strukturen af DNA tilvejebringer en mekanisme til arvelighed
gener bærer biologisk information, der skal kopieres nøjagtigt til transmission til næste generation hver gang en celle deler sig for at danne to datterceller. To centrale biologiske spørgsmål stammer fra disse krav: Hvordan kan informationen til angivelse af en organisme bæres i kemisk form, og hvordan kopieres den nøjagtigt? Opdagelsen af strukturen af DNA – dobbeltspiralen var et vartegn i det tyvende århundredes biologi, fordi det straks foreslog svar på begge spørgsmål og derved løste på molekylært niveau problemet med arvelighed. Vi diskuterer kort svarene på disse spørgsmål i dette afsnit, og vi vil undersøge dem mere detaljeret i de efterfølgende kapitler.
DNA koder information gennem rækkefølgen eller sekvensen af nukleotiderne langs hver streng. Hver base-A, C, T eller G—kan betragtes som et bogstav i et alfabet med fire bogstaver, der præciserer biologiske meddelelser i DNA ‘ ets kemiske struktur. Som vi så I kapitel 1, adskiller organismer sig fra hinanden, fordi deres respektive DNA-molekyler har forskellige nukleotidsekvenser og følgelig bærer forskellige biologiske meddelelser. Men hvordan bruges nukleotidalfabetet til at lave meddelelser, og hvad staver de ud?
som diskuteret ovenfor var det kendt godt før DNA-strukturen blev bestemt, at gener indeholder instruktionerne til fremstilling af proteiner. DNA-meddelelserne skal derfor på en eller anden måde kode proteiner (figur 4-6). Dette forhold gør straks problemet lettere at forstå på grund af proteinernes kemiske karakter. Som diskuteret i kapitel 3 bestemmes egenskaberne af et protein, som er ansvarlig for dets biologiske funktion, af dets tredimensionelle struktur, og dets struktur bestemmes igen af den lineære sekvens af de aminosyrer, som det er sammensat af. Den lineære sekvens af nukleotider i et gen skal derfor på en eller anden måde stave den lineære sekvens af aminosyrer i et protein. Den nøjagtige korrespondance mellem DNA-nukleotidalfabet med fire bogstaver og proteinets aminosyrealfabet med tyve bogstaver-den genetiske kode—er ikke åbenlyst fra DNA—strukturen, og det tog over et årti efter opdagelsen af dobbeltspiralen, før den blev udarbejdet. I kapitel 6 beskriver vi denne kode i detaljer i løbet af udarbejdelsen af processen, kendt som genekspression, hvorigennem en celle oversætter nukleotidsekvensen af et gen til aminosyresekvensen af et protein.

figur 4-6
forholdet mellem genetisk information båret i DNA og proteiner.
det komplette sæt information i en organisms DNA kaldes dets genom, og det bærer informationen for alle de proteiner, organismen nogensinde vil syntetisere. (Udtrykket genom bruges også til at beskrive det DNA, der bærer denne information.) Mængden af information indeholdt i genomer er svimlende: for eksempel indeholder en typisk human celle 2 meter DNA. Skrevet ud i nukleotidalfabet med fire bogstaver optager nukleotidsekvensen af et meget lille humant gen en fjerdedel af en side med tekst (figur 4-7), mens den komplette sekvens af nukleotider i det menneskelige genom ville fylde mere end tusind bøger på størrelse med denne. Ud over andre kritiske oplysninger bærer den instruktionerne for omkring 30.000 forskellige proteiner.

figur 4-7
nukleotidsekvensen af det humane reloglobin-gen. Dette gen bærer informationen for aminosyresekvensen af en af de to typer underenheder af hæmoglobinmolekylet, som bærer ilt i blodet. Et andet gen, den Kris-globin (mere…)
Ved hver celledeling skal cellen kopiere sit genom for at overføre det til begge datterceller. Opdagelsen af DNA-strukturen afslørede også det princip, der gør denne kopiering mulig: fordi hver DNA-streng indeholder en sekvens af nukleotider, der er nøjagtigt komplementær til nukleotidsekvensen af dens partnerstreng, kan hver streng fungere som en skabelon eller form til syntese af en ny komplementær streng. Med andre ord, hvis vi betegner de to DNA-strenge som S og S’, kan streng s tjene som en skabelon til fremstilling af en ny streng S’, mens streng S’ kan tjene som en skabelon til fremstilling af en ny streng S (figur 4-8). Således kan den genetiske information i DNA kopieres nøjagtigt ved den smukt enkle proces, hvor streng s adskiller sig fra streng S’, og hver adskilt streng fungerer derefter som en skabelon til produktion af en ny komplementær partnerstreng, der er identisk med dens tidligere partner.
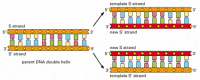
figur 4-8
DNA som en skabelon til sin egen duplikering. Da nukleotid A kun parres med T og G med C, kan hver DNA-streng specificere sekvensen af nukleotider i dens komplementære streng. På denne måde kan dobbelt-spiralformet DNA kopieres nøjagtigt. (mere…)
evnen af hver streng af et DNA-molekyle til at fungere som en skabelon til fremstilling af en komplementær streng gør det muligt for en celle at kopiere eller replikere sine gener, før de overføres til sine efterkommere. I det næste kapitel beskriver vi det elegante maskineri, som cellen bruger til at udføre denne enorme opgave.