- Eh? Hvad er gruppering SET, CUBE og ROLLUP?
- hvorfor ville ROLLUP eller CUBE være nyttigt for mig?
- er disse standard SDL eller er de en Microsoft-eneste ting?
- kan jeg ekskludere en eller flere kolonner fra ROLLUP?
- hvad er gruppering sæt derefter? Skal jeg vide om dem?
- hvorfor vil vi kombinere kolonner i enhver aggregering?
- er der mere ved gruppering af sæt end en måde at gøre ‘Kurt la carte’ terninger på?
- hvorfor stilles funktionerne gruppering() og Gruppering_id () til rådighed?
- Eh? Hvad er gruppering SET, CUBE og ROLLUP?
- hvorfor ville ROLLUP eller CUBE være nyttigt for mig?
- er disse standard SDL eller er de en Microsoft-eneste ting?
- kan jeg ekskludere en eller flere kolonner fra ROLLUP?
- Hvad er GRUPPERINGSSÆT da? Skal jeg vide om dem?
- hvorfor vil vi kombinere kolonner i enhver aggregering?
- er der mere ved gruppering af sæt end en måde at gøre ‘Kurt la carte’ terninger på?
- hvorfor stilles funktionerne gruppering() og Gruppering_id () til rådighed?
Eh? Hvad er gruppering SET, CUBE og ROLLUP?
CUBE, ROLLUP og gruppering sæt er valgfri operatører af gruppe efter klausul i SELECT-sætningen for at gøre rapporter med store mængder information. De giver dig mulighed for at udføre flere grupper efter operationer i en erklæring, hvilket potentielt sparer en masse tid og beregningsindsats. De kan give alle de oplysninger, der er nødvendige for rapportering, herunder totaler, samtidig med at de giver god ydeevne over store tabeller og hjælper Forespørgselsoptimeren med at udarbejde en god eksekveringsplan.
de ekstra ‘super-aggregerede’ rækker giver oversigtsværdier, hvorved du kan have flere ‘aggregeringer’ såsom SUM() eller maks() inden for det ene resultat. Nullerne inden for disse rækker i resultatet er beregnet til at betyde ‘alt’ snarere end ‘ukendt’. Det giver dig mulighed for at få alle de aggregeringer, du har brug for i en passage gennem bordet. På grund af tilstedeværelsen af ekstra rækker i resultaterne leveres ekstra funktioner GROUPING() og GROUPING_ID() for at angive disse ekstra ‘super-aggregerede’ rækker, og hvilke kolonner der aggregeres.
dette giver stor mening, hvis du har et program, der skal køre flere rapporter uden ekstra beregning eller uden at gå tilbage til databasen: du har alt hvad du behøver i et resultat.
Tag Dette standardeksempel på en ROLLUP (jeg bruger Eventyrværk 2012 her)..
|
1
2
3
4
5
6
|
vælg t. som region, t.name som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på S. Territoriyid = T. Territoriyid
gruppe af t., t.navn, datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate)
med ROLLUP
|
samt den enkle gruppe efter Samlede rækker med det samlede forfaldne for hver måned, som du får med en simpel gruppering, får du også subtotal eller super-aggregerede rækker, og også en grand total række. (her er begyndelsen på resultatet)
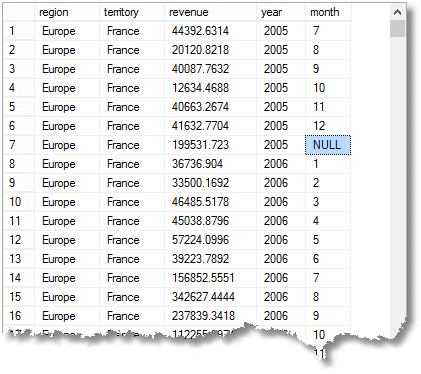
at NULL jeg har highlit betyder, at rækken er et aggregat for ‘alle’ måneder af 2005 i Frankrig (del af Europa-regionen)
ud over alt dette får du det samlede forfaldne beløb for hvert år, for hvert territorium og territorial gruppe samt det fulde forfaldne beløb. (fra slutningen)
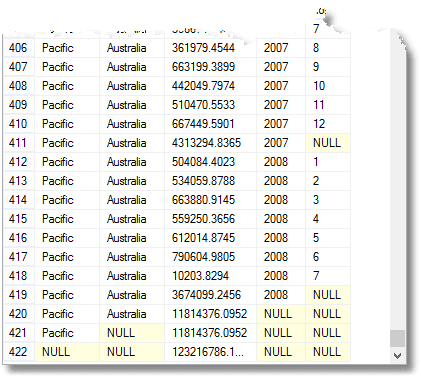
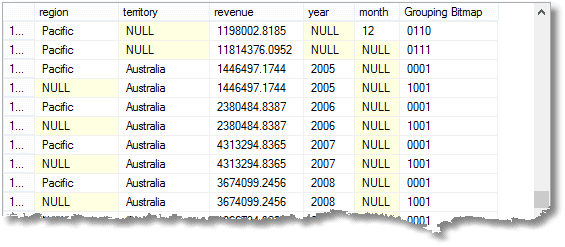
disse nuller betyder ‘Alle’, husk. Den sidste række er det samlede beløb, og over det er det samlede beløb for Stillehavsområdet. Oven i det er Australiens Bidrag til Stillehavsområdet. Den fjerde række fra bunden er Australiens bidrag fra 2008. Antallet af grupperinger, der returneres, er en mere end antallet af udtryk i listen over sammensatte elementer, der leveres til gruppen ved sætning.
for at få den samme effekt uden at bruge rollup, skal du gøre noget som dette (Eventyrarbejder2012)
|
1
2
3
4
5
6
8
9
10
11
12
13
14
15
17
18
29
21
|
;
med myGrouping (region, territorium, totalDue,,)
AS (Vælg t., t.name, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på S. Territoriyid = T. Territoriyid
gruppe efter t.name, t., datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate))
vælg Region, territorium, totalDue, ,
fra myGrouping
UNION alle
vælg Region, territorium, sum(totalDue), , NULL
fra myGrouping gruppe efter Region, territorium,
UNION alle
div> vælg region, territorium, sum(totaldue), null, null
fra mygrouping gruppe efter region, territorium
union alle
vælg region, null, sum(TOTALDUE), null, null
fra mygrouping gruppe efter region
Union alle
vælg null, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‘GROUPBY ROLLUP (t.,t.navn, datepart (ÅÅÅÅ, OrderDate), datepart(mm, OrderDate))’
|
denne nye syntaks giver dig nogle ekstra funktionalitet. Husk også, at kolonnerækkefølgen påvirker outputgrupperingerne af ROLLUP og kan påvirke antallet af rækker i resultatsættet.
kuben gør det samme generelle, men i stedet for at give et hierarki af totaler i ordnede superaggregerede rækker giver den alle ‘superaggregerede’ permutationer (‘symmetriske superaggregerede’ rækker), de såkaldte tværtabulationsrækker. Hvis du ønskede at vide, hvilket område der gav flest ordrer i marts, eller hvilket område der fungerede mindst godt i 2006, så ville du have brug for en terning. Du giver alle de mulige summeringer i resultatet.
gruppering sæt giver dig mulighed for at finjustere dit resultat til at give mere specialiserede oplysninger ud over CUBE. Det kan give sammenfattende oplysninger om kombinationer af dimensioner. Du kan få nøjagtigt det samme resultat som i vores ROLLUP-eksempel ved at bruge GRUPPERINGSSÆT, men med meget mere indtastning.
|
1
2
3
4
5
6
7
8
10
|
vælg t. som region, t.name som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s. TerritoryID = T.TerritoryID
gruppe efter gruppering sæt (
(T., T.name, datepart(ÅÅÅÅ, OrderDate), datepart (mm, OrderDate)),
(T., T.name, datepart (ÅÅÅÅ, OrderDate) ),
(T., T.name),
(T.),
())
|
Dette er bare for at vise, hvordan de forholder sig. I virkeligheden vil du ty til gruppering af sæt for at få resultater, der er umulige med ROLLUP eller CUBE.
næsten alle disse oversigter kan opnås ved at bruge Just GROUP BY, men kun ved gentagne gange at gruppere resultatet af en gruppe efter eller ved at få mere end en til at passere dataene.
når du bruger CUBE -, ROLLUP-eller GRUPPERINGSSÆT, kan du ikke bruge det særskilte søgeord i dine samlede udtryk, f. eks. AVG (distinkt kolonnenavn), COUNT (distinkt kolonnenavn) og SUM (distinkt kolonnenavn)
hvorfor ville ROLLUP eller CUBE være nyttigt for mig?
ROLLUP og CUBE havde deres storhedstid før SSA ‘ er. De var nyttige til at levere den samme slags faciliteter, der tilbydes af cube i OLAP. Det har dog stadig sine anvendelser. Det er overkill, men hvis du håndterer store datamængder, skal du kun videregive dine data en gang og gøre så meget som muligt på data, der er samlet. Begivenheder, der skete i fortiden, kan ikke ændres, så det er sjældent nødvendigt at opbevare Historiske data på et aktivt OLTP-system. I stedet behøver du kun at opbevare de aggregerede data på det detaljeringsniveau (‘granularitet’), der kræves for alle forudsigelige rapporter.
Forestil dig, at du er ansvarlig for at rapportere om en telefonkontakt, der har to millioner opkald om dagen. Hvis du beholder alle disse opkald på din OLTP-server, finder du snart, at serveren arbejder over brugsrapporter. Du skal opbevare de originale opkaldsoplysninger i en lovbestemt periode, men du bestemmer ud fra virksomheden, at de højst kun er interesseret i antallet af opkald på et minut. Derefter har du reduceret dit lagringskrav på OLTP-serveren til 1.4% af hvad det var, og opkaldsposterne kan arkiveres til en anden server for ad hoc-forespørgsler og kundeerklæringer. Det er sandsynligvis en besparelse værd at gøre. Cube-og ROLLUP-klausulerne giver dig mulighed for endda at gemme rækketotaler, kolonnetotaler og hovedtotaler uden at skulle foretage en tabel eller grupperet indeks, scanning af oversigtstabellen.
så længe ændringer ikke foretages med tilbagevirkende kraft til disse data, og alle tidsperioder er færdige, behøver du aldrig at gentage eller ændre aggregeringerne baseret på tidligere tidsperioder, selvom store totaler skal overskrives!.
lad os foregive, men ved hjælp af Eventyrarbejder2012, så du kan spille sammen.
for det første opretter vi gram-oversigtstabellen.
|
1
2
3
4
5
6
7
8
10
11
12
13
14
15
16
17
18
|
hvis der findes (vælg * fra tempdb.sys.tabeller, hvor navn som ‘ #AggregationTable%’)
DROP TABLE #aggregationTable-slet den midlertidige tabel,hvis den findes
vælg
identitet(INT,1, 1) som, – så vi kan have en unik kolonne
t. som region, t.name som territorium, sum (TotalDue) som omsætning,
datepart (ÅÅÅÅ, OrderDate) AS, datepart (mm, OrderDate) AS ,
gruppering(t.name) som isNameGroup, — vedrører dette alle territorier
gruppering(t.) Som isGroupGroup, – vedrører dette alle kontinenter
gruppering(datepart(ÅÅÅÅ, OrderDate)) som isYearGroup, – vedrører dette Alle år
gruppering(datepart(mm, OrderDate)) som isMonthGroup, – vedrører dette alle måneder
Gruppering_id (t.name, t.,
datepart(ÅÅÅÅ,OrderDate), datepart(mm, OrderDate)) som isgruppering
–er dette en ekstra ikke-datarække, der indeholder aggregerede data
i #AggregationTable
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s. TerritoryID = T.Territorieid
gruppe efter t.name, t., datepart (ÅÅÅÅ, OrderDate), datepart(mm, OrderDate)
med ROLLUP
|
Bemærk, at vi tilføjer ekstra ‘bit’ kolonner, der fortæller os, hvilke rækker der indeholder de sammenfattende rækker. Hvis du fejlagtigt tilføjer dem til yderligere aggregeringer, får du nogle alvorligt oppustede resultater. Du kan ikke bruge Grouping() eller Grouping_ID på det gemte resultat, selvfølgelig, så du burde give noget i stedet.
nu kan vi producere pivottabellen meget hurtigt
|
1
2
3
4
5
6
8
10
11
12
13
14
15
16
17
18
|
— nu kan vi oprette en simpel pivottabel med række og
— kolonne totaler
vælg område,
sum(tilfælde, hvor 2005 derefter indtægter ellers 0 ende) AS,
sum(tilfælde, hvor 2006 derefter indtægter ellers 0 ende) AS,
sum(tilfælde, hvor 2007 derefter indtægter ellers 0 ende) AS,
sum(tilfælde, hvor 2008 derefter indtægter ellers 0 ende) AS,
sum(omsætning) som
fra #AggregationTable
hvor ERGRUPPERING =0
gruppe efter område
Union alle
vælg ‘total’, sum(sag når 2005 derefter indtægter ellers 0 ende) som,
sum(sag når 2006 derefter indtægter ellers 0 ende) som,
sum(sag når 2007 derefter indtægter ellers 0 ende) som ,
sum(tilfælde, hvor 2008 derefter indtægter ellers 0 ende) som,
sum(omsætning) som
fra #AggregationTable
hvor isYearGroup =0 og isMonthGroup=1
|
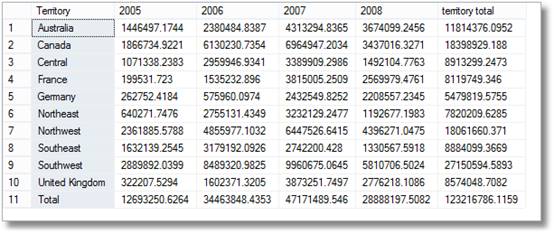
så der er korte smil fra lederne om at se dette, men så siger de Lyst ‘jeg er sikker på, at jeg også bad om en opdeling efter territorium pr.
|
1
2
3
4
5
6
7
8
10
11
12
13
14
15
16
17
18
20
21
22
23
24
25
26
27
28
29
30
31
32
|
vælg
datename(måned,dateadd(måned, ,’01 dec 2000′)) AS ,
sum(sagsområde, når ‘Australien’ derefter indtægter ellers 0 ende) AS,
sum(sagsområde, når ‘Central’ ‘derefter indtægter ellers 0 ende) som,
sum(sagsområde, når’ Frankrig ‘derefter indtægter ellers 0 ende) som,
sum(sagsområde, når’ Tyskland ‘derefter indtægter ellers 0 ende) som,
sum(sagsområde, når’ nordøst ‘derefter indtægter ellers 0 ende) som,
sum(sagsområde Når ‘nordvest’ derefter indtægter ellers 0 ende) som ,
sum(sagsområde når ‘sydøst’ derefter indtægter ellers 0 ende) som ,
sum(sagsområde når ‘sydvest’ derefter indtægter ellers 0 ende) som ,
sum(sagsområde når ‘Det Forenede Kongerige’ derefter indtægter ellers 0 ende) som ,
sum(omsætning) som
fra #AggregationTable
hvor =0
gruppe efter måned
Union alle
vælg
‘i alt’,
sum(sagsområde når ‘Australien’ derefter indtægter ellers 0 ende) som ,
sum(sagsområde, når ‘Australien’ derefter indtægter ellers 0 ende) som,
sum (sagsområde, når ‘Canada’ derefter indtægter ellers 0 ende) AS ,
sum(sagsområde når ‘Central’ derefter indtægter ellers 0 ende) AS ,
sum(sagsområde når ‘Frankrig’ derefter indtægter ellers 0 ende) AS ,
sum(sagsområde når ‘Tyskland’ derefter indtægter ellers 0 ende) AS ,
sum(sagsområde når ‘nordøst’ derefter indtægter ellers 0 ende) AS ,
sum(sagsområde når ‘Tyskland’ derefter indtægter ellers 0 ende) as ,
sum(sagsområde når ‘nordøst’ derefter indtægter ellers 0 ende) AS ,
sum(sagsområde når ‘nordøst’ derefter indtægter ellers 0 ende) AS ,
sum (sagsområde når ‘nordøst’ derefter indtægter ellers 0 ende) som,
sum (sagsområde når ‘sydøst’ derefter indtægter ellers 0 ende) som,
sum (sagsområde når ‘sydvest’ derefter indtægter ellers 0 ende) som,
sum(sagsområde, når ‘Det Forenede Kongerige’ derefter indtægter ellers 0 ende) som,
sum(omsætning) som
fra #AggregationTable
hvor ergruppering =0
|

men hvis du havde brugt CUBE i stedet for Rollup, ville den sidste ‘samlede’ række allerede beregnes. I et reelt eksempel, der ville koste tid at gøre rapporten. Du kan lave en terning på op til ti dimensioner; selvom de har tendens til at samle aggregeringen, er de ikke for dyre.
er disse standard SDL eller er de en Microsoft-eneste ting?
disse er nu standard ANSI kvm fra 1999, dog med CUBE og med ROLLUP blev først introduceret af Microsoft. Denne optagelse er noget overraskende, fordi de introducerer en anden betydning, ‘alle’, for nulværdien udover ‘ukendt’. Da Microsoft først introducerede CUBE og ROLLUP, syntaksen var lidt anderledes, men begge former er tilladt i cube Server. Kun en syntaksstil kan bruges i en enkelt SELECT-sætning, og du skal bruge den ISO-kompatible syntaks til alt nyt arbejde.
kan jeg ekskludere en eller flere kolonner fra ROLLUP?
Hvis du vil! Forestil dig, at jeg ikke ønskede en super-samlet total for alle regionerne (t.)
|
1
2
3
4
5
6
|
vælg t. som region, t.name som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s. Territoriyid = T. Territoriyid
gruppe af t., ROLLUP (t.name, datepart (ÅÅÅÅ, OrderDate), datepart(mm, OrderDate))
|
Her bruger vi den syntaks, der er kompatibel med ANSI 2006. Du kan gøre det samme med en terning. Jeg har aldrig fundet en praktisk anvendelse til dette, men du kan komme på tværs af det
Hvad er GRUPPERINGSSÆT da? Skal jeg vide om dem?
gruppering sæt betyder, at du beder os om at gruppere resultatet flere gange. Du kan bruge syntaksen GRUPPERINGSSÆT til at specificere nøjagtigt, hvilke aggregeringer der skal beregnes. Her er et eksempel.
|
1
2
3
4
5
6
|
vælg t. som region, t.name som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s.Territorieid = T. Territorieid
gruppe efter t., gruppering sæt(ROLLUP(t.name),
ROLLUP(datepart(ÅÅÅÅ, OrderDate), datepart(mm, OrderDate)))
|
Her beder du om opdeling efter territoriumgruppe for hver måned i hvert år med måneds-og årstotaler efterfulgt af en summarisk total af territorium navn, men uden en samlet sum. I modsætning til ROLLUP får du det samme resultat uanset rækkefølgen af kolonnerne inden for hvert GRUPPERINGSSÆT og rækkefølgen af GRUPPERINGSSÆT.
gruppering sæt kan give dig præcis, hvad CUBE og ROLLUP giver dig og meget mere udover. Som du kan se med dette sidste eksempel, kan du bruge standard ‘table d’ h kristite ‘terning og ROLLUP blandet sammen med direkte udtrykte ‘Kristi la carte’ gruppering sæt.
hvorfor vil vi kombinere kolonner i enhver aggregering?
hvor to kolonner skal kombineres i nogle rapporter, er det nyttigt at erklære en aggregering, der kombinerer to kolonner. I det første eksempel kombinerer vi år og måned for rollup, der har den virkning at begrænse totalerne til bare hvert område,
|
1
2
3
4
5
6
|
–få kun totalerne for hvert område – nej totaler for hver region eller år
Vælg t. som region, t.navn som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s. Territoriyid = T. Territoriyid
gruppe af t., t.name, ROLLUP
((datepart (ÅÅÅÅ, OrderDate), datepart (mm, OrderDate)))
|
den ekstra beslag i SAMMENSÆTNINGSKLAUSULEN har haft den virkning at begrænse aggregeringerne til kun territoriet og måneden / året. Lad dem ud, og du får totaler for hvert år.
|
1
2
3
4
5
6
8
9
10
|
–få totalerne for hvert år inden for hvert område samt totalerne
–for hvert område
— ingen totaler for hver region
Vælg t. som region, t.navn som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s. Territoriyid = T. Territoriyid
gruppe af t., t.name, ROLLUP
(datepart(ÅÅÅÅ, OrderDate), datepart (mm, OrderDate))
|
dette kan være meget nyttigt for visse data. Vi har undgået at skulle kombinere kolonner her. Hvis du skulle lave en terning, og udtrykkene for territorier brugte ordene som ‘nordlig’ eller ‘sydlig’ til at beskrive et område i mere end en region, ville du have nogle bisarre aggregeringer, der gælder for ‘nordlige’ territorier, der ikke er relateret. Ved at kombinere kolonner ville du undgå dette.
er der mere ved gruppering af sæt end en måde at gøre ‘Kurt la carte’ terninger på?
Jeg er ikke sikker på, at jeg ville være genert over at stille dette spørgsmål. SQL:1999S GRUPPERINGSSÆT giver en rig rekursiv syntaks, der giver dig mulighed for at samle kombinationer af kolonner og definere alle mulige esoteriske rapporter, der giver op til ti dimensioner. Aggregeringerne kan indlejres, og du kan indlejre terninger inden for ROLLUPs og nest ROLLUPs inden for CUBEs. Du bliver nødt til at læse en specialpublikation for at finde ud af mere om dette.
hvorfor stilles funktionerne gruppering() og Gruppering_id () til rådighed?
det er ikke rigtig en god ide at bruge NULL til at betegne, at en kolonne er en aggregering. Problemet er, at hvis en grupperingskolonne indeholder null-værdier, betragtes alle null-værdier som ens og placeres i en enkelt NULL-gruppe, der maskerer sig som en oversigt. For at omgå den åbenlyse vanskelighed med nulværdier i de originale data leveres to funktioner: gruppering() og Grouping_ID().
Grouping() funktionen er bestået navnet på en kolonne, der deltog i ROLLUP, CUBE eller gruppering sæt. Det returnerer nul, hvis denne række er en oversigt for denne kolonne med en NULL-værdi, der betyder ‘alle’, eller om den indeholder en værdi.
funktionen GROUPING_ID er bestået en liste, der nøjagtigt skal matche udtrykket i gruppen efter liste. GROUPING_ID oprettes som en bitmap for de respektive oversigtskolonner. Hvis for eksempel områdekolonnen har en NULL, der betyder ‘alle’ territorier snarere end et navn på et område, og det er angivet som den anden kolonne, indstilles den anden bit fra venstre. Dette heltal returneres derefter.
Grouping_ID() bruges generelt til at angive, om rækken er en primær eller sekundær aggregering (0 eller>0) og, hvis sekundær, derefter udelukket fra enhver yderligere gruppe ved manipulation.
det betragtes normalt som god praksis at medtage en bitkolonne for hver dimension (såsom ‘territorium’ eller ‘Region’ i vores eksempel), der er indstillet, hvis rækken er en oversigt for den dimension sammen med enGrouping_ID() værdi for at hjælpe enhver yderligere gruppering af resultatet.
for at illustrere den måde, som Grouping_ID rent faktisk virker, får vi her at se på, hvordan bitene i Grouping_ID er indstillet i henhold til typen af Oversigt. Vi bruger Phil Factors funktion ToBinaryString til at vise bitene.
|
1
2
3
4
5
6
7
8
9
|
vælg t. som region, t.navn som territorium, sum (TotalDue) som omsætning,
datepart(ÅÅÅÅ, OrderDate) som , datepart(mm, OrderDate) som ,
højre (
dbo.ToBinaryString (–liste alle gruppen efter elementer, som de er
Grouping_ID (t., t.name, datepart (ÅÅÅÅ, OrderDate), datepart(mm,OrderDate))
), 4) AS-brug bare de sidste fire tegn, da vi har fire kolonner på vores liste.
fra salg.SalesOrderHeader s
indre JOIN salg.SalesTerritory T på s. Territoriyid = T. Territoriyid
gruppe efter terning (t., t.navn, datepart(ÅÅÅÅ, OrderDate),datepart(mm, OrderDate))
|
dette giver (bare en prøve selvfølgelig)…