- Eh? Mitkä ovat ryhmittely joukko, kuutio ja ROLLUP SQL?
- miksi ROLLUP tai CUBE olisi minulle hyödyllinen?
- ovatko nämä SQL-standardin mukaisia vai vain Microsoftin juttuja?
- Voinko jättää yhden tai useamman palstan pois rullauksesta?
- mitkä ovat RYHMITYSJOUKOT sitten? Pitäisikö minun tietää heistä?
- miksi haluamme yhdistää sarakkeita mihinkään aggregaatioon?
- onko sarjojen ryhmittelyssä muutakin kuin tapa tehdä ”à la carte” – kuutioita?
- miksi funktiot ryhmittely() ja Grouping_ID() annetaan?
- Eh? Mitkä ovat ryhmittely joukko, kuutio ja ROLLUP SQL?
- miksi ROLLUP tai CUBE olisi minulle hyödyllinen?
- ovatko nämä SQL-standardin mukaisia vai vain Microsoftin juttuja?
- Voinko jättää yhden tai useamman sarakkeen pois rullauksesta?
- mitkä ovat RYHMITTELYSARJAT sitten? Pitäisikö minun tietää heistä?
- miksi haluamme yhdistää sarakkeita mihinkään aggregaatioon?
- onko sarjojen ryhmittelyssä muutakin kuin tapa tehdä ”à la carte” – kuutioita?
- miksi funktiot ryhmittely() ja Grouping_ID() annetaan?
Eh? Mitkä ovat ryhmittely joukko, kuutio ja ROLLUP SQL?
kuutio, rullaus ja RYHMITYSJOUKKO ovat valinnaisia ryhmän operaattoreita SELECT-lausekkeen lausekkeittain, joilla tehdään raportteja, joissa on paljon tietoa. Niiden avulla voit tehdä useita ryhmä operaatioita yhdessä lausumassa, mahdollisesti säästää paljon aikaa ja laskennallista vaivaa. Ne voivat tarjota kaikki raportointiin tarvittavat tiedot, mukaan lukien kokonaissummat, samalla kun ne tarjoavat hyvän suorituskyvyn suurissa taulukoissa ja auttavat kyselyn optimistia laatimaan hyvän suoritussuunnitelman.
ylimääräiset ”super-aggregaatti” – rivit antavat summaarvoja, jolloin yhden tuloksen sisällä voi olla useita ”aggregaatteja”, kuten summa() tai MAX (). Näiden rivien sisällä olevien Nullien on tarkoitus tarkoittaa ”kaikkia” eikä ”tuntemattomia”. Sen avulla voit saada kaikki aggregaatit tarvitset yhdellä läpi taulukon. Koska tuloksissa on ylimääräisiä rivejä, annetaan lisäfunktiot GROUPING() ja GROUPING_ID() ilmoittamaan nämä ylimääräiset ”superaggregoidut” rivit ja mitkä sarakkeet kootaan yhteen.
Tämä on erittäin järkevää, jos sinulla on sovellus, joka tarvitsee ajaa useita raportteja ilman ylimääräistä laskenta tai menemättä takaisin tietokantaan: sinulla on kaikki mitä tarvitset yhdessä tuloksessa.
ota tämä standardiesimerkki ROLLUPISTA (käytän AdventureWorks 2012 tässä)..
|
1
2
3
4
5
6
|
valitse t. alueena t.name alueena, summa(TotalDue) tuloina,
päiväys(VVVV, Tilauspäivitys) AS , päiväys (mm, Tilauspäivitys) AS
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON S. TerritoryID = T. TerritoryID
ryhmä T., t.name, datepart(VVVV, OrderDate), datepart(mm, OrderDate)
ROLLUP
|
sekä yksinkertainen ryhmä aggregoiduilla riveillä, joissa kunkin kuukauden erääntyvä summa, jonka saat yksinkertaisella ryhmityksellä, saat myös välisumman tai super-yhteenlaskettu rivit, ja myös grand yhteensä rivi. (tässä on tuloksen alku)
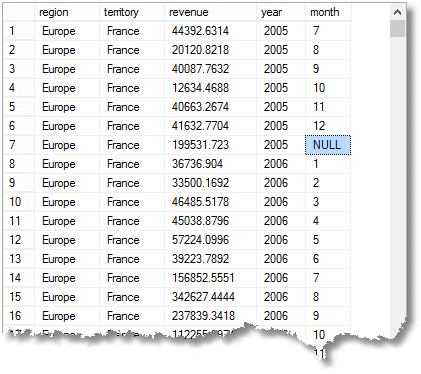
että NULL I ’ve highlit tarkoittaa, että rivi on aggregaatti vuoden 2005 ”kaikille” kuukausille Ranskassa (osa Euroopan aluetta)
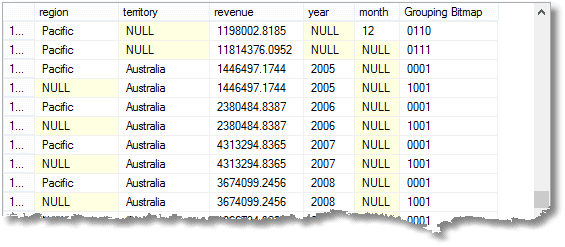
sekä kaikki tämä, saat kunkin vuoden, kunkin alueen ja alueellisen ryhmän erääntyneen summan sekä koko erääntyneen summan. (lopusta)
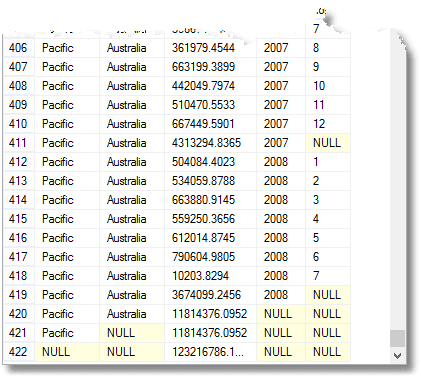
Nullit tarkoittavat ”kaikkia”, muista. Viimeinen rivi on kokonaissumma, ja sen yläpuolella on Tyynenmeren alueen kokonaissumma. Sen yläpuolella on Australian osuus Tyynenmeren alueella. Neljäs rivi alhaalta on Australian vuoden 2008 panos. Palautettavien ryhmittelyjen määrä on yksi enemmän kuin ryhmälle lausekkeittain toimitetun yhdistelmäelementtiluettelon lausekkeiden määrä.
saman efektin saamiseksi ilman rollupia olisi tehtävä jotain tällaista (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
MYGROUPINGIN kanssa (alue, territorio, totalDue, , )
AS (valitse t., t.name, summa(yhteensä) tuloina,
päiväys(VVVV, tilauspäivä), päiväys (mm, tilauspäivä)
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON S. TerritoryID = T. TerritoryID
ryhmä t.name, t., päiväys(VVVV, Järjestyspäivä), päiväys(mm, Järjestyspäivä))
valitse alue, alue, totalDue, ,
MYGROUPINGISTA
valitse alue, alue, summa(totalDue), , NULL
myGrouping-ryhmästä alueittain, alueittain,
unioni kaikki
Valitse alue, territorio, summa(totaldue), null, null
mygroupingin ryhmästä alueittain, territorioittain
Union all
valitse alue, null, sum(totaldue), null, null
MYGROUPINGIN ryhmästä alueittain
Union all
valitse null, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
’GROUPBY ROLLUP (t.,t.name, datepart(VVVV,OrderDate),datepart (mm,OrderDate))”
|
Tämä uusi syntaksi mahdollistaa joitakin lisätoimintoja. Muista myös, että sarakejärjestys vaikuttaa rullauksen tuotosryhmiin ja voi vaikuttaa tulosjoukon rivien määrään.
kuutio tekee saman yleisen asian, mutta sen sijaan, että se tarjoaisi järjestetyissä superaggregaattiriveissä olevien loppusummien hierarkian, se tarjoaa kaikki ”superaggregaatin” permutaatiot (”symmetriset superaggregaattirivit”), niin sanotut ristikkäistaulurivit. Jos halusi tietää, mikä alue antoi eniten tilauksia maaliskuussa, tai mikä alue suoriutui heikoimmin vuonna 2006, silloin tarvittiin kuutio. Annatte kaikki mahdolliset yhteenvedot tuloksesta.
RYHMITTELYSARJAN avulla voit hienosäätää tuloksesi ja antaa erikoistuneempaa tietoa kuution yläpuolella ja sen ulkopuolella. Se voi antaa yhteenvetoa ulottuvuuksien yhdistelmistä. Voit saada täsmälleen saman tuloksen kuin meidän ROLLUP esimerkki käyttämällä ryhmittely sarjaa, mutta paljon enemmän kirjoittamalla.
|
1
2
3
4
5
6
7
8
9
10
|
Tämä vain osoittaa, miten ne liittyvät. Todellisuudessa, sinun turvautua ryhmittely sarjaa saada tuloksia, jotka ovat mahdottomia ROLLUP tai kuutio.
lähes kaikki nämä yhteenvedot voidaan saada käyttämällä vain ryhmä kerrallaan, mutta vain ryhmittelemällä toistuvasti ryhmän tulos, tai tekemällä useampi kuin yksi aineiston läpi.
kun käytät CUBE -, ROLLUP-tai RYHMITYSJOUKKOJA, et voi käyttää erillistä avainsanaa koosteilmaisuissasi, kuten AVG (erillinen sarake_nimi), COUNT (erillinen sarake_nimi) ja SUM (erillinen sarake_nimi)
miksi ROLLUP tai CUBE olisi minulle hyödyllinen?
ROLLUP ja CUBE olivat kukoistuskauttaan ennen SSAS: ää. Ne olivat hyödyllisiä tarjota samantyyppisiä palveluja tarjoamia kuutio OLAP. Sillä on silti käyttötarkoituksensa. Adventureworksissa se on ylilyöntiä, mutta jos käsittelet suuria tietomääriä, sinun täytyy siirtää tietosi vain kerran, ja tehdä mahdollisimman paljon tietoja, jotka on koottu. Menneisyydessä tapahtuneita tapahtumia ei voi muuttaa, joten aktiivisen OLTP-järjestelmän historiatietoja on harvoin tarpeen säilyttää. Sen sijaan sinun tarvitsee vain säilyttää yhdistetyt tiedot kaikkien ennakoitavissa olevien raporttien edellyttämällä tarkkuudella (”rakeisuus”).
Kuvittele, että olet vastuussa puhelinkytkimen raportoinnista, jossa on noin kaksi miljoonaa puhelua päivässä. Jos säilytät kaikki nämä puhelut OLTP-palvelimellasi, löydät pian SQL Server laboring over usage Reportsin. Sinun täytyy säilyttää alkuperäisen puhelun tiedot lakisääteisen ajan, mutta voit määrittää liiketoiminnan, että ne ovat, korkeintaan, kiinnostaa vain määrä puheluita minuutissa. Sitten olet vähentänyt tallennustarvetta OLTP-palvelimella 1.4% siitä, mitä se oli, ja puhelutiedot voidaan arkistoida toiseen SQL-palvelimeen ad-hoc-kyselyjä ja asiakaslausuntoja varten. Siitä kannattaa säästää. Kuutio-ja ROLLUP-lausekkeiden avulla voit jopa tallentaa rivisummat, sarakkeen loppusummat ja suursummat ilman, että sinun tarvitsee tehdä yhteenvetotaulukon taulukkoa tai ryhmitettyä indeksiä.
niin kauan kuin näihin tietoihin ei tehdä takautuvasti muutoksia ja kaikki aikajaksot ovat täydellisiä, aggregaatteja ei tarvitse toistaa tai muuttaa aikaisempien aikajaksojen perusteella, vaikka kokonaissummat on ylikirjoitettava!.
leikitään, mutta käyttämällä AdventureWorks2012, jotta voit leikkiä mukana.
ensin luodaan gram-yhteenvetotaulukko.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
jos on olemassa (valitse * tempdb: stä.sys.taulukot, joissa nimi kuten ” #AggregationTable%”)
DROP TABLE #aggregationTable –delete the temporary table if it exist
valitse
identity(INT,1,1) AS , –so we can have a unique column
t. as region, t.name alueena, summa (yhteensä) tuloina,
päiväys (VVVV, tilauspäivä), päiväys (mm, tilauspäivä),
ryhmittely(t.name) kuten isNameGroup, –koskeeko tämä kaikkia alueita
ryhmittely(t.) Isgroup-ryhmänä,–koskeeko tämä kaikkia maanosia
ryhmittely(päiväys(VVVV, Järjestyspäivä)) isyearryhmänä,–koskeeko tämä kaikkia vuosia
ryhmittely(päiväys(mm, Järjestyspäivä)) iskuukausiryhmänä,–koskeeko tämä kaikkia kuukausia
Grouping_ID (t.name, t.,
datepart(VVVV, Järjestyspäivä),datepart (mm, järjestyspäivä)) AS ISGROUPINGROW
–onko tämä ylimääräinen ei-datarivi, joka sisältää aggregaattitiedot
INTO #AggregationTable
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON S. TerritoryID = T.TerritoryID
ryhmä t.name, t., päiväys(VVVV, Järjestyspäivä), päiväys(mm, Järjestyspäivä)
ROLLUP
|
huomaa, että lisäämme ylimääräisiä ”bittisiä” sarakkeita, jotka kertovat, mitkä rivit sisältävät yhteenvetorivit. Jos vahingossa lisätä ne muihin aggregations saat joitakin vakavasti paisutettu tuloksia. Et voi käyttää Grouping() tai Grouping_ID tallennettuun tulokseen, ilmeisesti, joten sinun pitäisi tarjota jotain sen sijaan.
nyt voidaan tuottaa pivotaulukko hyvin nopeasti
|
1
2
3
4
5
6
7
8
9
10
11
12
13
div>14 15
16
17
8
|
— nyt voidaan luoda yksinkertainen pivotaulukko riveineen ja
— sarakkeen loppusummat
valitse alue,
sum(CASE WHEN 2005 THEN revenue ELSE 0 END) AS ,
sum(CASE WHEN 2006 THEN revenue ELSE 0 END) AS ,
sum(CASE WHEN 2007 THEN revenue ELSE 0 END) AS ,
sum(CASE WHEN 2008 THEN revenue ELSE 0 END) AS ,
sum(revenue ELSE 0 END) AS,
sum(revenue ELSE 0 END) AS,
sum(revenue) AS
sum(revenue) AS
FROM #AggregationTable
where ISGROUPINGROW =0
group by territory
Union all
select ”total”, sum (case when 2005 then revenue else 0 end) as,
sum (case when 2006 then revenue else 0 end) as,
sum (case when 2007 then revenue else 0 end) as,
sum (case when 2007 then revenue else 0 end) as ,
sum(CASE WHEN 2008 THEN revenue ELSE 0 END) AS ,
sum(revenue) AS
FROM #AggregationTable
WHERE isYearGroup =0 and isMonthGroup=1
|
div>
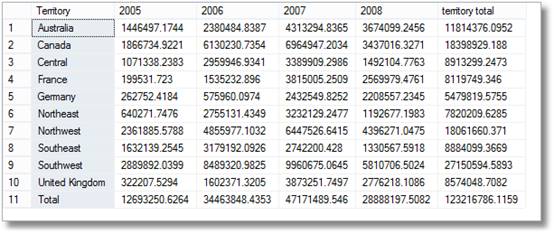
joten managereilta tulee lyhyitä hymähdyksiä tämän nähdessään, mutta sitten he kirkkaasti sanovat ” Olen varma, että pyysin myös erittelyä alueittain kuukaudessa
lyhyellä hekotuksella, sinä teet tämän.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
25
26
div>27 28
29
30
31
32
|
SELECT
datename(MONTH,dateadd(MONTH, dateadd(MONTH,, ”01 dec 2000”)) AS,
sum(CASE territory WHEN ”Australia” THEN revenue ELSE 0 END) AS,
sum(CASE territory WHEN ”Canada” THEN revenue ELSE 0 END) AS,
sum(CASE territory WHEN ”Canada” THEN revenue ELSE 0 END) AS,
sum(CASE territory WHEN ”Canada” THEN revenue ELSE 0 END) AS,
sum(CASE territory WHEN ”Canada” THEN revenue ELSE 0 END) Central ”then revenue else 0 end) as,
sum(Case Territory when ”France” then revenue else 0 end) as,
sum (case Territory when ”Germany” then revenue else 0 end) as,
sum (case Territory when ”Northeast” then revenue else 0 end) as,
sum (case Territory when ”Northeast” then revenue else 0 end) as,
sum (case Territory when ”Northeast” then revenue else 0 end) WHEN ”Northwest” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Southeast” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Southwest” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”United Kingdom” THEN revenue ELSE 0 END) AS ,
sum(revenue) AS
Sum(revenue) as
FROM #AggregationTable
where ISGROUPINGROW =0
group by month
Union all
select
”Total”,
sum(Case Territory when ”Australia” then revenue else 0 end) as,
sum (Case Territory when ”Australia” then revenue else 0 end) ”Canada” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Central” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”France” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Germany” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Northeast” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Northeast” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Northeast” THEN revenue ELSE 0 END) AS ,
sum(CASE territory WHEN ”Northwest” then revenue else 0 end) as ,
sum (case Territory when ”Southeast” then revenue else 0 end) as,
sum (case Territory when ”Southeast” then revenue else 0 end) as,
sum(CASE territory WHEN”United Kingdom”THEN revenue ELSE 0 END) AS ,
sum(revenue) AS
FROM #AggregationTable
WHERE isGroupingrow =0
|
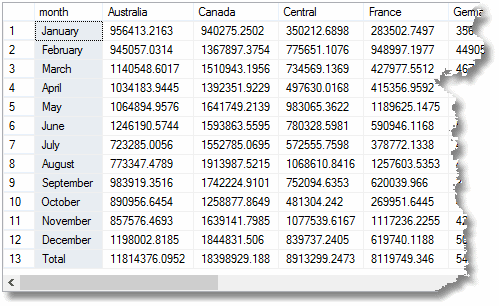
mutta jos olisi käyttänyt kuutiota Rollupin sijaan, se viimeinen ”kokonaisrivi” olisi jo laskettu. Todellinen esimerkki, joka maksaisi aikaa raportin tekemiseen. Voit tehdä kuution jopa kymmenen mitat; vaikka ne yleensä irtotavarana ylös aggregaatiota, ne eivät ole liian kalliita.
ovatko nämä SQL-standardin mukaisia vai vain Microsoftin juttuja?
nämä ovat nyt ANSI-standardin mukaisia SQL-versioita vuodelta 1999, joskin Cuben ja ROLLUPIN kanssa Microsoft esitteli ne ensimmäisen kerran. Tämä sisällyttäminen on hieman yllättävää, että ne otetaan käyttöön toinen merkitys, ”Kaikki”, että NULL arvo lisäksi ”tuntematon”. Kun Microsoft esitteli ensimmäisen kerran Cuben ja ROLLUPIN, syntaksi oli hieman erilainen, mutta molemmat muodot ovat sallittuja SQL Server-käyttöjärjestelmässä. Yksittäisessä select-lausekkeessa voidaan käyttää vain yhtä syntaksityyliä, ja kaikissa uusissa töissä tulee käyttää ISO-yhteensopivaa syntaksia.
Voinko jättää yhden tai useamman sarakkeen pois rullauksesta?
Jos haluat! Kuvitelkaa, etten halunnut superkokonaisuutta kaikille alueille (t.)
|
1
2
3
4
5
6
|
valitse t. alueena t.name alueena, summa(TotalDue) tuloina,
päiväys(VVVV, Tilauspäivitys) AS , päiväys (mm, Tilauspäivitys) AS
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON S. TerritoryID = T. TerritoryID
ryhmä t., ROLLUP (t.name, datepart(VVVV, Järjestyspäivä), datepart (mm, Järjestyspäivä))
|
tässä käytetään ANSI SQL 2006-yhteensopivaa syntaksia. Saman voi tehdä kuutiolla. En ole koskaan löytänyt tälle käytännöllistä käyttöä, mutta saatat törmätä siihen
mitkä ovat RYHMITTELYSARJAT sitten? Pitäisikö minun tietää heistä?
RYHMITTELYJOUKKO tarkoittaa, että pyydät SQL: ää ryhmittelemään tuloksen useita kertoja. RYHMITTELYASETUSTEN syntaksin avulla voit määrittää tarkasti, mitkä aggregaatit lasketaan. Tässä on esimerkki.
|
1
2
3
4
5
6
|
valitse t. alueena t.name alueena, summa(TotalDue) tuloina,
päiväys(VVVV, Tilauspäivitys) AS , päiväys (mm, Tilauspäivitys) AS
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON s.TerritoryID = T. TerritoryID
ryhmä t., RYHMITTELYJOUKOT (ROLLUP(t.name),
ROLLUP(päiväys(VVVV, Järjestyspäivä), päiväys(mm, Järjestyspäivä))
|
tässä pyydetään alueryhmittäin jaottelua kunkin vuoden jokaiselta kuukaudelta kuukausi-ja vuosisummineen, joita seuraa Yhteenveto alueen nimi, mutta ilman loppusummaa. Toisin kuin ROLLUP, saat saman tuloksen riippumatta siitä, missä järjestyksessä sarakkeet kussakin RYHMITTELYJOUKOSSA ja RYHMITTELYJOUKOISSA.
RYHMITTELYSARJOILLA voi saada juuri sen, mitä kuutio ja ROLLUP antavat ja paljon muutakin. Kuten viimeksi mainitussa esimerkissä näkyy, voit käyttää vakiomuotoisia ” table d ’hôte” -kuutioita ja ROLLUPIA sekoitettuna suoraan ilmaistuihin ”à la carte” – RYHMITTELYSARJOIHIN.
miksi haluamme yhdistää sarakkeita mihinkään aggregaatioon?
Jos joissakin raporteissa on yhdistettävä kaksi saraketta, on hyödyllistä ilmoittaa yhdistelmä, joka yhdistää kaksi saraketta. Ensimmäisessä esimerkissä yhdistämme käyttöönottovuoden ja – kuukauden, jolloin loppusummat rajoittuvat vain kuhunkin alueeseen,
|
1
2
3
4
5
6
7
|
–get the totals for each Territories only-no totals for kukin alue tai vuosi
valitse t. kuten alue, t.nimi alueena, summa(TotalDue) tuloina,
päiväys(VVVV, Tilauspäivitys) AS , päiväys (mm, Tilauspäivitys) AS
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON S. TerritoryID = T. TerritoryID
GROUP BY t. t.name, ROLLUP
((päiväys (VVVV, Järjestyspäivä), päiväys (mm, Järjestyspäivä))
|
tämä KÄYTTÖÖNOTTOLAUSEKKEEN lisäluokka on rajoittanut aggregaatiot koskemaan vain aluetta ja kuukautta/vuotta. Jos jätät ne pois, saat summat jokaiselta vuodelta.
|
1
2
3
4
5
6
7
8
9
10
|
Tämä voi olla erittäin hyödyllistä tiettyjen tietojen osalta. Olemme välttäneet kolonnien yhdistämisen täällä. Jos tekisit kuution, ja alueiden termeissä käytettäisiin sanoja ”Pohjoinen” tai ”eteläinen” kuvaamaan aluetta useammalla kuin yhdellä alueella, sinulla olisi joitakin outoja aggregaatioita, jotka pätevät ”pohjoisiin” alueisiin, jotka eivät liity toisiinsa. Yhdistämällä sarakkeet, voit välttää tämän.
onko sarjojen ryhmittelyssä muutakin kuin tapa tehdä ”à la carte” – kuutioita?
en ole varma, ujostelisinko kysyä tätä kysymystä. SQL:1999: n ryhmittely asetetaan tarjota rikas rekursiivinen syntaksi, jonka avulla voit koota yhdistelmiä sarakkeita ja määritellä kaikenlaisia esoteerinen raportit tarjoavat jopa kymmenen ulottuvuutta. Aggregaatit voidaan pesiä ja voit pesä kuutiot sisällä ROLLUPs ja pesä ROLLUPs sisällä kuutiot. Sinun täytyy lukea asiantuntija julkaisu lisätietoja tästä.
miksi funktiot ryhmittely() ja Grouping_ID() annetaan?
ei kannata käyttää nollia osoittamaan, että sarake on aggregaatti. Ongelma on se, että jos ryhmittelysarake sisältää nolla-arvot, kaikki nolla-arvot katsotaan samanarvoisiksi ja laitetaan yhteen NOLLARYHMÄÄN, joka naamioituu yhteenvedoksi. Jotta voidaan kiertää alkuperäisen aineiston ilmeinen vaikeus, annetaan kaksi funktiota: ryhmittely () ja Grouping_ID().
Grouping() funktio ohittaa ROLLUP -, kuutio-tai RYHMITYSJOUKKOON osallistuneen sarakkeen nimen. Se palauttaa nollan, jos tämä rivi on tämän sarakkeen yhteenveto, jonka arvo on nolla Eli ”kaikki”, tai jos se sisältää arvon.
GROUPING_ID-funktiolle annetaan lista, jonka on vastattava tarkasti ryhmän lauseketta luetteloittain. GROUPING_ID luodaan bittikarttana vastaavista yhteenvetosarakkeista. Jos esimerkiksi territorio-sarakkeessa on Noll-merkitys ”kaikilla” alueilla eikä alueen nimi, ja se on lueteltu toisena sarakkeena, asetetaan toinen bitti vasemmalta. Tämä kokonaisluku palautetaan.
Grouping_ID() käytetään yleensä ilmaisemaan, onko rivi primaarinen vai sekundaarinen aggregaatio (0 tai >0), ja jos> 0), ja jos>, jätetään se manipuloimalla pois muista ryhmistä.
hyvinä käytäntöinä pidetään yleensä sitä, että jokaiselle ulottuvuudelle (kuten”Territory”tai” Region ”esimerkissämme), joka on asetettu, jos rivi on kyseisen ulottuvuuden Yhteenveto, lisätään Grouping_ID() arvo, joka auttaa tuloksen ryhmittelyssä.
havainnollistaaksemme tapaa, jolla Grouping_ID todella toimii, tässä saamme tarkastella tapaa, jolla Grouping_ID: n bitit asetetaan yhteenvedon tyypin mukaan. Käytämme Phil Factorin tobinarystring-toimintoa näyttääksemme osat.
|
1
2
3
4
5
6
7
8
9
|
valitse t. alueena t.nimi alueena, summa(TotalDue) tuloina,
päiväys(VVVV, Järjestyspäivä) AS , päiväys (mm, Järjestyspäivä) AS ,
right (
dbo.ToBinaryString (–listaa kaikki ryhmät erittäin, koska ne ovat
Grouping_ID(t. t.name, päiväys (VVVV, tilauspäivä), päiväys(mm,tilauspäivä))
), 4) AS –just use the last four characters as we have four columns in our list.
myynnistä.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T ON s. TerritoryID = T. TerritoryID
ryhmä kuutioittain(t., t.name, datepart(VVVV, OrderDate),datepart(mm, OrderDate))
|
Tämä antaa (vain näytteen tietenkin)…