
to je důležitý bod k pochopení. Nejen, že použití nesprávné metody někdy povede k tomu, že stránky nebudou z indexu odstraněny, jak bylo zamýšleno, ale může to mít také negativní vliv na SEO.
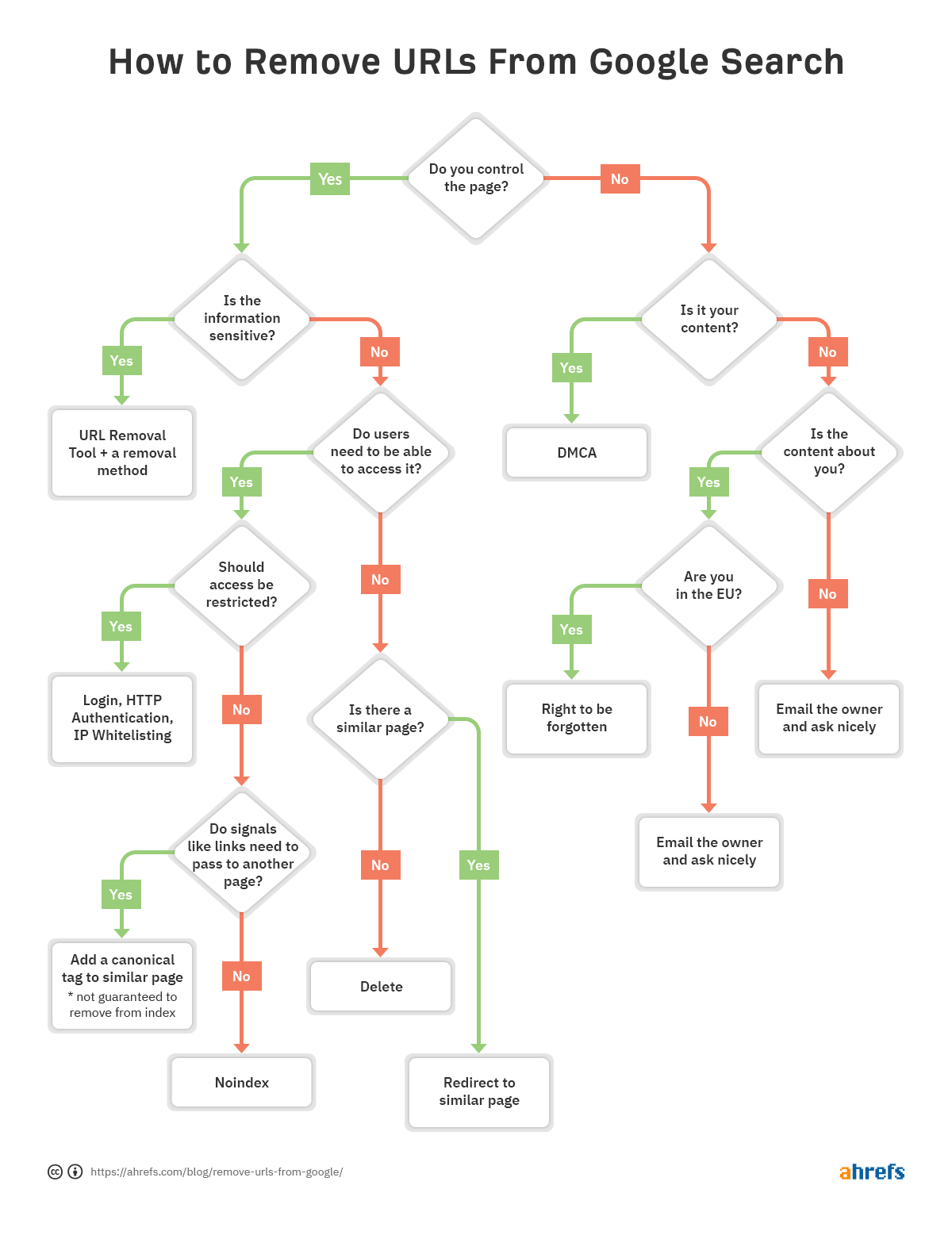
abychom vám pomohli rychle rozhodnout, který způsob odstranění je pro vás nejlepší, vytvořili jsme vývojový diagram, abyste mohli přeskočit na příslušnou část článku.
v tomto příspěvku se dozvíte:
- Jak zkontrolovat, zda URL je indexována
- Pět způsobů, jak odstranit Url z Google
- Jak upřednostnit pohlcení
- Časté odstraňování chyb, aby se zabránilo
- Jak odstranit obsah, který není na vaše stránky
- Jak odstranit obrázky
To, co jsem obvykle vidět, Seo udělat, aby zkontrolovat, zda obsah je indexován je použít stránky: hledání v Google (např. webu:https://ahrefs.com). Zatímco stránky: vyhledávání může být užitečné pro identifikaci stránky nebo části stránky, které mohou být problematické, pokud se bude zobrazovat ve výsledcích vyhledávání, musíte být opatrní, protože oni nejsou normální dotazy a vyhrál vlastně ani říct, jestli je stránka indexovaná. Mohou zobrazovat stránky, které jsou společnosti Google známy, ale to neznamená, že jsou způsobilé k zobrazení v běžných výsledcích vyhledávání bez webu: operátor.
například vyhledávání na webu může stále zobrazovat stránky, které přesměrovávají nebo jsou kanonizovány na jinou stránku. Když požádáte o konkrétní web, Google může zobrazit stránku z této domény s obsahem, názvem a popisem z jiné domény. Vezměte si například moz.com které slouží k být seomoz.org. Žádné pravidelné uživatele dotazy, které vedou na stránky, na moz.com ukáže moz.com v SERPs, zatímco site:seomoz.org ukáže seomoz.org ve výsledcích vyhledávání, jak je uvedeno níže.
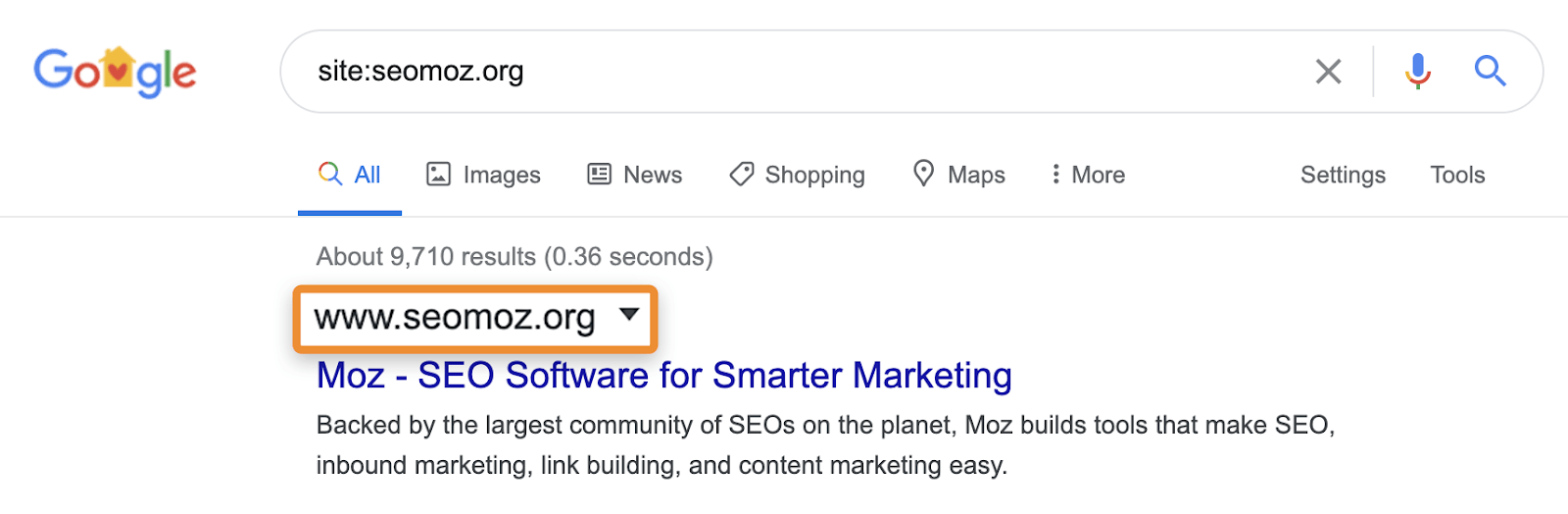
důvodem je důležité rozlišení, že může vést SEO k chybám, jako je aktivní blokování nebo odstranění adres URL z indexu staré domény, což zabraňuje konsolidaci signálů, jako je PageRank. Viděl jsem mnoho případů s domény migrace, kde si lidé myslí, že udělal chybu během migrace, protože tyto stránky stále zobrazovat na site:old-domain.com hledání a nakonec aktivně poškozuje jejich webové stránky, zatímco se snaží „opravit“ problém.
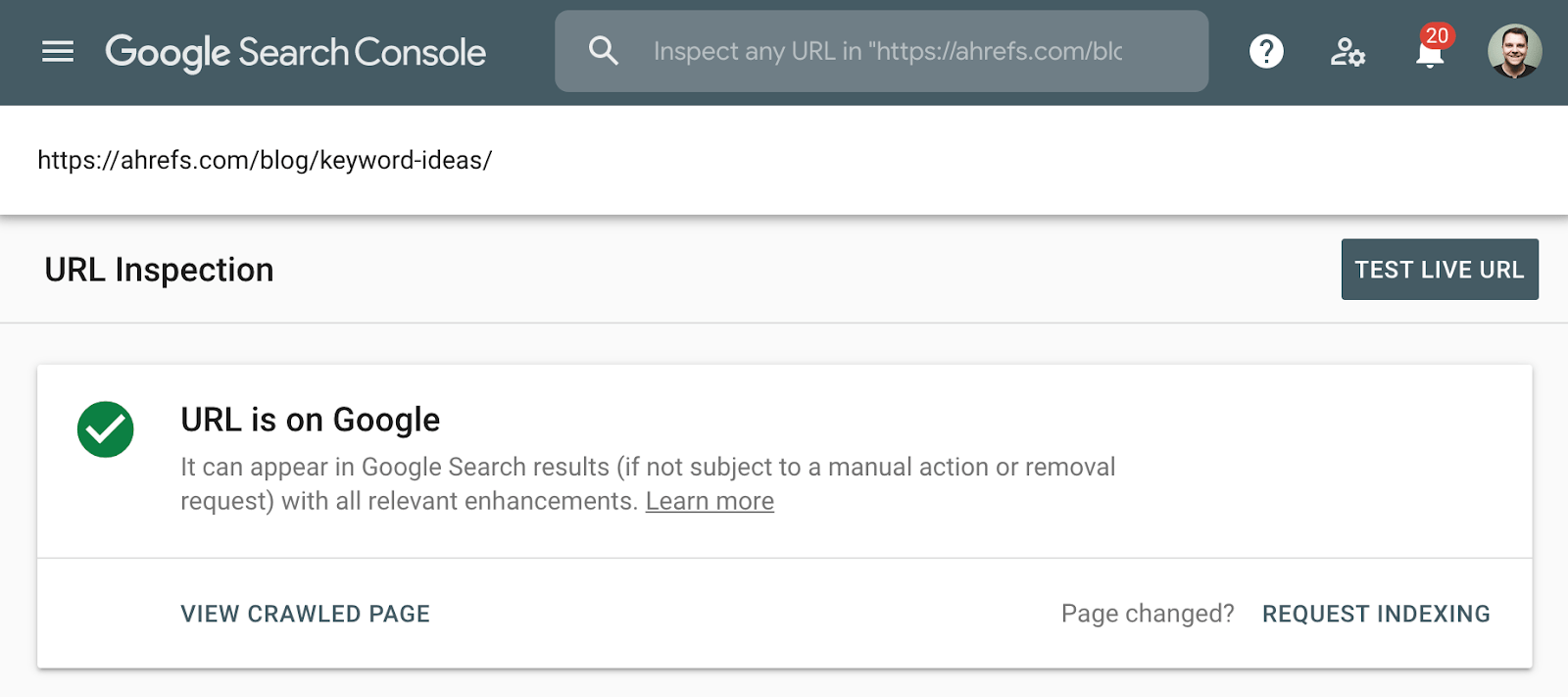
lepší metodou pro kontrolu indexace je použití zprávy o pokrytí indexů ve Vyhledávací konzoli Google nebo nástroje pro kontrolu URL pro jednotlivé adresy URL. Tyto nástroje vám řeknou, zda je stránka indexována, a poskytnou další informace o tom, jak společnost Google zachází se stránkou. Pokud k tomu nemáte přístup, jednoduše vyhledejte na Googlu úplnou adresu URL vaší stránky.
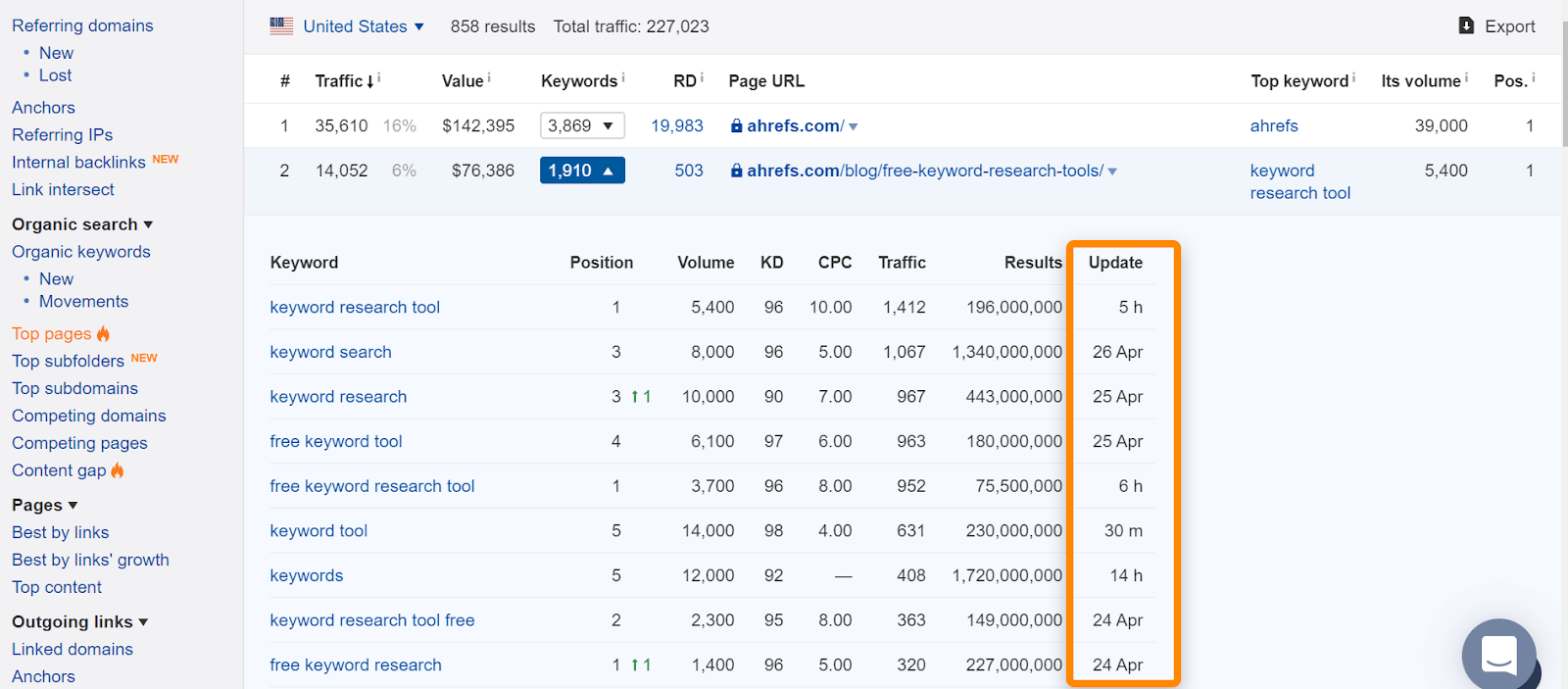
V Ahrefs, pokud najdete stránku, v našem „Top stránek“ zprávě nebo pořadí pro organické klíčová slova, to obvykle znamená, že jsme viděli, že pořadí pro normální vyhledávací dotazy, a je dobré znamení, že stránka byla indexována. Všimněte si, že stránky byly indexovány, když jsme je viděli, ale to se mohlo změnit. Zkontrolujte datum, kdy jsme naposledy viděli stránku pro dotaz.
Pokud to je problém s konkrétní URL a je třeba odstranění z indexu, postupujte podle diagramu na začátku článku najít správnou možnost odstranění, pak skok na příslušnou část níže.
Pokud stránku odstraníte a zobrazíte stavový kód 404 (Nenalezeno) nebo 410 (pryč), bude stránka z indexu odstraněna krátce po opětovném procházení stránky. Dokud nebude odstraněna, stránka se může stále zobrazovat ve výsledcích vyhledávání. A i když samotná stránka již není k dispozici, může být dočasně k dispozici verze stránky uložená v mezipaměti.
Pokud budete potřebovat jinou možnost:
- potřebuji okamžité odstranění. Viz část nástroj pro odstranění adresy URL.
- potřebuji konsolidovat signály jako odkazy. Viz část kanonizace.
- potřebuji stránku dostupnou pro uživatele. Zjistěte, zda sekce noindex nebo omezení přístupu odpovídají vaší situaci.
- možnost odstranění 2: Noindex
- Odstranění varianta 3: Omezit přístup
- možnost odstranění 4: Nástroj pro odstranění URL
- možnost Odstranění 5: Kanonizace
- Noindex v robotech.txt
- blokování procházení roboty.txt
- Nofollow
- Noindex a canonical na jinou adresu URL
- Noindex, čekat na Google plazit, pak blok z plazí
- co když je to obsah o vás, ale ne na webu, který vlastníte?
- závěr
možnost odstranění 2: Noindex
značka noindex meta robots nebo odpověď záhlaví x-robots řeknou vyhledávačům, aby odstranili stránku z indexu. Značka meta robots funguje pro stránky, kde odpověď x-robots funguje pro stránky a další typy souborů, jako jsou soubory PDF. Aby tyto značky byly vidět, vyhledávač musí být schopen procházet stránky—takže se ujistěte, že nejsou blokovány v robotech.txt. Také si všimněte, že odstranění stránek z indexu může zabránit konsolidaci odkazů a dalších signálů.
příklad meta robotů noindex:
<meta name="robots" content="noindex">
Příklad x‑robots noindex v záhlaví odezvy:
HTTP/1.1 200 OKX-Robots-Tag: noindex
, Když budete potřebovat různé možnosti:
- nechci uživatelům přístup na tyto stránky. Viz část omezení přístupu.
- potřebuji konsolidovat signály jako odkazy. Viz část kanonizace.
Odstranění varianta 3: Omezit přístup
Pokud chcete na stránku, aby byly přístupné pro některé uživatele, ale není vyhledávačů, pak to, co asi chceš, je jedním z těchto tří možností:
- nějaký přihlašovací systém;
- HTTP Autentizace (pokud je vyžadováno heslo pro přístup);
- IP Whitelisting (což umožňuje pouze určité IP adresy pro přístup na stránky)
Tento typ nastavení je nejlepší pro věci, jako je vnitřní sítě, člen pouze obsah, nebo pro pořádání, test, nebo rozvojové lokality. Umožňuje skupině uživatelů přístup na stránku, ale vyhledávače k nim nebudou mít přístup a nebudou indexovat stránky.
Pokud budete potřebovat jinou možnost:
- potřebuji okamžité odstranění. Viz část nástroj pro odstranění adresy URL. V tomto konkrétním případě možná budete chtít okamžité odstranění, pokud byl obsah, který se pokoušíte skrýt, uložen do mezipaměti a je třeba zabránit uživatelům vidět tento obsah.
možnost odstranění 4: Nástroj pro odstranění URL
název tohoto nástroje od společnosti Google je mírně zavádějící, protože způsob, jakým funguje, je, že dočasně skryje obsah. Google bude tento obsah stále vidět a procházet, ale stránky se uživatelům nezobrazí. Tento dočasný efekt trvá v Googlu šest měsíců, zatímco Bing má podobný nástroj, který trvá tři měsíce. Tyto nástroje by měly být použity v nejextrémnějších případech pro věci, jako jsou bezpečnostní problémy, úniky dat, osobní identifikační údaje (PII) atd. Pro Google použijte nástroj pro odstranění a pro Bing, viz Jak blokovat adresy URL.
stále je třeba použít jinou metodu spolu s pomocí virů nástroj, s cílem, aby skutečně mít stránky odstraněny na delší dobu (noindex nebo odstranit), nebo zabránit uživatelům v přístupu k obsahu, pokud mají odkazy (odstranit nebo omezit přístup). To vám dává rychlejší způsob skrytí stránek, zatímco odstranění má čas na zpracování. Zpracování žádosti může trvat až jeden den.
možnost Odstranění 5: Kanonizace
Když máte více verzí stránky a chcete konsolidovat signály jako odkazy na jednu verzi, co chcete udělat, je nějaká forma kanonizace. To je většinou zabránit duplicitnímu obsahu při konsolidaci více verzí stránky na jednu indexovanou adresu URL.
máte několik možností kanonizace:
- Canonical tag. To určuje jinou adresu URL jako kanonickou verzi nebo verzi, kterou chcete zobrazit. Pokud jsou stránky duplicitní nebo velmi podobné, mělo by to být v pořádku. Pokud jsou stránky příliš odlišné, kanonický může být ignorován, protože se jedná o nápovědu a nikoli o směrnici.
- přesměrování. Přesměrování vezme uživatele a vyhledávací bot z jedné stránky na druhou. 301 je nejčastěji se používá přesměrování pomocí Seo, a to říká vyhledávače, který chcete konečná adresa URL bude zobrazen ve výsledcích vyhledávání, a, kde signály jsou konsolidované. 302 nebo dočasné přesměrování říká vyhledávačům, že chcete, aby původní adresa URL zůstala v indexu a aby tam konsolidovala signály.
- zpracování parametrů URL. Parametr je přidán na konec URL a obvykle obsahuje otazník, jako ahrefs.com?to=parametr. Tento nástroj od společnosti Google umožňuje jim říct, jak k léčbě adresy Url s konkrétními parametry. Můžete například určit, zda parametr mění obsah stránky nebo zda je určen pouze ke sledování využití.
Pokud máte z indexu Google odebráno více stránek, měly by být odpovídajícím způsobem upřednostňovány.
nejvyšší priorita: tyto stránky obvykle souvisejí se zabezpečením nebo s důvěrnými údaji. To zahrnuje obsah, který obsahuje osobní údaje (PII), údaje o zákaznících nebo informace o vlastnictví.
Střední priorita: obvykle se jedná o obsah určený pro určitou skupinu uživatelů. Firemní intranety nebo zaměstnanecké portály, obsah určený pouze pro členy a pracovní, testovací nebo vývojová prostředí.
Nízká priorita: tyto stránky obvykle obsahují duplicitní obsah nějakého druhu. Některé příklady by zahrnovaly stránky obsluhované z více adres URL, adresy URL s parametry a opět by mohly zahrnovat pracovní, testovací nebo vývojová prostředí.
chci pokrýt několik způsobů, jak obvykle vidím odstranění provedené nesprávně a co se děje v každém scénáři, aby lidé pochopili, proč nefungují.
Noindex v robotech.txt
zatímco Google neoficiálně podporoval noindex v robotech.txt, nikdy to nebyl oficiální standard a nyní formálně odstranili podporu. Mnoho stránek, které to dělaly, tak činily nesprávně a poškozovaly se.
blokování procházení roboty.txt
procházení není totéž jako indexování. I když je Google blokován v procházení stránek, pokud existují nějaké interní nebo externí odkazy na stránku, mohou ji stále indexovat. Google nebude vědět, co je na stránce, protože se nebude plazit, ale oni vědí, že strana existuje a bude i napsat název se bude zobrazovat ve výsledcích vyhledávání na základě signálů, jako je kotva text odkazů na stránce.
Nofollow
to se běžně zaměňuje za noindex a někteří lidé jej použijí na úrovni stránky a očekávají, že stránka nebude indexována. Nofollow je nápověda, a přestože původně zastavil procházení odkazů na stránce a jednotlivých odkazů s atributem nofollow, už tomu tak není. Google nyní může procházet tyto odkazy, pokud chtějí. Nofollow byl také použit na jednotlivých odkazech, aby se pokusil zabránit Google v procházení na konkrétní stránky a pro sochařství PageRank. Opět to již nefunguje, protože nofollow je náznak. V minulosti, pokud na ni měla stránka jiný odkaz, mohl Google stále objevit z této alternativní cesty procházení.
Všimněte si, že nofollowed stránky můžete najít hromadně pomocí tohoto filtru v Průzkumníku stránek v Ahrefs‘ Site Audit.
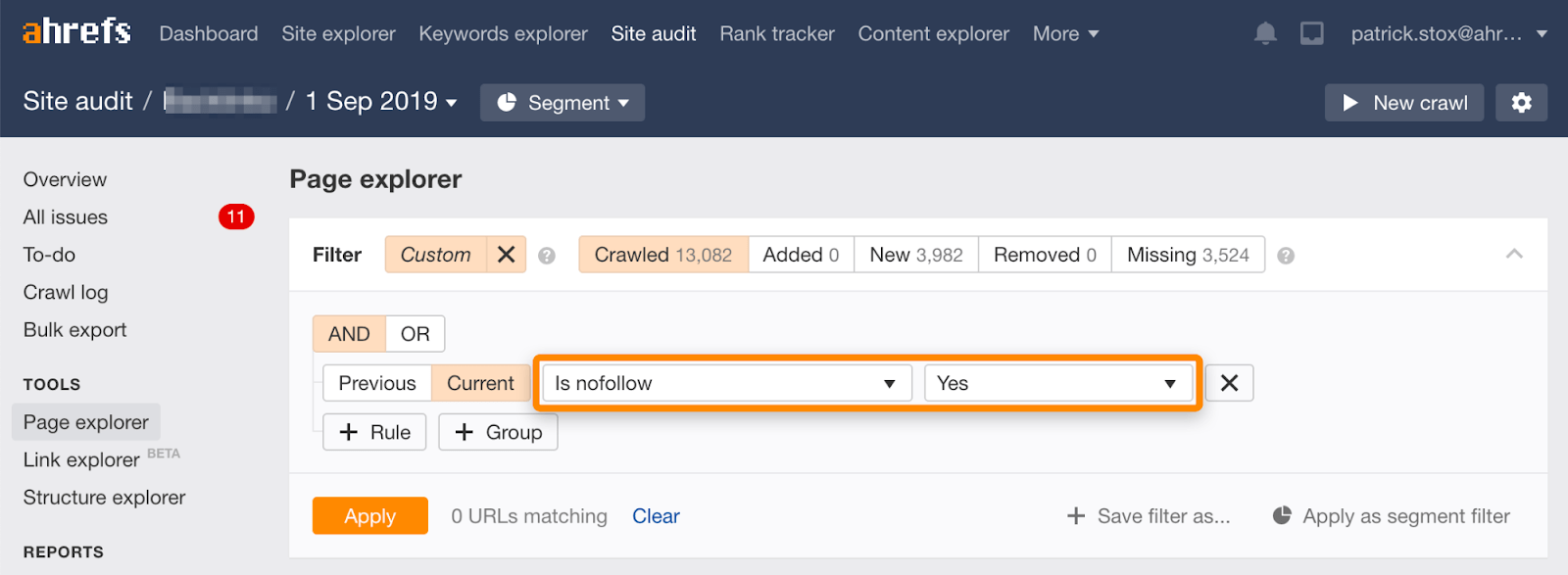
protože málokdy má smysl nofollow všechny odkazy na stránce, počet výsledků by měl být nulový nebo téměř nulový. Pokud tam jsou odpovídající výsledky, žádám vás, abyste zkontrolovat, zda nofollow směrnice byla omylem přidána místo noindex a zvolit vhodnější způsob odstranění, pokud je třeba.
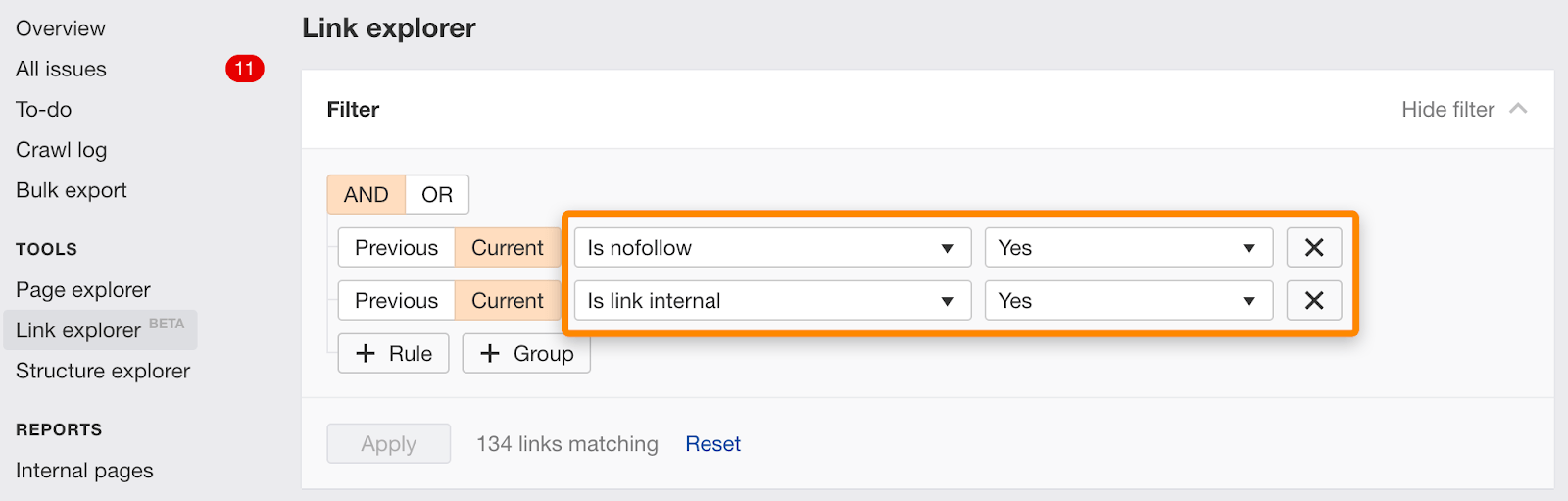
můžete také najít jednotlivé odkazy označené nofollow pomocí tohoto filtru V Link Explorer.
Noindex a canonical na jinou adresu URL
Tyto signály jsou protichůdné. Noindex říká, že odstraní stránku z indexu, a canonical říká, že Další stránka je verze, která by měla být indexována. To může ve skutečnosti fungovat pro konsolidaci, protože Google se obvykle rozhodne ignorovat noindex a místo toho použít canonical jako hlavní signál. Nejedná se však o absolutní chování. Existuje algoritmus a existuje riziko, že značka noindex může být počítán signál. Pokud tomu tak je, pak se stránky nebudou správně konsolidovat.
Všimněte si, že můžete najít noindexed stránky s non-self-referential ornátech pomocí této sady filtrů na Stránce Explorer na Webu Audit:
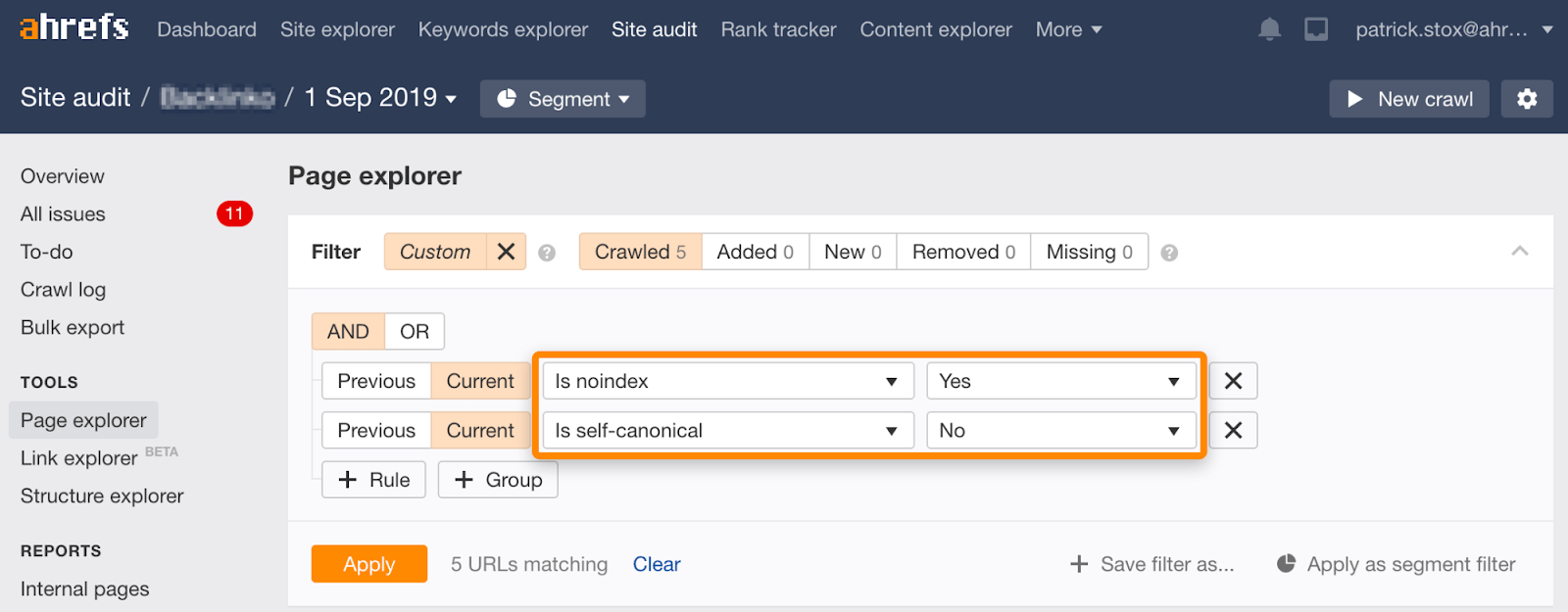
Noindex, čekat na Google plazit, pak blok z plazí
Existuje několik způsobů, jak to obvykle stává:
- Stránky jsou již blokovány, ale jsou indexovány, lidé přidat noindex a odblokovat tak, že Google může procházet a vidět noindex, pak blokovat stránky z procházení znovu.
- lidé přidávají značky noindex pro stránky, které chtějí odstranit, a poté, co Google procházel a zpracoval značku noindex, zablokují procházení stránek.
Ať tak či onak, konečný stav je blokován z procházení. Pokud si pamatujete, dříve jsme hovořili o tom, jak procházení není stejné jako indexování. I když jsou tyto stránky blokovány, mohou stále skončit v indexu.
Pokud vlastníte obsah, který se používá na jiné webové stránce, můžete podat nárok na základě zákona o autorských právech Digital Millennium (DMCA). Nástroj pro odstranění autorských práv společnosti Google můžete použít k tomu, co se nazývá zastavení šíření DMCA, které vyžaduje odstranění jakéhokoli materiálu chráněného autorskými právy.
co když je to obsah o vás, ale ne na webu, který vlastníte?
Pokud jste v EU, můžete nechat odstranit obsah, který obsahuje informace o vás díky soudnímu příkazu k zapomenutí. Můžete požádat o odstranění osobních údajů pomocí formuláře pro odstranění soukromí EU.
Chcete-li odstranit obrázky z Googlu, nejjednodušší je s roboty.txt. Zatímco neoficiální podpora pro odstraňování stránek byla odstraněna z robotů.txt jak jsme již zmínili, jednoduše zakázat procházení obrázků je správný způsob, jak odstranit obrázky.
Pro jeden obraz:
User-agent: Googlebot-ImageDisallow: /images/dogs.jpg
Pro všechny obrázky:
User-agent: Googlebot-ImageDisallow: /
závěr
Jak odebrat adresy Url je dost situační. Mluvili jsme o několika možnostech, ale pokud jste stále zmateni, což je pro vás to pravé, podívejte se zpět na vývojový diagram na začátku.
můžete také projít právním nástrojem pro odstraňování problémů poskytovaným společností Google pro odstranění obsahu.
máte dotazy? Dejte mi vědět na Twitteru.