo farlo così bene che troviamo facce dove non ce ne sono, come nelle nuvole.
Tuttavia, questo rimane un problema difficile da eseguire automaticamente con il software, anche dopo 60 o più anni di ricerca. Fino a poco tempo fa.
Ad esempio, il riconoscimento di immagini del volto acquisite in un ambiente esterno con cambiamenti di illuminazione e / o posa rimane un problema in gran parte irrisolto. In altre parole, i sistemi attuali sono ancora lontani dalla capacità del sistema di percezione umana.
— Face Recognition: A Literature Survey, 2003.
Vuoi risultati con il Deep Learning per la visione artificiale?
Prendi il mio corso accelerato gratuito di 7 giorni (con codice di esempio).
Fare clic per iscriversi e anche ottenere una versione PDF Ebook gratuito del corso.
Scarica il tuo Mini-Corso GRATUITO
Processo di riconoscimento facciale automatico
Il riconoscimento facciale è il problema di identificare o verificare i volti in una fotografia.
Una dichiarazione generale del problema del riconoscimento automatico dei volti può essere formulata come segue: date immagini fisse o video di una scena, identificare o verificare una o più persone nella scena utilizzando un database memorizzato di volti
— Face Recognition: A Literature Survey, 2003.
Il riconoscimento facciale è spesso descritto come un processo che prevede innanzitutto quattro passaggi: rilevamento del volto, allineamento del viso, estrazione delle funzionalità e infine riconoscimento facciale.
- Rilevamento del volto. Individuare una o più facce nell’immagine e contrassegnare con un riquadro di delimitazione.
- Allineamento del viso. Normalizza la faccia in modo che sia coerente con il database, ad esempio geometria e fotometria.
- Estrazione di funzionalità. Estrarre caratteristiche dal volto che possono essere utilizzati per l’attività di riconoscimento.
- Riconoscimento facciale. Eseguire la corrispondenza del volto contro uno o più volti noti in un database preparato.
Un dato sistema può avere un modulo o un programma separato per ogni passaggio, che era tradizionalmente il caso, o può combinare alcuni o tutti i passaggi in un unico processo.
Una panoramica utile di questo processo è fornita nel libro “Handbook of Face Recognition”, fornito di seguito:
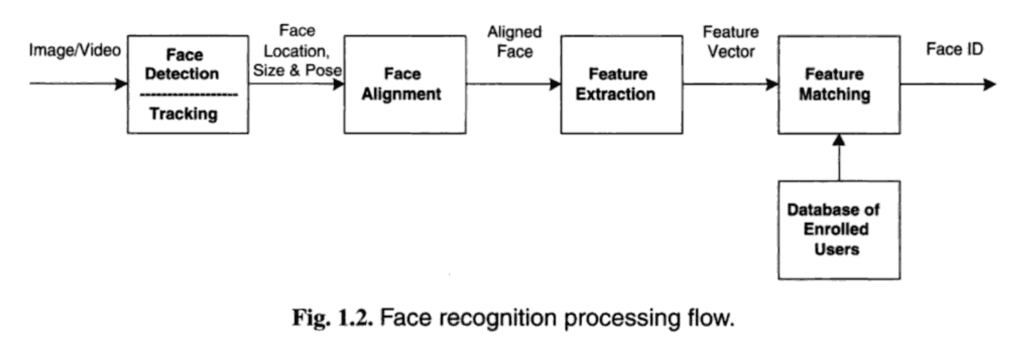
Panoramica dei passaggi in un processo di riconoscimento facciale. Tratto da “Handbook of Face Recognition”, 2011.
Face Detection Task
Face detection è il primo passo non banale nel riconoscimento dei volti.
È un problema di riconoscimento degli oggetti che richiede che sia la posizione di ciascuna faccia in una fotografia sia identificata (ad esempio la posizione) e l’estensione della faccia sia localizzata (ad esempio con un riquadro di delimitazione). Il riconoscimento degli oggetti in sé è un problema impegnativo, anche se in questo caso è simile in quanto esiste un solo tipo di oggetto, ad esempio le facce, da localizzare, sebbene le facce possano variare selvaggiamente.
Il volto umano è un oggetto dinamico e ha un alto grado di variabilità nel suo aspetto, il che rende il rilevamento dei volti un problema difficile nella visione artificiale.
– Face Detection: A Survey, 2001.
Inoltre, poiché è il primo passo in un sistema di riconoscimento facciale più ampio, il rilevamento dei volti deve essere robusto. Ad esempio, un volto non può essere riconosciuto se non può essere prima rilevato. Ciò significa che i volti devono essere rilevati con tutti i tipi di orientamenti, angoli, livelli di luce, acconciature, cappelli, occhiali, peli sul viso, trucco, età e così via.
Come processore front-end visivo, un sistema di rilevamento dei volti dovrebbe anche essere in grado di raggiungere il compito indipendentemente dall’illuminazione, dall’orientamento e dalla distanza della telecamera
— Face Detection: A Survey, 2001.
Il documento del 2001 intitolato “Face Detection: A Survey” fornisce una tassonomia dei metodi di rilevamento dei volti che possono essere ampiamente suddivisi in due gruppi principali:
- Basato su funzionalità.
- Basato su immagini.
Il rilevamento dei volti basato su funzionalità utilizza filtri artigianali che cercano e localizzano i volti nelle fotografie in base a una profonda conoscenza del dominio. Possono essere molto veloci e molto efficaci quando i filtri corrispondono, anche se possono fallire drammaticamente quando non lo fanno, ad esempio rendendoli un po ‘ fragili.
make fare uso esplicito della conoscenza del viso e seguire la classica metodologia di rilevamento in cui le caratteristiche di basso livello sono derivate prima dell’analisi basata sulla conoscenza. Le proprietà apparenti del viso come il colore della pelle e la geometria del viso vengono sfruttate a diversi livelli di sistema.
– Face Detection: A Survey, 2001.
In alternativa, il rilevamento dei volti basato sull’immagine è olistico e impara come individuare ed estrarre automaticamente i volti dall’intera immagine. Le reti neurali rientrano in questa classe di metodi.
address affrontare il rilevamento dei volti come un problema di riconoscimento generale. Le rappresentazioni basate su immagini dei volti, ad esempio in array di intensità 2D, sono classificate direttamente in un gruppo di volti utilizzando algoritmi di allenamento senza derivazione e analisi delle caratteristiche. queste tecniche relativamente nuove incorporano implicitamente la conoscenza del volto nel sistema attraverso schemi di mappatura e formazione.
– Face Detection: A Survey, 2001.
Forse il metodo dominante per il rilevamento dei volti utilizzato per molti anni (ed è stato utilizzato in molte fotocamere) è stato descritto nel documento del 2004 intitolato “Robusto rilevamento di oggetti in tempo reale”, chiamato cascata del rivelatore o semplicemente “cascata.”
Il loro rivelatore, chiamato detector cascade, è costituito da una sequenza di classificatori faccia semplice-complesso e ha attirato ampi sforzi di ricerca. Inoltre, detector cascade è stato implementato in molti prodotti commerciali come smartphone e fotocamere digitali. Mentre i rilevatori a cascata possono trovare con precisione facce verticali visibili, spesso non riescono a rilevare facce da diverse angolazioni, ad esempio vista laterale o facce parzialmente occluse.
– Multi-view Face Detection Utilizzando reti neurali convoluzionali profonde, 2015.
Per un tutorial sull’apprendimento profondo per il rilevamento dei volti vedi:
- Come eseguire il rilevamento dei volti con l’apprendimento profondo in Keras
Compiti di riconoscimento facciale
Il compito del riconoscimento facciale è ampio e può essere adattato alle esigenze specifiche di un problema di previsione.
Ad esempio, nel documento del 1995 intitolato “Human and machine recognition of faces: A survey”, gli autori descrivono tre compiti di riconoscimento facciale:
- Face Matching: trova la corrispondenza migliore per un determinato volto.
- Somiglianza faccia: trova le facce più simili a una determinata faccia.
- Trasformazione faccia: genera nuove facce simili a una determinata faccia.
Riassumono questi tre compiti separati come segue:
La corrispondenza richiede che l’immagine del volto corrispondente candidato sia in un insieme di immagini del viso selezionate dal sistema. Rilevamento somiglianza richiede oltre alla corrispondenza che le immagini di volti essere trovato che sono simili a un volto richiamato questo richiede che la misura di somiglianza utilizzato dal sistema di riconoscimento corrispondono strettamente le misure di somiglianza utilizzate dagli esseri umani Applicazioni di trasformazione richiedono che le nuove immagini create dal sistema essere simile a ricordi umani di un volto.
– Human and machine recognition of faces: A survey, 1995.
Il libro del 2011 sul riconoscimento facciale intitolato “Handbook of Face Recognition” descrive due modalità principali per il riconoscimento facciale, come:
- Verifica del volto. Una mappatura one-to-one di un dato volto contro un’identità nota (ad esempio, è questa la persona?).
- Identificazione del viso. Una mappatura uno-a-molti per un dato volto contro un database di volti noti (ad esempio chi è questa persona?).
Si prevede che un sistema di riconoscimento facciale identifichi automaticamente i volti presenti nelle immagini e nei video. Può operare in una o entrambe le modalità: (1) verifica del volto (o autenticazione) e (2) identificazione del volto (o riconoscimento).
— Pagina 1, Manuale di riconoscimento facciale. 2011.
Possiamo descrivere il problema del riconoscimento facciale come un compito di modellazione predittiva supervisionato addestrato su campioni con input e output.
In tutte le attività, l’input è una foto che contiene almeno una faccia, molto probabilmente una faccia rilevata che potrebbe anche essere stata allineata.
L’output varia in base al tipo di previsione richiesta per l’attività; ad esempio:
- Può quindi essere un’etichetta di classe binaria o una probabilità di classe binaria nel caso di un’attività di verifica facciale.
- Può essere un’etichetta di classe categoriale o un insieme di probabilità per un’attività di identificazione del volto.
- Può essere una metrica di similarità nel caso di un’attività di tipo similarità.
Deep Learning per il riconoscimento facciale
Il riconoscimento facciale è rimasto un’area attiva di ricerca nella visione artificiale.
Forse uno dei metodi di “machine learning” più conosciuti e adottati per il riconoscimento facciale è stato descritto nel documento del 1991 intitolato “Face Recognition Using Eigenfaces.”Il loro metodo, chiamato semplicemente “Eigenfaces”, è stato una pietra miliare in quanto ha raggiunto risultati impressionanti e ha dimostrato la capacità di semplici approcci olistici.
Le immagini dei volti vengono proiettate su uno spazio di feature (“face space”) che meglio codifica la variazione tra le immagini dei volti noti. Lo spazio del volto è definito dagli “eigenfaces”, che sono gli autovettori dell’insieme delle facce; non corrispondono necessariamente a caratteristiche isolate come occhi, orecchie e nasi
— Riconoscimento facciale con Eigenfaces, 1991.
Il documento 2018 intitolato “Deep Face Recognition: A Survey” fornisce un utile riassunto dello stato della ricerca sul riconoscimento facciale negli ultimi quasi 30 anni, evidenziando l’ampia tendenza dai metodi di apprendimento olistici (come Eigenfaces), al rilevamento di funzionalità artigianali locali, ai metodi di apprendimento poco profondi, ai metodi di apprendimento finalmente profondi che sono attualmente allo stato dell’arte.
Gli approcci olistici hanno dominato la comunità del riconoscimento facciale negli 1990. Nei primi anni 2000, descrittori locali artigianali è diventato popolare, e l’approccio di apprendimento caratteristica locale sono stati introdotti alla fine degli anni 2000. prestazioni migliora costantemente da circa 60% a sopra il 90%, mentre l’apprendimento profondo aumenta le prestazioni al 99,80% in soli tre anni.
— Riconoscimento facciale profondo: un sondaggio, 2018.
Data la svolta di AlexNet nel 2012 per il problema più semplice della classificazione delle immagini, c’è stata una raffica di ricerche e pubblicazioni nel 2014 e nel 2015 sui metodi di apprendimento profondo per il riconoscimento facciale. Le capacità hanno raggiunto rapidamente prestazioni a livello quasi umano, quindi hanno superato le prestazioni a livello umano su un set di dati di riconoscimento facciale standard entro un periodo di tre anni, il che rappresenta un incredibile tasso di miglioramento visti i decenni precedenti di sforzi.
Ci sono forse quattro sistemi milestone sul deep learning per il riconoscimento facciale che hanno guidato queste innovazioni; sono: DeepFace, la serie di sistemi DeepID, VGGFace e FaceNet. Tocchiamo brevemente ciascuno.
DeepFace è un sistema basato su reti neurali convoluzionali profonde descritte da Yaniv Taigman, et al. da Facebook AI Research e Tel Aviv. È stato descritto nel documento del 2014 intitolato “DeepFace: colmare il divario con le prestazioni a livello umano nella verifica del volto.”È stato forse il primo grande balzo in avanti utilizzando l’apprendimento profondo per il riconoscimento facciale, raggiungendo prestazioni quasi a livello umano su un set di dati standard di benchmark.
Il nostro metodo raggiunge una precisione del 97,35% sulle facce etichettate nel set di dati Wild (LFW), riducendo l’errore dello stato attuale dell’arte di oltre il 27%, avvicinandosi da vicino alle prestazioni a livello umano.
– DeepFace: colmare il divario con le prestazioni a livello umano nella verifica del volto, 2014.
Il DeepID, o” Deep hidden IDentity features”, è una serie di sistemi (ad esempio DeepID, DeepID2, ecc.), descritto per la prima volta da Yi Sun, et al. nel loro articolo 2014 intitolato ” Deep Learning Face Representation from Predicting 10,000 Classes.”Il loro sistema è stato descritto per la prima volta molto simile a DeepFace, anche se è stato ampliato nelle pubblicazioni successive per supportare sia le attività di identificazione che di verifica mediante la formazione tramite perdita contrastiva.
La sfida chiave del riconoscimento facciale è quella di sviluppare rappresentazioni efficaci delle caratteristiche per ridurre le variazioni intrapersonali e allo stesso tempo aumentare le differenze inter-personali. Il compito di identificazione del volto aumenta le variazioni inter-personali disegnando Deepid2 caratteristiche estratte da diverse identità a parte, mentre il compito di verifica del volto riduce le variazioni intra-personali tirando Deepid2 caratteristiche estratte dalla stessa identità insieme, entrambi i quali sono essenziali per il riconoscimento del volto.
– Rappresentazione del volto di apprendimento profondo mediante identificazione congiunta-Verifica, 2014.
I sistemi DeepID sono stati tra i primi modelli di apprendimento profondo per ottenere prestazioni migliori rispetto all’uomo sul compito, ad esempio DeepID2 ha raggiunto il 99,15% sui volti etichettati nel set di dati Wild (LFW), che è una prestazione migliore rispetto all’uomo del 97,53%. Sistemi successivi come FaceNet e VGGFace hanno migliorato questi risultati.
FaceNet è stato descritto da Florian Schroff, et al. a Google nel loro documento 2015 intitolato ” FaceNet: Un embedding unificato per il riconoscimento dei volti e il clustering.” Il loro sistema ha ottenuto risultati all’avanguardia e ha presentato un’innovazione chiamata “triplet loss” che ha permesso alle immagini di essere codificate in modo efficiente come vettori di funzionalità che hanno permesso un rapido calcolo della somiglianza e la corrispondenza tramite calcoli di distanza.
FaceNet, che apprende direttamente una mappatura dalle immagini dei volti in uno spazio euclideo compatto in cui le distanze corrispondono direttamente a una misura di somiglianza dei volti. Il nostro metodo utilizza una rete convoluzionale profonda addestrata per ottimizzare direttamente l’incorporamento stesso, piuttosto che un livello intermedio di collo di bottiglia come nei precedenti approcci di deep learning. Per addestrare, usiamo triplette di patch facciali approssimativamente allineate corrispondenti / non corrispondenti generate utilizzando un nuovo metodo di estrazione online di triplette
— FaceNet: A Unified Embedding for Face Recognition and Clustering, 2015.
Per un tutorial su FaceNet, vedi:
- Come sviluppare un sistema di riconoscimento facciale usando FaceNet in Keras
Il VGGFace (per mancanza di un nome migliore) è stato sviluppato da Omkar Parkhi, et al. dal Visual Geometry Group (VGG) di Oxford ed è stato descritto nel loro articolo del 2015 intitolato “Deep Face Recognition.”Oltre a un modello meglio sintonizzato, il focus del loro lavoro era su come raccogliere un set di dati di formazione molto ampio e usarlo per addestrare un modello CNN molto profondo per il riconoscimento facciale che ha permesso loro di ottenere risultati all’avanguardia su set di dati standard.
show mostriamo come un set di dati su larga scala (immagini 2.6 M, oltre persone 2.6 K) può essere assemblato da una combinazione di automazione e human in the loop
— Deep Face Recognition, 2015.
Per un tutorial su VGGFace, vedi:
- Come eseguire il riconoscimento facciale con VGGFace2 in Keras
Anche se queste possono essere le prime pietre miliari chiave nel campo del deep learning per la visione artificiale, il progresso è continuato, con molta innovazione focalizzata sulle funzioni di perdita per addestrare efficacemente i modelli.
Per un eccellente riepilogo aggiornato, vedere il documento 2018 “Deep Face Recognition: A Survey.”
Ulteriori letture
Questa sezione fornisce più risorse sull’argomento se stai cercando di approfondire.
Libri
- Manuale di riconoscimento facciale, Seconda edizione, 2011.
Face Recognition Papers
- Face Recognition: A Literature Survey, 2003.
- Face Detection: Un sondaggio, 2001.
- Riconoscimento umano e macchina dei volti: Un sondaggio, 1995.
- Robusto rilevamento di oggetti in tempo reale, 2004.
- Riconoscimento facciale con Eigenfaces, 1991.
Carte di riconoscimento facciale di apprendimento profondo
- Riconoscimento facciale profondo: un sondaggio, 2018.
- Riconoscimento facciale profondo, 2015.
- FaceNet: Un embedding unificato per il riconoscimento dei volti e il clustering, 2015.
- DeepFace: colmare il divario con le prestazioni a livello umano nella verifica del volto, 2014.
- Deep Learning Face Representation by Joint Identification-Verification, 2014.
- Rappresentazione faccia apprendimento profondo da predire 10.000 classi, 2014.
- Multi-view Face Detection Utilizzando reti neurali convoluzionali profonde, 2015.
- Dalle risposte delle parti facciali al rilevamento dei volti: un approccio di apprendimento profondo, 2015.
- Superando le prestazioni di verifica del volto a livello umano su LFW con GaussianFace, 2014.
Articoli
- Sistema di riconoscimento facciale, Wikipedia.
- Riconoscimento facciale, Wikipedia.
- Rilevamento del volto, Wikipedia.
- Volti etichettati nel set di dati Wild
Riepilogo
In questo post, hai scoperto il problema del riconoscimento facciale e di come i metodi di apprendimento profondo possono ottenere prestazioni sovrumane.
In particolare, hai imparato:
- Il riconoscimento facciale è un ampio problema di identificare o verificare le persone in fotografie e video.
- Il riconoscimento facciale è un processo composto da rilevamento, allineamento, estrazione di funzionalità e un’attività di riconoscimento
- I modelli di apprendimento profondo prima si sono avvicinati e poi hanno superato le prestazioni umane per le attività di riconoscimento facciale.
Hai qualche domanda?
Fai le tue domande nei commenti qui sotto e farò del mio meglio per rispondere.
Sviluppare modelli di apprendimento profondo per la visione di oggi!

Sviluppa i tuoi modelli di visione in pochi minuti
…con poche righe di codice python
Scopri come nel mio nuovo Ebook:
Deep Learning for Computer Vision
Fornisce tutorial di autoapprendimento su argomenti come:
classificazione, rilevamento di oggetti (yolo e rcnn), riconoscimento facciale (vggface e facenet), preparazione dei dati e molto altro…
Finalmente portare l’apprendimento profondo per i vostri progetti di visione
Saltare gli accademici. Solo risultati.
Guarda cosa c’è dentro