- Eh? Co jsou seskupení SET, CUBE a kumulativní v SQL?
- proč by ROLLUP nebo CUBE být užitečné pro mě?
- Jsou to standardní SQL nebo jsou to věc pouze pro Microsoft?
- mohu vyloučit jeden nebo více sloupců z kumulativního souboru?
- jaké jsou seskupovací sady? Mám o nich vědět?
- proč bychom chtěli Kombinovat sloupce v jakékoli agregaci?
- existuje více seskupování sad než způsob, jak dělat „à la carte“ kostky?
- proč jsou k dispozici funkce seskupování() a Grouping_ID ()?
- Eh? Co jsou seskupení SET, CUBE a kumulativní v SQL?
- Proč by ROLLUP nebo KOSTKU být užitečné pro mě?
- jsou to standardní SQL nebo jsou to věc pouze pro Microsoft?
- mohu vyloučit jeden nebo více sloupců z kumulativního souboru?
- co jsou seskupení sady pak? Mám o nich vědět?
- proč bychom chtěli Kombinovat sloupce v jakékoli agregaci?
- existuje více seskupování sad než způsob, jak dělat „à la carte“ kostky?
- proč jsou k dispozici funkce seskupování() a Grouping_ID ()?
Eh? Co jsou seskupení SET, CUBE a kumulativní v SQL?
KRYCHLE, ROLLUP, a SESKUPENÍ NASTAVENÍ jsou volitelné provozovatelé klauzuli GROUP BY příkazu SELECT pro dělat zprávy s velkým množstvím informací. Umožňují provádět několik skupin podle operací v jednom příkazu, což potenciálně ušetří spoustu času a výpočetního úsilí. Oni vám může poskytnout všechny informace potřebné pro podávání zpráv, včetně součtů, přičemž dobrý výkon na velkých stolech, a pomáhá Optimalizátor Dotaz vymyslet dobrý plán vykonání.
další řádky „superagregate“ poskytují souhrnné hodnoty, což vám umožní mít několik „agregací“, jako je SUM() nebo MAX() v rámci jednoho výsledku. Nuly v těchto řádcích ve výsledku mají znamenat “ vše „spíše než „neznámé“. To vám umožní získat všechny agregace, které potřebujete, v jednom průchodu tabulkou. Protože přítomnosti další řádky ve výsledcích, extra funkce GROUPING()GROUPING_ID() jsou poskytovány uveďte tyto další ‚super-aggregate‘ řádky a sloupce, které jsou agregovány.
To dělá hodně smysl, pokud máte aplikaci, která musí běžet několik zpráv bez dodatečných výpočtů, nebo bez návratu do databáze: máte vše, co potřebujete v jeden výsledek.
Vezměte si tento standardní příklad kumulativního(používám AdventureWorks 2012 zde)..
|
1
2
3
4
5
6
|
VYBRAT t. JAKO region, t.jméno JAKO území, sum(TotalDue) JAKO příjem,
datepart(rrrr, Datumobjednávky) JAKO části řetězce datepart(mm, Datumobjednávky)
Z Prodeje.SalesOrderHeader s
INNER JOIN Sales.Prodejúzemí T na s. Teritoryid = T. Teritoryid
skupina t., t.jméno, datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky)
AKTUALIZACI
|
stejně Jako jednoduché SKUPINY agregované řádky, celková splatná za každý měsíc, že byste si s jednoduchým seskupení, můžete také získat mezisoučet nebo super-agregované řádky, a také celkem.řádku. (zde je začátek výsledku)
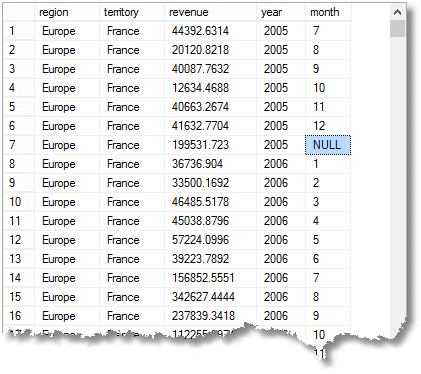
NULL jsem highlit znamená, že řádek je souhrnný pro všechny měsíce roku 2005 ve Francii (část Evropy, regionu)
stejně Jako tohle všechno, dostaneš celková splatná za každý rok, pro každé území a územní skupiny, stejně jako plná celková splatná. (od konce)
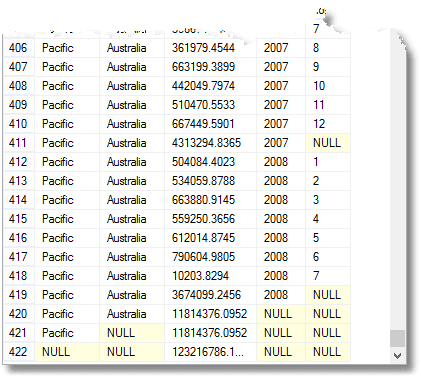
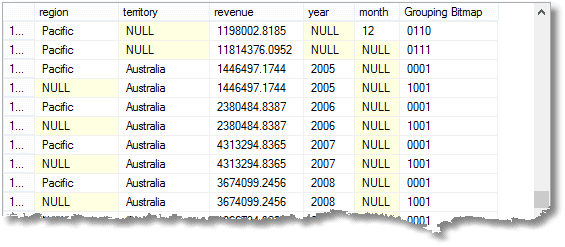
tyto nuly znamenají „vše“, pamatujte. Poslední řádek je celkový součet a nad ním je součet pro tichomořskou oblast. Nad tím je příspěvek Austrálie do tichomořského regionu. Čtvrtou řadou zdola je příspěvek Austrálie z roku 2008. Počet vrácených seskupení je o jeden více než počet výrazů v seznamu složených prvků poskytnutých skupině příkazem.
získat stejný efekt bez použití této kumulativní aktualizace, budete muset udělat něco jako tohle (AdventureWorks2012)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
;
S myGrouping ( region, území, totalDue, , )
(SELECT t., t.název, sum(TotalDue) JAKO příjem,
datepart(rrrr, Datumobjednávky) JAKO části řetězce datepart(mm, Datumobjednávky)
Z Prodeje.SalesOrderHeader s
INNER JOIN Sales.Prodejúzemí t na s. Teritoryid = T. Teritoryid
skupina podle t.name, T., datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky))
VYBERTE Region, území, totalDue, ,
OD myGrouping
UNIE
VYBERTE Region, území, sum(totalDue), , NULL
OD myGrouping SKUPINY PODLE Regionu, území,
UNIE
VYBERTE Region, území, sum(totalDue), NULL, NULL
OD myGrouping SKUPINY PODLE Regionu, území
UNIE
VYBERTE Region, NULL, sum(totalDue), NULL, NULL
OD myGrouping SKUPINY PODLE regionů
UNIE
SELECT NULL, NULL, sum(totalDue), NULL, NULL
FROM myGrouping
|
Which is a lot more expensive in CPU and I/O. Note that the standard syntax of the GROUP BY clause in recent versions is
|
1
2
|
…
‚GROUPBY ROLLUP (t.,t.jméno,datepart(rrrr,Datumobjednávky),datepart(mm,Datumobjednávky))‘
|
Tato nová syntaxe umožňuje některé další funkce. Nezapomeňte také, že pořadí sloupců ovlivňuje výstupní seskupení kumulativních hodnot a může ovlivnit počet řádků v sadě výsledků.
KRYCHLE dělá to samé obecné věci, ale místo toho poskytuje hierarchii hodnot v objednané super-agregované řádky, to poskytuje všechny super-celkové permutace (‚symetrické super-agregát řádků), tzv. cross-tabulation řádky. Pokud byste chtěli vědět, které území dalo v březnu nejvíce objednávek, nebo které území fungovalo nejméně dobře v roce 2006, pak byste potřebovali kostku. Poskytujete všechny možné součty ve výsledku.
seskupení SET umožňuje doladit výsledek poskytnout více specializované informace nad a za krychle. Může poskytnout souhrnné informace o kombinacích rozměrů. Můžete získat přesně stejný výsledek jako v našem kumulativním příkladu pomocí seskupování sad, ale s mnohem více psaní.
|
1
2
3
4
5
6
7
8
9
10
|
VYBRAT t. JAKO region, t.jméno JAKO území, sum(TotalDue) JAKO příjem,
datepart(rrrr, Datumobjednávky) JAKO části řetězce datepart(mm, Datumobjednávky)
Z Prodeje.SalesOrderHeader s
INNER JOIN Sales.Prodejúzemí T na s. Teritoryid = T.TerritoryID
SKUPINA SESKUPENÍ SAD(
(T, T jméno,datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky)),
(T, T jméno,datepart(rrrr, Datumobjednávky) ),
(T., T. název)
(T),
())
|
Tohle je jen ukázat, jak se vztahují. Ve skutečnosti byste se uchýlili k seskupování sad, abyste získali výsledky, které nejsou možné s kumulativním nebo krychlovým.
téměř všechny tyto souhrny lze získat použitím pouze skupiny podle, ale pouze opakovaným seskupením výsledku skupiny podle nebo provedením více než jednoho průchodu daty.
Pokud používáte KRYCHLE, ROLLUP nebo SESKUPENÍ SAD, můžete použít klíčové slovo DISTINCT ve své souhrnné výrazy, jako například AVG (DISTINCT jméno_sloupce), COUNT (DISTINCT jméno_sloupce), a SUM (DISTINCT jméno_sloupce)
Proč by ROLLUP nebo KOSTKU být užitečné pro mě?
ROLLUP a CUBE měli svůj rozkvět před SSA. Byly užitečné pro poskytování stejného druhu zařízení, které nabízí cube v OLAPU. Stále má své využití ačkoli. V AdventureWorks je to přehnané, ale pokud zpracováváte velké objemy dat, musíte svá data předat pouze jednou a udělat co nejvíce na agregovaných datech. Události, které se staly v minulosti, nelze změnit, takže je zřídka nutné uchovávat Historická data v aktivním systému OLTP. Místo toho musíte uchovávat pouze agregované údaje na úrovni podrobností („zrnitost“) požadované pro všechny předvídatelné zprávy.
Představte si, že jste zodpovědní za hlášení na telefonním přepínači, který má dva miliony hovorů denně. Pokud si ponecháte všechny tyto hovory na serveru OLTP, brzy najdete SQL Server, který pracuje na přehledech využití. Musíte si ponechat původní informace o hovoru po zákonnou dobu, ale z podnikání určíte, že se nejvíce zajímají pouze o počet hovorů za minutu. Poté jste snížili požadavek na úložiště na serveru OLTP na 1.4% toho, co to bylo, a záznamy hovorů lze archivovat na jiný SQL Server Pro Ad-hoc dotazy a prohlášení zákazníků. To bude pravděpodobně úspora, která stojí za to. Klauzule CUBE a kumulativní vám umožňují dokonce ukládat součty řádků, součty sloupců a velké součty, aniž byste museli provádět skenování souhrnné tabulky nebo seskupeného indexu.
tak dlouho, Jak změny nejsou zpětně k těmto údajům, a všechny lhůty jsou kompletní, budete nikdy muset opakovat nebo změnit shluky na základě minulých období, ale celkové součty budou muset být přepsána!.
pojďme předstírat, ale pomocí AdventureWorks2012, takže si můžete hrát spolu.
nejprve vytvoříme souhrnnou tabulku gram.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
POKUD EXISTUJE (VYBERTE * Z databáze tempdb.sys.tabulky, KDE je jméno JAKO ‚#AggregationTable%‘)
DROP TABLE #aggregationTable-odstranit dočasné tabulky, pokud existuje
VYBRAT
identity(INT,1,1), … takže můžeme mít jedinečný sloupec
u. JAKO region, t.jméno JAKO území, sum(TotalDue) JAKO příjem,
datepart(rrrr, Datumobjednávky) JAKO části řetězce datepart(mm, Datumobjednávky)
seskupení(t.název) JAKO isNameGroup, –Se to vztahuje na VŠECHNA území
seskupení(t.) JAKO isGroupGroup,–Se to vztahuje na VŠECHNY kontinenty
seskupení(datepart(rrrr, Datumobjednávky)) JAKO isYearGroup,–Se to vztahuje na VŠECHNY roky
seskupení(datepart(mm, Datumobjednávky)) JAKO isMonthGroup,–se to týká VŠECH měsíců
Grouping_ID (t.jméno,t.,
datepart(rrrr, Datumobjednávky),datepart(mm, Datumobjednávky)) JAKO isGroupingRow
– je to extra non-řádek dat obsahující souhrnné údaje
DO #AggregationTable
Z Prodeje.SalesOrderHeader s
INNER JOIN Sales.Prodejúzemí T na s. Teritoryid = T.TerritoryID
SKUPINA t.jméno, t., datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky)
AKTUALIZACI
|
Všimněte si, že jsme přidávání extra ‚trochu‘ sloupce, které nám říct, které řádky obsahují souhrnné řádky. Pokud je omylem přidáte do dalších agregací, získáte nějaké vážně nafouknuté výsledky. Nelze použít Grouping() nebo Grouping_ID na uložený výsledek, samozřejmě, takže byste měli poskytnout něco místo něj.
Nyní můžeme vytvářet kontingenční tabulky velmi rychle,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
– nyní můžeme vytvořit jednoduchý kontingenční tabulka s řádek a
— součty sloupců
VYBERTE Území,
sum(PŘÍPAD, KDY ROKU 2005 PAK příjmy ELSE 0 END)
sum(PŘÍPAD, KDY ROKU 2006 PAK příjmy OSTATNÍ 0 END)
sum(PŘÍPAD, KDY ROKU 2007 PAK příjmy ELSE 0 END)
sum(PŘÍPAD, KDY ROKU 2008 PAK tržby ELSE 0 END)
sum(příjmy) JAKO
Z #AggregationTable
, KDE isGroupingrow =0
SKUPINA PODLE území
UNIE
VYBERTE „Celkem“, sum(PŘÍPAD, KDY ROKU 2005 PAK příjmy ELSE 0 END)
sum(PŘÍPAD, KDY ROKU 2006 PAK příjmy OSTATNÍ 0 END),
sum(PŘÍPAD, KDY ROKU 2007 PAK příjmy ELSE 0 END) JAKO ,
sum(PŘÍPAD, KDY ROKU 2008 PAK tržby ELSE 0 END)
sum(příjmy) JAKO
Z #AggregationTable
, KDE isYearGroup =0 A isMonthGroup=1
|
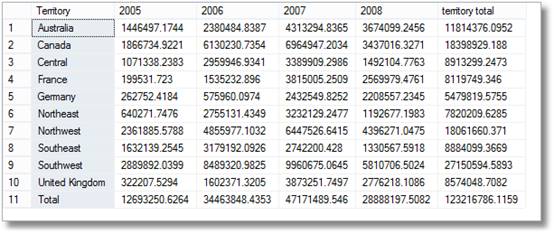
takže od manažerů jsou krátké úsměvy, když to vidí, ale pak jasně řeknou :“jsem si jistý, že jsem také požádal o rozdělení podle území za měsíc
s krátkým smíchem, uděláte to.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
VYBRAT
datename(MONTH,dateadd(MĚSÍC, ,’01 dec 2000′))
sum(CASE území, KDYŽ „Austrálie“ PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Kanada“ PAK příjmy ELSE 0 END),
sum(CASE území, KDYŽ „Střed“ PAK příjmy OSTATNÍ 0 END)
sum(CASE území, KDY „Francie“ PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Německo“ PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Severovýchod“, PAK příjmy OSTATNÍ 0 END),
sum(CASE území KDYŽ ‚Northwest‘, PAK příjmy OSTATNÍ 0 END)
sum(CASE území, KDYŽ ‚Jihovýchodní‘, PAK příjmy ELSE 0 END)
sum(CASE území PŘI Jihozápadní PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Spojené Království“, PAK příjmy ELSE 0 END)
sum(příjmy) JAKO
Z #AggregationTable
, KDE isGroupingrow =0
seskupit PODLE měsíce
UNIE
VYBRAT
‚Celkem‘,
sum(CASE území, KDYŽ „Austrálie“ PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Kanada“, PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Střed“ PAK příjmy OSTATNÍ 0 END)
sum(CASE území, KDY „Francie“ PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Německo“ PAK příjmy ELSE 0 END),
sum(CASE území, KDYŽ „Severovýchod“, PAK příjmy OSTATNÍ 0 END)
sum(CASE území PŘI Severozápad PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ ‚Jihovýchodní‘, PAK příjmy ELSE 0 END)
sum(CASE území PŘI Jihozápadní PAK příjmy ELSE 0 END)
sum(CASE území, KDYŽ „Spojené Království“, PAK příjmy ELSE 0 END)
sum(příjmy) JAKO
Z #AggregationTable
, KDE isGroupingrow =0
|
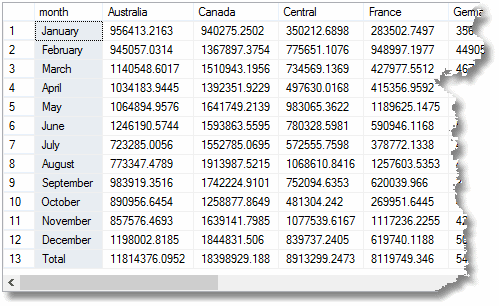
ale pokud byste použili CUBE místo kumulativní, že poslední ‚celkem‘ řádek by již být vypočtena. Ve skutečném příkladu, který by stál čas dělat zprávu. Můžete udělat kostku až na deset rozměrů; i když mají tendenci hromadně agregaci, nejsou příliš nákladné.
jsou to standardní SQL nebo jsou to věc pouze pro Microsoft?
Jedná se nyní o standardní ANSI SQL z roku 1999, ačkoli s CUBE a s kumulativní byly poprvé představeny společností Microsoft. Toto zahrnutí je poněkud překvapivé v tom, že zavádí druhý význam, „vše“, pro nulovou hodnotu kromě „neznámé“. Když Microsoft poprvé představil CUBE a kumulativní, syntaxe byla mírně odlišná, ale obě formy jsou povoleny v SQL Serveru. V jediném příkazu SELECT lze použít pouze jeden styl syntaxe a pro všechny nové práce byste měli použít syntaxi kompatibilní s ISO.
mohu vyloučit jeden nebo více sloupců z kumulativního souboru?
Pokud chcete! Představte si, že jsem nechtěla, super-úhrnu pro všechny regiony (t.)
|
1
2
3
4
5
6
|
VYBRAT t. JAKO region, t.jméno JAKO území, sum(TotalDue) JAKO příjem,
datepart(rrrr, Datumobjednávky) JAKO části řetězce datepart(mm, Datumobjednávky)
Z Prodeje.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T NA s.TerritoryID = T. TerritoryID
SKUPINA t., KUMULATIVNÍ (t.jméno, datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky))
|
Zde jsme pomocí ANSI SQL 2006 vyhovující syntaxi. Totéž můžete udělat s krychlí. Nikdy jsem nenašel praktické využití pro toto, ale můžete narazit na to
co jsou seskupení sady pak? Mám o nich vědět?
seskupování znamená, že žádáte SQL o seskupení výsledku několikrát. Pomocí syntaxe seskupování sad můžete přesně určit, které agregace se mají vypočítat. Zde je příklad.
|
1
2
3
4
5
6
|
VYBRAT t. JAKO region, t.jméno JAKO území, sum(TotalDue) JAKO příjem,
datepart(rrrr, Datumobjednávky) JAKO části řetězce datepart(mm, Datumobjednávky)
Z Prodeje.SalesOrderHeader s
INNER JOIN Sales.Prodejúzemí T na s.TerritoryID = T. TerritoryID
SKUPINA t., SESKUPENÍ SAD(KUMULATIVNÍ(t.název)
AKTUALIZACI(datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky)))
|
Tady, žádáte o členění podle území skupina pro každý měsíc, každý rok s měsíc a rok součty, následuje shrnutí celkem o území název, ale bez celkem. Na rozdíl od kumulativní, dostanete stejný výsledek bez ohledu na pořadí sloupců v každé seskupení sady a pořadí seskupení sady.
seskupování sady vám může dát přesně to, co krychle a kumulativní vám dává a mnohem více Kromě. Jak můžete vidět, že tento poslední příklad, můžete použít standardní tabulky d ‚hote‘ CUBE a ROLLUP smíchány s přímo-vyjádřil ‚à la carte ‚SESKUPENÍ Sad.
proč bychom chtěli Kombinovat sloupce v jakékoli agregaci?
Pokud by měly být v některých přehledech sloučeny dva sloupce, je vhodné deklarovat agregaci, která kombinuje dva sloupce. V prvním příkladu jsme se spojit rok a měsíc, pro aktualizace, které mají za následek omezení součty jen každé území,
|
1
2
3
4
5
6
7
|
–součty pro každé území pouze celkové součty pro každý region nebo rok
VYBRAT t. JAKO region, t.název jako území, součet (TotalDue) jako výnos,
datepart (rrrr, OrderDate) AS, datepart (mm, OrderDate) AS
z prodeje.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T NA s.TerritoryID = T. TerritoryID
SKUPINA t., t.jméno, KUMULATIVNÍ
((datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky)))
|
extra držák na AKTUALIZACI ustanovení má za následek omezení agregace na území a měsíc/rok. Vynechejte je a dostanete součty za každý rok.
|
1
2
3
4
5
6
7
8
9
10
|
–součty pro každý rok v rámci každého území, stejně jako součty
– pro každé území
— bez součtů pro každý region
VYBRAT t. JAKO region, t.název jako území, součet (TotalDue) jako výnos,
datepart (rrrr, OrderDate) AS, datepart (mm, OrderDate) AS
z prodeje.SalesOrderHeader s
INNER JOIN Sales.SalesTerritory T NA s.TerritoryID = T. TerritoryID
SKUPINA t., t.jméno, KUMULATIVNÍ
(datepart(rrrr, Datumobjednávky), datepart(mm, Datumobjednávky))
|
To může být velmi užitečné pro některé údaje. Vyhnuli jsme se nutnosti Kombinovat sloupce zde. Pokud jste měli udělat KOSTKU, a podmínky území, používá slova jako ‚Severní“ nebo „Jižní‘ k popisu území ve více než jedné oblasti, budete mít nějaké bizarní shluky, které se vztahují k ‚severní území, které nesouvisí. Kombinací sloupců byste se tomu vyhnuli.
existuje více seskupování sad než způsob, jak dělat „à la carte“ kostky?
Nejsem si jistý, že bych se styděl položit tuto otázku. SQL:1999 seskupování sady poskytují bohatou rekurzivní syntaxi, která vám umožní agregovat kombinace sloupců a definovat všechny druhy esoterických zpráv poskytuje až deset rozměrů. Agregace mohou být vnořeny a můžete hnízdit kostky v ROLLUPs a hnízdo ROLLUPs v kostkách. Budete si muset přečíst odbornou publikaci, abyste se o tom dozvěděli více.
proč jsou k dispozici funkce seskupování() a Grouping_ID ()?
není vhodné použít NULL k označení, že sloupec je agregace. Problém je v tom, že pokud sloupec seskupení obsahuje hodnoty null, jsou všechny hodnoty null považovány za stejné a vloženy do jedné skupiny NULL, která se maskuje jako souhrn. Chcete-li obejít zjevnou obtížnost nulových hodnot v původních datech, jsou k dispozici dvě funkce: seskupení() a Grouping_ID().
funkce Grouping() předává název sloupce, který se podílel na kumulativní, krychlové nebo seskupovací sadě. Vrátí nulu, pokud je tento řádek souhrnem pro tento sloupec s hodnotou NULL, což znamená “ Vše “ nebo zda obsahuje hodnotu.
funkce GROUPING_ID je předána seznamu, který musí přesně odpovídat výrazu ve skupině podle seznamu. GROUPING_ID je vytvořen jako bitmapa příslušných souhrnných sloupců. Pokud má například sloupec území nulový význam „všechna“ území, nikoli název území, a je uveden jako druhý sloupec, pak je nastaven druhý bit zleva. Toto celé číslo je pak vráceno.
Grouping_ID() je obecně používá k označení, zda řádek je primární nebo sekundární agregace (0 nebo >0) a, pokud je to střední, pak vyloučen z případné další SKUPINY manipulací.
To je obvykle považováno za dobrou praxi, aby zahrnovala trochu sloupec pro každý rozměr (jako „Území“ nebo „Kraj“ v našem příkladu), který je nastaven v případě, že řádek je souhrn pro tento rozměr, spolu s Grouping_ID() hodnota na pomoc žádné další seskupení výsledek.
pro ilustraci způsobu, jakým Grouping_ID skutečně funguje, se zde podíváme na způsob, jakým jsou bity v Grouping_ID nastaveny podle typu souhrnu. K zobrazení bitů použijeme funkci Phil Factor.
|
1
2
3
4
5
6
7
8
9
|
VYBRAT t. JAKO region, t.název jako území, součet (TotalDue) jako výnos,
datepart (rrrr, OrderDate) AS, datepart (mm, OrderDate) AS ,
right (
dbo.ToBinaryString(–list všechny skupiny položek, jako jsou
Grouping_ID(t., t.jméno, datepart(rrrr, Datumobjednávky),datepart(mm, Datumobjednávky))
),4) – stačí použít poslední čtyři znaky, jako máme čtyři sloupce v našem seznamu.
z prodeje.SalesOrderHeader s
INNER JOIN Sales.Prodejúzemí T na s. Teritoryid = T. Teritoryid
skupina podle krychle(t., t.jméno, datepart(rrrr, Datumobjednávky),datepart(mm, Datumobjednávky))
|
To dává (jen ukázka, samozřejmě)…