
Questo è un punto importante da capire. Non solo utilizzando il metodo sbagliato a volte portare a pagine non essere rimosso dall’indice come previsto, ma può anche avere un effetto negativo sulla SEO.
Per aiutarti a decidere rapidamente quale metodo di rimozione è il migliore per te, abbiamo creato un diagramma di flusso in modo da poter saltare alla sezione pertinente dell’articolo.
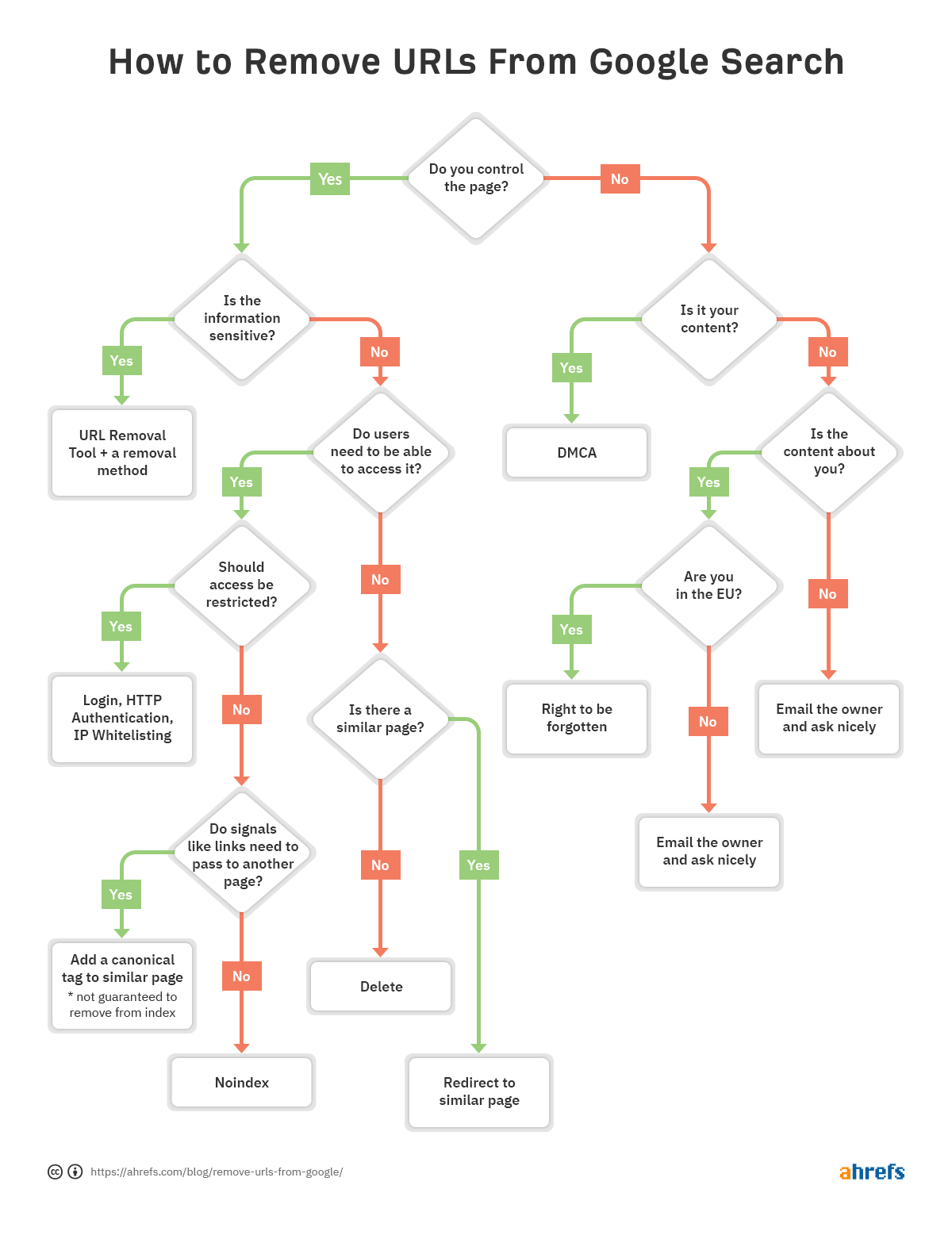
In questo post, imparerai:
- Come controllare se un URL indicizzato
- Cinque modi per rimuovere gli Url da Google
- Come priorità traslochi
- Comune di rimozione errori da evitare
- Come rimuovere il contenuto che non è sul tuo sito
- Come rimuovere immagini
Quello che di solito vedere i Seo fare per verificare se il contenuto viene indicizzato è l’uso di un sito: la ricerca in Google (ad esempio, sito:https://ahrefs.com). Mentre il sito: le ricerche possono essere utili per identificare le pagine o le sezioni di un sito Web che possono essere problematiche se mostrano nei risultati di ricerca, devi stare attento perché non sono normali query e in realtà non ti diranno se una pagina è indicizzata. Essi possono mostrare le pagine che sono noti a Google, ma questo non significa che sono idonei a mostrare nei normali risultati di ricerca senza il sito: operatore.
Ad esempio, site: le ricerche possono ancora mostrare pagine che reindirizzano o sono canonizzate a un’altra pagina. Quando chiedi un sito specifico, Google potrebbe mostrare una pagina di quel dominio con il contenuto, il titolo e la descrizione di un altro dominio. Prendiamo ad esempio moz.com che era seomoz.org. Qualsiasi query utente regolare che portano a pagine su moz.com mostrerà moz.com nelle SERP, mentre site:seomoz.org mostrerà seomoz.org nei risultati della ricerca come mostrato di seguito.
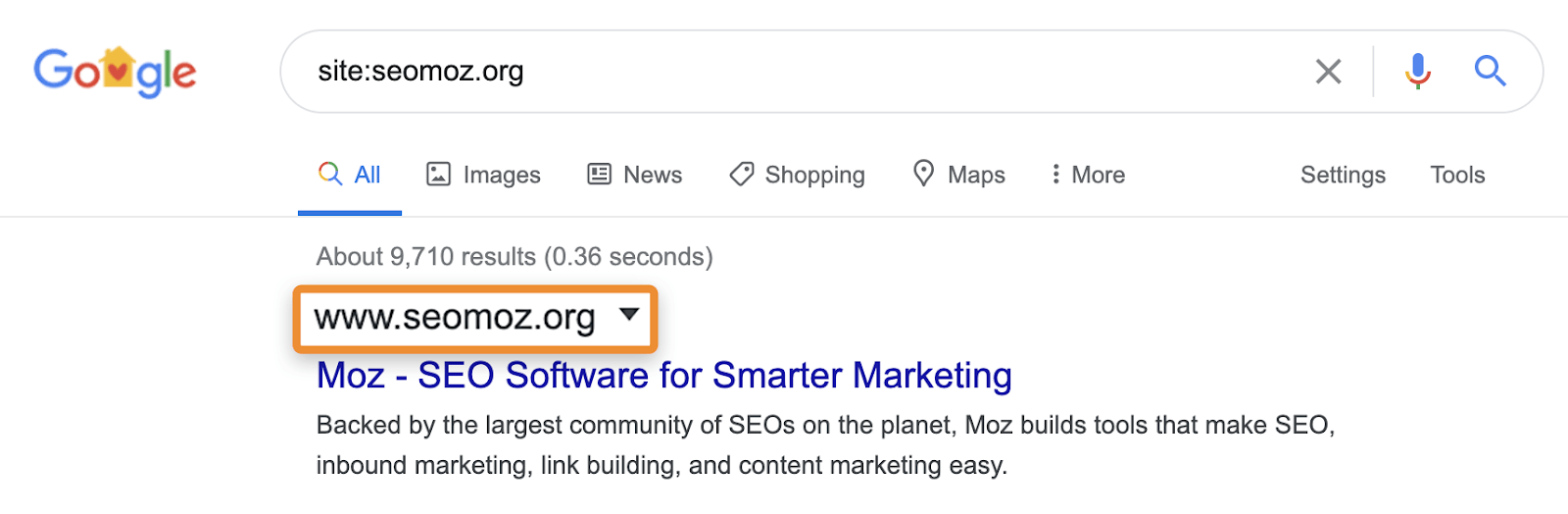
La ragione per cui questa è una distinzione importante è che può portare i SEO a commettere errori come bloccare o rimuovere attivamente gli URL dall’indice per il vecchio dominio, il che impedisce il consolidamento di segnali come PageRank. Ho visto molti casi con migrazioni di dominio in cui le persone pensano di aver commesso un errore durante la migrazione perché queste pagine mostrano ancora per site:old-domain.com ricerche e finiscono per danneggiare attivamente il loro sito web durante il tentativo di” risolvere ” il problema.
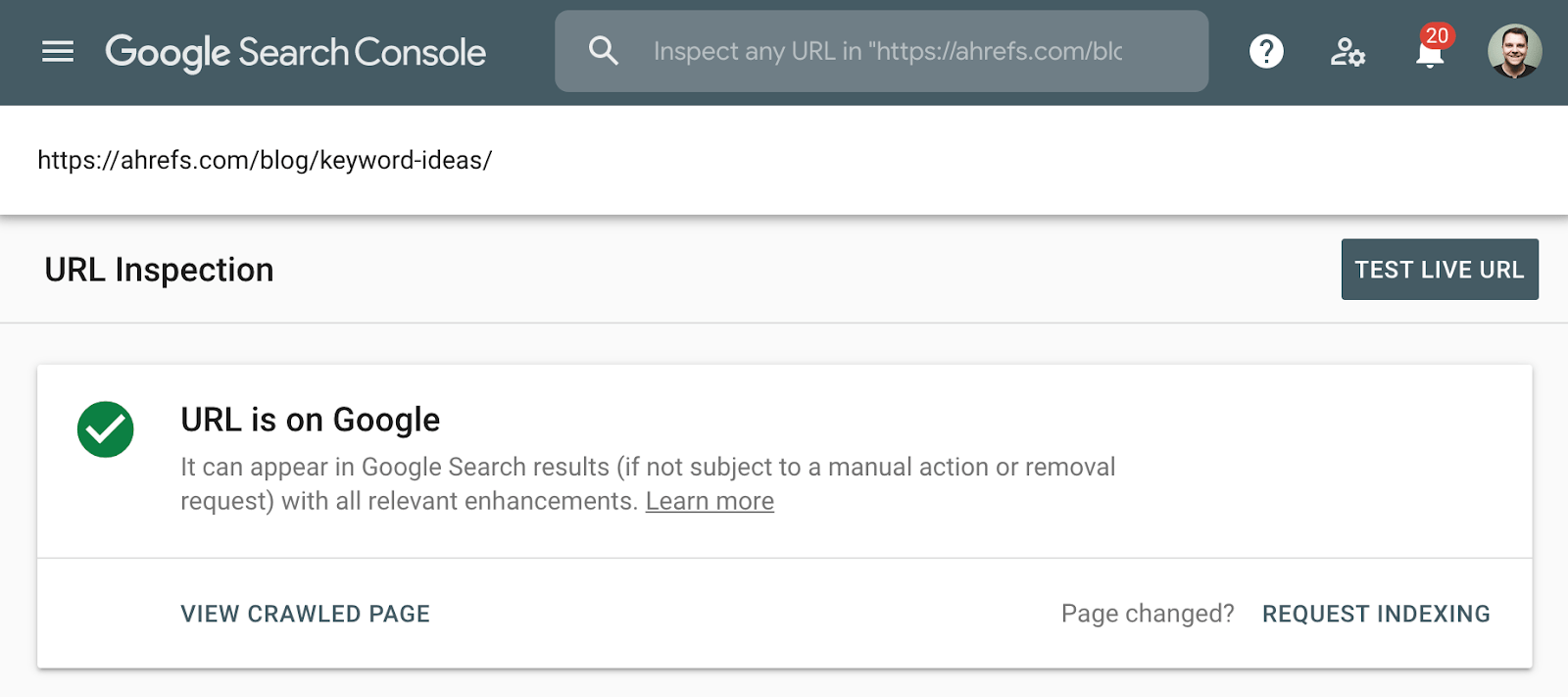
Il metodo migliore per controllare l’indicizzazione consiste nell’utilizzare il rapporto di copertura dell’indice in Google Search Console o lo strumento di ispezione URL per un singolo URL. Questi strumenti indicano se una pagina è indicizzata e forniscono ulteriori informazioni su come Google sta trattando la pagina. Se non hai accesso a questo, cerca su Google l’URL completo della tua pagina.
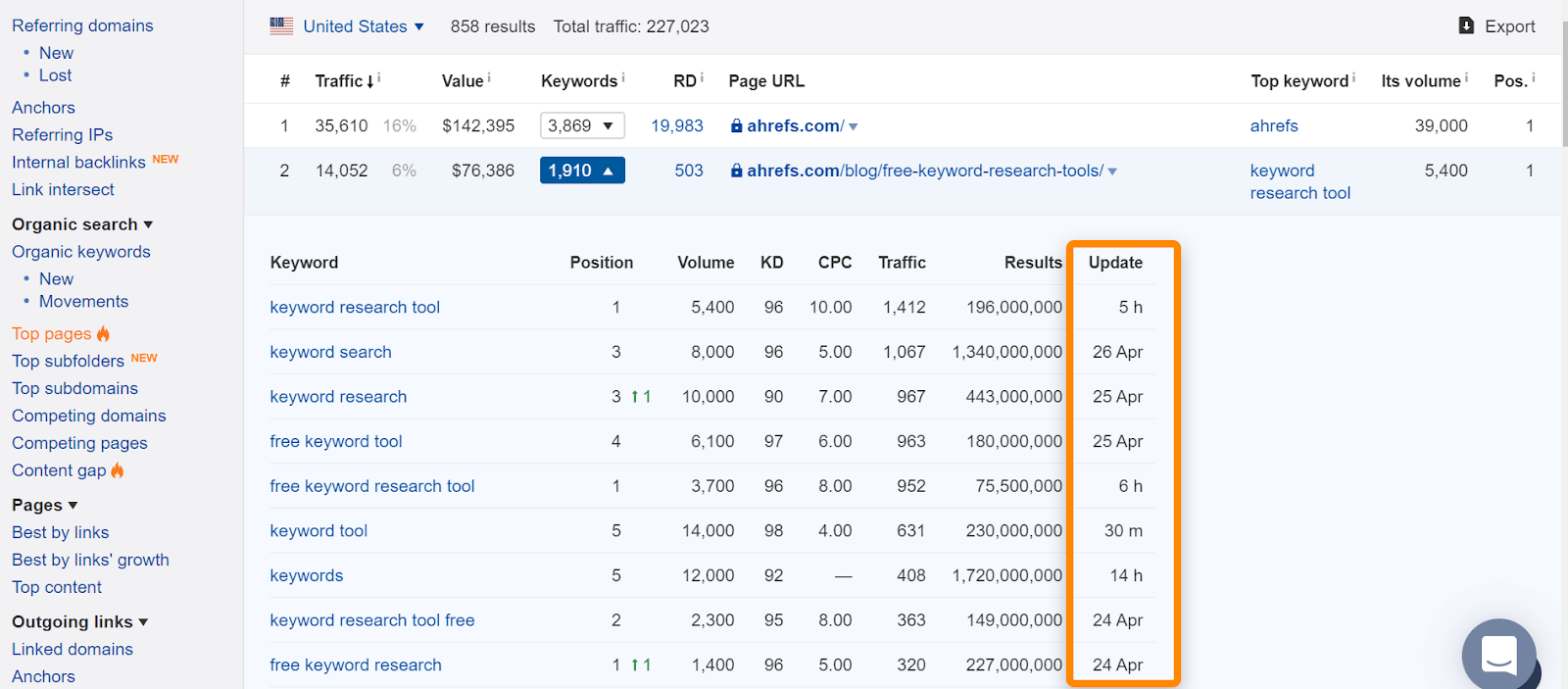
In Ahrefs, se trovi la pagina nel nostro rapporto “Top pages” o nella classifica per parole chiave organiche, di solito significa che l’abbiamo vista in classifica per le normali query di ricerca ed è una buona indicazione che la pagina è stata indicizzata. Si noti che le pagine sono state indicizzate quando le abbiamo viste, ma potrebbe essere cambiato. Controlla la data in cui abbiamo visto l’ultima volta la pagina per una query.
Se c’è un problema con un particolare URL e deve essere rimosso dall’indice, seguire il diagramma di flusso all’inizio dell’articolo per trovare l’opzione di rimozione corretta, quindi passare alla sezione appropriata qui sotto.
Se rimuovi la pagina e servi un codice di stato 404 (non trovato) o 410 (andato), la pagina verrà rimossa dall’indice poco dopo che la pagina sarà stata nuovamente scansionata. Fino a quando non viene rimosso, la pagina può ancora mostrare nei risultati di ricerca. E anche se la pagina stessa non è più disponibile, una versione memorizzata nella cache della pagina potrebbe essere temporaneamente disponibile.
Quando potresti aver bisogno di un’opzione diversa:
- Ho bisogno di una rimozione più immediata. Vedere la sezione strumento di rimozione URL.
- Ho bisogno di consolidare segnali come link. Vedere la sezione canonicalizzazione.
- Ho bisogno della pagina disponibile per gli utenti. Verifica se le sezioni noindex o restricting access si adattano alla tua situazione.
- Opzione di rimozione 2: Noindex
- Opzione di rimozione 3: Limitare l’accesso
- Opzione di rimozione 4: Strumento di rimozione URL
- Opzione di rimozione 5: Canonicalizzazione
- Noindex nei robot.txt
- Blocco dalla scansione nei robot.txt
- Nofollow
- Noindex e canonical ad un altro URL
- Noindex, attendere che Google la ricerca per indicizzazione, quindi bloccare la scansione
- Cosa succede se si tratta di contenuti su di te ma non su un sito che possiedi?
- Considerazioni finali
Opzione di rimozione 2: Noindex
Un tag noindex meta robots o una risposta di intestazione x‑robots diranno ai motori di ricerca di rimuovere una pagina dall’indice. Il tag meta robots funziona per le pagine in cui la risposta x-robots funziona per pagine e tipi di file aggiuntivi come i PDF. Per vedere questi tag, un motore di ricerca deve essere in grado di eseguire la scansione delle pagine, quindi assicurati che non siano bloccate nei robot.txt. Inoltre, si noti che la rimozione di pagine dall’indice può impedire il consolidamento di link e altri segnali.
Esempio di un meta robot noindex:
<meta name="robots" content="noindex">
Esempio di tag x‑robots noindex nell’intestazione risposta:
HTTP/1.1 200 OKX-Robots-Tag: noindex
Quando potrebbe essere necessaria un’opzione diversa:
- Non voglio che gli utenti accedano a queste pagine. Vedere la sezione limitazione dell’accesso.
- Ho bisogno di consolidare segnali come link. Vedere la sezione canonicalizzazione.
Opzione di rimozione 3: Limitare l’accesso
Se vuoi che la pagina sia accessibile ad alcuni utenti ma non ai motori di ricerca, allora quello che probabilmente vuoi è una di queste tre opzioni:
- una sorta di sistema di login;
- Autenticazione HTTP (dove è richiesta una password per l’accesso);
- Whitelist IP (che consente solo a specifici indirizzi IP di accedere alle pagine)
Questo tipo di configurazione è la migliore per cose come reti interne, contenuti per soli membri o per siti di staging, test o sviluppo. Consente a un gruppo di utenti di accedere alla pagina, ma i motori di ricerca non saranno in grado di accedervi e non indicizzeranno le pagine.
Quando potresti aver bisogno di un’opzione diversa:
- Ho bisogno di una rimozione più immediata. Vedere la sezione strumento di rimozione URL. In questo caso particolare, potresti volere una rimozione più immediata se il contenuto che stai cercando di nascondere è stato memorizzato nella cache e devi impedire agli utenti di vedere quel contenuto.
Opzione di rimozione 4: Strumento di rimozione URL
Il nome di questo strumento di Google è leggermente fuorviante in quanto il modo in cui funziona è che nasconderà temporaneamente il contenuto. Google continuerà a vedere e scansionare questo contenuto, ma le pagine non verranno visualizzate per gli utenti. Questo effetto temporaneo dura per sei mesi in Google, mentre Bing ha uno strumento simile che dura per tre mesi. Questi strumenti dovrebbero essere utilizzati nei casi più estremi per cose come problemi di sicurezza, perdite di dati, informazioni personali identificabili (PII), ecc. Per Google, utilizzare lo strumento Rimozioni e per Bing, vedere come bloccare gli URL.
È comunque necessario applicare un altro metodo insieme all’utilizzo dello strumento di rimozione per rimuovere effettivamente le pagine per un periodo più lungo (noindex o delete) o impedire agli utenti di accedere al contenuto se hanno ancora i collegamenti (eliminare o limitare l’accesso). Questo ti dà solo un modo più veloce di nascondere le pagine mentre la rimozione ha il tempo di elaborare. La richiesta può richiedere fino a un giorno per l’elaborazione.
Opzione di rimozione 5: Canonicalizzazione
Quando si hanno più versioni di una pagina e si desidera consolidare segnali come collegamenti a una singola versione, ciò che si vuole fare è una qualche forma di canonicalizzazione. Questo è principalmente per impedire il contenuto duplicato mentre si consolidano più versioni di una pagina in un singolo URL indicizzato.
Hai diverse opzioni di canonicalizzazione:
- Tag canonico. Questo specifica un altro URL come versione canonica o la versione che si desidera visualizzare. Se le pagine sono duplicate o molto simili, questo dovrebbe andare bene. Quando le pagine sono troppo diverse, la canonica può essere ignorata in quanto è un suggerimento e non una direttiva.
- Reindirizza. Un reindirizzamento porta un utente e un bot di ricerca da una pagina all’altra. 301 è il reindirizzamento più comunemente usato dai SEO e indica ai motori di ricerca che si desidera che l’URL finale sia quello mostrato nei risultati di ricerca e dove i segnali sono consolidati. Un reindirizzamento 302 o temporaneo indica ai motori di ricerca che si desidera che l’URL originale sia quello di rimanere nell’indice e consolidare i segnali lì.
- Gestione dei parametri URL. Un parametro viene aggiunto alla fine dell’URL e in genere include un punto interrogativo, come ahrefs.com?this=parameter. Questo strumento di Google ti consente di dire loro come trattare gli URL con parametri specifici. Ad esempio, è possibile specificare se il parametro cambia il contenuto della pagina o se è solo pensato per monitorare l’utilizzo.
Se hai più pagine da rimuovere dall’indice di Google, allora dovrebbero essere prioritarie di conseguenza.
Massima priorità: queste pagine sono solitamente relative alla sicurezza o relative a dati riservati. Ciò include contenuti che contengono dati personali (PII), dati dei clienti o informazioni proprietarie.
Priorità media: di solito si tratta di contenuti destinati a un gruppo specifico di utenti. Intranet aziendali o portali per dipendenti, contenuti destinati solo ai membri e ambienti di staging, test o sviluppo.
Bassa priorità: queste pagine di solito comportano contenuti duplicati di qualche tipo. Alcuni esempi di questo potrebbero includere pagine servite da più URL, URL con parametri, e ancora potrebbe includere staging, test, o ambienti di sviluppo.
Voglio coprire alcuni dei modi in cui di solito vedo le rimozioni eseguite in modo errato e cosa succede in ogni scenario per aiutare le persone a capire perché non funzionano.
Noindex nei robot.txt
Mentre Google supportava ufficiosamente noindex nei robot.txt, non è mai stato uno standard ufficiale e ora hanno formalmente rimosso il supporto. Molti dei siti che stavano facendo questo stavano facendo in modo non corretto e danneggiare se stessi.
Blocco dalla scansione nei robot.txt
La scansione non è la stessa cosa dell’indicizzazione. Anche se Google è bloccato dalla scansione delle pagine, se ci sono collegamenti interni o esterni a una pagina possono ancora indicizzarlo. Google non saprà cosa c’è nella pagina perché non lo scansionerà, ma sanno che esiste una pagina e scriverà persino un titolo da mostrare nei risultati di ricerca in base a segnali come il testo di ancoraggio dei link alla pagina.
Nofollow
Questo viene comunemente confuso per noindex e alcune persone lo useranno a livello di pagina aspettandosi che la pagina non venga indicizzata. Nofollow è un suggerimento e, mentre in origine ha interrotto la scansione dei collegamenti sulla pagina e dei singoli collegamenti con l’attributo nofollow, non è più così. Google può ora eseguire la scansione di questi link, se vogliono. Nofollow è stato utilizzato anche su singoli link per cercare di fermare Google da strisciare attraverso a pagine specifiche e per PageRank scultura. Ancora una volta, questo non funziona più poiché nofollow è un suggerimento. In passato, se la pagina avesse un altro link ad essa, Google potrebbe ancora scoprire da questo percorso alternativo di scansione.
Si noti che è possibile trovare le pagine nofollowed in blocco utilizzando questo filtro in Esplora pagine in Ahrefs’ Site Audit.
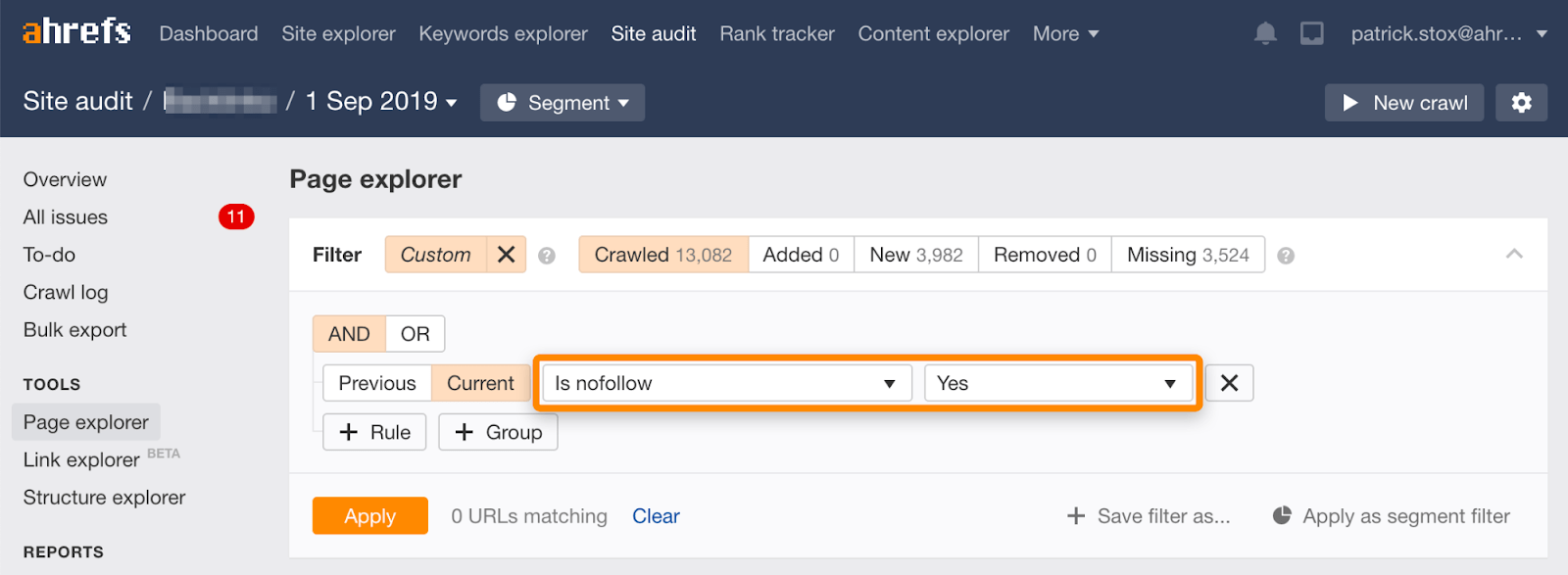
Poiché raramente ha senso nofollow tutti i link su una pagina, il numero di risultati dovrebbe essere zero o vicino a zero. Se ci sono risultati corrispondenti, ti esorto a verificare se la direttiva nofollow è stata aggiunta accidentalmente al posto di noindex e a scegliere un metodo di rimozione più appropriato se necessario.
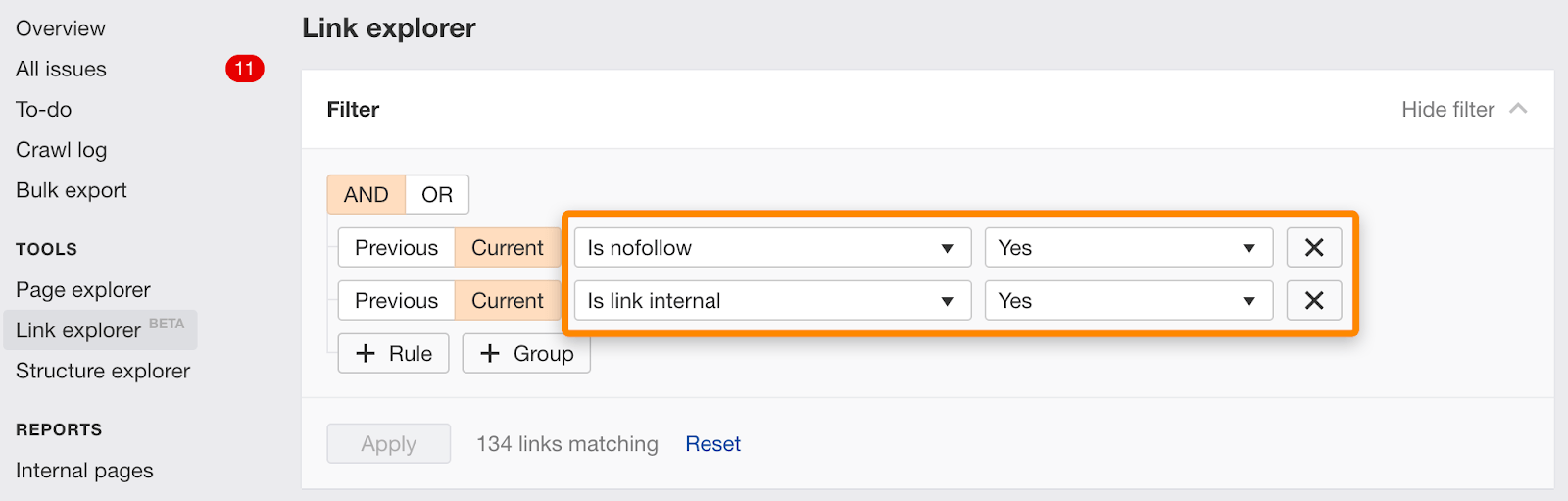
È anche possibile trovare singoli link contrassegnati nofollow utilizzando questo filtro in Esplora collegamenti.
Noindex e canonical ad un altro URL
Questi segnali sono in conflitto. Noindex dice di rimuovere la pagina dall’indice e canonical dice che un’altra pagina è la versione che dovrebbe essere indicizzata. Questo potrebbe effettivamente funzionare per il consolidamento in quanto Google in genere sceglie di ignorare il noindex e utilizzare invece il canonico come segnale principale. Tuttavia, questo non è un comportamento assoluto. C’è un algoritmo coinvolto e c’è il rischio che il tag noindex possa essere il segnale contato. Se questo è il caso, le pagine non si consolideranno correttamente.
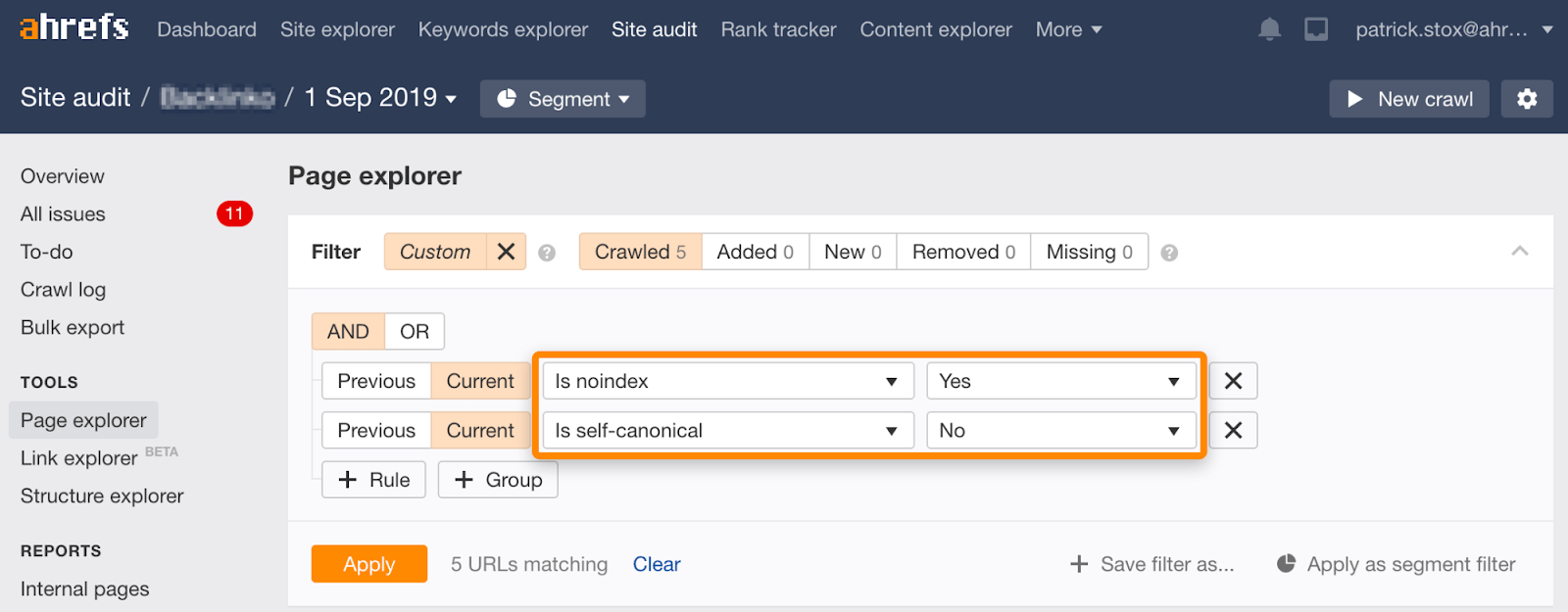
si noti che è possibile trovare noindexed pagine con i non-auto-referenziale canonici utilizzando questo set di filtri nella Pagina di Explorer nel Sito di Controllo:
Noindex, attendere che Google la ricerca per indicizzazione, quindi bloccare la scansione
Ci sono un paio di modi per fare questo di solito accade:
- Pagine sono già bloccato, ma sono indicizzate, le persone di aggiungere noindex e sbloccare in modo che Google è in grado di eseguire la scansione e vedere il noindex, quindi bloccare le pagine di eseguire la scansione di nuovo.
- Le persone aggiungono tag noindex per le pagine che vogliono rimuovere e dopo che Google ha eseguito la scansione e elaborato il tag noindex, bloccano la scansione delle pagine.
In entrambi i casi, lo stato finale è bloccato dalla scansione. Se ricordi, prima, abbiamo parlato di come la scansione non sia la stessa dell’indicizzazione. Anche se queste pagine sono bloccate, possono comunque finire nell’indice.
Se possiedi il contenuto che viene utilizzato su un altro sito Web, potresti essere in grado di presentare un reclamo basato sul Digital Millennium Copyright Act (DMCA). È possibile utilizzare lo strumento di rimozione del copyright di Google per fare quello che viene chiamato un takedown DMCA, che richiede la rimozione di qualsiasi materiale protetto da copyright.
Cosa succede se si tratta di contenuti su di te ma non su un sito che possiedi?
Se ti trovi nell’UE, puoi rimuovere contenuti che contengono informazioni su di te grazie a un’ordinanza del tribunale per il diritto all’oblio. È possibile richiedere la rimozione delle informazioni personali utilizzando il modulo di rimozione della privacy UE.
Per rimuovere le immagini da Google, il modo più semplice è con i robot.txt. Mentre il supporto non ufficiale per la rimozione di pagine è stato rimosso dai robot.txt come abbiamo accennato in precedenza, semplicemente non consentire la scansione delle immagini è il modo giusto per rimuovere le immagini.
Per una singola immagine:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
Per tutte le immagini:
User-agent: Googlebot-ImageDisallow: /
Considerazioni finali
Come rimuovere gli URL è abbastanza situazionale. Abbiamo parlato di diverse opzioni, ma se sei ancora confuso quale è giusto per te, fai riferimento al diagramma di flusso all’inizio.
Puoi anche passare attraverso lo strumento di risoluzione dei problemi legale fornito da Google per la rimozione dei contenuti.
Hai domande? Fammi sapere su Twitter.