datamodellering er processen med at dokumentere et komplekst systemdesign som et let forståeligt diagram ved hjælp af tekst og symboler til at repræsentere den måde, data skal strømme på. Diagrammet kan bruges til at sikre effektiv brug af data, som en plan for konstruktion af nye programmer eller til Re-engineering af en ældre applikation.
datamodellering er en vigtig færdighed for dataforskere eller andre, der er involveret i dataanalyse. Traditionelt er der bygget datamodeller under analyse-og designfaserne i et projekt for at sikre, at kravene til en ny applikation er fuldt ud forstået. Datamodeller kan også påberåbes senere i datalivscyklussen for at rationalisere datadesign, der oprindeligt blev oprettet af programmører på ad hoc-basis.
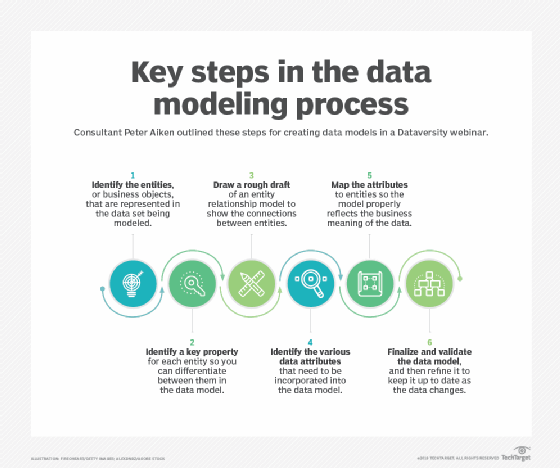
datamodelleringsmetoder
datamodellering kan være en omhyggelig forudgående proces og ses som sådan undertiden som i strid med hurtige udviklingsmetoder. Da agil programmering er kommet i bredere brug for at fremskynde udviklingsprojekter, tilpasses efter-the-fact metoder til datamodellering i nogle tilfælde. Typisk kan en datamodel betragtes som et rutediagram, der illustrerer forholdet mellem data. Det gør det muligt for interessenter at identificere fejl og foretage ændringer, før der er skrevet nogen programmeringskode. Alternativt kan modeller introduceres som en del af reverse engineering-indsatsen, der udtrækker modeller fra eksisterende systemer, som det ses med Noskl-data.
datamodeller bruger ofte flere modeller til at se de samme data og sikre, at alle processer, enheder, relationer og datastrømme er blevet identificeret. De igangsætter nye projekter ved at indsamle krav fra forretningsinteressenter. Datamodelleringsfaser nedbrydes groft til oprettelse af logiske datamodeller, der viser specifikke attributter, enheder og relationer mellem enheder og den fysiske datamodel.
den logiske datamodel tjener som grundlag for oprettelse af en fysisk datamodel, som er specifik for den applikation og database, der skal implementeres. En datamodel kan danne grundlag for at opbygge et mere detaljeret dataskema.
hierarkisk datamodellering
datamodellering som en disciplin begyndte at opstå i 1960 ‘ erne, der ledsagede opsvinget i brug af datamodellering, som en disciplin, der databasestyringssystemer (dbmses). Datamodellering gjorde det muligt for organisationer at bringe konsistens, repeterbarhed og velordnet udvikling til databehandling. Applikations slutbrugere og programmører var i stand til at bruge datamodellen som reference i kommunikation med datadesignere.hierarkiske datamodeller, der opstiller data i treelike, en-til-mange arrangementer markerede disse tidlige bestræbelser og erstattede filbaserede systemer i mange populære brugssager. IBMs informationsstyringssystem (IMS) er et primært eksempel på den hierarkiske tilgang, der fandt bred anvendelse i virksomheder, især inden for bankvirksomhed. Selvom hierarkiske datamodeller stort set blev afløst-begyndende i 1980 ‘ erne-af relationelle datamodeller, er den hierarkiske metode stadig almindelig i dag. Netværksdatamodeller opstod også i de tidlige dage af DBMSes som et middel til at give datadesignere et bredt konceptuelt syn på deres systemer. Et sådant eksempel er konferencen om Datasystemsprog (CODASYL), som blev dannet i slutningen af 1950 ‘ erne for at guide udviklingen af et standard programmeringssprog, der kunne bruges på tværs af forskellige typer computere.
relationel datamodellering
mens det reducerede programkompleksitet versus filbaserede systemer, krævede den hierarkiske model stadig detaljeret forståelse af den specifikke fysiske datalagring, der blev anvendt. Foreslået som et alternativ til den hierarkiske datamodel kræver den relationelle datamodel ikke, at udviklere definerer dataveje. Relationel datamodellering blev først beskrevet i et teknisk papir fra 1970 af IBM-forsker E. F. Codd. Codds relationelle model sætter scenen for industriens brug af relationelle databaser, hvor datasegmenter eksplicit er forbundet med brug af tabeller sammenlignet med den hierarkiske model, hvor data implicit er sammenføjet. Kort efter starten blev den relationelle datamodel kombineret med struktureret forespørgselssprog og begyndte at få et stadig større fodfæste inden for enterprise computing som et effektivt middel til at behandle data.
entity relationship model
relationel datamodellering tog endnu et skridt fremad, der begyndte i midten af 1970 ‘ erne, da brugen af entity relationship (er) modeller blev mere udbredt. Tæt integreret med relationelle datamodeller bruger ER-modeller diagrammer til grafisk at skildre elementerne i en database og for at lette forståelsen af underliggende modeller.
med relationel modellering bestemmes datatyper og ændres sjældent over tid. Enheder omfatter attributter; for eksempel kan en medarbejderenheds attributter omfatte efternavn, fornavn, år ansat og så videre. Relationer er visuelt kortlagt, giver en klar måde at kommunikere data design mål til forskellige deltagere i data udvikling og vedligeholdelse. Over tid fik modelleringsværktøjer, herunder Ideras ER/Studio, Ervin Data Modeler og SAP-designer, bred anvendelse blandt dataarkitekter til design af systemer.
da objektorienteret programmering fik plads i 1990 ‘ erne, fik objektorienteret modellering trækkraft som endnu en måde at designe systemer på. Mens de ligner ER-metoder, adskiller objektorienterede tilgange sig ved, at de fokuserer på objektabstraktioner af virkelige enheder. Objekter grupperes i klassehierarkier, og objekterne i sådanne klassehierarkier kan arve attributter og metoder fra overordnede klasser. På grund af denne arvstræk har objektorienterede datamodeller nogle fordele i forhold til ER-modellering med hensyn til at sikre dataintegritet og understøtte mere komplekse datarelationer. Også opstået i 1990 ‘ erne var datamodeller specifikt orienteret mod datalagringsbehov. Bemærkelsesværdige eksempler er snefnug skema og stjerne skema dimensionelle modeller.
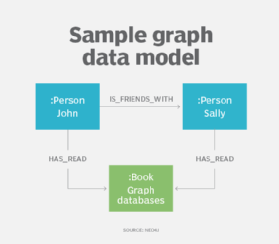
Graph data models
en udløber af hierarkisk og netværksdatamodellering er property graph-modellen, som sammen med grafdatabaser har fundet øget anvendelse til at beskrive komplekse forhold inden for datasæt, især i applikationer til social media, recommender og fraud detection.
Ved hjælp af grafdatamodellen beskriver designere deres system som en tilsluttet graf over noder og relationer, ligesom de kan gøre med ER-eller objektdatamodellering. Graph data modeller kan bruges til tekstanalyse, skabe modeller, der afdækker relationer mellem datapunkter i dokumenter.