La modellazione dei dati è il processo di documentazione di un complesso progetto di sistema software come un diagramma facilmente comprensibile, utilizzando testo e simboli per rappresentare il modo in cui i dati devono fluire. Il diagramma può essere utilizzato per garantire un uso efficiente dei dati, come progetto per la costruzione di nuovo software o per la reingegnerizzazione di un’applicazione legacy.
La modellazione dei dati è un’abilità importante per gli scienziati dei dati o altri coinvolti nell’analisi dei dati. Tradizionalmente, i modelli di dati sono stati costruiti durante le fasi di analisi e progettazione di un progetto per garantire che i requisiti per una nuova applicazione siano pienamente compresi. I modelli di dati possono anche essere richiamati più avanti nel ciclo di vita dei dati per razionalizzare i progetti di dati originariamente creati dai programmatori su base ad hoc.
Approcci alla modellazione dei dati
La modellazione dei dati può essere un processo iniziale scrupoloso e, in quanto tale, a volte è vista come in contrasto con le metodologie di sviluppo rapido. Poiché la programmazione agile è entrata in un uso più ampio per accelerare i progetti di sviluppo, in alcuni casi i metodi di modellazione dei dati vengono adattati. In genere, un modello di dati può essere pensato come un diagramma di flusso che illustra le relazioni tra i dati. Consente alle parti interessate di identificare gli errori e apportare modifiche prima che sia stato scritto qualsiasi codice di programmazione. In alternativa, i modelli possono essere introdotti come parte degli sforzi di reverse engineering che estraggono modelli dai sistemi esistenti, come visto con i dati NoSQL.
I modellatori di dati utilizzano spesso più modelli per visualizzare gli stessi dati e garantire che tutti i processi, le entità, le relazioni e i flussi di dati siano stati identificati. Avviano nuovi progetti raccogliendo i requisiti degli stakeholder aziendali. Le fasi di modellazione dei dati si suddividono approssimativamente nella creazione di modelli di dati logici che mostrano attributi, entità e relazioni specifici tra entità e modello di dati fisici.
Il modello di dati logici serve come base per la creazione di un modello di dati fisici, che è specifico per l’applicazione e il database da implementare. Un modello di dati può diventare la base per la creazione di uno schema di dati più dettagliato.
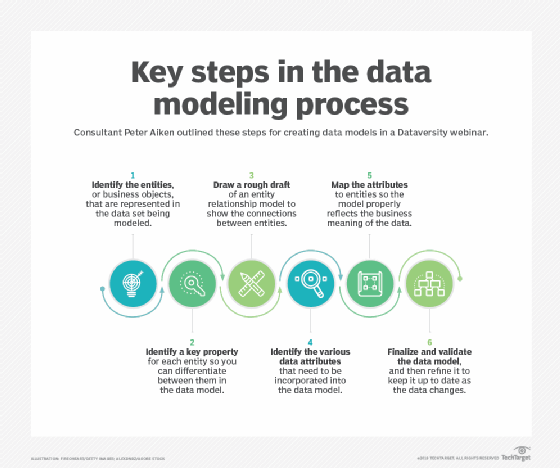
Gerarchica di modellazione dei dati
la modellazione dei Dati, intesa come disciplina, cominciarono a sorgere nel 1960, che accompagna la ripresa di utilizzo di sistemi di gestione di database (DBMSes). La modellazione dei dati ha permesso alle organizzazioni di portare coerenza, ripetibilità e sviluppo ben ordinato all’elaborazione dei dati. Gli utenti finali e i programmatori delle applicazioni sono stati in grado di utilizzare il modello di dati come riferimento nelle comunicazioni con i progettisti di dati.
I modelli di dati gerarchici che raggruppano i dati in treelike, accordi uno-a-molti hanno segnato questi primi sforzi e sostituito i sistemi basati su file in molti casi d’uso popolari. Il sistema di gestione delle informazioni di IBM (IMS) è un esempio primario dell’approccio gerarchico, che ha trovato ampio uso nelle aziende, in particolare nel settore bancario. Anche se i modelli di dati gerarchici sono stati in gran parte sostituiti-a partire dal 1980-da modelli di dati relazionali, il metodo gerarchico è ancora comune in XML (Extensible Markup Language) e Geographic Information systems (GISes) oggi. I modelli di dati di rete sono nati anche nei primi giorni di DBMS come mezzo per fornire ai progettisti di dati un’ampia visione concettuale dei loro sistemi. Un esempio è la Conferenza sui linguaggi dei sistemi di dati (CODASYL), che si è formata alla fine degli anni 1950 per guidare lo sviluppo di un linguaggio di programmazione standard che potrebbe essere utilizzato su vari tipi di computer.
Modellazione dei dati relazionali
Mentre riduceva la complessità del programma rispetto ai sistemi basati su file, il modello gerarchico richiedeva ancora una comprensione dettagliata dello specifico storage fisico dei dati impiegato. Proposto come alternativa al modello di dati gerarchico, il modello di dati relazionali non richiede agli sviluppatori di definire percorsi di dati. La modellazione dei dati relazionali è stata descritta per la prima volta in un documento tecnico del 1970 dal ricercatore IBM E. F. Codd. Il modello relazionale di Codd ha posto le basi per l’uso industriale di database relazionali in cui i segmenti di dati sono esplicitamente uniti dall’uso di tabelle, rispetto al modello gerarchico in cui i dati sono implicitamente uniti. Poco dopo la sua nascita, il modello di dati relazionali è stato accoppiato con il linguaggio di query strutturato (SQL) e ha iniziato a guadagnare un punto d’appoggio sempre più grande nel calcolo aziendale come mezzo efficiente per elaborare i dati.
Il modello di relazione tra entità
La modellazione dei dati relazionali ha fatto un altro passo avanti a partire dalla metà degli anni 1970 quando l’uso dei modelli di relazione tra entità (ER) è diventato più diffuso. Strettamente integrati con i modelli di dati relazionali, i modelli ER utilizzano diagrammi per rappresentare graficamente gli elementi in un database e per facilitare la comprensione dei modelli sottostanti.
Con la modellazione relazionale, i tipi di dati vengono determinati e raramente modificati nel tempo. Le entità comprendono gli attributi; ad esempio, gli attributi di un’entità dipendente possono includere cognome, nome, anni impiegati e così via. Le relazioni sono mappate visivamente, fornendo un mezzo pronto per comunicare gli obiettivi di progettazione dei dati ai vari partecipanti allo sviluppo e alla manutenzione dei dati. Nel corso del tempo, gli strumenti di modellazione, tra cui ER/Studio di Idera, Erwin Data Modeler e SAP PowerDesigner, hanno guadagnato ampio uso tra gli architetti di dati per la progettazione di sistemi.
Come programmazione orientata agli oggetti guadagnato terreno nel 1990, modellazione orientata agli oggetti guadagnato trazione come un altro modo per progettare sistemi. Pur avendo qualche somiglianza con i metodi ER, gli approcci orientati agli oggetti differiscono in quanto si concentrano sulle astrazioni degli oggetti delle entità del mondo reale. Gli oggetti sono raggruppati in gerarchie di classi e gli oggetti all’interno di tali gerarchie di classi possono ereditare attributi e metodi dalle classi padre. A causa di questo tratto di ereditarietà, i modelli di dati orientati agli oggetti presentano alcuni vantaggi rispetto alla modellazione ER, in termini di garanzia dell’integrità dei dati e supporto di relazioni di dati più complesse. Inoltre, negli anni ‘ 90, sono emersi modelli di dati specificamente orientati alle esigenze di data warehousing. Esempi notevoli sono snowflake schema e star schema modelli dimensionali.
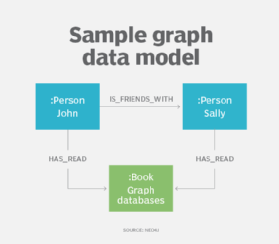
Graph data models
Una propaggine della modellazione gerarchica e dei dati di rete è il property graph model, che, insieme ai database graph, ha trovato un maggiore utilizzo per descrivere relazioni complesse all’interno di set di dati, in particolare nelle applicazioni di social media, recommender e fraud detection.
Utilizzando il modello di dati del grafico, i progettisti descrivono il loro sistema come un grafico connesso di nodi e relazioni, proprio come potrebbero fare con la modellazione dei dati ER o object. I modelli di dati grafici possono essere utilizzati per l’analisi del testo, creando modelli che scoprono le relazioni tra i punti dati all’interno dei documenti.